大数据开发常见问题
Linux
磁盘百分之百的问题
找到比较大的文件,然后删除大的一些日志文件
sudo find / -size +100M -exec ls -lh {} \;
&rewriteBatchedStatements=true&characterEncoding=utf-8免密
yonghu ALL=(root) NOPASSWD: ALL,!/usr/bin/reboot, !/sbin/reboot, !/bin/su,!/usr/bin/su, !/sbin/shutdown修改主机名
vi /etc/hostname
sudo hostnamectl set-hostname h1SSH
- 如果有对应的ssh连接出错,修改ssh的配置文件允许访问。
清理buff/cache
sudo sh -c 'echo 3 > /proc/sys/vm/drop_caches'
调整内核参数:一些内核参数可以影响文件系统缓存的使用。您可以通过修改
/etc/sysctl.conf文件来更改这些参数。其中一个常见的参数是vm.vfs_cache_pressure,它控制了内核在释放缓存时的倾向性。通过增加该值(例如从默认的 100 到 200),可以减少缓存的大小。
资源限制问题
#调整用户的资源限制,(有时候使用doris的时候如果不配置对应的限制会出现资源su: failed to execute /bin/bash: Resource temporarily unavailable)
sudo vi /etc/security/limits.conf
bigdata soft nofile 65535
bigdata hard nofile 65535
sudo vi /etc/security/limits.d/20-nproc.conf
bigdata soft nproc unlimitedHadoop
- 安装hadoop之前一定要修改hostname和对应的映射/etc/hosts,因为hadoop会依赖到hostname。也就是如果本机的/etc/hosts是master,那么hostname也修改成master,不然会出现各种问题。
- 如果出现运行wordcount卡住的情况,那么可能是/etc/hosts对应的127.0.0.1影响了,注解掉,重启hadoop。
- #查看namenode状态
hdfs haadmin -getServiceState nn1
元数据损坏问题
#####################一次元数据损坏问题##################
#删除损坏的元数据namenode节点的数据############
hdfs namenode -bootstrapStandby
#重启集群辅助操作
删除主节点的元数据信息,将新主节点的元数据信息复制过来(把从节点的所有current的fsimgge和it'复制到主节点,其他的所有保持不变)
hadoop namenode -recover(挂了的机器进行修复) 选c然后选a
启动
sbin/hadoop-daemon.sh start namenode
查看磁盘的健康状态
curl http://master1:9870/fsck (新主节点查看磁盘状态)
如果不健康关闭安全模式然后修复
hdfs dfsadmin -safemode leave
hadoop fs -setrep -w 3 -R /
然后再查看安全状态
curl http://master1:9870/fsck
curl http://master2:9870/fsck
hdfs haadmin -getAllServiceState高可用
离线数据仓库从0到1-阶段二软件安装_离线数仓软件_顶尖高手养成计划的博客-CSDN博客
flink on yarn 模式下提示yarn资源不足问题分析-腾讯云开发者社区-腾讯云
Yarn动态刷新配置
yarn rmadmin -refreshQueues 刷新的命令hadoop不能停止的问题
hadoop运行一段时间后,无法正常停止。
解决方法:
1.jps查询所有的相关进程,如namenode,然后kill -9 进程号
2.修改etc/hadoop/hadoop-env.sh 中的 hadoop-pid-dir 指定到一个有效的目录、
如:export HADOOP_PID_DIR=/home/bigdata/module/hadoop-3.1.3/pid
产生的原因是 hadoop-pid-dir 这个环境变量默认是 /tmp,而/tmp中的所有的内容是要被操作系统定期清除的,清除后,hadoop-daemon.sh stop xxx 无法找到相应的进程号,所有无法停止。
Cannot set priority of 问题
修改hdfs(主要的原因是上面修改了pid的目录以后默认执行shell的是hdfs,改成bigdata就有权限了)
HADOOP_SHELL_EXECNAME="bigdata"手动切换主节点
#手动切换主从
kill -9 进程号
#重启namenode
sbin/hadoop-daemon.sh start namenode
#查看状态
hdfs haadmin -getAllServiceState
#查看hdfs状态
curl http://master1:9870/fsck
#离开安全模式
hdfs dfsadmin -safemode leaveHive on Spark
hive元数据详解
Hive元数据服务MetaStore-腾讯云开发者社区-腾讯云
Mysql最大连接问题
如果连接不太够,hive on spark会失败

修改my.cnf
sudo vi /etc/my.cnf[mysql]
max_connections = 2000查看系统limit限制
# 查询文件限制
$ ulimit -n
1024修改系统文件限制
# 编辑系统文件配置文件
$ view /etc/security/limits.conf
# 在/etc/security/limits.conf最后增加如下两行记录
* hard nofile 65535
* soft nofile 65535- yarn logs -applicationId application_1670892172838_0002 查看对应的日志一般就可以找到答案,如果是对应的hostname无法找到,那么就是安装hadoop的时候可能没有修改hostname,修改重启hadoop就行。
- 如果磁盘到达百分之90往上,那么nodemanager就会是unhealth状态。
- hive on spark执行脚本的时候hive -e ...,如果资源不释放在后面加 一个quit;还要加上下面的配置,主要是hiveserver2会话不关闭的问题。
会话不关闭问题,hive on spark运行完以后资源不释放(hue)
hive.server2.session.check.interval
3000
The check interval for session/operation timeout, which can be disabled by setting to zero or negative value.
hive.server2.idle.session.timeout
0
Session will be closed when it's not accessed for this duration, which can be disabled by setting to zero or negative value.
hive.server2.idle.operation.timeout
0
Operation will be closed when it's not accessed for this duration of time, which can be disabled by setting to zero value. With positive value, it's checked for operations in terminal state only (FINISHED, CANCELED, CLOSED, ERROR). With negative value, it's checked for all of the operations regardless of state.
空值连接问题
原始表
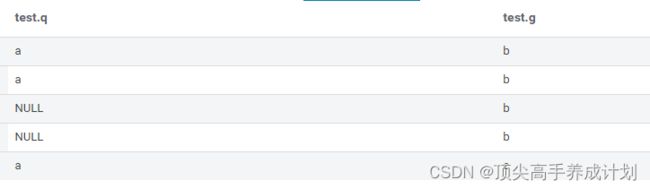
普通连接
select * from test a
left join
test b
on a.q=b.q and a.g=b.g;结果(可以看到空值没有进行关联)
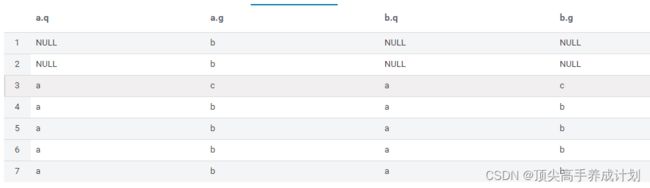
如果想空值和其他值一样进行关联(可以看到现在所有的值进行了关联,包括空值)
select * from test a
left join
test b
on COALESCE(a.q,'')=COALESCE(b.q,'') and COALESCE(a.g,'')=COALESCE(b.g,'');
failed to create spark client for spark session(资源不足导致超时)
修改两个参数

hive.spark.client.connect.timeout
90000ms
重建分区
#如果已经有分区的情况建表以后要执行重建分区的操作。
show partitions 库名.表名;
MSCK REPAIR TABLE 库名.表名;
#重建分区以后分区表就出现了
show partitions 库名.表名;Mysql使用大小写命名的时候Hive读取不到数据的问题
#mysql的表字段
isInStock :STRING
#hive创建的表字段
isinstock :STRING数据加载load
#load insert overwrite 的时候如果对应的位置没有文件,那么不会清除目标表数据。
Hive Session ID = 3fabdc4b-2fc9-4026-8434-89abc58500bc
Logging initialized using configuration in jar:file:/home/bigdata/module/apache-hive-3.1.2-bin/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive Session ID = 745f2d91-3f62-4f29-ba49-be8b5a76ac1a
FAILED: SemanticException Line 2:17 Invalid path ''/user/hive/warehouse/abs/ods/ods_orderinfo_inc/2023-03-07'': No files matching path hdfs://bigdatacluster/user/hive/warehouse/abs/ods/ods_orderinfo_inc/2023-03-07DataX
- 如果低版本的驱动连接8.0的话就要下载对应的8.0的jdbcjar

https://dev.mysql.com/downloads/file/?id=513754
应用文章
java.sql.SQLException:Could not retrieve transation read-only status server解决方法_观澄的博客-CSDN博客_sqlexception: could not retrieve transation read-o
![]()
找到对应的插件的lib文件替换就行了
jdbc:mysql://localhost:3306/demo?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTCdatax读取mysql数据到hdfs如果mysql的是null到hdfs就是空字符串。
Mysql
- 在mysql8.0的时候存储表情更加兼容,5.7的话有点问题。
create database analyze CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;一次mysql停机处理,这是是看不到进程号无法关闭处理
yum install -y lsof
sudo lsof -i:3306
sudo kill -9 32075
service mysqld status (查看进程号关闭)mysqldump --databases dolphinscheduler hive hue > all_database_bak.sqlmysql忘记密码处理
mysql忘记密码如何修改密码_mysql忘记密码怎么修改密码_qq_30748583的博客-CSDN博客
配置用户远程登录
#mysql5.7
CREATE USER 'mysql_monitor'@'%' IDENTIFIED BY 'Mysql@123' WITH MAX_USER_CONNECTIONS 10;
GRANT ALL PRIVILEGES ON *.* TO 'mysql_monitor'@'%' IDENTIFIED BY 'Mysql@123' WITH GRANT OPTION;
FLUSH PRIVILEGES;
EXIT
#测试登录
mysql -umysql_monitor -pMysql@123
#mysql8.0
#已经有用户的情况
ALTER USER USER() IDENTIFIED BY 'Mysql@123';
grant all privileges on *.* to 'root'@'%' with grant option;
FLUSH PRIVILEGES;
EXIT
#创建用户授权流程
CREATE USER 'root'@'%' IDENTIFIED BY 'Mysql@123' WITH MAX_USER_CONNECTIONS 1000;
grant all privileges on *.* to 'root'@'%' with grant option;
FLUSH PRIVILEGES;
EXIT
#测试登录
mysql -uroot -pAdmin2022!
修改指定用户的最大连接数
修改指定用户的最大连接数目
use mysql;
select MAX_USER_CONNECTIONS from user user='root'
update user set MAX_USER_CONNECTIONS='1000' where user='root';
FLUSH PRIVILEGES;
EXIT
Screen
#进入一个窗口
screen -S hue
#后台运行应用直接关闭窗口,或者Ctrl+AKafka
远程访问问题(开启 远程访问),如果只是局域网内可以访问,上面的listeners和advertised的ip相同就行,还有关闭防火墙和selinux。
listeners=PLAINTEXT://0.0.0.0:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://外网对应的ip总之如果上面配置了0.0.0.0那么这里就必须配置一个因为如果不配置就是listeners的ip,这个作用就是要写到zookeeper如果是0.0.0.0外网不知道是哪个:9092kafka启动访问hostname问题
#启动的服务和hostname有关
hostnamectl set-hostname doris2
#在访问kafka的机器也要配置好对应的/etc/hosts和启动的kafka集群的hostname对应才行
比如上面的hostname是doris2
那么访问对应的kafka的时候在访问的机器配置
/etc/hosts
doris2 kafka服务器详解地址
https://www.jb51.net/article/235535.htm
如果这样配置以后,关闭防火墙,关闭selinux,还是不能访问,那么可能就是服务器之间配置了安全组。
Kafka事务问题
面试官:Kafka 事务是如何工作的? - 掘金
Maxwell
mysql如果不是为full的话,那么修改的update的old就没有数据

binlog中断的问题
采集的时候binlog被删除了,maxwell采集中断,binlog的保存时间设置成7天。(这里是由于一定的网络原因问题,由于maxwell读取binlog的时候网络超时引起,比如在28号发现maxwell挂了,在29号启动maxwell,由于maxwell的ts存储的是binlog的的事件时间,在由于flume配置了用ts的时间作为时间变量,那么启动以后尽管现在是29号,它启动以后还是会把28号的数据消费过来形成 28号的目录文件)
#查询现在binlog的位置
show master status ;
#查询所有的binlog名称和位置
SHOW BINARY LOGS;
#查询具体的binlog信息
show binlog events in 'mysql-bin.004864' from 1891649;java.net.UnknownHostException: doris2
maxwell遇到错误,测试发送到kafka集群报错UnknownHostException,设置hosts以后消息成功发送
*** ms has passed since batch creation plus linger time
自己解决的办法是因为kafka在监听,是用的hostname,所以我在消费的主机加了本地的dns,也就是修改了/etc/hosts, kafkaip doris2 ,(注意这里集群内下面图的位置我没有修改,直接修改对应的host就行了,也就是说上面的doris2 是hostname,也是kafka监听的域名,这个时候只要本地使用了hosts映射那么就可以访问了)
#测试集群是否可以发送消息
bin/kafka-producer-perf-test.sh --topic test2 --record-size 200 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=ip:9092
参考文章
kafka启动报错:java.net.UnknownHostException|unknown error at java.net.Inet6AddressImpl.lookupAllHost 很详细_血煞长虹的博客-CSDN博客
Doris
有大量内存但是不能够全部利用的问题
cat /proc/sys/vm/overcommit_memory
echo 1 > /proc/sys/vm/overcommit_memory
sudo sh -c 'echo 1 > /proc/sys/vm/overcommit_memory'
https://blog.51cto.com/lookingdream/1933132
set global parallel_fragment_exec_instance_num =8;简单排错
#如果是mysql客户端报错查看下面的日志文件
apache-doris-fe-1.2.0-bin-x86_64/log/fe.warn.log
#如果是be挂了,查看be.out
#常见的错误码
https://doris.apache.org/zh-CN/docs/dev/admin-manual/maint-monitor/doris-error-codetop -H -p pid优化
show variables like '%parallel_fragment_exec_instance_num%';
set global parallel_fragment_exec_instance_num = 8; 在线表结构变更例子
https://github.com/apache/doris-flink-connector/blob/master/flink-doris-connector/src/test/java/org/apache/doris/flink/CDCSchemaChangeExample.java
配合flink
Flink sink doris案例_Z-hhhhh的博客-CSDN博客
Doris创建物化视图报错以后的处理办法
#查看节点的状态信息
SHOW PROC '/backends';
#查看表的物化视图和基表的操作
desc table_name all;
#查看表的物化视图的修改信息,和对应创建物化视图的jobid
SHOW ALTER TABLE MATERIALIZED VIEW FROM db_name;
#取消执行的job
CANCEL ALTER TABLE ROLLUP FROM db_name.table_name (446023);创建动态分区的简单模板
insert into test values('1','1',now());
insert into test values('1','1',now());
select * from test;
drop table test;
CREATE TABLE `test` (
`product_id` varchar(100) NOT NULL COMMENT '商品id',
`site` varchar(50) NULL,
`day_id` date
) ENGINE=OLAP
UNIQUE KEY(`product_id`, `site`,`day_id`)
COMMENT 'OLAP'
PARTITION BY RANGE(`day_id`)()
DISTRIBUTED BY HASH(product_id) BUCKETS 3
PROPERTIES (
"replication_allocation" = "tag.location.default: 3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "4",
"dynamic_partition.prefix" = "p",
"dynamic_partition.replication_allocation" = "tag.location.default: 3",
"dynamic_partition.buckets" = "10",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.history_partition_num" = "47",
"dynamic_partition.hot_partition_num" = "0",
"dynamic_partition.reserved_history_periods" = "NULL",
"dynamic_partition.storage_policy" = "",
"dynamic_partition.storage_medium" = "HDD",
"in_memory" = "false",
"storage_format" = "V2",
"disable_auto_compaction" = "false"
);
优秀案例
9 篇博文 含有标签「用户案例」 - 云原生实时数据仓库
文章
配置Fe的JVM
JAVA_OPTS="-Xms16g -Xmx16g -Xmn8g -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:$DORIS_HOME/log/fe.gc.log.$DATE"
# For jdk 9+, this JAVA_OPTS will be used as default JVM options
JAVA_OPTS_FOR_JDK_9="-Xms16g -Xmx16g -Xmn8g -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xlog:gc*:$DORIS_HOME/log/fe.gc.log.$DATE:time"小文件过多场景
compaction_task_num_per_disk = 4
compaction_task_num_per_fast_disk = 8
max_cumu_compaction_threads = 15
total_permits_for_compaction_score = 15000
segcompaction_threshold_segment_num = 15
JDBC Catalog的使用
show catalogs;
show catalog jdbc_catalog;
CREATE CATALOG jdbc_catalog PROPERTIES (
"type"="",
"user"="",
"password"="",
"jdbc_url" = "jdbc:mysql://ip:3306/",
"driver_url" = "mysql-connector-java-8.0.25.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver"
);
switch jdbc_catalog;
select * from jdbc_catalog.数据库.表名称;HDFS
Hdfs扩容
大数据Hadoop之——Hadoop HDFS多目录磁盘扩展与数据平衡实战操作_大数据老司机的博客-CSDN博客_hadoop磁盘均衡
数据均衡
HDFS 磁盘均衡 | HDFS 教程
dfs.datanode.fsdataset.volume.choosing.policy
org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy
dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction
0.75f
dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold
10737418240
dfs.datanode.data.dir
/data1,/data2,/data3,/data4
数据均衡 (每一个节点都要执行)
hdfs diskbalancer -plan node2执行计划
hdfs diskbalancer -execute /system/diskbalancer/2016-Aug-17-17-03-56/172.26.10.16.plan.json查看状态
hdfs diskbalancer -query node2看到PLAN_UNDER_PROGRESS 表示正在平衡,
PLAN_DONE 表示完成
查看执行的结果()
df -h![]()

上面可以清晰的看到数据在迁移
Hdfs数据磁盘满以后处理
方法一
这个简单粗暴,直接复制数据到指定目录。
先关闭hadoop
1.由于之前的磁盘 满了,如果没有指定datanode的位置那么就会在这个文件夹生成data目录存储datanode数据。

2.这个时候新添加一个磁盘,挂到/data目录下面。
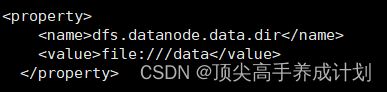
3 .设置好以后先启动下hadoop。这个时候就会生成下面的文件。
/data/current/BP-1174901237-192.168.66.10-1652784708371/current/finalized4.关闭hadoop,然后把之前的datanode的数据拷贝到新的datanode目录。
cp -r subdir0 /data/current/BP-1174901237-192.168.66.10-1652784708371/current/finalized![]()
其他的datanode数据也全部这样直接拷贝数据过去。
5.重新启动hadoop,数据正常。
方法二
这个主要是利用了hdfs的3个副本机制。
1.关闭hadoop集群。
2.删除一个datanode的数据。
3.指定新的路径。
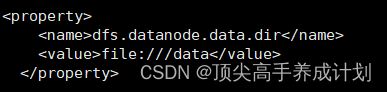
4.重启hadoop集群,检查下磁盘情况(可以看到现在就是有两个副本)。
http://master:9870/fsck![]()
正常情况如下,异常情况如上面。

5.执行数据同步。
运行hadoop fs -setrep -w 3 -R /, 重新生成副本, 如果中途出现out of memory,则重新运行该命令即可
6.查看检查报告看看有哪些目录的数据丢失,是否无关数据,删除这些无关数据:hadoop fsck <目录> -delete。
7.然后在重复修改其他的datanode存储数据的路径,然后重复5-7。
实战
情况
情况是新加了一块磁盘,由于是系统盘不太好扩容。
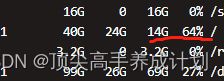
如图可以看到系统盘已经百分之64了,现在新加一个数据盘/data.他们现在的分区存储策略是,在相差10G之内就是负载均衡的策略。
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/data,/data
dfs.datanode.fsdataset.volume.choosing.policy
org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy
dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction
0.75f
dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold
10737418240
dfs.disk.balancer.enabled
true
现在的处理办法就是先关闭hadoop集群。因为现在配置了高可用。因为每一个datanode现在都有一个jounnalnode,所以停下集群。(如果现在这种情况,如下图,datanode和jn的数据存储现在都是在file://${hadoop.tmp.dir}/data,如果使用不停机修改配置的话jounnalnode可能会运行出错,动态修改配置的命令如下)
不停机修改配置(这里不做)
参考文章
Hadoop常用服务节点默认端口 - 掘金
Hadoop 变更磁盘的方法总结_铁猴的博客-CSDN博客
./hdfs dfsadmin -reconfig datanode 10.5.24.139:50020 start注:10.5.24.139为目录调整的Datanode节点,Datanode的默认IPC地址为:50020
查看配置:
Hadoop/bin/hdfs dfsadmin -report![]()

上面都是说明情况下面开始操作
开始操作
集群规划

1.先关闭hadoop集群.
先说明下变量,这个不用改。
core-site.xml
hadoop.tmp.dir
/home/bigdata/module/hadoop-3.1.3/data
原来的hdfs-site.xml
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/data,/data
修改后hdfs-site.xml(先修改一个datanode的,原因是想利用hdfs的3副本机制,复制副本到新的磁盘)
dfs.datanode.data.dir
file:///data
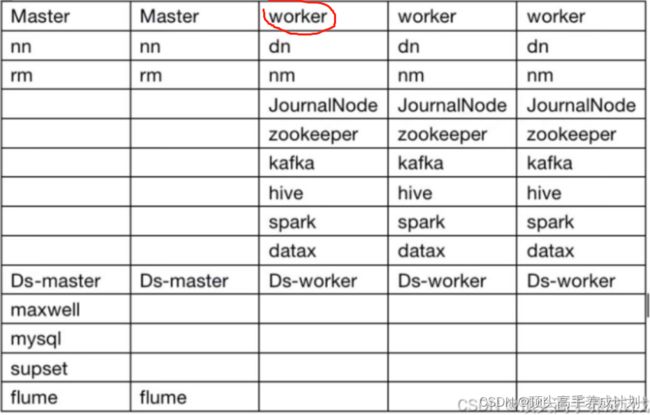
2.重启hadoop集群(下面是我数据仓库文章里面写的hadoop集群启动脚本)。
./hadoop-server-shell.sh start3.检查下现在的副本情况。
先检查下namenode的情况
hdfs haadmin -getAllServiceState![]()
检查副本情况
curl http://master1:9870/fsck可以看到很多块都只有两个副本现在(由于是上面修改了一个datanode的存储目录,所以现在有一个副本就丢失了)
![]()
![]()
这个时候开启副本重写机制(作用就是把现在的两个副本写成3个副本,如果有内存溢出的情况,重新执行命令)。
hadoop fs -setrep -w 3 -R /执行完以后再次执行,可以看到Missing replicas百分之0。
curl http://master1:9870/fsck4.关闭hadoop集群
./hadoop-server-shell.sh stop然后删除以前配置的file://${hadoop.tmp.dir}/data这个文件夹,看是否正常。
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/data,/data
这里注意千万别直接删除这个目录 ,由于自己的全部删除,导致jn也删除了,然后namenode无法启动,解决办法是把没有删除jn的复制到删除的datanode对应的jn目录(因为这里面存储了namenode高可用的变化信息,删除导致namenode高可用无法启动)
#也就是rm -rf file://${hadoop.tmp.dir}/data
rm -rf data/如果删除了解决办法(node1-3-sync-plus.sh是自己写的在datanode之间的分发脚本),分发以后如果不出意外就启动成功了。
./node1-3-sync-plus.sh /home/bigdata/module/hadoop-3.1.3/data/jn要执行下面的操作只删除datanode的data目录就行。
rm -rf /home/bigdata/module/hadoop-3.1.3/data/data操作完以后的结果对比。

重启hadoop集群
./hadoop-server-shell.sh start查看下状态是否正常
hdfs haadmin -getAllServiceState检查下磁盘状态
curl http://master1:9870/fsck如果一切正常那么开始重复上面的操作,修改datanode2,然后datanode3.......
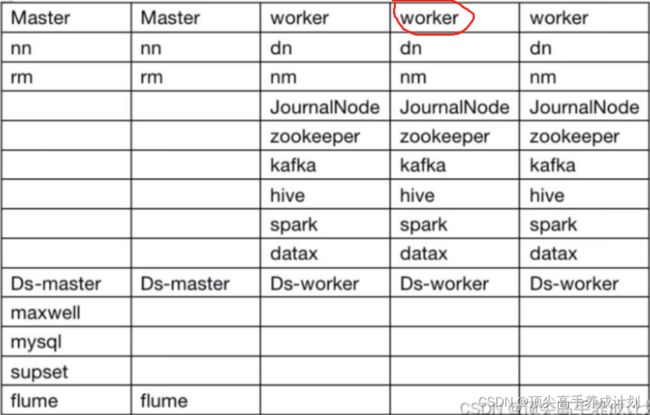
5.数据全部同步完成以后,把master1和master2的hdfs-site.xml配置文件也修改过来.
也就是直接分发下就行了(这个时候所有的机器配置文件就一样了)
./sync-plus.sh /home/bigdata/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
dfs.datanode.data.dir
file:///data
IDEA
源码无法下载问题
无法关联源码的时候在项目的目录打开命令行
![]()
mvn dependency:resolve -Dclassifier=sources相关本地调试链接
windows 安装superset - DB乐之者 - 博客园
Flink
提交任务
/home/bigdata/flink-1.13.6/bin/flink run \
-d \
#指定检查点
-s hdfs://master1:8020/checkpointunique/ck/66b06ff2bb80fb39318524aef76ea719/chk-14384 \
#yarn 集群模式
-m yarn-cluster \
#自定队列
-yqu high \
#指定提交到yarn的名称
-ynm unique \
-c com.bigdata.flinkmessageunique.FlinkMessageUnique \
bigdata-flink-kafka-message-unique-1.0-SNAPSHOT-jar-with-dependencies.jar
flink-doris-connector-1.15-1.2.0.jar
flink-sql-connector-mysql-cdc-2.2.1.jar
Flink CDC
1.有主键和唯一索引的情况下,单表的cdc操作能够增,删,改,都能够同步。
2.在关联表的时候,主键用的是order_detail的id,。
2.1 如果只是有order_info表的数据,没有order_info_detail数据,那么最后的结果没有数据,也就是说left join 不上数据。
2.2 如果有order_info的数据,也有 order_info_detail 的数据,这个时候能够把关联的结果算到最后的结果表里面。
2.3 如果是直接插入数据的情况,left join不会生效,left join的效果和inner join相同。
2.4 update `demo_order_info` set order_info='nihao' where id='1'; 无效
2.5 update `demo_order_info_detail` set order_info_detail='472398' where id=2; 有效,他是会先根据order_info_detail id 进行删除以后再添加。
2.6 update `demo_order_info_detail` set order_info_id='1' where id=2; 只要是修改了order_info_detail的id还有他们的关联条件order_info_id,那么程序就会出错。
结论:
如果涉及到关联操作,除非只有增加操作,不然多表关联就会出现错误。如果在初次全量同步以后,然后再增量的时候减少并行度,对于增量操作是没有影响的(这里的没有影响是断点续传没有影响)。
#上面的结论是mysql到mysql
下面是控制台就能够正常关联
id order_info order_info_id id0 order_info_detail
5 wo shi 5 5 5 wo ye shi 5
3 3 3 3 nihao
6 wo shi 5
2 orderinfo2
11 orderinfo1
到 mysql 通过 flinkcdc 到 kafka 的数据
-- canal-json
-- insert
-- {"data":[{"id":13,"order_info":"nihao"}],"type":"INSERT"}
-- {"data":[{"id":11,"order_info":"订单y"}],"type":"INSERT"}
-- csv
-- debezium-json
-- insert
-- {"before":null,"after":{"id":2,"order_info":"订单2"},"op":"c"}
-- update
-- {"before":{"id":2,"order_info":"订单2"},"after":null,"op":"d"}
-- {"before":null,"after":{"id":2,"order_info":"修改了"},"op":"c"}
-- delete
-- {"before":{"id":1,"order_info":"订单y"},"after":null,"op":"d"}
-- json
-- maxwell-json
-- {"data":{"id":13,"order_info":"不知道"},"type":"delete"}
-- {"data":{"id":13,"order_info":"nihao"},"type":"insert"}
-- ogg-json
-- raw Flink整合StreamPark相关配置
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.tolerable-failed-checkpoints: 30
execution.checkpointing.unaligned: false
state.backend: rocksdb
state.checkpoints.dir: hdfs://localhost:8020/flink-checkpoints
state.savepoints.dir: hdfs://localhost:8020/flink-savepoints
state.backend.incremental: true
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(CommonString.CHECKPOINT_TIME); // 每1分钟触发一次检查点
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 设置检查点模式为仅一次
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(CommonString.MIN_PASUE_BETWEEN_CHECKPOINTS); // 设置两个检查点之间的最小暂停时间
env.getCheckpointConfig().setCheckpointTimeout(CommonString.CHECKPOINT_TIMEOUT); // 设置检查点超时时间为2分钟
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 设置同时进行的最大检查点数量为1
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
在和kafka精确一次整合的时候,记得事务的超时时间要是检查点触发时间和超时时间之和才行不然会出错,还有就是
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "2000"); 不能使用默认值,不然事务运行会出错
#提交yarn任务
/home/bigdata/soft/flink-1.15.0/flink-1.15.4/bin/flink run \
-d \
-m yarn-cluster \
-yqu high \
-ynm appname \
-c com.bigdata.testApp \
bigdata-1.0-SNAPSHOT.jar
#保存检查点
/home/bigdata/soft/flink-1.15.0/flink-1.15.4/bin/flink savepoint db37d764dec3dff2051ed330be4a61d7(flink的jobid) hdfs://localhost:8020/flink-savepoints -yid application_123(yarn 容器id)
#停止yarn上的flink任务并且保存一个指定的保存点
/home/bigdata/soft/flink-1.15.0/flink-1.15.4/bin/flink stop db37d764dec3dff2051ed330be4a61d7 --savepointPath hdfs://localhost:8020/flink-savepoints -yid application_123s
#指定保存点运行
/home/bigdata/soft/flink-1.15.0/flink-1.15.4/bin/flink run \
-d \
--fromSavepoint hdfs://localhost:8020/flink-savepoints/savepoint-db37d7-690a0b97620d \
-m yarn-cluster \
-yqu high \
-ynm appname \
-c com.bigdata.testApp \
bigdata-1.0-SNAPSHOT.jar
#日常检查
yarn application -kill
yarn logs -applicationId application_1686709637666_1261
#重要事项,checkpoint不能小于1分钟timeout设置成2分钟,不然会出现意想不到的错误。 Flink TaskManager 内存管理机制介绍与调优总结-腾讯云开发者社区-腾讯云
堡垒机安装使用
https://blog.csdn.net/weixin_43279138/article/details/124441644
Python脚本模板
python执行hive
#!/usr/bin/env python
# coding=utf-8
# -*- coding=utf-8
import sys
import logging
import json
import datetime
import os
for item in range(66,1,-1):
today_time = (datetime.datetime.now()+datetime.timedelta(days=-item)).strftime("%Y-%m-%d")
sql_temp='''
INSERT OVERWRITE TABLE nlp
PARTITION(`load_date`='{}')
select
*
from
(
) as nlp;
quit;
'''.format(today_time)
hive_command="hive -e " + '\"'+sql_temp+'\"'
os.popen(hive_command)
调度器突然出问题
【异常解决】DolphinScheduler-2.0.5 工作流实例无法调度和停止异常_北溟小鱼123的博客-CSDN博客
【异常解决】DolphinScheduler-2.0.5 工作流实例无法调度和停止异常_北溟小鱼123的博客-CSDN博客
调度器源码编译
dolphinscheduler/docs/docs/en/contribute/development-environment-setup.md at dev · apache/dolphinscheduler · GitHub任务一直正在执行状态解决办法
#找到重复的任务
SELECT code ,version,COUNT(*) cnt from t_ds_task_definition_log group by code ,version order by cnt desc;
show create table t_ds_task_definition_log
#查找相同code的id,然后删除最后 一个
select id,code from t_ds_task_definition_log where code = '8488618187744';
#删除最后一个,保证唯一
delete from t_ds_task_definition_log where id= '97';Shorten the command line via JAR manifest or via a classpath file and rerun.

Docker
安装mysql(测试用)
docker run -p 3307:3306 --name mysql1 --restart always -di -v /root/mysql/mysql.conf.d/:/etc/mysql/mysql.conf.d/ -v /root/mysql/data/:/var/lib/mysql -v /root/mysql/log/:/var/log -e MYSQL_ROOT_PASSWORD=123456z mysql:5.7Flink
flinkcdc
配置文件中状态后端配置flink-conf.yaml
execution.checkpointing.interval: 5min
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.max-concurrent-checkpoints: 2
execution.checkpointing.min-pause: 10000
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.timeout: 5min
execution.checkpointing.tolerable-failed-checkpoints: 5
execution.checkpointing.unaligned: false
state.backend: rocksdb
state.checkpoints.dir: hdfs://bigdata:8020/flink-checkpoints
state.savepoints.dir: hdfs://bigdata:8020/flink-savepoints
state.backend.incremental: trueNode
nvm list available
https://www.freecodecamp.org/chinese/news/nvm-for-windows-how-to-download-and-install-node-version-manager-in-windows-10/
github仓库下载
https://github.com/coreybutler/nvm-windows#installation--upgrades
安装指定版本的node
nvm install 14.17.0
查看本地机器所有的node
nvm list
使用指定版本的node
nvm use 14.17.0StreamPark编译
apache-incubator-streampark源码编译本地运行-腾讯云开发者社区-腾讯云

flink写入kafka中文乱码问题
env.java.opts: "-Dfile.encoding=UTF-8"K8S
nohup ./node_exporter --web.listen-address=:9101 &
https://www.yuque.com/leifengyang/oncloud/ctiwgo
https://www.kubesphere.io/zh/docs/v3.3/installing-on-linux/introduction/multioverview/
https://kubernetes.io/zh-cn/docs/concepts/overview/
#sudo iptables -F
#sudo iptables -X
sudo iptables -t nat -F
sudo iptables -t nat -X
sudo systemctl restart docker
kubesphere和hadoop一块部署的时候不会影响hadoop会影响之前部署的docker应用
#创建k8s集群(生成配置文件)
./kk create config --with-kubernetes v1.23.10 --with-kubesphere v3.3.0
#创建集群
./kk create cluster -f config-sample.yaml
./kk delete cluster -f config-sample.yaml比较有意思的项目
基于电影知识图谱的智能问答系统(一) -- Mysql数据准备_nosql 问答系统_appleyk的博客-CSDN博客
Demo:基于 Flink SQL 构建流式应用 | Jark's Blog
https://www.cnblogs.com/chanshuyi/category/1862951.html
监控数据可视化 - prometheus-book
Grafana 使用表格面板进行数据可视化-grafana 表格
告警
Grafana alert预警+钉钉通知_grafana钉钉告警_AI强仔的博客-CSDN博客
飞书
如何使用机器人指令
Grafana 连接器
Flink监控
一口气搞懂「Flink Metrics」监控指标和性能优化,全靠这33张图和7千字(建议收藏) - 掘金