【机器学习】监督学习模型中的线性回归模型和分类模型
系列文章目录
第三章 Python 机器学习入门之线性回归模型和分类模型
目录
系列文章目录
一、线性回归模型
二、分类模型
三、监督学习的过程
一、线性回归模型
下面来学习监督学习的这过程是什么样的,以线性回归方程为例
线性回归模型就是对你的数据拟合成一条直线,这是使用非常广泛的学习算法了
像预测房子的价格,我们可以根据以知的数据(多大的房子卖了多少钱),这些数据集来构建线性回归模型
线性回归模型是 监督学习模型 supervised learning model,
因为我们需要通过给出一个数据来训练一个模型,给出的数据包含正确答案,也就是多大面积的房子卖了多少钱
因为我们给出了房子的模型例子,房子的大小,以及模型应该预测的每栋房子的价格。
我们得到的房子价格,就是数据集中的每一个房子都给出正确的答案。
线性回归模型是一种特殊类型的监督学习模型。
它被称为回归模型,因为它预测数字作为输出
任何预测数字的监督学习模型,在解决所谓的回归问题,称为回归模型,所以线性回归是回归模型的一个例子。
但是在回归问题中,还有其他的解决模型。
二、分类模型
另一种最常见的监督学习模型叫分类模型classification model
比如预测一张照片上是猫还是狗。
分类模型只有少量可能的输出,如果你的模型是识别猫和狗,那么它就有两种输出可能,猫或者狗。
回归模型可以输出无限多的可能数字,
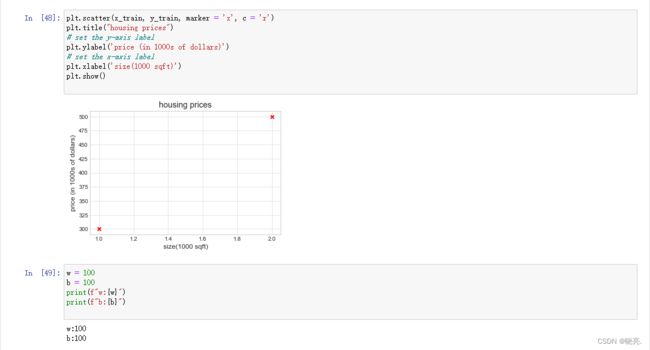
我们可以通过处理将数据可视化成一个图,数据表也非常有用。
用来训练模型的数据叫做数据集(training set),
我们先训练我们的模型,从数据集中学习,这个模型可以在机器学习中预测结果。比如估算房子的价格,如果有大量的数据(多大的房子卖了多少钱),我们可以训练模型,给它一个房子面积,它可以来预测房价。
表示输入的标注符号是x,x = "input" variable feature 我们称为输入变量,也叫做特征或者输入特征
表示我们想要预测的输出变量的标志符号是y , y = "output" variable “target”variable 有时也被称为目标变量
m是训练实例的总数, m = number of training examples
(x, y)= single training example 单个的训练实例
三、监督学习的过程
监督学习的工作过程是怎么样的?
监督学习算法将输入一个数据集,然后它到底做了什么,输出了什么呢?
监督学习中的数据集 training set,既包括输入特征,如房子的大小,也包括输出目标,如房子的价格。
输出目标是我们将从中学习的模型的正确答案。
为了训练模型,我们将训练集,输出特征,输出目标提供给学习算法,然后我们的监督学习算法就会产生一些函数 function,
我们将这个函数写成小写的f ,f 的工作是获取一个新的输入x 和输出 并估计或预测 y-hat 它就像变量y一样,
在机器学习中,规定y-hat 是对y 的预估或预测,函数f 称为模型 model , x称为输入或输入特征,模型的输出是预测 y-hat ,模型的预测是对 y 的估计值,
符号 y 指的是目标,即训练集中的实际真实值。y-hat 是一个估计值,它可能是实际的真实值,也可能不是。
例如房价,我们首先给定房子的大小,模型f 输出作为估计量的价格,即对真实价格的预测

当我们设计学习算法时,一个关键的问题时-是,我们将如何表示函数(function)f,
也就是需要弄明白,我们用来计算的 f 的数学公式是什么?
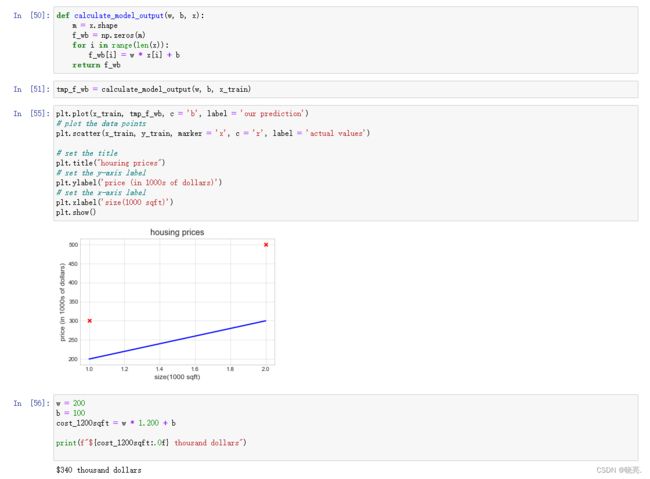
如果 f 是一条直线,我们可以将函数 f 写成 f w,b (x) = w*x + b,其中 f w,b (x) 也可以简写成 f(x)
函数写出来时,w,b还没有被定义,但是我们知道它们时数字,为w,b 赋值后,f 将根据输入特征 x 来确定预测 y-hat
f(x) 表示 f 是一个以 x 作为输入的函数,根据w和b的值,f 将输出预测 y-hat 的某个值
如果我们在图上训练数据集,其中输入特征 x 在水平轴上,输出目标 y 在纵轴上,该算法就会从这些数据中学习,并生成最佳拟合线。
这条直线就是x 的线性函数 f (x) = w*x + b,这就是这个函数正在做的事情,
它使用函数 f 通过输入变量x,来输出目标的预测值y-hat。
绘出来的图形是一条直线,就叫线性模型,
通过对线性模型的理解,我们可以更好的学习一些复杂的非线性模型。
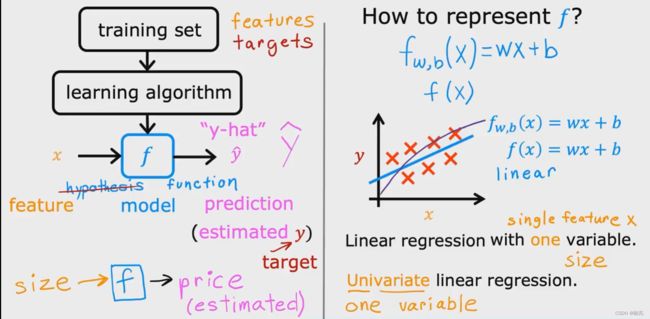
图中的这个模型就叫做线性回归,这是带一个变量的线性回归,linear regression with one variable, 表示存在单个输入变量或特征x,
具有一个变量的线性模型被称为单变量线性回归,univariable linear regression.
后面的学习中,我们可能需要输入多个变量,像房子的大小,房子中房间的个数等等。
下面是利用jupyter notebook 练习画图