java基础






















































![]()




















目录
-
- 基础
-
-
- 语言概述
-
- 计算机的高级编程语言类型:
- 字符编码表
- 转义和注释
- JUnit
- 自增
-
- 面试题
- 可变参数
- 正则表达式
- 基本功
-
- 进制
- 原、反、补码
- 位运算符
- 静态导入
- Lambda
- 关键字
-
- 修饰符
- this和super区别
- final
- finalize
- 易混淆
-
- 符号辨析
- length
- Scanner
- clone与copy的区别
- Shallow Clone与Deep Clone
- 如何实现对象克隆?
- 取模运算:异号时看第一个符号
- 重写和重载【辨析】
- Integer比较
- 两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
- 内部类可以引用它的包含类(外部类)的成员吗?有没有什么限制?
- try{}里有一个 return 语句,那么紧跟在这个 try 后的finally{}里的代码会不会被执行,什么时候被执行,在 return前还是后?
- 阐述 final、finally、finalize 的区别。
- 异常
- 数据类型
-
- 概述
- 整型细节
- 浮点数细节
- 字符类型
-
- char 型变量中能不能存贮一个中文汉字,为什么?
- String
-
- *split方法*
- *创建对象*
- 【== 和 equals】
- 测试题
- *string vs stringbuffer*
- *String不可变好处*
- *【String、StringBuffer、StringBuilder之间的区别】*
- 类型转化
-
- 自动转换(低精度-》高精度)
- 强制类型转换(高精度——》低精度)
- 拆装箱
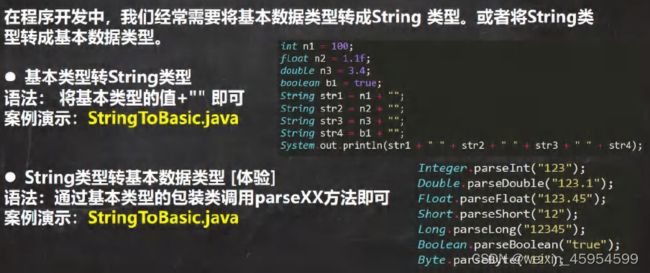
- 基本类型和Stirng互转
- short s1 = 1; s1 = s1 + 1;错
- Java 中如何实现序列化,有什么意义?
- 构造器
- 类加载
-
- java内存
- 解释内存中的栈(stack)、堆(heap)和方法区(method area)的用法
- 1、类被加载的时机
- 2、同一个类中,先静态->普通->构造
- 3、不同类中
- 4、大综合(☆)
- 描述一下JVM 加载class 文件的原理机制?
- 数组
- 集合Collection接口
-
- List接口
-
- 特性
- 实现类
- Set接口
-
- 特性
- 实现类
- HashSet
- Map 接口
-
- 介绍
- HashMap小结
- TreeMap
- HashTable
- Properties
- 选用集合实现类
- List、Set、Map 是否继承自 Collection 接口?
- Collection 和 Collections
- TreeMap 和 TreeSet 在排序时如何比较元素?Collections 工具类中的 sort()方法如何比较元素?
- 泛型
-
- 好处
- 使用细节
- 自定义泛型类
- 自定义泛型接口
- 自定义泛型方法
- 泛型的继承和通配符
- 抽象类
- 接口
- 接口 VS 继承
-
-
- 抽象的不可是静态的,不可是本地方法(native),不可被 synchronized修饰?
-
- 内部类
-
- 1.局部内部类
- 2.匿名内部类
- 3.成员内部类
- 4.静态内部类
- 枚举
-
- 1.自定义实现
- 2 enum 关键字实现枚举
- 对象
-
- **类和对象的内存分配机制**
- Java 创建对象的流程简单分析
- 对象创建流程分析(带构造器)
- Java 内存的结构分析
- 方法调用机制原理
- 基本类型传参机制
- 引用数据类型的传参机制
- 当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
- 克隆
- 多态
-
- 多态的向上转型
- 多态的向下转型
- 动态绑定机制(非常重要)
-
- 规则
- **例子**
- 多线程
-
- 三种创建方式
- 五大状态
- 方法
- 并发
- 互斥锁
- 线程池
- Thread 类的 sleep()方法和对象的 wait()方法都可以让线程暂停执行,它们有什么区别?
- 线程的 sleep()方法和 yield()方法有什么区别?
- 举例说明同步和异步
- 启动一个线程是调用 run()还是 start()方法?
- 什么是线程池(thread pool)?
- 简述 synchronized 和 java.util.concurrent.locks.Lock的异同?
- 注解
-
- 内置注解
- 元注解
- 自定义注解
- 反射
-
- java在计算机的三个阶段
- 获取Class对象方式
- Class对象功能
- 案例☆
- 异常
- 流
-
-
- Java 中有几种类型的流?
- 写一个方法,输入一个文件名和一个字符串,统计这个字符串在这个文件中出现的次数。
- 异常
-
-
- 数据库
-
-
- sql
-
- 1.什么是SQL ?
- SQL通用语法
- 注释
- mysql
- 操作指令
-
- 1.操作数据车: CRUD
- 2、操作表
- 3、操作数据
- 查询DQL语句
- 约束
- 多表关系
-
- 一对一
- 一对一关系
- 多对多
- 范式
-
- 概念
- 瑕疵表
- 1、消除部分依赖后[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D21zURFs-1645968588698)(java基础.assets/image-20210605112216086.png)]
- 2、消除传递依赖后
- 多表查询
-
- 1、内连接查询
- 2、外连接查询
- 3、子查询
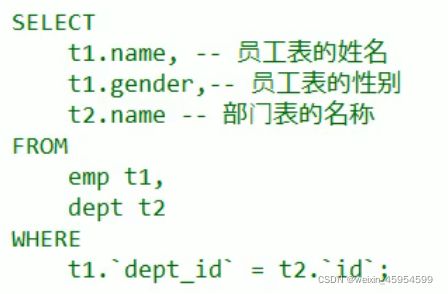
- 自连接查询例子
- 事务
- DCL
- jdbc
-
- PreparedStatement
- 数据库连接池
-
- 概念:
- 好处:
- 实现:
- C3P0:数据库连接池技术
- Druid:数据库连接池实现技术,由阿里巴巴提供的
- Spring JDBC
-
- java web
-
-
- 网络通信三要素
- tomcat
-
- 部署项目的方式:
- 访问路径
- js 基础
-
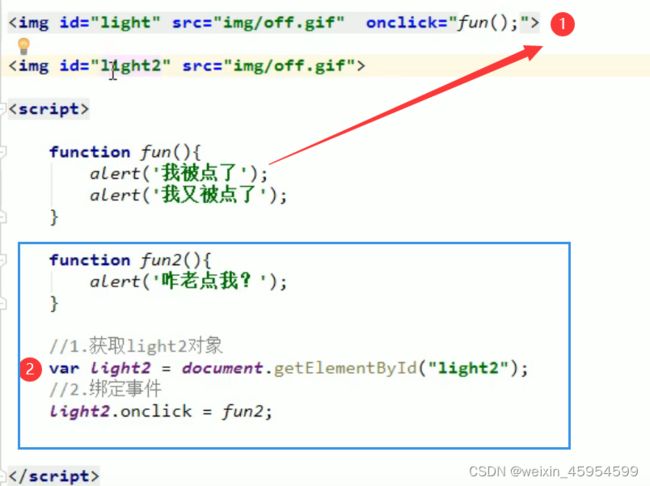
- 方法
- 绑定事件
- jquery
-
- JQuery对象和JS对象区别与转换
- attr和prop区别?
- 对class属性操作
- 插件:增强JQuery的功能
- jquery下的ajax
- bom
-
- 组成:
- Window:窗口对象
- Location:地址栏对象
- History:历史记录对象
- xml
-
- 1、概念:
- 3、解析:操作xml文档,将文档中的数据读取到内存中
- 4、快捷查询方式:
- json 与 java对象互转
-
- json-——>java
- java——>json
- servlet
-
- 执行原理:
- Servlet中的生命周期方法:
- 重定向和请求转发
- jsp
- Session 和 Cookie
- redis
-
- 1、概念
- redis的应用场景
- redis的数据结构:
- 持久化
- Java客户端 Jedis
- jedis连接池: JedisPool
- redis注意事项
- maven
-
- 生命周期
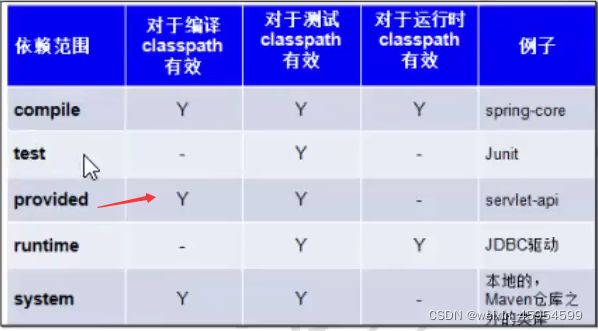
- 依赖范围
- jsp
- Session 和 Cookie
- redis
-
- 1、概念
- redis的应用场景
- redis的数据结构:
- 持久化
- Java客户端 Jedis
- jedis连接池: JedisPool
- redis注意事项
- maven
-
- 生命周期
- 依赖范围
-
基础
语言概述
C语言:
- 极好的福利:贴近硬件, 运行极快, 效率极高。
- 两个沉重的枷锁: 指针和内存管理
c++:
太复杂。 图形和游戏领域表现好
java:
为了实现跨平台, 我们在操作系统和应用程序之间增加了一个抽象层: Java 虚拟机
java 2 标准版(J2SE): 去占领桌面
Java 2 移动版(J2ME): 去占领手机
Java 2 企业版(J2EE): 去占领服务器 ( 【三高:高可用,高性能,高并发】 )
JAVA的成功除了自己具备跨平台特性外,更重要的是正好踩中了互联网发展的节奏。微软的成功除了windows好用外,也是正好踩中了个人电脑发展的节奏。
计算机的高级编程语言类型:
- 编译型 : 程序执行速度快。因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++
- 解释型.: 而一些网页脚本、服务器脚本及辅助开发接口这样
的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如Java、
JavaScript、Python等等。
Java 语言是两种类型的结合;
java用Unicode
Java是一种强类型语言,每个变量都必须声明其类型。
面试题
比较javascript 和 java
JavaScript 与 Java 是两个公司开发的不同的两个产品。Java 是原 SunMicrosystems 公司推出的面向对象的程序设计语言,特别适合于互联网应用程序开发;而 JavaScript 是 Netscape 公司的产品,为了扩展 Netscape 浏览器的功能而开发的一种可以嵌入 Web 页面中运行的基于对象和事件驱动的解释性语言。JavaScript 的前身是 LiveScript;而 Java 的前身是 Oak 语言。
下面对两种语言间的异同作如下比较:
(1)基于对象和面向对象:Java 是一种真正的面向对象的语言,即使是开发简单的程序,必须设计对象;JavaScript 是种脚本语言,它可以用来制作与网络无关的,与用户交互作用的复杂软件。它是一种基于对象(Object-Based)和事件驱动(Event-Driven)的编程语言,因而它本身提供了非常丰富的内部对象供设计人员使用。
(2)解释和编译:Java 的源代码在执行之前,必须经过编译。JavaScript 是一种解释性编程语言,其源代码不需经过编译,由浏览器解释执行。(目前的浏览器几乎都使用了 JIT(即时编译)技术来提升 JavaScript 的运行效率)
(3)强类型变量和类型弱变量:Java 采用强类型变量检查,即所有变量在编译之前必须作声明;JavaScript 中变量是弱类型的,甚至在使用变量前可以不作声明,JavaScript 的解释器在运行时检查推断其数据类型。
(4)代码格式不一样。
补充:上面列出的四点是网上流传的所谓的标准答案。其实 Java 和 JavaScript最重要的区别是一个是静态语言,一个是动态语言。目前的编程语言的发展趋势是函数式语言和动态语言。在 Java 中类(class)是一等公民,而 JavaScript 中函数(function)是一等公民,因此 JavaScript 支持函数式编程,可以使用 Lambda函数和闭包(closure),当然 Java 8 也开始支持函数式编程,提供了对 Lambda表达式以及函数式接口的支持。对于这类问题,在面试的时候最好还是用自己的语言回答会更加靠谱,不要背网上所谓的标准答案。
字符编码表
-
ASCII (一个字节表示, 一个128个字符,实际上一个字节可以表示256个字符,只用128个)
-
Unicode (两个字节来表示字符,字母和汉字统都是占用两个字节,
这样浪费空间)不会有乱码现象
兼容ASCII码
-
utf-8 (对unicode改进,大小可变的编码,字母使用1个字节,汉字使用3个字节)
-
gbk (可以表示汉字,而且范围广,字母使用1个字节,汉字2个字节)
-
gb2312 (可以表示汉字,gb2312 < gbk)
-
big5码(繁体中文台湾,香港)
怎样将 GB2312 编码的字符串转换为 ISO-8859-1 编码的字符串?
String s1 = "你好";
String s2 = new String(s1.getBytes("GB2312"), "ISO-8859-1");
转义和注释
转义
\r 和 \n 不一样
// /r是回车,\n换行
// 遇到换行时,光标移动到最前面,然后换行后的字符替代当前光标内容
public class ChangeChar{
public static void main(String[] args) {
System.out.println("1234 \r9"); //9234
System.out.println("3\n4");
}
}
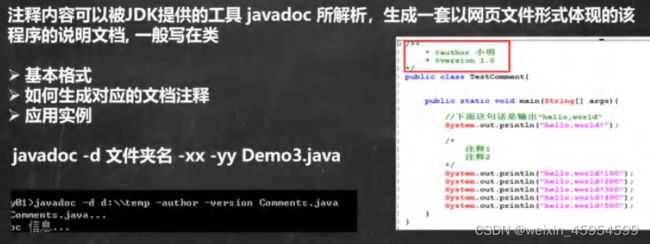
文档注释
javadoc -d (文档保存路径) [-xx] [-yy] (java文件)
JUnit
java单元测试
如果执行@Test。执行顺序,先@Before,再@Test,后@After
即使@Test抛出异常,@Before和@After里面代码块依旧会执行
@Test
public void m1() {
System.out.println("m1 方法被调用");
}
@Before
public void init() {
System.out.println("初始化资源");
}
@After
public void After() {
System.out.println("关闭资源");
}
自增
面试题
int i = 1;
i = ++i;
System.out.println(i); //i为2
int i = 1;
i = i++;
System.out.println(i); //i为1
【解析】
========== i=++i; 底层
(1) i=i+ 1;
(2) temp=i;
(3) i=temp:
=========== i=i++;底层
_temp = i;
i = i + 1;
i = _temp;
==========类似
int y = x++
底层源码:
_temp = x;
x = x + 1;
y = _temp;
可变参数
-
可变参数的实参可以为0个或任意多个。实参可以为数组。
-
可变参数的本质就是数组.
-
可变参数可以和普通类型的参数一起放在形参列表,但必须保证可变参数在最后
-
一个形参列表中只能出现一个可变参数
下面写法错误
public void f3(int… nums1, double… nums2) { }
正则表达式
-
正则表达式:定义字符串的组成规则。
-
单个字符:[]
如: [a] [ab] [a-zA-Z0-9_]
特殊符号代表特殊含义的单个字符:
\d:单个数字字符 [0-9]
\w:单个单词字符[a-zA-Z0-9_] -
量词符号:
?:表示出现0次或1次
*:表示出现0次或多次
+:出现1次或多次
{m,n}:表示 m<= 数量 <= n- m如果缺省: {,n}:最多n次
- n如果缺省:{m,} 最少m次
-
开始结束符号
- ^:开始
- $:结束
- 正则对象:
- 创建
- var reg = new RegExp(“正则表达式”);
- var reg = /正则表达式/;
- 方法
- test(参数):验证指定的字符串是否符合正则定义的规范
基本功
进制
二进制:以0b 或0B 开头。
十进制:
八进制:以数字0 开头表示。
十六进制: 以0x 或0X 开头表示。此处的A-F 不区分大小写
原、反、补码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tRH6nulx-1645968588651)(D:\09__my-JAVA\学习笔记\java基础.assets\image-20210423123914671.png)]
位运算符
java 中有7 个位运算(&、|、^、~、>>、<<和>>>)
1)算术右移>>:符号位不变,并用符号位补溢出的高位
2) 算术左移<<: 符号位不变,低位补0
3) >>> 逻辑右移也叫无符号右移,运算规则是**: 高位补0**
4) 特别说明:没有<<< 符号
静态导入
好处:简化操作(建议在有很多重复调用的时候使用)
import static java.lang.Math.random;
import static java.lang.Math.PI;
public class Test {
public static void main(String[] args) {
//之前是需要Math.random()调用的
System.out.println(random());
System.out.println(PI);
}
}
Lambda
概述
- Lambda 表达式是 JDK8 的一个新特性,可以取代大部分的匿名内部类,写出更优雅的 Java 代码,尤其在集合的遍历和其他集合操作中,可以极大地优化代码结构。
- Lambda 规定接口中只能有一个需要被实现的方法,不是规定接口中只能有一个方法。
- jdk 8 中有另一个新特性:default, 被 default 修饰的方法会有默认实现,不是必须被实现的方法,所以不影响 Lambda 表达式的使用。
语法
语法形式为 () -> {},其中 () 用来描述参数列表,{} 用来描述方法体,-> 为 lambda运算符
代码示例
/**无参无返回值*/
@FunctionalInterface
public interface NoReturnNoParam {
void method();
}
//无参无返回
NoReturnNoParam noReturnNoParam = () -> {
System.out.println("NoReturnNoParam");
};
noReturnNoParam.method();
/**一个参数无返回*/
@FunctionalInterface
public interface NoReturnOneParam {
void method(int a);
}
//一个参数无返回
NoReturnOneParam noReturnOneParam = (int a) -> {
System.out.println(a);
};
noReturnOneParam.method(6);
/**多参数无返回*/
@FunctionalInterface
public interface NoReturnMultiParam {
void method(int a, int b);
}
//多个参数无返回
NoReturnMultiParam noReturnMultiParam = (int a, int b) -> {
System.out.println( a+b);
};
noReturnMultiParam.method(6, 8);
//========= 有返回 =========
/*** 无参有返回*/
@FunctionalInterface
public interface ReturnNoParam {
int method();
}
//无参有返回值
ReturnNoParam returnNoParam = () -> {
System.out.print("ReturnNoParam");
return 1;
};
int res = returnNoParam.method();
System.out.println( res);
/**一个参数有返回值*/
@FunctionalInterface
public interface ReturnOneParam {
int method(int a);
}
/**多个参数有返回值*/
@FunctionalInterface
public interface ReturnMultiParam {
int method(int a, int b);
}
//多个参数有返回值
ReturnMultiParam returnMultiParam = (int a, int b) -> {
System.out.println( a + b );
return 1;
};
int res3 = returnMultiParam.method(6, 8);
System.out.println("return:" + res3);
简化
//1.简化参数类型,可以不写参数类型,但是必须所有参数都不写
NoReturnMultiParam lamdba1 = (a, b) -> {
System.out.println("简化参数类型");
};
lamdba1.method(1, 2);
//2.简化参数小括号,如果只有一个参数则可以省略参数小括号
NoReturnOneParam lambda2 = a -> {
System.out.println("简化参数小括号");
};
lambda2.method(1);
//3.简化方法体大括号,如果方法条只有一条语句,则可以省略方法体大括号
NoReturnNoParam lambda3 = () -> System.out.println("简化方法体大括号");
lambda3.method();
//4.如果方法体只有一条语句,并且是 return 语句,则可以省略方法体大括号
ReturnOneParam lambda4 = a -> a+3;
System.out.println(lambda4.method(5));
ReturnMultiParam lambda5 = (a, b) -> a+b;
System.out.println(lambda5.method(1, 1));
关键字
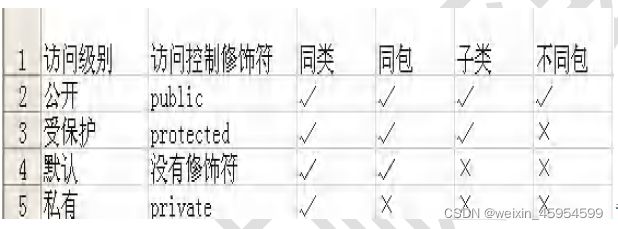
修饰符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QP0FeDca-1645968588653)(java基础.assets/image-20210512104632611.png)]
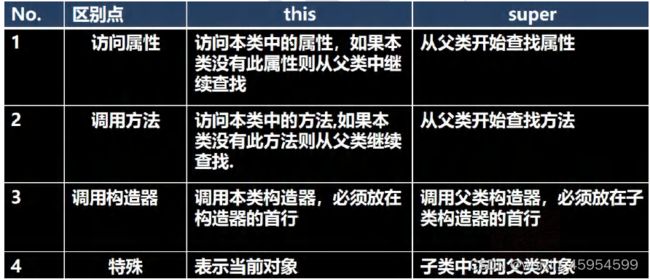
this和super区别
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2txslOXR-1645968588655)(java基础.assets/image-20210512121646393.png)]
final
final可以修饰类、属性、方法和局部变量.
- final修饰的属性在定义时,必须赋初值,并且以后不能再修改,赋值可以在如下位置之一【(选择一个位置赋初值即可】:
- 定义时:如public final double TAX_RATE=0.08;
- 在构造器中
- 在代码块中。
2)如果final修饰的属性是静态的,则初始化的位置只能是
- 定义时
- 在静态代码块
- 不能在构造器中赋值。
- final类不能继承,但是可以实例化对象。
4)如果类不是final类,但是含有final方法,则该方法虽然不能重写,但是可以被继承。
5)一般来说,如果一个类已经是final类了,就没有必要再将方法修饰成final方法。
- final不能修饰构造方法(即构造器)
7)final和static往往搭配使用,效率更高,不会导致类加载.底层编译器做了优化处理。
8)包装类(Integer,Double,Float,Boolean等都是final),String也是final类。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EcJ1VCKx-1645968588656)(java基础.assets/image-20210517152521202.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uFLUfG3w-1645968588656)(java基础.assets/image-20210517152637549.png)]
finalize
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vd98Yirl-1645968588657)(java基础.assets/image-20210513154316755.png)]
易混淆
全局变量可以不赋值,有默认值。局部变量必须赋值
属性可加修饰符,局部变量不可以
接口可以继承接口,而且支持多重继承。抽象类可以实现(implements)接口,抽象类可继承具体类也可以继承抽象类。
匿名内部类可以继承其它类,可以实现其他接口
符号辨析
-
&&与&和|| 与 |
&&:短路运算
eg: 例如,对于 if(str != null&& !str.equals(“”))表达式,当 str 为 null 时,后面的表达式不会执行,所以不会出现 NullPointerException
如果将&&改为&,则会抛出 NullPointerException 异常。
&: 当&操作符两边的表达式不是 boolean 类型时, &表示按位与操作 -
<< 与 <<< (0填充空位)
A = 0011 1100
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eJByKTF0-1645968588658)(java基础.assets/1612089791013.png)]
右移一位相当于除2取商。右移n位相当于除2n取商
左移一位相当于乘2。左移n位相当于x2 n
【常见面试题:int a=2*8怎样运算效率最快?】
用 int a = 2<<3
length
数组没有 length()方法
JavaScript 和 数组有 length 的属性。
String 有 length()方法。
Scanner
- next():
读取到有效字符后才可以结束输入,对输入有效字符之前遇到的空格键、Tab键或Enter键等结束符,next()方法会自动将其去掉,只有在输入有效字符之后,next()方法才将其后输入的空格键、Tab键或Enter键等视为分隔符或结束符。 - nextLine():
结束符只是Enter键,即nextLine()方法返回的是Enter键之前的所有字符,它是可以得到带空格的字符串的.
Scanner scanner = new Scanner(System.in);
String s = scanner.nextLine();
scanner.next();
如果在控制台上输入” hello” ,则nextLine打印出来的是” hello”,而next是 “hello”,自动舍去了有效字符前的空格。
clone与copy的区别
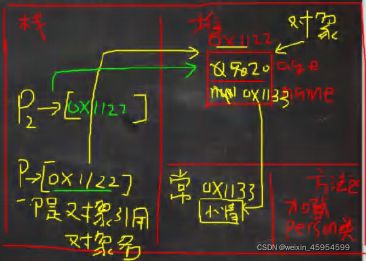
Employee tobby =new Employee(“CMTobby”,5000)
Employee cindyelf=tobby
只是简单了copy了一下reference, cindyelf和tobby都指向内存中同一个object,这样cindyelf或者tobby的一个操作都可能影响到对方。
我们希望得到tobby的一个精确拷贝,同时两者互不影响,这时候, 我们就可以使用Clone来满足我们的需求
Employee cindy=tobby.clone(),
这时会生成一个新的Employee对象,并且和tobby具有相同的属性值和方法。
Shallow Clone与Deep Clone
JAVA里除了8种基本类型传参数是值传递,其他的类对象传参数都是引用
调用Clone()方法的对象所属的类(Class)必须implements Clonable接口,否则在调用Clone方法的时候会抛出CloneNotSupportedException
如何实现对象克隆?
有两种方式:
1). 实现 Cloneable 接口并重写 Object 类中的 clone()方法;
2). 实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆
**注意:**基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用 Object 类的 clone 方法克隆对象。让问题在编译的时候暴露出来总是好过把问题留到运行时。
取模运算:异号时看第一个符号
负数%负数=负数;
负数%正数=负数;
正数%负数=正数;
重写和重载【辨析】
| 区别点 | 重载 overloading | 重写 overriding | |
|---|---|---|---|
| 1 | 定义 | 方法名称相同,参数的类型或个数不同 | 方法名称、参数的类型、返回值类型全部相同 |
| 2 | 权限 | 对权限没有要求 | 被重写的方法不能拥有比父类更加严格的权限 |
| 3 | 范围 | 发生在一个类中 | 发生在继承中 |
Integer比较
class AutoUnboxingTest {
public static void main(String[] args) {
Integer a = new Integer(3);
Integer b = 3;// 将 3 自动装箱成 Integer 类型
int c = 3;
System.out.println(a == b);// false 两个引用没有引用同一对象
System.out.println(a == c); // true a 自动拆箱成 int 类型再和 c比较
}
}
public class Test03 {
public static void main(String[] args) {
Integer f1 = 100, f2 = 100, f3 = 150, f4 = 150;
System.out.println(f1 == f2); // T
System.out.println(f3 == f4); // F
}
}
简单的说,如果整型字面量的值在-128 到 127 之间,那么不会 new 新的 Integer对象,而是直接引用常量池中的 Integer 对象,所以上面的面试题中 f1f4 的结果是 false。
两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
不对,如果两个对象 x 和 y 满足 x.equals(y) == true,它们的哈希码(hash code)应当相同。Java 对于 eqauls 方法和 hashCode 方法是这样规定的:
(1)如果两个对象相同(equals 方法返回 true),那么它们的 hashCode 值一定要相同;
(2)如果两个对象的 hashCode 相同,它们并不一定相同。
当然,你未必要按照要求去做,但是如果你违背了上述原则就会发现在使用容器时,相同的对象可以出现在 Set 集合中,同时增加新元素的效率会大大下降(对于使用哈希存储的系统,如果哈希码频繁的冲突将会造成存取性能急剧下降)。
内部类可以引用它的包含类(外部类)的成员吗?有没有什么限制?
一个内部类对象可以访问创建它的外部类对象的成员,包括私有成员。
try{}里有一个 return 语句,那么紧跟在这个 try 后的finally{}里的代码会不会被执行,什么时候被执行,在 return前还是后?
会执行,在方法返回调用者前执行。
阐述 final、finally、finalize 的区别。
1) final:修饰符(关键字)有三种用法:如果一个类被声明为 final,意味着它不能再派生出新的子类,即不能被继承,因此它和 abstract 是反义词。将变量声明为 final,可以保证它们在使用中不被改变,被声明为 final 的变量必须在声明时给定初值,而在以后的引用中只能读取不可修改。被声明为 final 的方法也同样只能使用,不能在子类中被重写。
(2)finally:通常放在 try…catch…的后面构造总是执行代码块,这就意味着程序无论正常执行还是发生异常,这里的代码只要 JVM 不关闭都能执行,可以将释放外部资源的代码写在 finally 块中.
(3)finalize:Object 类中定义的方法,Java 中允许使用 finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在销毁对象时调用的,通过重写 finalize()方法可以整理系统资源或者执行其他清理工作。
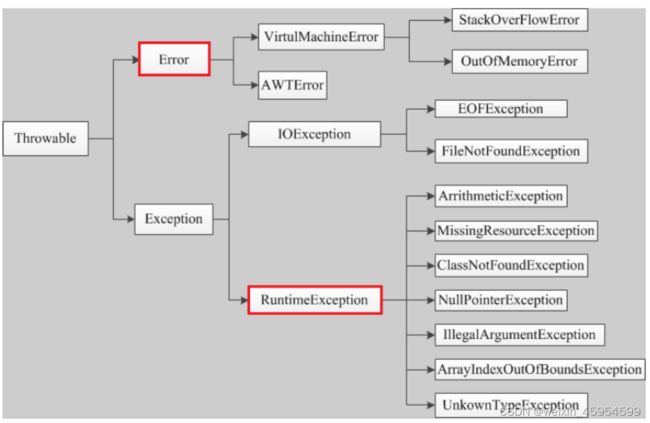
异常
抓取 ExampleA 类型异常的 catch 块能够抓住 try 块中抛出的 ExampleB 类型的异常)
抓到异常后就不再执行后面try
class ExampleA extends Exception {
}
class ExampleB extends ExampleA {
public ExampleB(String s) {
System.out.println(s);
}
}
public class CatchOrder {
public static void main(String[] args) throws ExampleB {
try {
throw new ExampleB("b");
} catch(ExampleA e){
System.out.println("ExampleA");
}
catch(Exception e){
System.out.println("Exception");
}
}
}
输出 b
ExampleA
数据类型
概述
java 数据类型分为两大类基本数据类型,引用类型
- 基本数据类型有8中―数值型[byte , short , int , long , float ,double] char , boolean
- 引用类型[类,接口,数组]
1字节: byte、boolean
2字节:char、short
4字节:int【默认】、float
8字节:long、double【默认】
整型细节
Java各整数类型有固定的范围和字段长度,不受具体OS[操作系统]的影响,以保证java程序的可移植性。
浮点数细节
-
关于浮点数在机器中存放形式的简单说明
浮点数=符号位+指数位+尾数位
尾数部分可能丢失,造成精度损失(小数都是近似值)。 -
浮点型常量有两种表示形式
(1)十进制数形式:如:5.12 512.0f.512(必须有小数点)
(2)科学计数法形式:如:5.12e2 [5.12*10的2次方]5.12E-2[5.12/10的2次方] -
通常情况下,应该使用double型,因为它比float型更精确。[举例说明]
double num9 =2.1234567851;
float num10 = 2.1234567851F; // 会丢失一些位数 -
浮点数使用陷阱:2.7和8.1/3比较
double num7=2.7;
double num8=8.1/3; //2.9999…997他两不等
当我们对运算结果是小数的进行相等判断是,要小心
应该是以两个数的差值的绝对值,在某个精度范围类判断
比较相等一般用Math.abs(num7 - num8)<0.00001
如果是直接查询得的的小数或者直接赋值,是可以判断相等
字符类型
在java中,char的本质是一个整数,在输出时,是unicode码对应的字符。
可以直接给char赋一个整数,然后输出时,会按照对应的unicode字符输出[97-》a]
char类型是可以进行运算的,相当于一个整数,因为它都对应有Unicode码.
char 型变量中能不能存贮一个中文汉字,为什么?
char 类型可以存储一个中文汉字,因为 Java 中使用的编码是 Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号,这是统一的唯一方法),一个 char 类型占 2 个字节(16 比特),所以放一个中文是没问题的。
补充:使用 Unicode 意味着字符在 JVM 内部和外部有不同的表现形式,在 JVM内部都是 Unicode,当这个字符被从 JVM 内部转移到外部时(例如存入文件系统中),需要进行编码转换。所以 Java 中有字节流和字符流,以及在字符流和字节流之间进行转换的转换流,如 InputStreamReader 和 OutputStreamReader,这两个类是字节流和字符流之间的适配器类,承担了编码转换的任务;
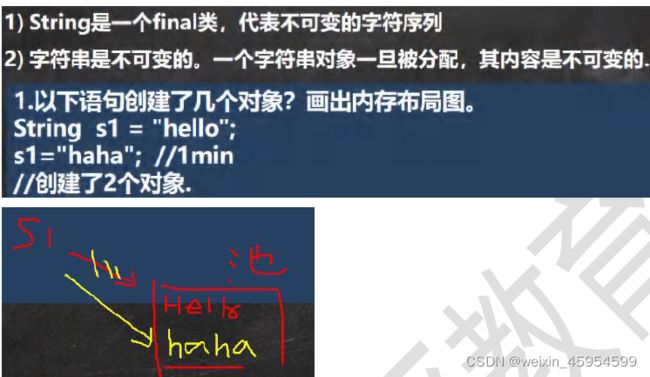
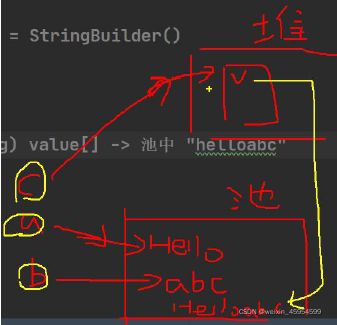
String
split方法
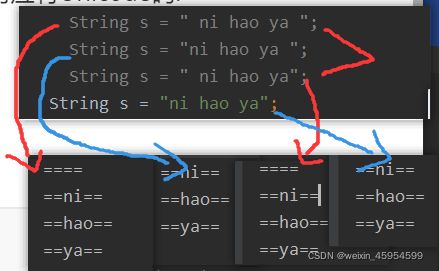
public static void count(String s){
String srr [] = s.split(" ");
for (int i = 0; i < srr.length; i++) {
System.out.println("=="+srr[i]+"==");
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTLBL5Cc-1645968588660)(java基础.assets/image-20210606195225442.png)]
总结:左边有几个空格,split后就会存几个“”,最后的空格不论多少个都不记录
创建对象
(1)对象在方法区的常量池
String str="1 hello";//直接赋值的方式
(2)对象在堆内存
String str=new String("hello");//实例化的方式
【总结】
-
直接赋值(String str = “hello”):只开辟一块堆内存空间,并且会自动入池,不会产生垃圾。
-
构造方法(String str= new String(“hello”);):会开辟两块堆内存空间,其中一块堆内存会变成垃圾被系统回收,而且不能够自动入池,需要通过public String intern();方法进行手工入池。
String str =new String("Lance").intern();//进行手工入池操作 -
在开发的过程中不会采用构造方法进行字符串的实例化。
【== 和 equals】
String中==在对字符串比较的时候,对比的是内存地址。
equals比较字符串内容
测试题
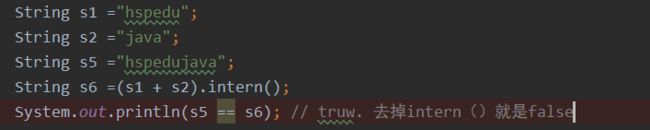
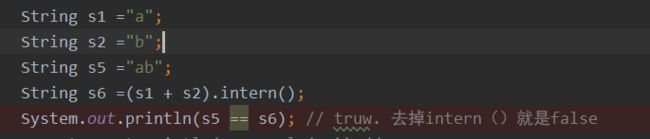
intern
常量池不同值
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-emAz2h55-1645968588661)(java基础.assets/image-20210621084005984.png)]
对象属性
对象创建问题
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KD1CWeM8-1645968588661)(java基础.assets/image-20210519161051442.png)]
【重点】执行方法会在栈中重新开辟一块空间
string vs stringbuffer
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jz5g9MCM-1645968588662)(java基础.assets/image-20210519172143219.png)]
String不可变好处
- 可以实现多个变量引用堆内存中的同一个字符串实例,避免创建的开销。
- 我们的程序中大量使用了String字符串,有可能是出于安全性考虑。
- HashMap中key为String类型,如果可变将变的多么可怕。
- 当我们在传参的时候,使用不可变类不需要去考虑谁可能会修改其内部的值,如果使用可变类的话,可能需要每次记得重新拷贝出里面的值,性能会有一定的损失。
【String、StringBuffer、StringBuilder之间的区别】
String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
在大多数情况下三者在执行速度方面的比较:StringBuilder > StringBuffer > String
从1拼接到8万耗时
StringBuffer 的执行时间:50
StringBuilder 的执行时间:27
string 的执行时间:7215
对于三者使用的总结:
1)如果要操作少量的数据用 = String
2)单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
3)多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
类型转化
自动转换(低精度-》高精度)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IGsiXKY2-1645968588663)(java基础.assets/image-20210422204706095.png)]
- (byte, short)和char之间不会相互自动转换。Boolean不参与转化
- byte, short, char他们三者可以计算,在计算时首先转换为int类型。
强制类型转换(高精度——》低精度)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ckzooTzv-1645968588664)(java基础.assets/image-20210422205414632.png)]
拆装箱
装箱:由基本类型向对应的包装类转换
拆箱:包装类向对应的基本类型转换
jdk1.5后课自动拆装箱(编译器帮忙)
int m = 0;
Integer obj = m; //自动装箱
int n = obj; //自动拆箱
所有的包装类(Integer、Long、Byte、Double、Float、Short)都是抽象类 Number 的子类。
【1、 实现 int 和 Integer 的相互转换】
int m = 500;
Integer obj = new Integer(m); // 手动装箱
int n = obj.intValue(); // 手动拆箱
基本类型和Stirng互转
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-du6FAPlx-1645968588665)(java基础.assets/image-20210422205842368.png)]
【面试题】
Integer i1 = new Integer(127);
Integer i2 = new Integer(127);
System.out.println(i1 == i2);//F
Integer i5 = 127;//底层Integer.valueOf(127)
Integer i6 = 127;//-128~127
System.out.println(i5 == i6); //T
Integer i9 = 127; //Integer.valueOf(127)
Integer i10 = new Integer(127);
System.out.println(i9 == i10);//F
Integer i13=128;
int i14=128;
System.out.println(i13==i14);//T
short s1 = 1; s1 = s1 + 1;错
short s1 = 1; s1 += 1; 对
对于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 类型,因此 s1+1 运算结果也是 int型,需要强制转换类型才能赋值给 short 型。
而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short(s1 + 1);其中有隐含的强制类型转换。
Java 中如何实现序列化,有什么意义?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。
序列化是为了解决对象流读写操作时可能引发的问题(如果不进行序列化可能会存在数据乱序的问题)。要实现序列化,需要让一个类实现 Serializable 接口,该接口是一个标识性接口,标注该类对象是可被序列化的,然后使用一个输出流来构造一个对象输出流并通过 writeObject(Object)方法就可以将实现对象写出(即保存其状态);如果需要反序列化则可以用一个输入流建立对象输入流,然后通过 readObject 方法从流中读取对象。序列化除了能够实现对象的持久化之外,还能够用于对象的深度克隆
构造器
-
构造器是完成对象的初始化,不是创建对象
-
显示定义构造器后,就不能用默认无参构造器,除非显示定义无参构造器
this()可访问构造器:只能在构造器中访问另一个构造器,必须放在第一条语句位置
######构造器不能被继承,因此不能被重写,但可以被重载。
类加载
java内存
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-toyre8X9-1645968588666)(java基础.assets/image-20210602092516723.png)]
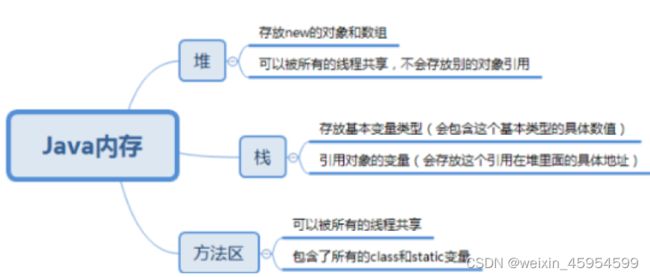
解释内存中的栈(stack)、堆(heap)和方法区(method area)的用法
通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用 JVM 中的栈空间;
通过 new 关键字和构造器创建的对象则放在堆空间
程序中的字面量(literal)如直接书写的 100、”hello”和常量都是放在常量池中,常量池是方法区的一部分
方法区和堆都是各个线程共享的内存区域,用于存储已经被 JVM 加载的类信息、常量、静态变量、JIT 编译器编译后的代码等数据
栈空间操作起来最快但是栈很小,通常大量的对象都是放在堆空间
String str = new String("hello");
上面的语句中变量 str 放在栈上,用 new 创建出来的字符串对象放在堆上,而”hello”这个字面量是放在方法区的。
补充 1:较新版本的 Java(从 Java 6 的某个更新开始)中,由于 JIT 编译器的发展和”逃逸分析”技术的逐渐成熟,栈上分配、标量替换等优化技术使得对象一定分配在堆上这件事情已经变得不那么绝对了。
补充 2:Java 语言并不要求常量一定只有编译期间才能产生,*运行期间也可以将新的常量放入池中,String类的 intern()*方法就是这样的。
看看下面代码的执行结果是什么并且比较一下 Java 7 以前和以后的运行结果是否一致。
1、类被加载的时机
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2odhfC7D-1645968588667)(java基础.assets/image-20210517102946779.png)]
2、同一个类中,先静态->普通->构造
一个类中,先静态的【先父后子】,【按照父和子类分别执行下面】再普通的,再构造
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cluf5hYU-1645968588668)(java基础.assets/image-20210517104603587.png)]
3、不同类中
父类静态,子类静态
父类普通、构造
子类普通、构造
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k7IMbTnd-1645968588669)(java基础.assets/image-20210517105330530.png)]
class AAA { //父类Object
{
System.out.println("AAA 的普通代码块");
}
public AAA() {
//(1)super()
//(2)调用本类的普通代码块
System.out.println("AAA() 构造器被调用....");
}
}
class BBB extends AAA {
{
System.out.println("BBB 的普通代码块...");
}
public BBB() {
//(1)super()
//(2)调用本类的普通代码块
System.out.println("BBB() 构造器被调用....");
}
}
public static void main(String[] args) {
new BBB();//(1)AAA 的普通代码块(2)AAA() 构造器被调用(3)BBB 的普通代码块(4)BBB() 构造器被 调用
}
4、大综合(☆)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xTR0ZuTb-1645968588670)(java基础.assets/image-20210517111023531.png)]
【案例】
class A02 { //父类
private static int n1 = getVal01();
static {
System.out.println("A02 的一个静态代码块..");//(2)
}
{
System.out.println("A02 的第一个普通代码块..");//(5)
}
public int n3 = getVal02();//普通属性的初始化
public static int getVal01() {
System.out.println("getVal01");//(1)
return 10;
}
public int getVal02() {
System.out.println("getVal02");//(6)
return 10;
}
public A02() {//构造器
//隐藏
//super()
//普通代码和普通属性的初始化......
System.out.println("A02 的构造器");//(7)
}
}
class B02 extends A02 { // 子类
private static int n3 = getVal03();
static {
System.out.println("B02 的一个静态代码块..");//(4)
}
public int n5 = getVal04();
{
System.out.println("B02 的第一个普通代码块..");//(9)
}
public static int getVal03() {
System.out.println("getVal03");//(3)
return 10;
}
public int getVal04() {
System.out.println("getVal04");//(8)
return 10;
}
//一定要慢慢的去品..
public B02() {//构造器
//隐藏了
//super()
//普通代码块和普通属性的初始化...
System.out.println("B02 的构造器");//(10)
// TODO Auto-generated constructor stub
}
}
class C02 {
private int n1 = 100;
private static int n2 = 200;
private void m1() {
}
private static void m2() {
}
static {
//静态代码块,只能调用静态成员
//System.out.println(n1);错误
System.out.println(n2);//ok
//m1();//错误
m2();
}
{
//普通代码块,可以使用任意成员
System.out.println(n1);
System.out.println(n2);//ok
m1();
m2();
}
}
测试
public class CodeBlockDetail04 {
public static void main(String[] args) {
//老师说明
//(1) 进行类的加载
//1.1 先加载父类A02 1.2 再加载B02
//(2) 创建对象
//2.1 从子类的构造器开始
//new B02();//对象
new C02();
}
}
class A {
static {
System.out.print("1");
}
public A() {
System.out.print("2");
}
}
class B extends A{
static {
System.out.print("a");
}
public B() {
System.out.print("b");
}
}
public class Hello {
public static void main(String[] args) {
A ab = new B(); // 1a2b
ab = new B(); // 2b
// 执行结果:1a2b2b
}
}
描述一下JVM 加载class 文件的原理机制?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-suYYSDb8-1645968588672)(java基础.assets/image-20210621085735682.png)]
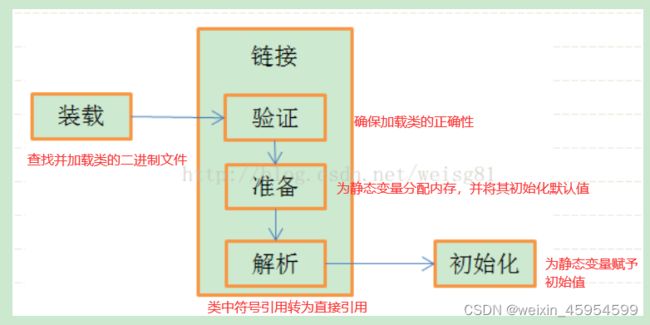
类的加载过程
JVM将类加载过程分为三个步骤:装载(Load),链接(Link)和初始化(Initialize)
数组
数组中元素可以是基本类型,也可是引用类型,但不可混用
集合Collection接口
1)可以动态保存任意多个对象,使用比较方便!
2)提供了一系列方便的操作对象的方法:add、remove、set、get等
3)使用集合添加,删除新元素的示意代码-简洁了
Java 的集合类很多,主要分为两大类,如图:[背下来]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c4liXZw9-1645968588672)(java基础.assets/image-20210525201045084.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IfkaPxi2-1645968588673)(java基础.assets/image-20210525201108483.png)]
List接口
特性
里面元素有序(存入和取出顺序一致),且可重复
支持索引
遍历:迭代器、增强for循环、for
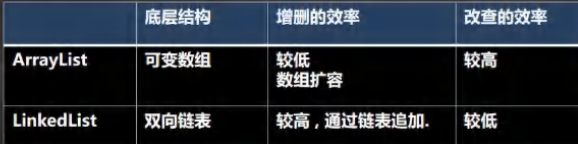
实现类
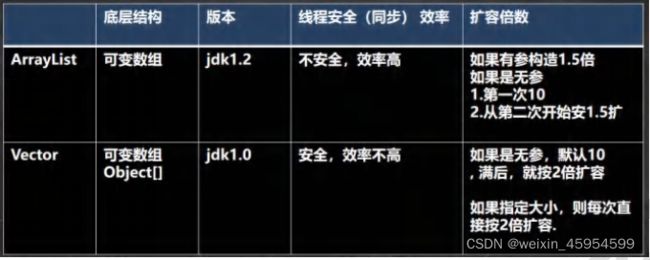
-
1、ArrayList
ArrayList基本和vector等同,除了ArrayList是线程不安全的(执行效率高)
-
2、LinkedList
1)LinkedList底层实现了双向链表和双端队列特点
2)可以添加任意元素(元素可以重复),包括null
3)线程不安全,没有实现同步
-
3、vector
线程同步
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UxUGuPO9-1645968588674)(java基础.assets/image-20210525220342526.png)]
Set接口
特性
1)无序(添加和取出的顺序不一致),没有索引
2)不允许重复元素,所以最多包含一个null
3)遍历方种:迭代器、增强for循环【不能用索引遍历】
实现类
- 1、HashSet
底层是HashMap,HashMap底层是(数组+链表+红黑树)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K60Nfhwh-1645968588674)(java基础.assets/image-20210525221352812.png)]
HashSet
// String 的 equals 比较值
set.add(new String("hsp"));//ok
set.add(new String("hsp"));//加入不了.
// 对象 的 equals 如果没重写就继承object类,比较地址
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//Ok
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P5mmjKZr-1645968588675)(java基础.assets/image-20210526162647820.png)]
重写hashCode和equals方法
class Employee {
private String name;
private int age;
// 省略构造、set、get等方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age &&
Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
- 2、LinkedHashSet
- LinkedHashSet是 HashSet的子类
2)LinkedHashSet底层是一个 LinkedHashMap,底层维护了一个数组+双向链表 - LinkedHashSet根据元素的 hashCode值来决定元素的存储位置,同时使
用链表维护元素的次序(图),这使得元素看起来是以插入顺序保存的。 - LinkedHashSet不允许添重复元素
- 3、TreeSet
//1. 当我们使用无参构造器,创建TreeSet 时,仍然是无序的
//2. 老师希望添加的元素,按照字符串大小来排序
//3. 使用TreeSet 提供的一个构造器,可以传入一个比较器(匿名内部类)
// 并指定排序规则
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面调用String 的compareTo 方法进行字符串大小比较
//如果要求加入的元素,按照长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();
}
});
//添加数据.
treeSet.add("jack");
Map 接口
介绍
注意:这里讲的是JDK8的Map接口特点 Map_.java
1)Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value
2) Map 中的key 和value可以是任何引用类型的数据,会封装到HashMap$Node对象中
3) Map 中的 key 不允许重复,原因和HashSet一样,前面分析过源码.
- Map 中的value可以重复
- Map 的key可以为null, value也可以为null,注意key为null,只能有一个,value为null,可以多个.
6)常用String类作为Map的key - key 和 value之间存在单向一对一关系,即通过指定的key总能找到对应的value
遍历方式
containsKey:查找键是否存在
keySet:获取所有的键
values:获取所有的值
entrySet:获取所有关系k-v
// =========== 1.keySet() ==========
Set keyset = map.keySet();
//(1) 增强for
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
// =========== 2.values() ==========
Collection values = map.values();// 也是增强for或迭代器
// =========== 3.entrySet() ==========
Set entrySet = map.entrySet();// EntrySet>
//(1) 增强for
for (Object entry : entrySet) {
//将entry 转成Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -实现-> Map.Entry (getKey,getValue)
//向下转型Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
HashMap小结
1 ) Map接口常用实现类:HashMap、Hasntable和Properties.
- HashMap是 Map接口使用频率最高的实现类。
- HashMap 是以 key-val对的方式来存储数据(HashMap$Node类型)
4)key不能重复,但是值可以重复,允许使用null键和null值。
5)如果添加相同的key,则会覆盖原来的key-val ,等同于修改.(key不会替换,val会替换)6)与HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的.(jdk8的hashMap底层数组+链表+红黑树) - HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有
synchronized
TreeMap
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照传入的k(String) 的大小进行排序
//按照K(String) 的长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o2).length() - ((String) o1).length();
}
});
treeMap.put("jack", "杰克");
treeMap.put("tom", "汤姆");
treeMap.put("kristina", "克瑞斯提诺");
treeMap.put("smith", "斯密斯");
treeMap.put("hsp", "韩顺平");//加入不了
HashTable
介绍
1)存放的元素是键值对:即K-v
2) hashtable的键和值都不能为null,否则会抛出NullPointerException
- hashTable使用方法基本上和HashMap一样
- hashTable是线程安全的(synchronized), hashMap是线程不安全的
HashTableExercise.javaHashtable table = new Hashtable0;//ok
table.put("john".100); //ok
table.put(null, 100); //异常
table.put("john", null);//异常
table.put("lic" ,100);//oktable.put(" lic",88);//替换System.out.println(table);
Hashtable 和HashMap 对比
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EMbjEEJX-1645968588676)(java基础.assets/image-20210529071213307.png)]
Properties
- Properties继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形
式来保存数据。 - Properties还可以用于从xxx.properties 文件中,加载数据到Properties类对象,
并进行读取和修改
//1. Properties 继承Hashtable
//2. 可以通过k-v 存放数据,当然key 和value 不能为null
//增加
Properties properties = new Properties();
//properties.put(null, "abc");//抛出空指针异常
//properties.put("abc", null); //抛出空指针异常
properties.put("lic", 88);//如果有相同的key , value 被替换
选用集合实现类
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PVXKzqfa-1645968588677)(java基础.assets/image-20210529073227511.png)]
Collections
//我们希望按照字符串的长度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//可以加入校验代码.
return ((String) o2).length() - ((String) o1).length();
}
});
//int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("tom 出现的次数=" + Collections.frequency(list, "tom"));
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
面试
List、Set、Map 是否继承自 Collection 接口?
List、Set 是 ,Map 不是。Map 是键值对映射容器,与 List 和 Set 有明显的区别,而 Set 存储的零散的元素且不允许有重复元素(数学中的集合也是如此),List是线性结构的容器,适用于按数值索引访问元素的情形。
Collection 和 Collections
Collection 是一个接口,它是 Set、List 等容器的父接口;Collections 是个一个工具类,提供了一系列的静态方法来辅助容器操作,这些方法包括对容器的搜索、排序、线程安全化等等。
TreeMap 和 TreeSet 在排序时如何比较元素?Collections 工具类中的 sort()方法如何比较元素?
TreeSet 要求存放的对象所属的类必须实现 Comparable 接口,该接口提供了比较元素的 compareTo()方法,当插入元素时会回调该方法比较元素的大小。
TreeMap 要求存放的键值对映射的键必须实现 Comparable 接口从而根据键对元素进行排序。
Collections 工具类的 sort 方法有两种重载的形式,
- 第一种要求传入的待排序容器中存放的对象实现 Comparable 接口以实现元素的比较;
- 第二种不强制性的要求容器中的元素必须可比较,但是要求传入第二个参数,参数是Comparator 接口的子类型(需要重写 compare 方法实现元素的比较),相当于一个临时定义的排序规则,其实就是通过接口注入比较元素大小的算法,也是对回调模式的应用(Java 中对函数式编程的支持)。
泛型
好处
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zYEdHcS5-1645968588678)(java基础.assets/image-20210529155015094.png)]
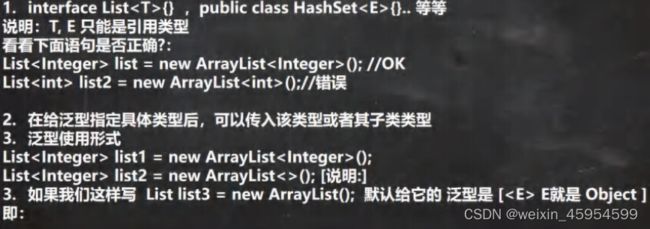
使用细节
- 说明: T, E只能是引用类型
interface List,class HashSet 等等
看看下面语句是否正确?:
List< Integer> list = new ArrayList < Integer> 0); //OK
List<int> list2 = new ArrayList <int> ();//错误
2.在给泛型指定具体类型后,可以传入该类型或者其子类类型
3.泛型使用形式
List<Integer> list1 = new ArrayList < Integer> ();
List< Integer> list2 = new ArrayList<> 0; [说明:]推荐这样写 (简洁)
3.如果我们这样写List list3 = new ArrayList(); 默认给它 E就是Object
自定义泛型类
基本语法
class 类名<T,R...> { } //...表示可以有多个泛型成员
注意细节
1)普通成员可以使用泛型(属性、方法)
2)使用泛型的数组,不能初始化
3)静态方法中不能使用类的泛型(静态是类加载时的,早于创建对象)
4)泛型类的类型,是在创建对象时确定的(因为创建对象时,需要指定确定类型)
5)如果在创建对象时,没有指定类型,默认为Object
自定义泛型接口
➢基本语法
interface 接口名
➢注意细节
1)接口中,静态成员也不能使用泛型(这个和泛型类规定一样)
2)泛型接口的类型,在继承接口或者实现接口时确定
3)没有指定类型,默认为Object
自定义泛型方法
基本语法
修饰符
➢ 注意细节
1.泛型方法,可以定义在普通类中,也可以定义在泛型类中
2.当泛型方法被调用时,类型会确定
3.public void eat(E e) {}, 修饰符后没有
//泛型方法,可以定义在普通类中, 也可以定义在泛型类中
class Car {//普通类
public void run() {//普通方法
}
//说明泛型方法
//1. 就是泛型
//2. 是提供给fly 使用的
public <T, R> void fly(T t, R r) {//泛型方法
System.out.println(t.getClass());//String
System.out.println(r.getClass());//Integer
}
}
class Fish<T, R> {//泛型类
public void run() {//普通方法
}
public<U,M> void eat(U u, M m) {//泛型方法
}
//说明
//1. 下面hi 方法不是泛型方法,因为没有< >
//2. 是hi 方法使用了类声明的泛型
public void hi(T t) {
}
//泛型方法,可以使用类声明的泛型,也可以使用自己声明泛型
public<K> void hello(R r, K k) {
System.out.println(r.getClass());//ArrayList
System.out.println(k.getClass());//Float
}
}
// ========= 测试 =================
public class CustomMethodGeneric {
public static void main(String[] args) {
Car car = new Car();
car.fly("宝马", 100);//当调用方法时,传入参数,编译器,就会确定类型
System.out.println("=======");
car.fly(300, 100.1);//当调用方法时,传入参数,编译器,就会确定类型
//测试
//T->String, R-> ArrayList
Fish<String, ArrayList> fish = new Fish<>();
fish.hello(new ArrayList(), 11.3f);
}
}
泛型的继承和通配符
1)泛型不具备继承性
List错
2) :支持任意泛型类型
3) :支持A类以及A类的子类,规定了泛型的上限
4) :支持A类以及A类的父类,不限于直接父类,规定了泛型的下限
抽象类
1)抽象类不能被实例化
2)抽象类不一定要包含abstract方法。也就是说,抽象类可以没有abstract方法,还可以有实现的方法
3)一旦类包含了abstract方法,则这个类必须声明为abstract
- abstract 只能修饰类和方法,不能修饰属性和其它的。
5)抽象类可以有任意成员【抽象类本质还是类】,比如:非抽象方法.构造器、静态属性等等
6)抽象方法不能有主体,即不能实现
abstract void aaa();
7)如果一个类继承了抽象类,则它必须实现抽象类的所有抽象方法,除非它自己也声明为abstract类。
8)抽象方法不能使用private、final和static来修饰,因为这些关键字都是和重写相违背的.
【抽象类最佳实践——模板设计模式】
抽象类不能new对象,那么抽象类中有没有构造器?
有
接口
接口就是给出一些没有实现的方法,封装到一起,到某个类要使用的时候,在根据具体情况把这些方法写出来。
语法:
interface{
//属性
//抽象方法
}
class 类名 implements 接口{
自己属性;
自己方法;
必须实现接口的抽象方法
}
小结:接口是更加抽象的抽象的类,抽象类里的方法可以有方法体,接口里的所有方法都没有方法体【jdk7.0】。接口体现了程序设计的多态和高内聚低偶合的设计思想。
接口中方法可以省略abstract关键字
【特别说明】:Jdk8.0后接口类可以有静态方法,默认方法,也就是说接口中可以有方法的具体实现,如果是有方法体,用default修饰,则不会报错。
【注意细节】
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cVb2sCQ9-1645968588679)(java基础.assets/image-20210517160447620.png)]
5)一个类同时可以实现多个接口
6)接口中的属性,只能是final的,而且是 public static final修饰符。比如:
int a=1;实际上是public static final int a=1;(必须初始化)
7)接口中属性的访问形式:接口名.属性名
8)接口不能继承其它的类,但是可以继承多个别的接口
interface A extends B,C
9)接口的修饰符只能是 public和默认,这点和类的修饰符是一样的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ztGdfkSH-1645968588680)(java基础.assets/image-20210517162658913.png)]
接口 VS 继承
当子类继承了父类,就自动的拥有父类的功能
如果子类需要扩展功能,可以通过实现接口的方式扩展.
可以理解实现接口是对java 单继承机制的一种补充.
1.接口和继承解决的问题不同
继承的价值主要在于:解决代码的复用性和可维护性。
接口的价值主要在于:设计,设计好各种规范(方法),让其它类去实现这些方法。即更加的灵活.
2.接口比继承更加灵活
继承是满足 is - a的关系,而接口只需满足like - a的关系。
接口在一定程度上实现代码解耦[即:接口规范性+动态绑定机制]
普通类:只有具体实现
抽象类:具体实现和规范(抽象方法) 都有!
接口:只有规范
抽象类也是类,除了可以写抽象方法以及不能直接new对象之外,其他的和普通类没有什么不一样的。接口已经另一种类型了,和类是有本质的区别的,所以不能用类的标准去衡量接口。
同
不能够实例化,但可以定义抽象类和接口类型的引用。
异
抽象类:可以定义构造器,可以有抽象方法和具体方法
接口:不能定义构造器而且其中的方法全部都是抽象方法、成员全都是 public、成员变量实际上都是常量
有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法
抽象的不可是静态的,不可是本地方法(native),不可被 synchronized修饰?
抽象方法需要子类重写,而静态的方法是无法被重写的,因此二者是矛盾的。本地方法是由本地代码(如 C 代码)实现的方法,而抽象方法是没有实现的,也是矛盾的。synchronized 和方法的实现细节有关,抽象方法不涉及实现细节,因此也是相互矛盾的。
内部类
如果定义类在局部位置(方法中/代码块) :(1) 局部内部类(2) 匿名内部类
定义在成员位置(1) 成员内部类(2) 静态内部类
类的五大成员(属性,方法,构造,代码块,内部类)
1.局部内部类
说明:局部内部类是定义在外部类的局部位置,比如方法中,并且有类名。
1.可以直接访问外部类的所有成员,也可访问方法,包含私有的
2.不能添加访问修饰符,因为它的地位就是一个局部变量。局部变量是不能使用
修饰符的。但是可以使用final修饰,因为局部变量也可以使用final
3.作用域:仅仅在定义它的方法或代码块中。
4.局部内部类—访问---->外部类的成员[访问方式:直接访问]
5.外部类—访问---->局部内部类的成员
访问方式:创建对象,再访问(注意:必须在作用域内)
本质仍然是一个类
6.外部其他类—不能访问----->局部内部类(因为局部内部类地位是一个局部变量)
7.如果外部类和局部内部类的成员重名时,默认遵循就近原则,如果想访问外部类的成员,则可以使用**(外部类名.this.成员)**去访问【演示】
System.out.println(“外部类的n2=”+外部类名.this.n2);
2.匿名内部类
访问方式以及作用域等同上
应用
public class Test {
public static void main(String[] args) {
//如果我们需要使用接口中的方法,我们只需要走一步,就是使用匿名内部类,直接将其类的对象创建出来。
new Test1(){
public void method(){
System.out.println("实现了Test接口的方法");
}
}.method();
}
}
interface Test1{
public void method();
}
new Test1(){实现接口中方法的代码}; Test1(){…}这个的作用就是将接口给实
现了,只不过这里实现该接口的是一个匿名类,也就是说这个类没名字,
3.成员内部类
成员内部类区别于前面两种,可以加修饰符,因为他的地位就是一个成员
外部类访问成员内部类
-
第一种:Outer.Inner inObject = outObject.new Inner();
-
第二种:在外部类中,编写一个方法,可以返回内部类对象
eg(一)
public class Outer {
private int id;
public void out(){
System.out.println("这是外部类方法");
}
class Inner{
public void in(){
System.out.println("这是内部类方法");
}
//内部类访问外部类私有的成员变量
public void useId(){
System.out.println(id+3);。
}
//内部类访问外部类的方法
public void useOut(){
out();
}
}
public static void main(String[] args) {
//实例化成员内部类分两步
//1、实例化外部类
Outer outObject = new Outer();
//2、通过外部类调用内部类
Outer.Inner inObject = outObject.new Inner();
//测试
inObject.useId();//打印3,因为id初始化值为0,0+3就为3,其中在内部类就使用了
//外部类的私有成员变量id。
inObject.useOut();//打印:这是外部类方法
}
}
eg(二)
public class Out2 {
class Inner1{
int i = 100;
}
public Inner1 getInner1Instance(){
return new Inner1();
}
}
class T{
public static void main(String[] args) {
Out2 w = new Out2();
Out2.Inner1 I1 = w.getInner1Instance();
System.out.println(I1.i);
}
}
4.静态内部类
和成员内部类很相似,区别在于是否有static修饰,可以加修饰符等
外部类访问成员内部类
-
第一种:Outer.Inner inObject = outObject.Inner();
-
第二种:在外部类中,编写一个方法,可以返回内部类对象
下面的代码哪些地方会产生编译错误?
class Outer {
class Inner {
}
public static void foo() {
new Inner();
}
public void bar() {
new Inner();
}
public static void main(String[] args) {
new Inner();
}
}
**注意:**上面的面试题中 foo和 main 方法都是静态方法,静态方法中没有 this,也就是说没有所谓的外部类对象,因此无法创建内部类对象,如果要在静态方法中创建内部类对象,可以这样做:
new Outer().new Inner();
枚举
1.自定义实现
- 构造器私有化
- 本类内部创建一组对象[四个春夏秋冬]
- 对外暴露对象(通过为对象添加public final static 修饰符,)
- 可以提供get 方法,但是不要提供set
public static final Season SPRING = new Season("春天", "温暖");
public static final Season WINTER = new Season("冬天", "寒冷");
class Season {//类
private String name;
private String desc;//描述
//定义了四个对象, 固定.
public static final Season SPRING = new Season("春天", "温暖");
public static final Season WINTER = new Season("冬天", "寒冷");
public static final Season AUTUMN = new Season("秋天", "凉爽");
public static final Season SUMMER = new Season("夏天", "炎热");
//1. 将构造器私有化,目的防止直接new
//2. 去掉setXxx 方法, 防止属性被修改
//3. 在Season 内部,直接创建固定的对象
//4. 优化,可以加入final 修饰符
private Season(String name, String desc) {
this.name = name;
this.desc = desc;
}
public String getName() {
return name;
}
public String getDesc() {
return desc;
}
@Override
public String toString() {
return "Season{" +
"name='" + name + '\'' +
", desc='" + desc + '\'' +
'}';
}
}
// ======== 测试 =================
public class Enumeration02 {
public static void main(String[] args) {
System.out.println(Season.AUTUMN);
System.out.println(Season.SPRING);
}
}
2 enum 关键字实现枚举
【注意事项】
-
当我们使用enum 关键字开发一个枚举类时,默认会继承Enum 类, 而且是一个final 类[如何证明],使用javap 工具来演示
-
传统的public static final Season2 SPRING = new Season2(“春天”, “温暖”); 简化成SPRING(“春天”, “温暖”), 这里必须知道,它调用的是哪个构造器.
-
如果使用无参构造器创建枚举对象,则实参列表和小括号都可以省略
-
当有多个枚举对象时,使用,间隔,最后有一个分号结尾
-
枚举对象必须放在枚举类的行首.
SPRING("春天", "温暖"), WINTER("冬天", "寒冷"), AUTUMN("秋天", "凉爽"),
SUMMER("夏天", "炎热")/*, What()*/;
//演示使用enum 关键字来实现枚举类
enum Season2 {//类
//如果使用了enum 来实现枚举类
//1. 使用关键字enum 替代class
//2. public static final Season SPRING = new Season("春天", "温暖") 直接使用
// SPRING("春天", "温暖") 解读常量名(实参列表)
//3. 如果有多个常量(对象), 使用,号间隔即可
//4. 如果使用enum 来实现枚举,要求将定义常量对象,写在前面
//5. 如果我们使用的是无参构造器,创建常量对象,则可以省略()
SPRING("春天", "温暖"), WINTER("冬天", "寒冷"), AUTUMN("秋天", "凉爽"),
SUMMER("夏天", "炎热")/*, What()*/;
private String name;
private String desc;//描述
private Season2() {//无参构造器
}
private Season2(String name, String desc) {
this.name = name;
this.desc = desc;
}
public String getName() {
return name;
}
public String getDesc() {
return desc;
}
@Override
public String toString() {
return "Season{" +
"name='" + name + '\'' +
", desc='" + desc + '\'' +
'}';
}
}
// ======== 测试 ================
public class Enumeration03 {
public static void main(String[] args) {
System.out.println(Season2.AUTUMN);
System.out.println(Season2.SUMMER);
}
}
枚举不能再继承其他类,但可以实现其他接口
class Test{
public static void main(String[] args) {
Enum.e.play();
}
}
public enum Enum implements I{
e;
@Override
public void play() {
System.out.println("play in enum");
}
}
interface I{
void play();
}
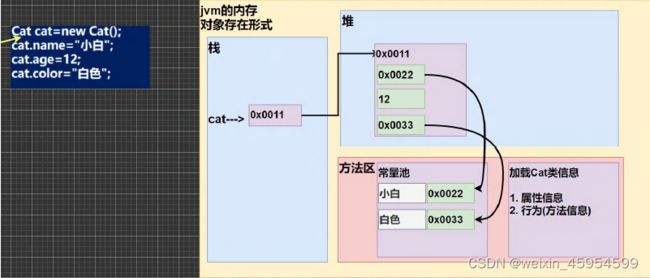
对象
从概念或叫法上看: 成员变量= 属性= field(字段)
类和对象的内存分配机制
内存图如下:
Java 创建对象的流程简单分析
Person p = new Person();
p.name = “jack”;
p.age = 10
-
先加载Person 类信息(属性和方法信息, 只会加载一次)
-
在堆中分配空间, 进行默认初始化(看规则)
-
把地址赋给p , p 就指向对象
-
进行指定初始化, 比如p.name =”jack” p.age = 10
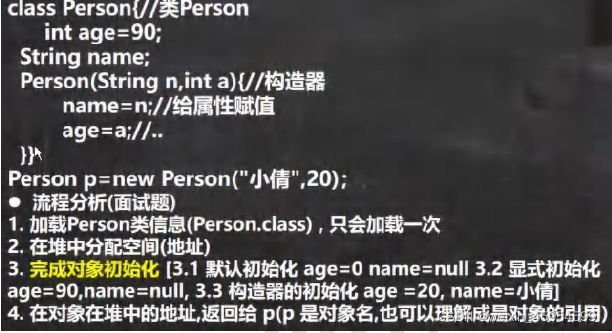
对象创建流程分析(带构造器)
先执行age=90再执行构造器里的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-auAIxWgq-1645968588681)(java基础.assets/image-20210506180239855.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MYfqEjp8-1645968588681)(java基础.assets/image-20210506180323088.png)]
Java 内存的结构分析
- 栈: 一般存放基本数据类型(局部变量)
- 堆: 存放对象(Cat cat , 数组等)
- 方法区:常量池(常量,比如字符串), 类加载信息
方法调用机制原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uTEjRPcG-1645968588682)(java基础.assets/image-20210429150357078.png)]
如果方法是void,则方法体中可以没有return 语句,或者只写return ;
重点
基本类型传参机制
传递的是值,形参的改变不影响实参
class AA {
public void swap(int a,int b){
//完成了a 和b 的交换
int tmp = a;
a = b;
b = tmp;
}
}
public class MethodParameter01 {
public static void main(String[] args) {
int a = 10;
int b = 20;
AA obj = new AA();
obj.swap(a, b); //调用swap
System.out.println("main 方法a=" + a + " b=" + b);//a=10 b=20
}
}
引用数据类型的传参机制
【其实也是值,只不过值是地址】
注意,test01 和 test02 是一类,test03 和 test04 是一类
class Person {
String name;
int age;
}
class B {
// ============ 1
public void test01(int[] arr) {
arr[0] = 200;//修改元素
}
// ============ 2
public void test02(Person p) {
p.age = 10000;
}
// ============ 3
public void test03(Person p) {
p = null;
}
// ============ 4
public void test04(Person p){
p = new Person();
p.name = "tom";
p.age = 99;
}
}
public class Test {
public static void main(String[] args) {
//测试-1
B b = new B();
int[] arr = {1, 2, 3};
b.test01(arr);
// 遍历数组, 输出 200,2,3
//测试-2
Person p = new Person();
p.name = "jack";
p.age = 10;
b.test02(p);
System.out.println("main 的p.age=" + p.age);//10000
b.test03(p) //此时age=10传进去
System.out.println("main 的p.age=" + p.age);//10
b.test04(p) //此时age=10传进去
System.out.println("main 的p.age=" + p.age);//10
}
}
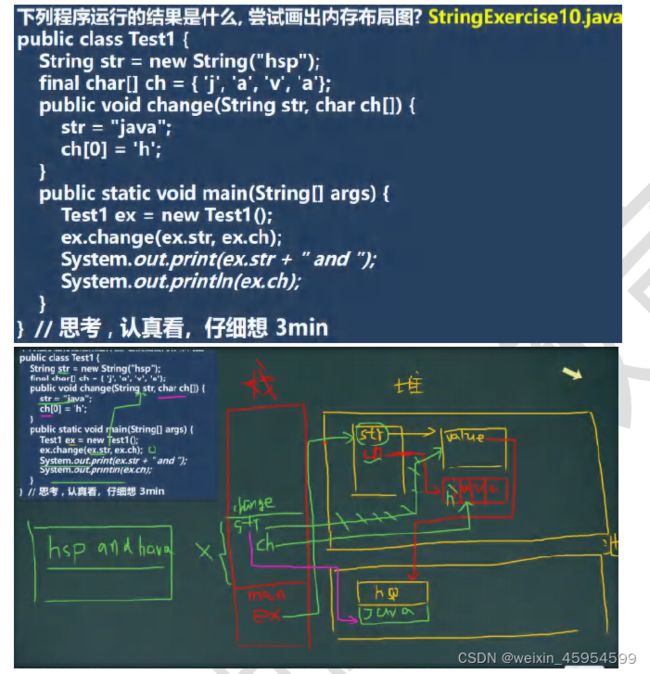
当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
是值传递。Java 语言的方法调用只支持参数的值传递。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的属性可以在被调用过程中被改变,但对对象引用的改变是不会影响到调用者的
public static void main(String[] args) {
String s1 = "Programming";
String s2 = new String("Programming");
String s3 = "Program";
String s4 = "ming";
String s5 = "Program" + "ming";
String s6 = s3 + s4;
System.out.println(s1 == s2); //no
System.out.println(s1 == s5); // yes
System.out.println(s1 == s6); // false
System.out.println(s1 == s6.intern()); // yes
System.out.println(s2 == s2.intern()); // on
}
克隆
java的克隆分为深克隆和浅克隆:
了解克隆clone我们必须要了解
1.首先,要了解什么是克隆,怎么实现克隆。
2.其次,你要大概知道什么是地址传递,什么是值传递。
3.最后,你要知道你为什么使用这个clone方法
Cloneable接口的作用:
Object类中的clone()是protected的方法,在没有重写Object的clone()方法且没有实现Cloneable接口的实例上调用clone方法,会报CloneNotSupportedException异常。
实现Cloneable接口仅仅是用来指示Object类中的clone()方法可以用来合法的进行克隆,即实现了Cloneable接口在调用Object的clone方法时不会再报CloneNotSupportedException异常。
clone方法:
类在重写clone方法的时候,要把clone方法的属性设置为public。
为什么需要克隆?
在实际编程过程中,会需要创建与已经存在的对象A的值一样的对象B,但是是与A完全独立的一个对象,即对两个对象做修改互不影响,这时需要用克隆来创建对象B。通过new一个对象,然后各个属性赋值,也能实现该需求,但是clone方法是native方法,native方法的效率一般远高于非native方法。
怎么实现克隆?
在要克隆的类要实现Cloneable接口和**重写Object的clone()**方法。
浅克隆
对于Object类中的clone()方法产生的效果是:现在内存中开辟一块和原始对象一样的内存空间,然后原样拷贝原始对象中的内容。对基本数据类型来说,这样的操作不会有问题,但是对于非基本类型的变量,保存的仅仅是对象的引用,导致clone后的非基本类型变量和原始对象中相应的变量指向的是同一个对象,对非基本类型的变量的操作会相互影响。
结论:
1、克隆一个对象不会调用对象的构造方法。
2、clone()方法有三条规则:
1)x.clone() != x;
2)x.clone().getClass() == x.getClass();
3)一般情况下x.clone().equals(x); 3)不是必须要满足的。
3、对对象基本数据类型的修改不会互相影响,浅克隆对对象非基本数据类型的修改会相互影响,所以需要实现深克隆。
深克隆
深克隆除了克隆自身对象,还对其非基本数据类型的成员变量克隆一遍。
深克隆的步骤:
1、首先克隆的类要实现Cloneable接口和重写Object的clone()方法。
2、在不引入第三方jar包的情况下,可以使用两种方法:
-
1)先对对象进行序列化,紧接着马上反序列化
-
2)先调用super.clone()方法克隆出一个新对象,然后手动给克隆出来的对象的非基本数据类型的成员变量赋值。
在数据结构比较复杂的情况下,序列化和反序列化可能实现起来简单,方法2)实现比较复杂。经测试2)会比1)的执行效率高。
【例子】
浅克隆
对象实现Cloneable接口并重写Object类中的clone()方法
(a)用户信息
public class Person implements Cloneable{
private String name;
private Phone phone;
/**
* 实现Cloneable接口,并重写clone方法
*/
@Override
protected Object clone(){
Person p=null;
try {
/**
* 若要实现深克隆,此处就必须将对象中所有的复合数据类型统统单独复制拷贝一份,
* 但是实际开发中,无法确定对象中复合数据的种类和个数,
* 因此一般不采用此种方式实现深克隆
*/
p = (Person) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return p;
}
// 省略 构造、set、get、toString方法
}
(b)手机信息
public class Phone{
private String number;
private String area;
// 省略 构造、set、get、toString方法
}
(c)测试代码
public static void main(String[] args) {
Person p=new Person("雷小涛", "man", new Phone("123456", "四川成都"));
Person p2=(Person) p.clone();
System.out.println("p:"+p.toString());
System.out.println("p2:"+p2.toString());
p2.setName("leixiaotao");
p2.getPhone().setArea("四川乐山");
System.out.println("-------其中一个对象修改值过后-------");
System.out.println("p:"+p.toString());
System.out.println("p2:"+p2.toString());
}
深度克隆
对象实现Serializable接口,通过对象的序列化和反序列化实现克隆
(a)用户信息类
public class Person implements Serializable{
private static final long serialVersionUID = -3936148364278781089L;
private String name;
private Phone phone;
// 省略 构造、set、get、toString方法
}
(b)手机信息类
public class Phone implements Serializable{
private static final long serialVersionUID = -4482468804013490322L;
private String number;
private String area;
// 省略 构造、set、get、toString方法
}
(c)CloneUtil工具类
public class CloneUtil {
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T object) throws Exception{
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(object);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
// 此处不需要释放资源,说明:调用ByteArrayInputStream或ByteArrayOutputStream对象的close方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
return (T) ois.readObject();
}
}
(d)测试代码
public static void main(String[] args) throws Exception {
Person p=new Person("雷小涛", "man", new Phone("123456", "四川成都"));
// Person p2=(Person) p.clone();
Person p2=CloneUtil.clone(p);
System.out.println("p:"+p.toString());
System.out.println("p2:"+p2.toString());
p2.setName("leixiaotao");
p2.getPhone().setArea("四川乐山");
System.out.println("-------其中一个对象修改值过后-------");
System.out.println("p:"+p.toString());
System.out.println("p2:"+p2.toString());
}
多态
多态性是指允许不同子类型的对象对同一消息作出不同的响应
多态性分为编译时的多态性和运行时的多态性
方法重载(overload)实现的是编译时的多态性(也称为前绑定),而方法重写(override)实现的是运行时的多态性(也称为后绑定)。运行时的多态是面向对象最精髓的东西
要实现多态需要做两件事:
1). 方法重写(子类继承父类并重写父类中已有的或抽象的方法);
2). 对象造型(用父类型引用引用子类型对象,这样同样的引用调用同样的方法就会根据子类对象的不同而表现出不同的行为)。
多态的向上转型
1)本质:父类的引用指向了子类的对象
2)语法:父类类型 引用名= new 子类类型();
3)特点:编译类型看左边,运行类型看右边。
4)可以调用父类中的所有成员(需遵守访问权限),不能调用子类中特有成员;
最终运行效果着子类的具体实现!
多态的向下转型
1)语法: 子类类型 引用名=(子类类型)父类引用
2)只能强转父类的引用,不能强转父类的对象
3)要求父类的引用必须指向的是当前目标类型的对象
4)当向下转型后,可以调用子类类型中所有的成员
动态绑定机制(非常重要)
规则
- 调用对象方法时,该方法会和该对象的内存地址/运行类型绑定
- 调用对象属性时,没有动态绑定机制,哪里声明,哪里使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HO85DfcU-1645968588683)(java基础.assets/image-20210512134700410.png)]
例子
class A {//父类
public int i = 10;
//动态绑定机制:
public int sum() {//父类sum()
// 若再把B中getI()方法注释掉,则 10+10
return getI() + 10;//20 + 10
}
public int sum1() {//父类sum1()
return i + 10;//10 + 10
}
public int getI() {//父类getI
return i;
}
}
class B extends A {//子类
public int i = 20;
public int getI() {//子类getI()
return i;
}
}
public class DynamicBinding {
public static void main(String[] args) {
//a 的编译类型A, 运行类型B
A a = new B();//向上转型
System.out.println(a.sum());// -> 30
System.out.println(a.sum1());//-> 20
}
}
多线程
程序:指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念。
进程:是系统资源分配的单位。执行程序的一次执行过程,它是一个动态的概念。
并发和并行
进程:是操作系统进行资源分配和调度的一个独立单位;
线程:是进程的一个实体,是 CPU 调度和分派的基本单位,是比进程更小的能独立运行的基本单位。
线程的划分尺度小于进程,这使得多线程程序的并发性高;
进程在执行时通常拥有独立的内存单元,而线程之间可以共享内存。
使用多线程的编程通常能够带来更好的性能和用户体验,但是多线程的程序对于其他程序是不友好的,因为它可能占用了更多的 CPU 资源。当然,也不是线程越多,程序的性能就越好,因为线程之间的调度和切换也会浪费 CPU 时间。时下很时髦的 Node.js就采用了单线程异步 I/O 的工作模式。
三种创建方式
(1)实现Runnable接口(重点)☆
(推荐使用:避免单继承局限性,灵活方便,方便同一个对象被多个线程使用)
定义MyRunnable类实现Runnable接口
实现run()方法,编写线程执行体
创建线程对象,调用start()方法启动线程 new Thread(myRunnable).start()
(2)继承Thread类(重点)
自定义线程类继承Thread类
重写run()方法,编写线程执行体
创建线程对象,调用start()方法启动线程 myRunnable.start()
(3)实现Callable接口(了解)
1. 实现Callable接口,需要返回值类型
2. 重写call方法,需要抛出异常
3. 创建目标对象 t1
4. 创建执行服务:ExecutorService ser = Executors.newFixedThreadPool(1);
5. 提交执行:Future<Boolean> result1 = ser.submit(t1);
6. 获取结果:boolean r1 = result1.get()
7. 关闭服务:ser.shutdownNow();
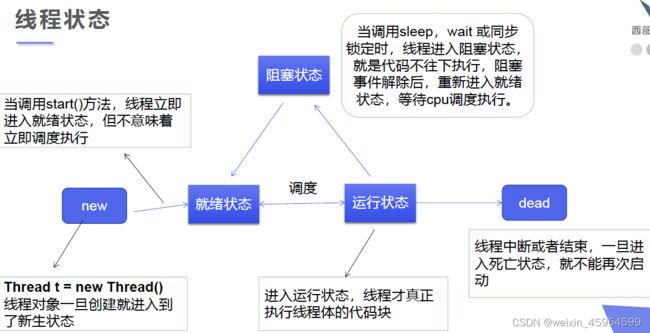
五大状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZcNtAGdH-1645968588684)(java基础.assets/1613904617114.png)]
方法
(1)停止线程
- 不推荐使用JDK提供的 stop()、destroy()方法。【已废弃】
- 推荐线程自己停止下来
- 建议使用一个标志位进行终止变量,当flag=false,则终止线程运行。
public class TestStop implements Runnable {
//1.线程中定义线程体使用的标识
private boolean flag =true;
public void run(){
//2.线程体使用该标识
while (flag){
System.out.println ("run... Thread") ;
}
}
//3.对外提供方法改变标识
public void stop(0){
this.flag =false;
}
}
(2)线程休眠
- sleep时间达到后线程进入就绪状态;
- 每一个对象都有一个锁,sleep不会释放锁;
(3)线程礼让 yield
- 礼让线程,让当前正在执行的线程暂停,但不阻塞
- 将线程从运行状态转为就绪状态
- 让cpu重新调度,礼让不一定成功!看CPU心情
(3)Join
- Join合并线程,待此线程执行完成后,再执行其他线程,其他线程阻塞
- 可以想象成插队
(4)线程优先级
-
线程的优先级用数字表示,范围从1~10.
Thread.MIN_PRIORITY = 1;
Thread.MAX_PRIORITY = 10;
Thread.NORM_PRIORITY = 5; -
使用以下方式改变或获取优先级
getPriority() 、setPriority(int xxx) -
优先级的设定建议在start()调度前
-
优先级低只是意味着获得调度的概率低.并不是优先级低就不会被调用了.这都是看CPU的调度
(5)守护(daemon)线程
- 线程分为用户线程和守护线程
- 虚拟机必须确保用户线程执行完毕
- 虚拟机不用等待守护线程执行完毕
如,后台记录操作日志,监控内存,垃圾回收等待. - setDaemon(true); 先设置。后调用start()
并发
并发 : 同一个对象被多个线程同时操作 eg:同时抢票、取钱
产生死锁的四个必要条件:
-
互斥条件:一个资源每次只能被一个进程使用。
-
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
-
不剥夺条件 : 进程已获得的资源,在末使用完之前,不能强行剥夺。
-
循环等待条件 : 若干进程之间形成一种头尾相接的循环等待资源关系。
思路:同步(队列+锁)
措施:synchronized 方法 和synchronized 块 .
同步块 : synchronized (Obj ) { }
Obj 称之为 同步监视器
Obj 可以是任何对象 , 但是推荐使用共享资源作为同步监视器
同步方法中无需指定同步监视器 , 因为同步方法的同步监视器就是this , 就是这个对象本身 , 或者是 class [ 反射中讲解 ]
缺陷 : 若将一个大的方法申明为synchronized 将会影响效率
Lock
private final ReentrantLock lock = new ReenTrantLock();
public void m(){
lock.lock();
try{
//保证线程安全的代码;
}
finally{
lock.unlock();
//如果同步代码有异常,要将unlock()写入finally语句块
}
}
}
synchronized 与 Lock 的对比
- Lock是显式锁(手动开启和关闭锁,别忘记关闭锁)synchronized是隐式锁,出了作用域自动释放
- Lock只有代码块锁,synchronized有代码块锁和方法锁
- 使用Lock锁,JVM将花费较少的时间来调度线程,性能更好。并且具有更好的扩展性(提供更多的子类)
- 优先使用顺序:
Lock > 同步代码块(已经进入了方法体,分配了相应资源)> 同步方法(在方
法体之外)
线程通信
生产消费者问题
在生产者消费者问题中 , 仅有synchronized是不够的
synchronized 可阻止并发更新同一个共享资源 , 实现了同步
synchronized 不能用来实现不同线程之间的消息传递 (通信)
解决:管程法(生产者将生产好的数据放入缓冲区 , 消费者从缓冲区拿出数据)、信号灯法
Java提供了几个方法解决线程之间的通信问题
| 方法名 |
|---|
| wait() 表示线程一直等待 , 直到其他线程通知 , 与sleep不同 ,会释放锁 |
| notifyAll() 唤醒同一个对象上所有调用wait()方法的线程 , 优先级别高的线程优先调度 |
注意 : 均是Object类的方法 , 都只能在同步方法或者同步代码块中使用,否则会抛出异常IllegalMonitorStateException
#####线程同步
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nMcbsjyr-1645968588685)(java基础.assets/image-20210602075559590.png)]
互斥锁
- Java语言中,引入了对象互斥锁的概念,来保证共享数据操作的完整性
- 每个对象都对应于一个可称为“互斥锁”的标记,这个标记用来保证在任一 时刻,只能有一个线程访问该对象。
- 关键字synchronized来与对象的互斥锁联系。当某个对象用synchronized修饰时,表明该对象在任一时刻只能由一个线程访问
- 同步的局限性:导致程序的执行效率要降低
- 同步方法(非静态的)的锁可以是this,也可以是其他对象(要求是同一个对象)
- 同步方法(静态的)的锁为当前类本身。
//1. public synchronized void sell() {} 就是一个同步方法
//2. 这时锁在this 对象
//3. 也可以在代码块上写synchronize ,同步代码块, 互斥锁还是在this 对象
public synchronized void m1() {}
public void m1() {
synchronized (this) {
}
}
public synchronized static void m1() {}
public static void m2() {
synchronized (SellTicket03.class) {
}
}
线程池
好处:
- 提高响应速度(减少了创建新线程的时间)
- 降低资源消耗(重复利用线程池中线程,不需要每次都创建)
- 便于线程管理(…)
corePoolSize:核心池的大小
maximumPoolSize:最大线程数
keepAliveTime:线程没有任务时最多保持多长时间后会终止
public static void main( Stringl] args) {
//1.创建服务,创建线程池
// newFixedThreadPool参数为;线程池大小
ExecutorService service = Executors.newFixedThreadPool( nThreads: 10);
//执行
service.execute (new MyThread());
service.execute ( new MyThread ( ) ) ;
//2.关闭链接
service. shutdown( );
}
class MyThread implements Runnable{
@override
public void run( ) {
system.out.println(Thread.currentThread ( ).getName() ) ;
}
}
面试
Thread 类的 sleep()方法和对象的 wait()方法都可以让线程暂停执行,它们有什么区别?
sleep()方法(休眠)是线程类(Thread)的静态方法,调用此方法会让当前线程暂停执行指定的时间,将执行机会(CPU)让给其他线程,但是对象的锁依然保持,因此休眠时间结束后会自动恢复(线程回到就绪状态)
wait()是 Object 类的方法,调用对象的 wait()方法导致当前线程放弃对象的锁(线程暂停执行),进入对象的等待池(wait pool),只有调用对象的 notify()方法(或 notifyAll()方法)时才能唤醒等待池中的线程进入等锁池(lock pool),如果线程重新获得对象的锁就可以进入就绪状态。
线程的 sleep()方法和 yield()方法有什么区别?
(1) sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
(2) 线程执行 sleep()方法后转入阻塞(blocked)状态,而执行 yield()方法后转入就绪(ready)状态;
(3)sleep()方法声明抛出 InterruptedException,而 yield()方法没有声明任何异常;
(4)sleep()方法比 yield()方法(跟操作系统 CPU 调度相关)具有更好的可移植性。
举例说明同步和异步
如果系统中存在临界资源(资源数量少于竞争资源的线程数量的资源),例如正在写的数据以后可能被另一个线程读到,或者正在读的数据可能已经被另一个线程写过了,那么这些数据就必须进行同步存取(数据库操作中的排他锁就是最好的例子)。
当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就应该使用异步编程,在很多情况下采用异步途径往往更有效率。
事实上,所谓的同步就是指阻塞式操作,而异步就是非阻塞式操作
启动一个线程是调用 run()还是 start()方法?
启动一个线程是调用 start()方法,使线程所代表的虚拟处理机处于可运行状态,这意味着它可以由 JVM 调度并执行,这并不意味着线程就会立即运行。run()方法是线程启动后要进行回调(callback)的方法。
什么是线程池(thread pool)?
在面向对象编程中,创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。在 Java 中更是如此,虚拟机将试图跟踪每一个对象,以便能够在对象销毁后进行垃圾回收。所以提高服务程序效率的一个手段就是尽可能减少创建和销毁对象的次数,特别是一些很耗资源的对象创建和销毁,这就是”池化资源”技术产生的原因。
线程池顾名思义就是事先创建若干个可执行的线程放入一个池(容器)中,需要的时候从池中获取线程不用自行创建,使用完毕不需要销毁线程而是放回池中,从而减少创建和销毁线程对象的开销。Java 5+中的 Executor 接口定义一个执行线程的工具。它的子类型即线程池接口是 ExecutorService。要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,因此在工具类 Executors 面提供了一些静态工厂方法,生成一些常用的线程池,如下所示:
(1)newSingleThreadExecutor:创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
(2)newFixedThreadPool:创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
(3) newCachedThreadPool:创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60 秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。
(4)newScheduledThreadPool:创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
如果希望在服务器上使用线程池,强烈建议使用 newFixedThreadPool方法来创建线程池,这样能获得更好的性能。
简述 synchronized 和 java.util.concurrent.locks.Lock的异同?
Lock 是 Java 5 以后引入的新的 API,和关键字 synchronized 相比主要相同点:Lock 能完成 synchronized 所实现的所有功能;
主要不同点:Lock 有比synchronized 更精确的线程语义和更好的性能,而且不强制性的要求一定要获得锁。synchronized 会自动释放锁,而 Lock 一定要求程序员手工释放,并且最好在 finally 块中释放(这是释放外部资源的最好的地方)。
注解
Annotation 是从JDK5.0开始引入的新技术 .
Annotation的作用
- 不是程序本身 , 可以对程序作出解释.(这一点和注释(comment)没什么区别)
- 可以被其他程序(比如:编译器等)读取.
我们可以通过反射机制实现对这些元数据的访问
内置注解
- @Override
- @Deprecated
- @SuppressWarnings
public class Test1 extends Object {
//@Override 表示方法重写
@Override
public String toString() {
return super.toString();
}
//方法过时了, 不建议使用 , 可能存在问题 , 并不是不能使用!
@Deprecated
public static void stop(){
System.out.println("测试 @Deprecated");
}
//@SuppressWarnings 抑制警告 , 可以传参数
@SuppressWarnings("all")
public void sw(){
List list = new ArrayList();
}
public static void main(String[] args) {
stop();
}
}
元注解
元注解的作用就是负责注解其他注解 , Java定义了4个标准的meta-annotation类型,他们被用来提供对其他annotation类型作说明 .
这些类型和它们所支持的类在java.lang.annotation包中可以找到.( @Target , @Retention ,
@Documented , @Inherited )
- @Target : 用于描述注解的使用范围(即:被描述的注解可以用在什么地方)
- @Retention : 表示需要在什么级别保存该注释信息 , 用于描述注解的生命周期
(SOURCE < CLASS < RUNTIME) - @Document:说明该注解将被包含在javadoc中
- @Inherited:说明子类可以继承父类中的该注解
自定义注解
使用 @interface自定义注解时 , 自动继承了java.lang.annotation.Annotation接口
分析 :
@ interface用来声明一个注解
格式 : public @ interface 注解名 { 定义内容 }
其中的每一个方法实际上是声明了一个配置参数.
方法的名称就是参数的名称.
返回值类型就是参数的类型 ( 返回值只能是基本类型,Class , String , enum ).
可以通过default来声明参数的默认值
如果只有一个参数成员 , 一般参数名为value
注解元素必须要有值 , 我们定义注解元素时 , 经常使用空字符串,0作为默认值 .
@interface MyAnnotation3{
// 参数类型 参数名称
String value();
}
@Target(value = {ElementType.METHOD})
@Retention(value = RetentionPolicy.RUNTIME)
@interface MyAnnotation2{
//参数类型 , 参数名
String name() default "";
int age() default 0;
int id() default -1; //String indexOf("abc") -1 , 不存在,找不到
String[] schools() default {"西部开源","狂神说Java"};
}
@Target(value = {ElementType.METHOD})
@Retention(value = RetentionPolicy.RUNTIME)
// ============= 测试 =======================
public class Test3 {
//显示定义值 不显示值就是默认值
@MyAnnotation2(age = 18,name = "秦疆",id = 001,schools = {"西工大"})
public void test() {
}
//只有一个参数, 默认名字一般是value.使用可省略不写
@MyAnnotation3("aaa")
public void test2(){
}
}
反射
反射:将类的各个组成部分封装为其他对象,这就是反射机制
好处:
- 1.可以在程序运行过程中,操作这些对象。
- 2.可以解耦,提高程序的可扩展性。
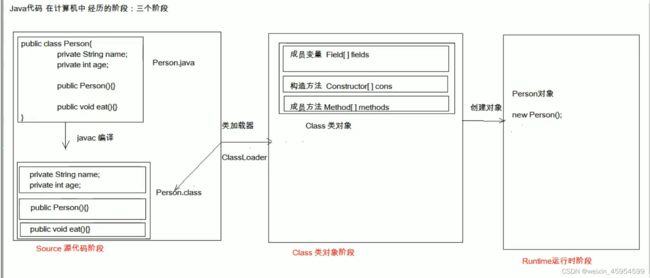
java在计算机的三个阶段
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KLmEcDQX-1645968588687)(java基础.assets/image-20210603173005216.png)]
获取Class对象方式
//1.Class.forName("全类名")
Class cls1 = Class .forName( "cn.Person");
System.out.println(cls1);
//2. 类名.class .
Class cls2 = Person.class;
System.out.println(cls2);
//3.对象.getClass()
Person p = new Person();
Class cls3 = p.getClass();
System.out.println(cls3);
//==比较三个对象
System. out.println(cls1 == cls2);//true
System. out.println(cls1 == cls3);//true
结论:
同一个字节码文件( .class)在一次程序运行过程中, 只会被加载一次, 不论通过哪-种方式获取的Class对象都是同一个。
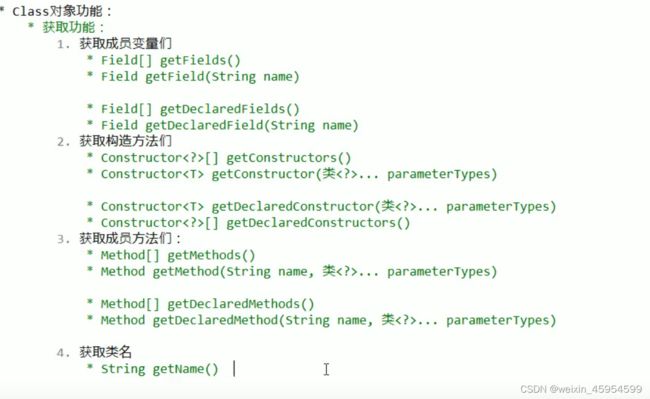
Class对象功能
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qanJblvD-1645968588688)(java基础.assets/image-20210603182759874.png)]
案例☆
【需求】
写一个“框架”,在不改变原有代码情况下,可以创建任意类的对象,并执行其中任意方法(通过修改配置文件)
【实现】
1、reflection包下Person类
package reflection;
public class Person {
public void eat(){
System.out.println("Person # eat");
}
}
2、reflection包下Student类
package reflection;
public class Student {
public void doWork(){
System.out.println("Student # doWork");
}
}
3、src目录下reflect.properties配置文件
className = reflection.Student
methodName = doWork
========= 或者用以下 =============
className = reflection.Person
methodName = eat
4、reflection包下测试反射类
package reflection;
public class ReflectTest {
public static void main(String[] args) throws Exception{
Properties properties = new Properties();
// 获取class目录下配置文件
ClassLoader classLoader = ReflectTest.class.getClassLoader();
InputStream is = classLoader.getResourceAsStream("reflect.properties");
// 加载配置文件
properties.load(is);
// 获取配置文件中数据
String className = (String) properties.get("className");
String methodName = (String) properties.get("methodName");
// 加载该类进内存
Class<?> cls = Class.forName(className);
Object obj = cls.newInstance();
Method method = cls.getMethod(methodName);
method.invoke(obj);
}
}
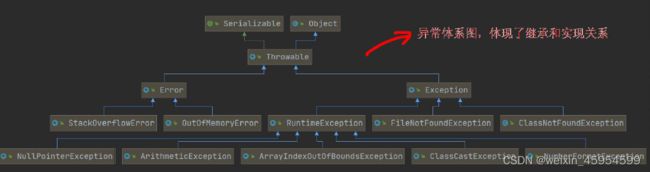
异常
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JaUgUEgn-1645968588689)(java基础.assets/image-20210709131307754.png)]
检查异常( checked exception ):除了Error 和 RuntimeException 的其它异常。
javac 强制要求程序员为这样的异常做预备处理工作(使用try…catch…finally 或者throws )。
非检查异常( unckecked exception ): Error 和 RuntimeException 以及他们的子类
流
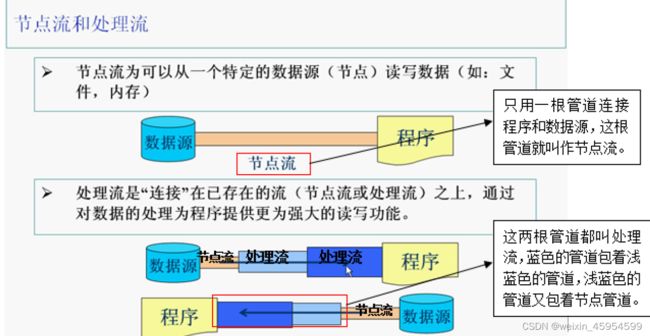
按数据流的方向不同可以分为输入流和输出流
按照处理数据单位不同可以分为字节流和字符流
按照功能不同可以分为节点流和处理流
字节流:最原始的一个流,读出来的数据就是010101这种最底层的数据表示形式,只不过它是照字节来读的,一个字节(Byte)是8位(bit)读的时候不是一个位一个位的来读,而是一个字节一个字节来读。
字符流:字符流是一个字符一个字符地往外读取数据。一个字符是2个字节
- FileInputStream流来读取有中文的内容时,读出来的是乱码,因为使用InputStream流里面的read()方法读取内容时是一个字节一个字节地读取的,而一个汉字是占用两个字节的,所以读取出来的汉字无法正确显示。
- FileReader流来读取内容时,中英文都可以正确显示,因为Reader流里面的read()方法是一个字符一个字符地读取的,这样每次读取出来的都是一个完整的汉字
输入流:InputStream(字节流),Reader(字符流)
输出流:OutPutStream(字节流),Writer(字符流)
面试
Java 中有几种类型的流?
字节流和字符流。字节流继承于 InputStream、OutputStream,字符流继承于Reader、Writer。
在 java.io 包中还有许多其他的流,主要是为了提高性能和使用方便。
关于 Java 的 I/O 需要注意的有两点:一是两种对称性(输入和输出的对称性,字节和字符的对称性);二是两种设计模式(适配器模式和装潢模式)。
写一个方法,输入一个文件名和一个字符串,统计这个字符串在这个文件中出现的次数。
public final class MyUtil {
// 工具类中的方法都是静态方式访问的因此将构造器私有不允许创建对象
// (绝对好习惯)
private MyUtil() {
throw new AssertionError();
}
/**
* 统计给定文件中给定字符串的出现次数
*
* @param filename 文件名
* @param word 字符串
* @return 字符串在文件中出现的次数
*/
public static int countWordInFile(String filename, String word) {
int counter = 0;
try (FileReader fr = new FileReader(filename)) {
try (BufferedReader br = new BufferedReader(fr)) {
String line = null;
while ((line = br.readLine()) != null) {
int index = -1;
while (line.length() >= word.length() && (index =
line.indexOf(word)) >= 0) {
counter++;
line = line.substring(index + word.length());
}
}
}
}
catch (Exception ex) {
ex.printStackTrace();
}
return counter;
}
}
异常
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WdJ2Js2j-1645968588690)(java基础.assets/image-20210518135446184.png)]
编译异常:必须捕获,运行时异常:可以不捕获
try{
int n1 = 10;
int n2 = 1;
System.out.println(n1 / n2);
}finally {
System.out.println("执行了finally..");
}
// n2=0时,此句不打印。 n2!=0时,此句打印
System.out.println("程序继续执行..");
自定义异常
1)定义类:自定义异常类名(程序员自己写)继承Exception或RuntimeException
2)如果继承Exception,属于编译异常
3)如果继承RuntimeException,属于运行异常(一般来说,继承RuntimeException)
public class CustomException {
public static void main(String[] args) /*throws AgeException*/ {
int age = 180;
//要求范围在18 – 120 之间,否则抛出一个自定义异常
if(!(age >= 18 && age <= 120)) {
//这里我们可以通过构造器,设置信息
throw new AgeException("年龄需要在18~120 之间");
}
System.out.println("你的年龄范围正确.");
}
}
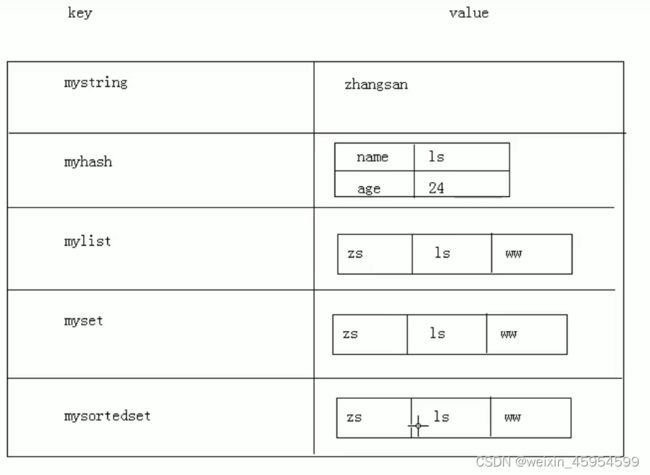
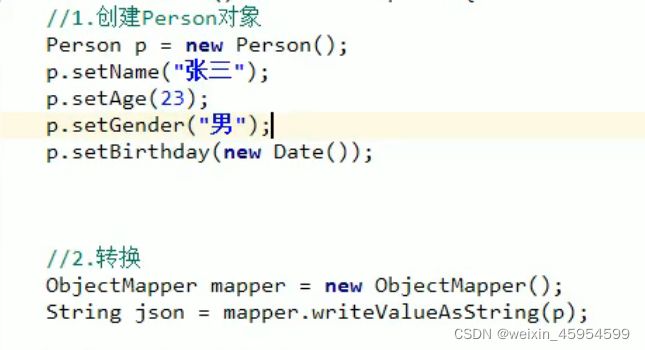
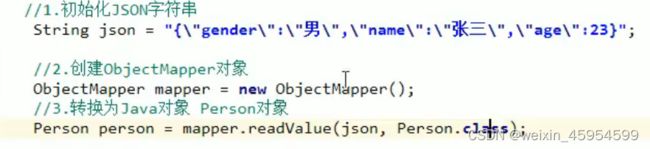
//自定义一个异常
//1. 一般情况下,我们自定义异常是继承RuntimeException
//2. 即把自定义异常做成运行时异常,好处时,我们可以使用默认的处理机制
class AgeException extends RuntimeException {
public AgeException(String message) {//构造器
super(message);
}
}
数据库
sql
1.什么是SQL ?
Structured Query Language :结构化查询语言
其实就是定义了操作所有关系型数据库的规则。每-种数据库操作的方式存在不一样的地方,称为“方言”。
SQL通用语法
- SQL语句可以单行或多行书写,以分号结尾。
- MySQL 数据库的SQL语句不区分大小写,关键字建议使用大写。
注释
单行注释: --注释内容 或 #注释内容(mysql特有)
多行注释: /*注释*/
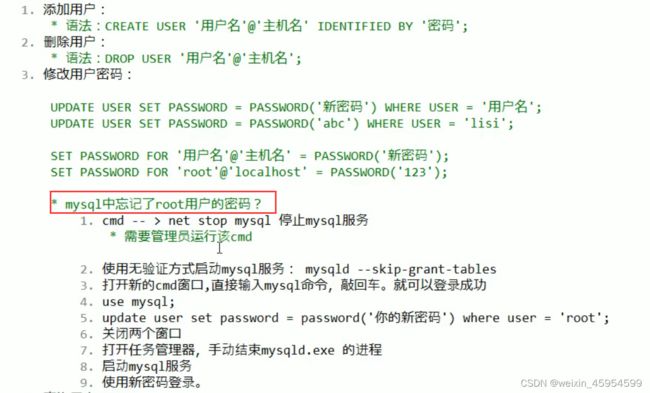
mysql
【卸载】
1.去mysql的安装目录找到my. ini文件
复制datadir=“C: /Progr amData/MySQL/MySQL Server 5 .5/Data/”
2.卸载MySQL
3.删除C:/ProgramData目录 下的MySQL文件夹。
3.配置
【MySQL服务启动】
1.手动。电脑右键管理-服务
2.cmd(管理员模式)–> services .msc打开服务的窗口
3.cmd
net start mysql :启动mysql的服务
net stop mysql :养闭mysq1服务
【MySQL登录】
-
mysql -uroot - p密码
-
mysql -hip -uroot - p连接目标的密码
-
mysql --host=ip --user=root --passsword=连接目标的密码
【MySQL退出】
- exit
- quit
【备份和还原】

操作指令
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yzbCqdvf-1645968588692)(java基础.assets/image-20210603090458273.png)]
1.操作数据车: CRUD
1、创建数据库:
1、create database 数据库名称;
2、create database if not exists数据库名称;
3、create database 数据库名称 character set 字符集名;
eg
create database if not exists db4 character set
utf8;
2、查询数据库
1、show databases ;
查询某个数据库的创建语句
2、show create database 数据库名称;
3、修改数据库
alter database 数据库名称 character set 字符集名称;
4、删除数据库
drop database 数据库名称;
drop database if exists 数据库名称;
5、使用数据库
查询当前正在使用的数据库名称
select database();
使用数据库
use 数据库名称;
2、操作表
1、建表
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
列名n 数据类型n
)
2、复制表:
create table 表名 like 被复制的表名;
3、查询表
所有的表名称show tables;
查询表结构 desc表名;
4、修改表
alter table 表名 rename to 新的表名;
alter table 表名 character set 字符集名称;
添加一列
alter table 表名 add 列名 数据类型;
修改列名称类型
alter table 表名 change 列名 新列 别新数据类型;
alter table 表名 modify 列名 新数据类型;
删除列
alter table 表名 drop 列名;
5、删除表
drop table表名;
drop table if exists 表名;
3、操作数据
1、添加
insert into 表名(列名1 ,列名2) values(值1,值2)
2、删除数据:
delete from 表名 [where 条件]
delete 和 truncate
- delete from 表名; --不推荐使用。有多少条记录就会删多少次(执行语句为n-记录条数)
- TRUNCATE TABLE 表名; --推荐使用,效率更高先删(先删表,再建结构。不管多少条记录,只执行2条语句)
3、修改数据
update 表名 set 列名1=值1,列名2=值2,... [where]
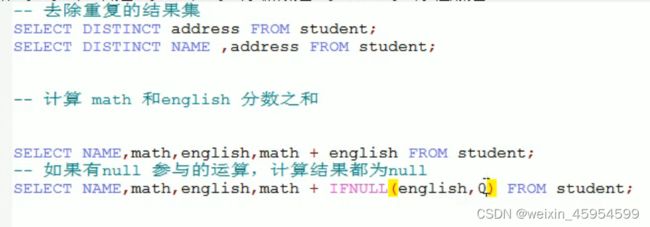
查询DQL语句
distinct:去重、ifnull(需判断的字段,改字段为空后的替换值)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5btn79Hd-1645968588693)(java基础.assets/image-20210604140325384.png)]
起别名 as(可省略)
is 【not】null 判断 不能用== 或 != 判断 null
like: _ 单个字符 % 多个
排序查询
order by 排序字段1 排序方式1,排序字段2 排序方式2...
如果有多个排序条件,则当前边条件一样时,才会判断第二条件
聚合查询:
- 一列数据作为整体,进行纵向计算
- 聚合函数包括(count、max、avg、sum等)
- 聚合函数计算,排除null值
- 解决方案
- 1.选择非空的列计算
- IFNULL函数
- 解决方案
*count(*)*只要某条记录中有一列不为null,则也会被算入。不推荐使用
分组查询
【语法】: group by分组字段
【注意】
分组之后查询的字段:分组字段、聚合函数
【where和having的区别?】
-
where 在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来
-
where后不可以跟聚合函数,having可以进行聚合函数的判断。
--按照性别分组。分别查询男、女同学的平均分 SELECT sex,AVG (math) FROM student GROUP BY sex; --按照性别分组。分别查询男、女同学的平均分,人数 SELECT sex,AVG (math) , COUNT(id) FROM student GROUP BY sex; -- 按照性别分组。分别查询男、女同学的平均分,人数要求:分数低于70分的人,不参与分组 SELECT sex,AVG (math) , COUNT(id) FROM student WHERE math > 70 GROUP BY sex; -- 按照性别分组。分别查询男、女同学的平均分,人数要求:分数低于70分的人,不参与分组,分组之后。人数要大于2个人 SELECT sex,AVG (math) , COUNT (id) FROM student WHERE math > 70 GROUP BY sex HAVING COUNT (id) > 2;
分页查询
约束
添加、删除非空约束
alter table stu modify phone not null
添加、删除自动增长
alter table stu modifyid int 【auto_increment】
删除唯一约束【语法特殊】
alter table stu drop index phone
删除主键【语法特殊】
alter table stu dorp primary key
外键约束: foreign key,
让表于表产生关系,从而保证数据的正确性。
1.在创建表时,可以添加外键
create table 表名(
//外键列
constraint 外键名 foreign key (外键列名 ) references 主表名称(主表列名称)
)
2.删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
3.创建表之后,添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称)
先建主表,再建现在的外键表
级联操作
1.添加级联操作
ALTER TABLE 表名 ADD CONSTRAINT 外键名称
FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称)
ON UPDATE CASCADE ON DELETE CASCADE ;
【分类】:
1.级联更新: ON UPDATE CASCADE
2.级联删除:ON DELETE CASCADE
【例子】
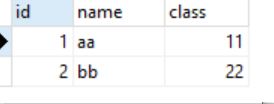
student表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XhPk9ezm-1645968588694)(java基础.assets/image-20210604172003552.png)]
cls表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4yrjWvBe-1645968588695)(java基础.assets/image-20210604172017740.png)]
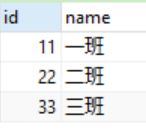
添加级联
ALTER TABLE student ADD CONSTRAINT stu_cls-fk
FOREIGN KEY (class) REFERENCES cls(id)
ON UPDATE CASCADE ON DELETE CASCADE ;
// 从表student 主表cls
// 级联更新 cls 的id变后, student 的 class会自动变
// 级联删除 cls 的一条记录删除后, student 的 对应的记录会自动删
多表关系
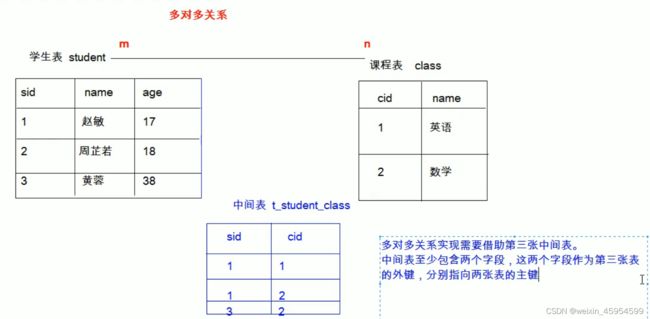
一对一
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4gCyWvpp-1645968588696)(java基础.assets/image-20210605110201879.png)]
一对一关系
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RSgLjcIk-1645968588696)(java基础.assets/image-20210605105501904.png)]
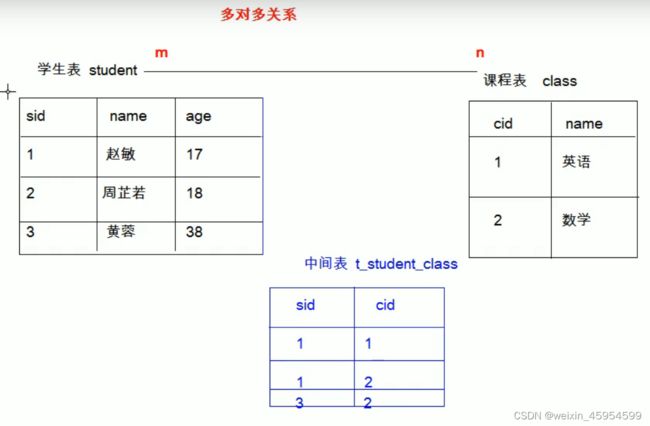
多对多
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-USeAQkbL-1645968588697)(java基础.assets/image-20210605110006426.png)]
范式
概念
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HXipIAbM-1645968588697)(java基础.assets/image-20210605112027691.png)]
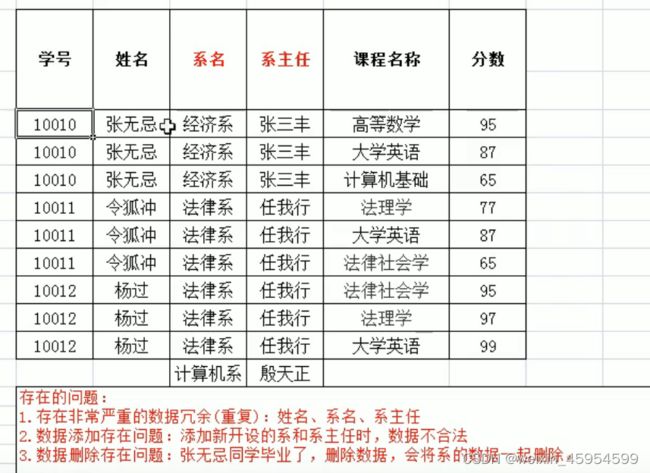
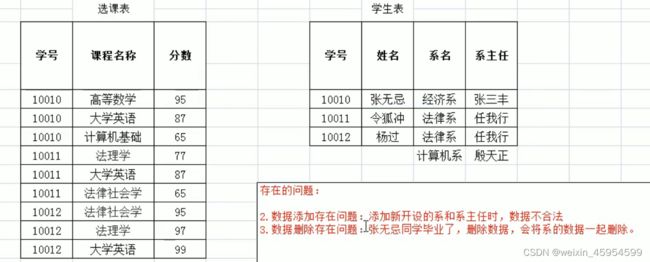
瑕疵表
1、消除部分依赖后[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D21zURFs-1645968588698)(java基础.assets/image-20210605112216086.png)]
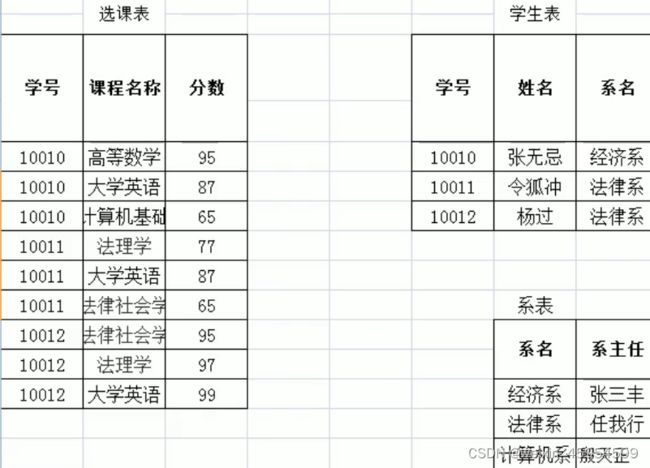
2、消除传递依赖后
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gwTbEgLm-1645968588699)(java基础.assets/image-20210605111934657.png)]
多表查询
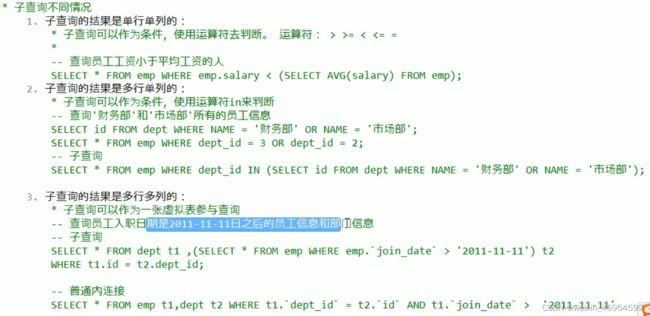
笛卡尔积:有两个集合,取这两个集合所有组成情况。要完成多表查询,要消除无用数据
方法参照如下
【多表查询分类】
1、内连接查询
-
隐式内连接:使用where消除无用数据
-
显示内连接:
select 字段列表 from 表1 [ inner ] join 表2 on 条件【隐式内连接】
【显示内连接】
2、外连接查询
-
左外连接
select 字段列表 from 表1 left [outer] join 表2 on 条件查询表1全部数据+表1和表2共同数据
-
右外连接
select 字段列表 from 表1 right[outer] join 表2 on 条件查询表2全部数据+表1和表2共同数据
左或右外连接是相对的,一般用左外连接就ok
左外连接以join左边的表为主,右外连接以join右边的表为主
3、子查询
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sk3gDkjM-1645968588700)(java基础.assets/image-20210605122253995.png)]
自连接查询例子
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z5p57YJE-1645968588701)(java基础.assets/image-20210605133246054.png)]
当要查的两个列在同一张表时,可以通过给表起别名的方式虚拟两张表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X9xicq2X-1645968588702)(java基础.assets/image-20210605133405643.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NcxebPMf-1645968588703)(java基础.assets/image-20210605133338274.png)]
事务
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vDnX90p0-1645968588704)(java基础.assets/image-20210605151058388.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7H06UL4y-1645968588705)(java基础.assets/image-20210605150939108.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dcjcYMid-1645968588705)(java基础.assets/image-20210605151837144.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Le3ZRRQr-1645968588706)(java基础.assets/image-20210605171309758.png)]
DCL
用户(增删改查)
jdbc
JDBC规范定义接口,具体的实现由各大数据库厂商来实现。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iBoJxqXR-1645968588707)(java基础.assets/image-20210606151436397.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XbhJTdlD-1645968588708)(java基础.assets/image-20210606151452925.png)]
PreparedStatement
好处
1.有预先编译的功能,提高SQL的执行效率。
prepareStatement()会先将SQL语句发送给数据库预编译。PreparedStatement会引用着预编译后的结果。可以多次传入不同的参数给PreparedStatement对象并执行。减少SQL编译次数,提高效率。
2.安全性更高,没有SQL注入的隐患。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yOEurh0T-1645968588708)(java基础.assets/image-20210606151631422.png)]
数据库连接池
-
概念:
其实就是一个容器(集合),存放数据库连接的容器。
当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器。 -
好处:
-
节约资源
-
用户访问高效
-
实现:
-
标准接口:DataSource javax.sql包下的
- 方法:
- 获取连接:getConnection()
- 归还连接:Connection.close()。如果连接对象Connection是从连接池中获取的,那么调用Connection.close()方法,则不会再关闭连接了。而是归还连接
- 方法:
-
一般我们不去实现它,有数据库厂商来实现
- C3P0:数据库连接池技术
- Druid:数据库连接池实现技术,由阿里巴巴提供的
-
-
C3P0:数据库连接池技术
-
步骤:
- 导入jar包 (两个) c3p0-0.9.5.2.jar mchange-commons-java-0.2.12.jar ,
- 不要忘记导入数据库驱动jar包
- 定义配置文件:
- 名称: c3p0.properties 或者 c3p0-config.xml
- 路径:直接将文件放在src目录下即可。
- 创建核心对象 数据库连接池对象 ComboPooledDataSource
- 获取连接: getConnection
- 导入jar包 (两个) c3p0-0.9.5.2.jar mchange-commons-java-0.2.12.jar ,
-
C3P0代码
//1.创建数据库连接池对象
DataSource ds = new ComboPooledDataSource();
//2. 获取连接对象
Connection conn = ds.getConnection();
-
Druid:数据库连接池实现技术,由阿里巴巴提供的
- 步骤:
- 导入jar包 druid-1.0.9.jar
- 定义配置文件:
- 是properties形式的
- 可以叫任意名称,可以放在任意目录下
- 加载配置文件。Properties
- 获取数据库连接池对象:通过工厂来来获取 DruidDataSourceFactory
- 获取连接:getConnection
- 步骤:
Druid代码
//3.加载配置文件
Properties pro = new Properties();
InputStream is = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
pro.load(is);
//4.获取连接池对象
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
//5.获取连接
Connection conn = ds.getConnection();
Spring JDBC
- Spring框架对JDBC的简单封装。提供了一个JDBCTemplate对象简化JDBC的开发
- 步骤:
-
导入jar包
-
创建JdbcTemplate对象。依赖于数据源DataSource
- JdbcTemplate template = new JdbcTemplate(ds);
-
调用JdbcTemplate的方法来完成CRUD的操作
- update():执行DML语句。增、删、改语句
- queryForMap():查询结果将结果集封装为map集合,将列名作为key,将值作为value 将这条记录封装为一个map集合
- 注意:这个方法查询的结果集长度只能是1
- queryForList():查询结果将结果集封装为list集合
- 注意:将每一条记录封装为一个Map集合,再将Map集合装载到List集合中
- query():查询结果,将结果封装为JavaBean对象
- query的参数:RowMapper
- 一般我们使用BeanPropertyRowMapper实现类。可以完成数据到JavaBean的自动封装
- new BeanPropertyRowMapper<类型>(类型.class)
- query的参数:RowMapper
- queryForObject:查询结果,将结果封装为对象
- 一般用于聚合函数的查询
-
java web
网络通信三要素
- IP:电子设备(计算机)在网络中的唯一标识。
- 端口:应用程序在计算机中的唯一标识。 0~65536
- 传输协议:规定了数据传输的规则
- 基础协议:
- tcp:安全协议,三次握手。 速度稍慢
- udp:不安全协议。 速度快
- 基础协议:
tomcat
部署项目的方式:
1. 直接将项目放到webapps目录下即可。
* /hello:项目的访问路径-->虚拟目录
- 简化部署:将项目打成一个war包,再将war包放置到webapps目录下。
- war包会自动解压缩
访问路径
1、在conf\Catalina\localhost创建任意名称的xml文件。【推荐】
在文件中编写
- 虚拟目录:xml文件的名称
2、配置conf/server.xml文件
在
- docBase:项目存放的路径
- path:虚拟目录
js 基础
方法
isNaN():判断一个值是否是NaN
* NaN六亲不认,连自己都不认。NaN参与的==比较全部问false
eval():讲 JavaScript 字符串,并把它作为脚本代码来执行。
绑定事件
jquery
JQuery对象和JS对象区别与转换
1、JQuery对象在操作时,更加方便。
2、JQuery对象和js对象方法不通用的.
3、两者相互转换
- jq – > js : jq对象[索引] 或者 jq对象.get(索引)
- js – > jq : $(js对象)
attr和prop区别?
- 如果操作的是元素的固有属性【如id等】,则建议使用prop
- 如果操作的是元素自定义的属性【如 hh=“”】,则建议使用attr
对class属性操作
- addClass():添加class属性值
- removeClass():删除class属性值
- toggleClass():切换class属性
- toggleClass(“one”):
* 判断如果元素对象上存在class=“one”,则将属性值one删除掉。 如果元素对象上不存在class=“one”,则添加
- toggleClass(“one”):
插件:增强JQuery的功能
实现方式:
1. $.fn.extend(object)
* 增强通过Jquery获取的对象的功能 $("#id")
2. $.extend(object)
- 增强JQeury对象自身的功能 $/jQuery
jquery下的ajax
1. $.ajax()
* 语法:$.ajax({键值对});
//使用$.ajax()发送异步请求
$.ajax({
url:"ajaxServlet1111" , // 请求路径
type:"POST" , //请求方式
//data: "username=jack&age=23",//请求参数
data:{"username":"jack","age":23},
success:function (data) {
alert(data);
},//响应成功后的回调函数
error:function () {
alert("出错啦...")
},//表示如果请求响应出现错误,会执行的回调函数
dataType:"text"//设置接受到的响应数据的格式
});
2. $.get():发送get请求
* 语法:$.get(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
3. $.post():发送post请求
* 语法:$.post(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
bom
- 概念:Browser Object Model 浏览器对象模型
- 将浏览器的各个组成部分封装成对象。
-
组成:
- Window:窗口对象
- Navigator:浏览器对象
- Screen:显示器屏幕对象
- History:历史记录对象
- Location:地址栏对象
-
Window:窗口对象
-
创建
-
方法
-
与弹出框有关的方法:
alert() 显示带有一段消息和一个确认按钮的警告框。
confirm() 显示带有一段消息以及确认按钮和取消按钮的对话框。* 如果用户点击确定按钮,则方法返回true- 如果用户点击取消按钮,则方法返回false
prompt() 显示可提示用户输入的对话框。
- 返回值:获取用户输入的值
-
与打开关闭有关的方法:
close() 关闭浏览器窗口。
* 谁调用我 ,我关谁
open() 打开一个新的浏览器窗口
* 返回新的Window对象 -
与定时器有关的方式
setTimeout() 在指定的毫秒数后调用函数或计算表达式。- 参数:
- js代码或者方法对象
2. 毫秒值
- js代码或者方法对象
- 参数:
* 返回值:唯一标识,用于取消定时器 *clearTimeout()* 取消由 setTimeout() 方法设置的 timeout。 *setInterval()* 按照指定的周期(以毫秒计)来调用函数或计算表达式。 *clearInterval()* 取消由 setInterval() 设置的 timeout。 -
-
属性:
- 获取其他BOM对象:
history
location
Navigator
Screen: - 获取DOM对象
document
- 获取其他BOM对象:
-
特点
- Window对象不需要创建可以直接使用 window使用。 window.方法名();
- window引用可以省略。 方法名();
-
-
Location:地址栏对象
-
创建(获取):
- window.location
-
location
-
方法:
- reload() 重新加载当前文档。刷新
-
属性
- href 设置或返回完整的 URL。
-
-
History:历史记录对象
-
创建(获取):
- window.history
-
history
-
方法:
- back() 加载 history 列表中的前一个 URL。
- forward() 加载 history 列表中的下一个 URL。
- go(参数) 加载 history 列表中的某个具体页面。
- 参数:
- 正数:前进几个历史记录
- 负数:后退几个历史记录
- 参数:
-
属性:
- length 返回当前窗口历史列表中的 URL 数量。
-
xml
1、概念:
Extensible Markup Language 可扩展标记语言
-
可扩展:标签都是自定义的。
-
功能
- 存储数据
- 配置文件
- 在网络中传输
- 存储数据
-
xml与html的区别
- xml标签都是自定义的,html标签是预定义。
- xml的语法严格,html语法松散
- xml是存储数据的,html是展示数据
-
w3c:万维网联盟
#####2、 语法:
- 基本语法:
- xml文档的后缀名 .xml
- xml第一行必须定义为文档声明
- xml文档中有且仅有一个根标签
- 属性值必须使用引号(单双都可)引起来
- 标签必须正确关闭
- xml标签名称区分大小写
- 快速入门:
<?xml version='1.0' ?>
<users>
<user id='1'>
<name>zhangsan</name>
<age>23</age>
<gender>male</gender>
<br/>
</user>
<user id='2'>
<name>lisi</name>
<age>24</age>
<gender>female</gender>
</user>
</users>
-
组成部分:
- 文档声明
- 格式:
- 属性列表:
- version:版本号,必须的属性
- encoding:编码方式。告知解析引擎当前文档使用的字符集,默认值:ISO-8859-1
- standalone:是否独立
- 取值:
- yes:不依赖其他文件
- no:依赖其他文件
- 取值:
- *指令(*了解):结合css的
- 标签:标签名称自定义的
- 规则:
- 名称可以包含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字母 xml(或者 XML、Xml 等等)开始
- 名称不能包含空格
- 属性:
id属性值唯一 - 文本:
- CDATA区:在该区域中的数据会被原样展示
- 格式:
3、解析:操作xml文档,将文档中的数据读取到内存中
-
操作xml文档
- 解析(读取):将文档中的数据读取到内存中
- 写入:将内存中的数据保存到xml文档中。持久化的存储
-
解析xml的方式:
- DOM:将标记语言文档一次性加载进内存,在内存中形成一颗dom树
- 优点:操作方便,可以对文档进行CRUD的所有操作
- 缺点:占内存
- SAX:逐行读取,基于事件驱动的。
- 优点:不占内存。
- 缺点:只能读取,不能增删改
- DOM:将标记语言文档一次性加载进内存,在内存中形成一颗dom树
-
xml常见的解析器:
- JAXP:sun公司提供的解析器,支持dom和sax两种思想
- DOM4J:一款非常优秀的解析器
- Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
4、快捷查询方式:
- selector:选择器
- 使用的方法:Elements select(String cssQuery)
- 语法:参考Selector类中定义的语法
- 使用的方法:Elements select(String cssQuery)
- XPath:XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言
- 使用Jsoup的Xpath需要额外导入jar包。
- 查询w3cshool参考手册,使用xpath的语法完成查询
【代码】
* 快速入门:
* 步骤:
1. 导入jar包
2. 获取Document对象
3. 获取对应的标签Element对象
4. 获取数据
* 代码:
============== selector 选择器 ============
//2.1获取student.xml的path
String path = JsoupDemo1.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象 Element
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
============= jsoup =======================
//1.获取student.xml的path
String path = JsoupDemo6.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.根据document对象,创建JXDocument对象
JXDocument jxDocument = new JXDocument(document);
//4.结合xpath语法查询
//4.1查询所有student标签
List jxNodes = jxDocument.selN("//student");
for (JXNode jxNode : jxNodes) {
System.out.println(jxNode);
}
System.out.println("--------------------");
//4.3查询student标签下带有id属性的name标签
List jxNodes3 = jxDocument.selN("//student/name[@id]");
for (JXNode jxNode : jxNodes3) {
System.out.println(jxNode);
}
System.out.println("--------------------");
//4.4查询student标签下带有id属性的name标签 并且id属性值为itcast
List jxNodes4 = jxDocument.selN("//student/name[@id='itcast']");
for (JXNode jxNode : jxNodes4) {
System.out.println(jxNode);
}
4、约束
规定xml文档的书写规则
- 作为框架的使用者(程序员):
能够在xml中引入约束文档
能够简单的读懂约束文档
- 分类:
-
DTD:一种简单的约束技术
-
Schema:一种复杂的约束技术
-
DTD:
* 引入dtd文档到xml文档中
* 内部dtd:将约束规则定义在xml文档中- 外部dtd:将约束的规则定义在外部的dtd文件中
- 本地:
-
网络:
-
Schema:
1.填写xml文档的根元素 2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd" 4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml" <students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.itcast.cn/xml" xsi:schemaLocation="http://www.itcast.cn/xml student.xsd">
-
-
json 与 java对象互转
* JSON解析器:
* 常见的解析器:Jsonlib,Gson,fastjson,jackson
1. JSON转为Java对象
1. 导入jackson的相关jar包
2. 创建Jackson核心对象 ObjectMapper
3. 调用ObjectMapper的相关方法进行转换
1. readValue(json字符串数据,Class)
2. Java对象转换JSON
1. 使用步骤:
1. 导入jackson的相关jar包
2. 创建Jackson核心对象 ObjectMapper
3. 调用ObjectMapper的相关方法进行转换
1. 转换方法:
* writeValue(参数1,obj):
参数1:
File:将obj对象转换为JSON字符串,并保存到指定的文件中
Writer:将obj对象转换为JSON字符串,并将json数据填充到字符输出流中
OutputStream:将obj对象转换为JSON字符串,并将json数据填充到字节输出流中
* writeValueAsString(obj):将对象转为json字符串
2. 注解:
1. @JsonIgnore:排除属性。
2. @JsonFormat:属性值得格式化
* @JsonFormat(pattern = "yyyy-MM-dd")
3. 复杂java对象转换
1. List:数组
2. Map:对象格式一致
json-——>java
java——>json
服务器响应的数据,在客户端使用时,要想当做json数据格式使用。
有两种解决方案:
- $.get(type):将最后一个参数type指定为"json"
- 在服务器端设置MIME类型
response.setContentType(“application/json;charset=utf-8”);
servlet
概念:运行在服务器端的小程序
Servlet就是一个接口,定义了Java类被浏览器访问到(tomcat识别)的规则。
执行原理:
- 当服务器接受到客户端浏览器的请求后,会解析请求URL路径,获取访问的Servlet的资源路径
- 查找web.xml文件,是否有对应的
标签体内容。 - 如果有,则在找到对应的
全类名 - tomcat会将字节码文件加载进内存,并且创建其对象
- 调用其方法
Servlet中的生命周期方法:
-
被创建:执行init方法,只执行一次
- Servlet什么时候被创建?
- 默认情况下,第一次被访问时,Servlet被创建
- 可以配置执行Servlet的创建时机。
- 在
标签下配置
- 第一次被访问时,创建
*的值为负数 - 在服务器启动时,创建
的值为0或正整数
- 在
Servlet的init方法,只执行一次,说明一个Servlet在内存中只存在一个对象,Servlet是单例的
* 多个用户同时访问时,可能存在线程安全问题。
* 解决:尽量不要在Servlet中定义成员变量。即使定义了成员变量,也不要对修改值 - Servlet什么时候被创建?
-
提供服务:执行service方法,执行多次
* 每次访问Servlet时,Service方法都会被调用一次。- 被销毁:执行destroy方法,只执行一次
重定向和请求转发
* 重定向的特点:redirect
1. 地址栏发生变化
2. 重定向可以访问其他站点(服务器)的资源
3. 重定向是两次请求。不能使用request对象来共享数据
4. 效率较低
* 转发的特点:forward
1. 转发地址栏路径不变
2. 转发只能访问当前服务器下的资源
3. 转发是一次请求,可以使用request对象来共享数据
4. 效率较高
jsp
. 概念:
* Java Server Pages: java服务器端页面
原理
- JSP本质上就是一个Servlet
Session 和 Cookie
细节:
1. 当客户端关闭后,服务器不关闭,两次获取session是否为同一个?
* 默认情况下。不是。
* 如果需要相同,则可以创建Cookie,键为JSESSIONID,设置最大存活时间,让cookie持久化保存。
Cookie c = new Cookie("JSESSIONID",session.getId());
c.setMaxAge(60*60);
response.addCookie(c);
2. 客户端不关闭,服务器关闭后,两次获取的session是同一个吗?
* 不是同一个,但是要确保数据不丢失。tomcat自动完成以下工作
* session的钝化:
* 在服务器正常关闭之前,将session对象序列化到硬盘上
* session的活化:
* 在服务器启动后,将session文件转化为内存中的session对象即可。
3. session什么时候被销毁?
1. 服务器关闭
2. session对象调用invalidate() 。
3. session默认失效时间 30分钟
选择性配置修改
30
- session与Cookie的区别:
- session存储数据在服务器端,Cookie在客户端
- session没有数据大小限制,Cookie有
- session数据安全,Cookie相对于不安全
redis
1、概念
redis是一款高性能的NOSQL系列的非关系型数据库
NOSQL和关系型数据库比较
NOSQL优点:
1)成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
2)查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
3)存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
4)扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。
缺点:
1)维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。
2)不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
3)不提供关系型数据库对事务的处理。
总结
关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用NoSQL的时候使用NoSQL数据库,
让NoSQL数据库对关系型数据库的不足进行弥补。
一般会将数据存储在关系型数据库中,在nosql数据库中备份存储关系型数据库的数据
redis的应用场景
• 缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒)
• 分布式集群架构中的session分离
redis的数据结构:
redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
value的数据结构:
1) 字符串类型 string
2) 哈希类型 hash : map格式
3) 列表类型 list : linkedlist格式。支持重复元素
4) 集合类型 set : 不允许重复元素
5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序
#####命令操作
1、字符串类型 string
存储: set key value eg:127.0.0.1:6379> set user zhangsan
获取: get key eg:get user
删除: del key eg: del age
2、哈希类型 hash
存储: hset key field value eg: hset myhash user lisi
获取: hget key field eg: hget myhash user
获取所有的field和value: hgetall key
删除: hdel key field
3、列表类型 list: 可以添加一个元素到列表的头部(左边)或者尾部(右边)
【添加】
列表左lpush key value
列表右rpush key value
【获取:】
lrange key start end :范围获取
【删除:】
`lpop key`: 删除列表最左边的元素,并将元素返回
4、集合类型 set : 不允许重复元素
存储:sadd key value
获取集合中所有元素:smembers key
删除set集合中的某个元素srem key value
5、有序集合类型 sortedset:不允许重复元素,且元素有顺序
每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序
存储:zadd key score value 通过score来从小到大排序
获取:zrange key start end [withscores]
eg 127.0.0.1:6379> zrange mysort 0 -1
删除:zrem key value
通用命令
keys * : 查询所有的键
type key : 获取键对应的value的类型
del key:删除
持久化
- redis是一个内存数据库,当redis服务器重启,或者电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
- redis持久化机制:
-
RDB:默认方式,不需要进行配置,默认就使用这种机制
- 在一定的间隔时间中,检测key的变化情况,然后持久化数据
-
编辑redis.windwos.conf文件
save 300 100
-
重新启动redis服务器,并指定配置文件名称
D:\redis\windows-64\redis-2.8.9> redis-server.exe redis.windows.conf
-
AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据
-
编辑redis.windwos.conf文件
appendonly no(关闭aof) --> appendonly yes (开启aof)appendfsync always : 每一次操作都进行持久化
appendfsync everysec : 每隔一秒进行一次持久化
appendfsync no : 不进行持久化
-
-
Java客户端 Jedis
-
Jedis: 一款java操作redis数据库的工具.
-
使用步骤:
-
下载jedis的jar包
-
使用
//1. 获取连接 Jedis jedis = new Jedis("localhost",6379); //2. 操作 对应数据结构操作 jedis.set("username","zhangsan"); //3. 关闭连接 jedis.close();
-
jedis连接池: JedisPool
使用:
//0.创建一个配置对象
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(50);
config.setMaxIdle(10);
//1.创建Jedis连接池对象
JedisPool jedisPool = new JedisPool(config,"localhost",6379);
//2.获取连接
Jedis jedis = jedisPool.getResource();
//3. 使用
jedis.set("hehe","heihei");
//4. 关闭 归还到连接池中
jedis.close();
redis注意事项
- 使用redis缓存一些不经常发生变化的数据。
- 数据库的数据一旦发生改变,则需要更新缓存。
maven
生命周期
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NnDAEEnV-1645968588710)(java基础.assets/image-20210612112000246.png)]
执行后面的指令时会自动执行前面的
依赖范围
转发的特点:forward
1. 转发地址栏路径不变
2. 转发只能访问当前服务器下的资源
3. 转发是一次请求,可以使用request对象来共享数据
4. 效率较高
jsp
. 概念:
* Java Server Pages: java服务器端页面
原理
- JSP本质上就是一个Servlet
Session 和 Cookie
细节:
1. 当客户端关闭后,服务器不关闭,两次获取session是否为同一个?
* 默认情况下。不是。
* 如果需要相同,则可以创建Cookie,键为JSESSIONID,设置最大存活时间,让cookie持久化保存。
Cookie c = new Cookie("JSESSIONID",session.getId());
c.setMaxAge(60*60);
response.addCookie(c);
2. 客户端不关闭,服务器关闭后,两次获取的session是同一个吗?
* 不是同一个,但是要确保数据不丢失。tomcat自动完成以下工作
* session的钝化:
* 在服务器正常关闭之前,将session对象序列化到硬盘上
* session的活化:
* 在服务器启动后,将session文件转化为内存中的session对象即可。
3. session什么时候被销毁?
1. 服务器关闭
2. session对象调用invalidate() 。
3. session默认失效时间 30分钟
选择性配置修改
30
- session与Cookie的区别:
- session存储数据在服务器端,Cookie在客户端
- session没有数据大小限制,Cookie有
- session数据安全,Cookie相对于不安全
redis
1、概念
redis是一款高性能的NOSQL系列的非关系型数据库
NOSQL和关系型数据库比较
NOSQL优点:
1)成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
2)查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
3)存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
4)扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。
缺点:
1)维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。
2)不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
3)不提供关系型数据库对事务的处理。
总结
关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用NoSQL的时候使用NoSQL数据库,
让NoSQL数据库对关系型数据库的不足进行弥补。
一般会将数据存储在关系型数据库中,在nosql数据库中备份存储关系型数据库的数据
redis的应用场景
• 缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒)
• 分布式集群架构中的session分离
redis的数据结构:
redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
value的数据结构:
1) 字符串类型 string
2) 哈希类型 hash : map格式
3) 列表类型 list : linkedlist格式。支持重复元素
4) 集合类型 set : 不允许重复元素
5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序
#####命令操作
1、字符串类型 string
存储: set key value eg:127.0.0.1:6379> set user zhangsan
获取: get key eg:get user
删除: del key eg: del age
2、哈希类型 hash
存储: hset key field value eg: hset myhash user lisi
获取: hget key field eg: hget myhash user
获取所有的field和value: hgetall key
删除: hdel key field
3、列表类型 list: 可以添加一个元素到列表的头部(左边)或者尾部(右边)
【添加】
列表左lpush key value
列表右rpush key value
【获取:】
lrange key start end :范围获取
【删除:】
`lpop key`: 删除列表最左边的元素,并将元素返回
4、集合类型 set : 不允许重复元素
存储:sadd key value
获取集合中所有元素:smembers key
删除set集合中的某个元素srem key value
5、有序集合类型 sortedset:不允许重复元素,且元素有顺序
每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序
存储:zadd key score value 通过score来从小到大排序
获取:zrange key start end [withscores]
eg 127.0.0.1:6379> zrange mysort 0 -1
删除:zrem key value
通用命令
keys * : 查询所有的键
type key : 获取键对应的value的类型
del key:删除
持久化
- redis是一个内存数据库,当redis服务器重启,或者电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
- redis持久化机制:
-
RDB:默认方式,不需要进行配置,默认就使用这种机制
- 在一定的间隔时间中,检测key的变化情况,然后持久化数据
-
编辑redis.windwos.conf文件
save 300 100
-
重新启动redis服务器,并指定配置文件名称
D:\redis\windows-64\redis-2.8.9> redis-server.exe redis.windows.conf
-
AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据
-
编辑redis.windwos.conf文件
appendonly no(关闭aof) --> appendonly yes (开启aof)appendfsync always : 每一次操作都进行持久化
appendfsync everysec : 每隔一秒进行一次持久化
appendfsync no : 不进行持久化
-
-
Java客户端 Jedis
-
Jedis: 一款java操作redis数据库的工具.
-
使用步骤:
-
下载jedis的jar包
-
使用
//1. 获取连接 Jedis jedis = new Jedis("localhost",6379); //2. 操作 对应数据结构操作 jedis.set("username","zhangsan"); //3. 关闭连接 jedis.close();
-
jedis连接池: JedisPool
使用:
//0.创建一个配置对象
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(50);
config.setMaxIdle(10);
//1.创建Jedis连接池对象
JedisPool jedisPool = new JedisPool(config,"localhost",6379);
//2.获取连接
Jedis jedis = jedisPool.getResource();
//3. 使用
jedis.set("hehe","heihei");
//4. 关闭 归还到连接池中
jedis.close();
redis注意事项
- 使用redis缓存一些不经常发生变化的数据。
- 数据库的数据一旦发生改变,则需要更新缓存。
maven
生命周期
[外链图片转存中…(img-NnDAEEnV-1645968588710)]
执行后面的指令时会自动执行前面的
依赖范围
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dynSeOIx-1645968588711)(java基础.assets/image-20210611150605428.png)]