必示科技2020年度告警数据挖掘方向顶会论文分享
本文根据必示科技算法总监隋楷心在2020国际AIOps挑战赛的主题演讲整理而成,重点介绍了必示科技在INFOCOM 2020 、ICSE SEIP 2020、ESEC/FSE 2020发表的三篇论文成果以及核心方法,为业界在告警数据挖掘方向的研究提供新思路。
各位老师、同学,大家下午好!
今天和大家分享一下,必示科技2020年度在告警数据挖掘方向的三篇顶会论文。
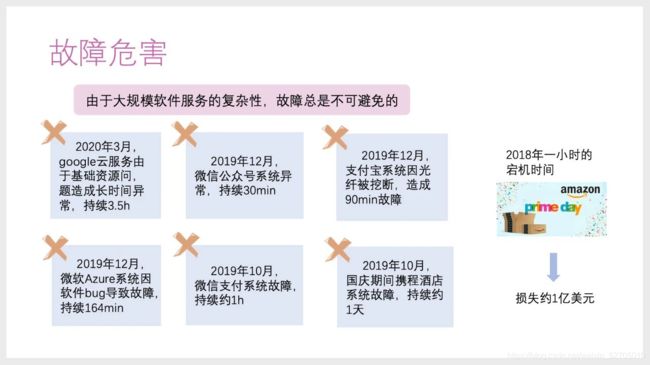
先介绍下背景,从大型互联网公司过去一年遇到的服务故障可以看到,服务故障对企业效益和用户体验造成了非常大的影响。比如,亚马逊2018年Prime Day活动,1小时宕机时间就引发了约1亿美元的损失。
目前很多工作在关注运维领域的服务质量保证和可靠性提升,但由于大规模软件服务的复杂性,故障总不可避免。
告警数据挖掘的方向及痛点
为了保证软件服务质量和用户体验、减少经济损失,故障智能分析至关重要,主要聚焦在三个方向:

- 故障发现,即如何及时、准确发现故障;
- 故障诊断,即如何快速、准确诊断出故障的根因;
- 故障预测,即如何提前预警故障,规避故障。
对已有的监控告警数据进行智能分析,即告警数据挖掘在故障智能分析中,能够起到什么作用、解决什么痛点?
我们发现,在故障发现领域,告警定级策略不合理会影响故障发现的时效性;故障诊断过程中,运维工程师通常遇到的告警风暴会严重影响诊断的效率;在故障预测方面,告警信息在故障引发业务损失之前就已经有了大量的征兆,这说明,告警中的隐患信号未被有效捕捉,故障预警非常困难。
对此,我们提出了相应的告警数据挖掘的方法:
自适应的告警动态定级;
告警风暴摘要;
基于告警的事件预测。

下面,我针对痛点问题进行具体讲解:
01
告警定级策略不合理,影响故障发现时效性
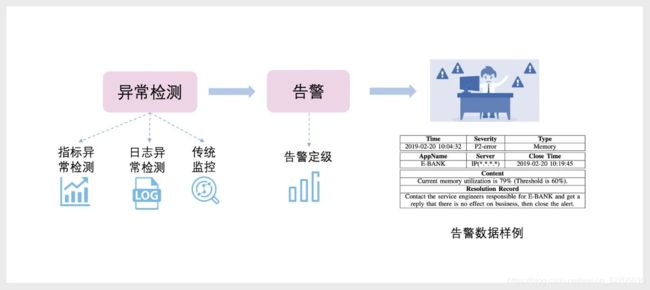
告警和故障发现,通常是两个步骤。第一步异常检测,检测到异常后,通过第二步聚合和定级策略产生告警信号。告警信号是运维工程师发现故障、处理故障、介入故障的重要来源。
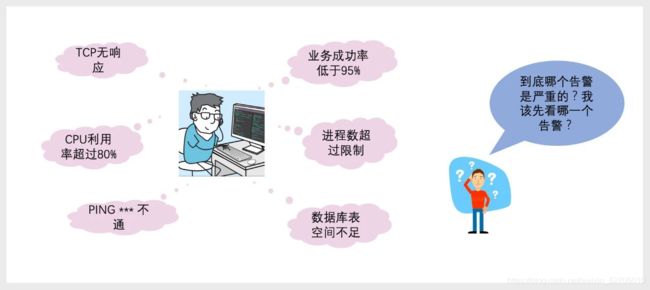
由于软件服务规模越来越大、复杂性越来越高,故障发生时往往会产生大量告警。在大量告警发生时,运维工程师陷入了困惑:哪个告警最严重?应该先看哪个告警?经验丰富的运维工程师可以抽丝剥茧,一下命中肯綮,但更多时候呈现出一团乱麻的状态。
举个实际案例,曾有金融客户在早上10点45分通过用户电话报障发现故障,但在10点45分之前就已有一些与故障相关的告警,比如说响应时间上升到500ms。不过由于人工设置的阈值导致告警级别不够高,并没有引起工程师的注意。
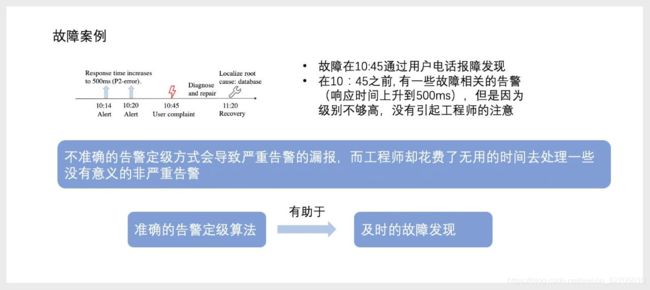
不准确的告警定级方式会导致严重告警的漏报,工程师排障时也会花费很多时间去处理没有意义的非严重告警。这表明,准确的告警定级算法有助于及时的故障发现。
02
告警风暴影响故障诊断的效率
这是运维人都会遇到的痛点。软件架构复杂化,业务拓扑之间的关系都会导致告警。一个系统引发告警,很多系统会随之呈现风暴式告警。软件架构如此,硬件拓扑网络也是如此。如果底层路由器会引发问题,整个硬件从底到上都会传导告警,形成告警风暴。

需要注意的是,服务故障和告警风暴产生时,应用架构有很多组件,且每个组件都有自己的监控数据,会产生相应的告警。同时,硬件拓扑和软件会发生复杂依赖关系,导致这些告警和故障之间会不断传导。

处于告警风暴情况下,运维管理员的难题在于:到底发生了什么事、哪些告警跟故障相关、告警风暴的核心内容是什么。如果手工检查所有的告警,不仅耗时、耗力,还容易出错。
03
告警的隐患信号未被有效捕捉,故障预警困难
学术界现有的故障预测方法有一些限制。在第一届挑战赛时,我曾跟大家介绍过在微软做的利用磁盘SMART数据做磁盘故障预测的论文。后来,我们实验室也用交换机日志做交换机故障预测,用节点性能指标做节点故障预测,还用工业设备日志去做设备故障预测。
但是,大多数方法专门为一种故障设计,比如磁盘故障、节点故障、交换机故障等,不具备泛化性。同时,这些方法大多是利用指标和日志数据来提取有预测作用的征兆特征,训练开销非常大。此外,我们希望用轻量级的告警数据来做事件预测,但已有的一些方法仅仅考虑了每类告警的数量作为特征,实际表现并不理想。

以上是学术界的情况,但是工业界也没有用告警数据做故障预测的有效方案。
首先,我们常常听到,大家会基于专家知识和运维经验,去总结事件预测的规则。比如当线上的告警满足规则,就认为要发生相应的事件。不过,基于规则的预测方法,在实际中经常会出现误报、漏报。我们分析其原因在于:维护和制定规则需要足够的运维经验,且耗费时间;不同工程师制定规则的偏好不一样,很难有统一的标准;服务系统总是会经历不停的迭代变更,固定的规则很难适应动态的环境。
其次,基于频繁项集挖掘去做探索,我们认为经常一起出现的告警会有一些征兆表现,而实际落地尝试中,金融行业工程师反馈这类方法覆盖面比较小。由于告警数据的复杂性和告警内容中混杂的参数,大多数事件都没有对应的频繁项告警,所以这类方法在金融数据中心可用性并不高。
关于告警数据挖掘的三篇论文研究成果
我们在INFOCOM 2020 、ICSE SEIP 2020、ESEC/FSE 2020发表了三篇论文(如下图),对应解决故障发现、故障诊断和故障预测的痛点问题。

接下来,我将介绍论文的核心方法。
INFOCOM 2020:自适应的告警动态定级
第一篇文章的核心,是用历史告警的处置记录做标注,利用多特征融合方法训练排序模型,对线上实时到达的告警流进行排序,以排序结果作为严重性的定级结果。
我们可以看到,工业界实践中告警定级通常基于手工规则的告警,比如P1是严重,P2是错误,P3是警告。怎么去区分?这里做了一些规则。对于CPU来说是阈值,利用率超过90%是P2,利用率超过80%是P3;对于日志来说是关键字,如果有fail就是P1,有warning就是P3。
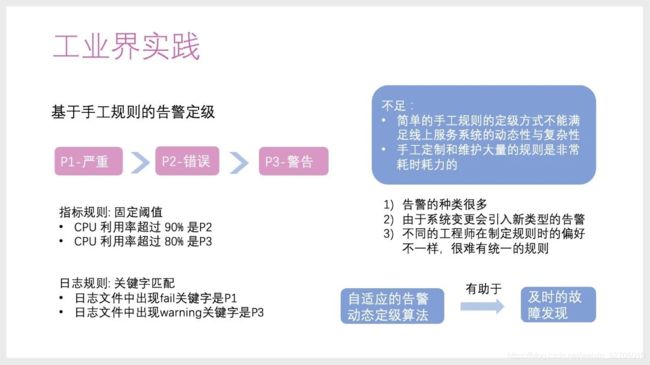
当然,这也有明显的不足,简单的手工规则的定级方式不能满足线上服务系统的动态性与复杂性,手工定制和维护大量的规则耗时、耗力。
同时,我们也遇到了告警种类非常多,系统变更会引入新类型的告警,不同工程师制定规则的偏好不一致、很难有统一的规则等问题。这要求我们通过数据挖掘和数据驱动的方式,来做到基于系统自适应的告警动态定级的算法,来帮助及时的故障发现。
在此过程中,我们同样遇到了一些挑战(如图):

- 标注开销非常大,这是常见的问题。
- 告警类型复杂多样,有大量的应用、网络、数据库、中间件、存储等告警数据。
- 复杂动态的线上环境。因为我们要适应动态的线上环境,比如系统变更衍生出的新告警。
- 数据不平衡。故障种类少,严重告警比例比较小。
对于告警处理方法和流程,我们的核心思想在于:首先采用多特征融合,不仅采用告警数据,还提取了一部分指标特征;其次,对告警严重性进行排序,把识别告警严重性定义为排序模型。其实,告警严不严重是相对概念,只要它比别的严重,那就更严重。这不是常说的分类概念,ranking model排序模型在此场景下更为合适。

整体流程方面,将告警数据和指标数据分别进行预处理和数据筛选,用告警模板提取相应的特征,指标也提取相应的特征,生成特征向量后,再从工单中进行标注提取,建立排序模型,完成离线训练。在线数据同样会进行特征提取和特征向量的建立,经过排序模型后给出结果,直接反馈给工程师,去看哪一个更严重。

我们使用数据包括告警数据、KPI数据和工单数据。我们基于工单数据中的记录和历史告警数据中的处置记录,对每一个告警给出严重性评分(比如某个告警关联到了工单,那这个告警的严重性就很高;如果某个告警的处置记录反馈无影响,那么这个告警的严重性就相对较低)。
在特征工程方面,我们采用多特征融合方式,针对告警数据提取三类特征:一是文本特征,包括告警语义的主题模型和文本熵IDF(Inverse document frequency),去看关键词的重要性;二是时间特征,包括频率、周期、告警数量和间隔时间等;三是告警类型和发出时间等其他特征。比如发出时间就是一个关键特征,券商客户遇到的告警发生在开市期间还是闭市期间?不同时间同样的CPU告警级别是完全不同的。

告警所在的业务也有各种各样的黄金指标,特别是相应的业务指标。对此,我们提取了所在应用系统的关键业务指标,比如交易量、响应时间、成功率等。这里主要采用两种方式:一、对它们做异常检测,将异常分数作为评分;二、进行多指标异常检测,安全模拟一个实体的健康分数,作为特征融入模型。

通过上图特征分析,可以看到,特征和告警严重性并不是简单的线性关系。这要求我们使用AI机器学习模型,去综合建模不同的特征和最后告警定级之间的复杂关系。
我们论文中的特征工程,一共用到40个特征。特征完成后去训练排序模型,这里的标签主要来自于历史的告警数据的处置记录,也就是工单。另外,我们还采用了XGBoost ranking模型。

在线数据同样经过特征工程,经过排序的过程,生成排序结果。比如,当abcde告警同时到达时,我们能够给出ranking结果,让管理员更清晰知道从哪个告警入手。

最后介绍一下评估规则,我们使用三组工业界真实的告警数据来评估,用AlertRank方法去对比传统基于规则的方法和BUG报告定级算法BUG-KNN。结果表明, AlertRank方法可以达到平均90%的F1 -SCORE,是整体最优的方法。同时,我们评估了多特征融合方式的作用,分别看了告警特征和指标特征对结果的贡献,发现它们对模型起到正向作用。
以上是发表在INFOCOM 2020顶会上的论文,我们提出的“自适应的告警动态定级”方法已应用于工业实践中,赋能金融客户切实解决运维难题。
下一期精彩继续,将分享在ICSE SEIP 2020、ESEC/FSE 2020发表的两篇论文,介绍“告警风暴摘要”和“基于告警的事件预测”的核心思想,敬请关注。