GPT家族
Task04 GPT家族
目录
-
GPT-1
-
GPT-1的训练
-
无监督预训练
-
有监督微调
-
任务相关的输入变换
-
GPT-1的数据集
-
网络结构的细节
-
无监督训练
-
有监督微调
-
GPT-1的性能
-
总结
-
-
GPT-2
-
GPT-2的核心思想
-
GPT-2的数据集
-
模型结构
-
GPT-2的性能
-
与 GPT-1 的区别
-
总结
-
-
GPT-3
-
模型结构
-
数据集
-
下游评估方式
-
In-context learning
-
结果
-
GPT-3的性能
-
GPT-3有什么问题?
-
GPT-1
在GPT-1之前(和ELMo同一年),传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点:
- 需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界;
- 根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP。
这里介绍的GPT-1的思想是先通过在无标签的数据上学习一个生成式的语言模型,然后再根据特定热任务进行微调,处理的有监督任务包括
- 自然语言推理(Natural Language Inference 或者 Textual Entailment):判断两个句子是包含关系(entailment),矛盾关系(contradiction),或者中立关系(neutral);
- 问答和常识推理(Question answering and commonsense reasoning):类似于多选题,输入一个文章,一个问题以及若干个候选答案,输出为每个答案的预测概率;
- 语义相似度(Semantic Similarity):判断两个句子是否语义上市是相关的;
- 分类(Classification):判断输入文本是指定的哪个类别。
将无监督学习左右有监督模型的预训练目标,因此叫做生成式预训练(Generative Pre-training,GPT)。
GPT-1的训练
GPT-1的训练分为无监督的预训练和有监督的模型微调,下面进行详细介绍。
无监督预训练
GPT-1的无监督预训练是基于语言模型进行训练的,给定一个无标签的序列$ \mathcal{U} = {u_1, \cdots, u_n} $,语言模型的优化目标是最大化下面的似然值:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_1(\mathcal{U}) = \sum_i \log P(u_i | u_{i-k}, \dots, u_{i-1}; \Theta) L1(U)=∑ilogP(ui∣ui−k,…,ui−1;Θ) (1)
其中$ k 是滑动窗口的大小, 是滑动窗口的大小, 是滑动窗口的大小, P 是条件概率, 是条件概率, 是条件概率, \Theta $是模型的参数。这些参数使用SGD进行优化。
在GPT-1中,使用了12个transformer块的结构作为解码器,每个transformer块是一个多头的自注意力机制,然后通过全连接得到输出的概率分布。

h 0 = U W e + W p h_0 = UW_e + W_p h0=UWe+Wp (2)
$ h_l = \text{transformer_block}(h_{l-1}) \forall i \in [1,n] $ (3)
$ P(u) = \text{softmax}(h_nW_e^T) $ (4)
其中$ U=(u_{-k},\dots,u_{-1}) 是当前时间片的上下文 t o k e n , 是当前时间片的上下文token, 是当前时间片的上下文token, n 是层数, 是层数, 是层数, W_e 是词嵌入矩阵, 是词嵌入矩阵, 是词嵌入矩阵, W_p $是位置嵌入矩阵。
有监督微调
当得到无监督的预训练模型之后,我们将它的值直接应用到有监督任务中。对于一个有标签的数据集$ \mathcal{C} $,每个实例有 m 个输入token: $ {x^1, \dots, x^m} ,它对于的标签 ,它对于的标签 ,它对于的标签 y 组成。首先将这些 t o k e n 输入到训练好的预训练模型中,得到最终的特征向量 组成。首先将这些token输入到训练好的预训练模型中,得到最终的特征向量 组成。首先将这些token输入到训练好的预训练模型中,得到最终的特征向量 h_l^m 。然后再通过一个全连接层得到预测结果 。然后再通过一个全连接层得到预测结果 。然后再通过一个全连接层得到预测结果 y $:
P ( y ∣ x 1 , … , x m ) = softmax ( h l m W y ) P(y|x^1, \dots, x^m) = \text{softmax}(h^m_l W_y) P(y∣x1,…,xm)=softmax(hlmWy) (5)
其中$ W_y $为全连接层的参数。有监督的目标则是最大化(5)式的值:
L 2 ( C ) = ∑ x , y log P ( y ∣ x 1 , … , x m ) L_2(\mathcal{C}) = \sum_{x,y} \log P(y|x^1, \dots, x^m) L2(C)=∑x,ylogP(y∣x1,…,xm) (6)
作者并没有直接使用$ L_2 ,而是向其中加入了 ,而是向其中加入了 ,而是向其中加入了 L_1 ,并使用 ,并使用 ,并使用 \lambda 进行两个任务权值的调整, 进行两个任务权值的调整, 进行两个任务权值的调整, \lambda 的值一般为 的值一般为 的值一般为 0.5 $:
$ L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda L_1(\mathcal{C}) $ (7)
当进行有监督微调的时候,我们只训练输出层的$ W_y $和分隔符(delimiter)的嵌入值。
任务相关的输入变换
文章开头介绍了GPT-1处理的4个不同的任务,这些任务有的只有一个输入,有的则有多组形式的输入。对于不同的输入,GPT-1有不同的处理方式,具体介绍如下:
- 分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
- 自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
- 语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果;
- 问答和常识推理:将 n 个选项的问题抽象化为 n 个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。

GPT-1的数据集
GPT-1使用了BooksCorpus数据集,这个数据集包含 7,000 本没有发布的书籍。选这个数据集的原因有二:1. 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系;2. 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
网络结构的细节
GPT-1使用了12层的transformer,使用了掩码自注意力头,掩码的使用使模型看不见未来的信息,得到的模型泛化能力更强。
无监督训练
- 使用字节对编码(byte pair encoding,BPE),共有 40,000 个字节对;
- 词编码的长度为 768 ;
- 位置编码也需要学习;
- 12 层的transformer,每个transformer块有 12 个头;
- 位置编码的长度是 3,072 ;
- Attention, 残差,Dropout等机制用来进行正则化,drop比例为 0.1 ;
- 激活函数为GLEU;
- 训练的batchsize为 64 ,学习率为 2.5$ e^{-4} $,序列长度为 512 ,序列epoch为 100 ;
- 模型参数数量为 1.17 亿。
有监督微调
- 无监督部分的模型也会用来微调;
- 训练的epoch为 3 ,学习率为 6.25$ e^{-5} $,这表明模型在无监督部分学到了大量有用的特征。
GPT-1的性能
在有监督学习的12个任务中,GPT-1在9个任务上的表现超过了state-of-the-art的模型。在没有见过数据的zero-shot任务中,GPT-1的模型要比基于LSTM的模型稳定,且随着训练次数的增加,GPT-1的性能也逐渐提升,表明GPT-1有非常强的泛化能力,能够用到和有监督任务无关的其它NLP任务中。GPT-1证明了transformer对学习词向量的强大能力,在GPT-1得到的词向量基础上进行下游任务的学习,能够让下游任务取得更好的泛化能力。对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
总结
初代 GPT 到底做了什么?有哪些贡献?
第一,它是最早一批提出在 NLP 任务上使用 pre-train + fine-tuning 范式的工作。
第二,GPT 的实验证明了模型的精度和泛化能力会随着解码器层数增加而不断提升,而且目前还有提升空间。
第三,预训练模型具有 zero-shot 的能力,并且能随着预训练的进行不断增强。
值得注意的是,上述第二和第三点,也直接预示着后续 GPT-2 和 GPT-3 的出现。
其实 pre-train + fine-tuning 在计算机视觉里面早在好多年前已经成为主流的算法,但是在 NLP 中一直没有流行起来,主要还是因为在 NLP 里面没有像 ImageNet 那样大规模标好的数据集,这也导致相当一段时间内,深度学习在 NLP 的进展相对比较缓慢,直到 GPT 和 BERT 的出现才渐渐打开局面。
如果说使用大规模无标注的文本进行模型的预训练使 NLP 的发展往前走了一大步,那么 GPT 系列一直在努力推动的 zero-shot 可以说是走了另一大步。
为了进一步验证 zero-shot 的能力,OpenAI 在 GPT-1 提出一年后,推出了 GPT-2。
GPT-2
GPT-2 原文标题为 Language Models are Unsupervised Multitask Learners,字面意思为语言模型是一种无监督多任务学习器。
标题中的多任务学习与我们常规理解的有监督学习中的多任务不太一样,这里主要是指模型从大规模数据中学到的能力能够直接在多个任务之间进行迁移,而不需要额外提供特定任务的数据,因此引出了 GPT-2 的主要观点:zero-shot。
不论是 GPT-1 还是 BERT,NLP 任务中比较主流的 pre-train + fine-tuning 始终还是需要一定量的下游任务有监督数据去进行额外的训练,在模型层面也需要额外的模块去进行预测,仍然存在较多人工干预的成本。GPT-2 想彻底解决这个问题,通过 zero-shot,在迁移到其他任务上的时候不需要额外的标注数据,也不需要额外的模型训练。
GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集。
GPT-2的核心思想
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。因为文本数据的时序性,一个输出序列可以表示为一系列条件概率的乘积:
p ( x ) = ∏ i = 1 n p ( s n ∣ s 1 , … , s n − 1 ) p(x) = \prod_{i=1}^n p (s_n | s_1, \dots, s_{n-1}) p(x)=∏i=1np(sn∣s1,…,sn−1) (8)
上式也可以表示为$ p(s_{n-k},\dots,s_n | s_1, s_2, \dots, s_{n-k-1}) ,它的实际意义是根据已知的上文 ,它的实际意义是根据已知的上文 ,它的实际意义是根据已知的上文 input = {s_1, s_2, \dots, s_{n-k-1}} 预测未知的下文 预测未知的下文 预测未知的下文 output={s_{n-k},\dots,s_k} ,因此语言模型可以表示为 ,因此语言模型可以表示为 ,因此语言模型可以表示为 p(output|input) 。对于一个有监督的任务,它可以建模为 。对于一个有监督的任务,它可以建模为 。对于一个有监督的任务,它可以建模为 p(output|input,task) $的形式。在decaNLP中,他们提出的MQAN模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个分类任务,而无需再为每一个子任务单独设计一个模型。
基于上面的思想,作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。例如当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。
综上,GPT-2 的核心思想就是,当模型的容量非常大且数据量足够丰富时,仅仅靠语言模型的学习便可以完成其他有监督学习的任务,不需要在下游任务微调。
GPT-2的数据集
GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
模型结构
在模型结构方面,整个 GPT-2 的模型框架与 GPT-1 相同,只是做了几个地方的调整,这些调整更多的是被当作训练时的 trick,而不作为 GPT-2 的创新,具体为以下几点:
- 后置层归一化( post-norm )改为前置层归一化( pre-norm );
- 在模型最后一个自注意力层之后,额外增加一个层归一化;
- 调整参数的初始化方式,按残差层个数进行缩放,缩放比例为$ 1 : \sqrt[]{n} $;
- 输入序列的最大长度从 512 扩充到 1024;
其中,关于 post-norm 和 pre-norm 可以参考《Learning Deep Transformer Models for Machine Translation》。两者的主要区别在于,post-norm 将 transformer 中每一个 block 的层归一化放在了残差层之后,而 pre-norm 将层归一化放在了每个 block 的输入位置,如下图所示:
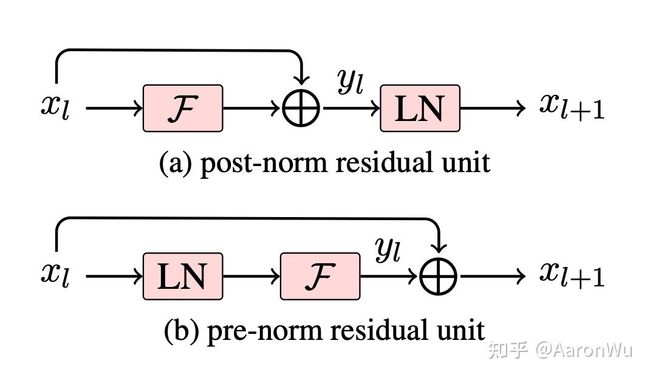
GPT-2 进行上述模型调整的主要原因在于,随着模型层数不断增加,梯度消失和梯度爆炸的风险越来越大,这些调整能够减少预训练过程中各层之间的方差变化,使梯度更加稳定。
其中 117M 参数等价于 GPT-1 模型,345M 参数模型用于对标同期的 BERT-large 模型。
其他改动
- 同样使用了使用字节对编码构建字典,字典的大小为 50,257 ;
- 滑动窗口的大小为 1,024 ;
- batchsize的大小为 512 ;
- 将残差层的初始化值用$ 1/\sqrt{N} $进行缩放,其中 N 是残差层的个数。
最终 GPT-2 提供了四种规模的模型:

GPT-2的性能
- 在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
- 在“Children’s Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
- “LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
- 在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
- 在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
- GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
与 GPT-1 的区别
整体来看,GPT-2 相比于 GPT-1 有如下几点区别:
- 主推 zero-shot,而 GPT-1 为 pre-train + fine-tuning;
- 训练数据规模更大,GPT-2 为 800w 文档 40G,GPT-1 为 5GB;
- 模型大小,GPT-2 最大 15 亿参数,GPT-1为 1 亿参数;
- 模型结构调整,层归一化和参数初始化方式;
- 训练参数,batch_size 从 64 增加到 512,上文窗口大小从 512 增加到 1024,等等;
总结
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了我们下面要介绍的GPT-3。
GPT-3
虽然 GPT-2 主推的 zero-shot 在创新度上有比较高的水平,但是由于其在效果上表现平平,所以在业界并没有取得比较大的影响力,而 GPT-3 正是为了解决效果上的问题而提出的。GPT-3 不再去追求那种极致的不需要任何样本就可以表现很好的模型,而是考虑像人类的学习方式那样,仅仅使用极少数样本就可以掌握某一个任务,因此就引出了 GPT-3 标题 Language Models are Few-Shot Learners。
模型结构
在模型结构上,GPT-3 延续使用 GPT 模型结构,但是引入了 Sparse Transformer 中的 sparse attention 模块(稀疏注意力)。
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)
sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)
具体来说,sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,… 的 token,其他所有 token 的注意力都设为 0,如下图所示:
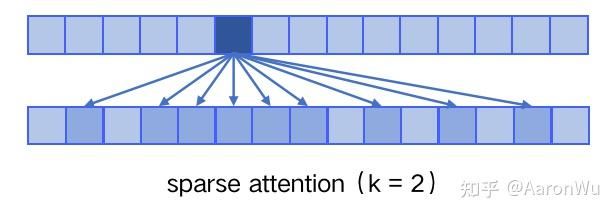
使用 sparse attention 的好处主要有以下两点:
- 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
- 具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少;
另外在网络容量上做了很大的提升,具体如下:
- GPT-3采用了 96 层的多头transformer,头的个数为 96 ;
- 词向量的长度是 12,888 ;
- 上下文划窗的窗口大小提升至 2,048 个token;
- 使用了alternating dense和locally banded sparse attention。
数据集
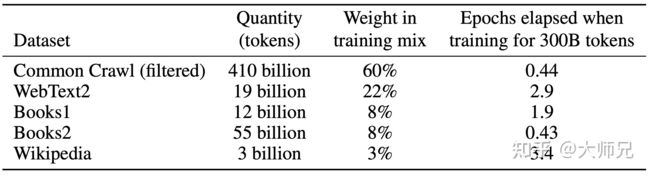
GPT-3共训练了5个不同的语料,分别是低质量的Common Crawl,高质量的WebText2,Books1,Books2和Wikipedia,GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到,如表1所示。
下游评估方式
GPT-3 在下游任务的评估与预测时,提供了三种不同的方法:
Zero-shot:仅使用当前任务的自然语言描述,不进行任何梯度更新;
One-shot:当前任务的自然语言描述,加上一个简单的输入输出样例,不进行任何梯度更新;
Few-shot:当前任务的自然语言描述,加上几个简单的输入输出样例,不进行任何梯度更新;·
其中 Few-shot 也被称为 in-context learning,虽然它与 fine-tuning 一样都需要一些有监督标注数据,但是两者的区别是:
- 【本质区别】fine-tuning 基于标注数据对模型参数进行更新,而 in-context learning 使用标注数据时不做任何的梯度回传,模型参数不更新;
- in-context learning 依赖的数据量(10~100)远远小于 fine-tuning 一般的数据量;
In-context learning
In-context learning是这篇论文中介绍的一个重要概念,要理解in-context learning,需要先理解meta-learning(元学习)。对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
这里的介绍使用的是MAML(Model-Agnostic Meta-Learning)算法,正常的监督学习是将一个批次的数据打包成一个batch进行学习。但是元学习是将一个个任务打包成batch,每个batch分为支持集(support set)和质询集(query set),类似于学习任务中的训练集和测试集。

对一个网络模型 f ,其参数表示为$ \theta $,它的初始化值被叫做meta-initialization。MAML的目标则是学习一组meta-initialization,能够快速应用到其它任务中。MAML的迭代涉及两次参数更新,分别是内循环(inner loop)和外循环(outer loop)。内循环是根据任务标签快速的对具体的任务进行学习和适应,而外学习则是对meta-initialization进行更新。直观的理解,我用一组meta-initialization去学习多个任务,如果每个任务都学得比较好,则说明这组meta-initialization是一个不错的初始化值,否则我们就去对这组值进行更新,如图4所示。目前的实验结果表明元学习距离学习一个通用的词向量模型还是有很多工作要做的。

而GPT-3中据介绍的in-context learning(情境学习)则是元学习的内循环,而基于语言模型的SGT则是外循环,如图5所示。

而另外一个方向则是提供容量足够大的transformer模型来对语言模型进行建模。而近年来使用大规模的网络来训练语言模型也成为了非常行之有效的策略(图6),这也促使GPT-3一口气将模型参数提高到 1,750 亿个。

结果
在few-shot learning中,提供若干个( 10 - 100 个)示例和任务描述供模型学习。one-shot laerning是提供1个示例和任务描述。zero-shot则是不提供示例,只是在测试时提供任务相关的具体描述。作者对这3种学习方式分别进行了实验,实验结果表明,三个学习方式的效果都会随着模型容量的上升而上升,且few shot > one shot > zero show。
从理论上讲GPT-3也是支持fine-tuning的,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。
并且犹如可以看出,当我们想要线性的提升一个任务的效果时,往往需要指数级的提升模型的规模和所需的数据量。

GPT-3的性能
仅仅用惊艳很难描述GPT-3的优秀表现。首先,在大量的语言模型数据集中,GPT-3超过了绝大多数的zero-shot或者few-shot的state-of-the-art方法。另外GPT-3在很多复杂的NLP任务中也超过了fine-tune之后的state-of-the-art方法,例如闭卷问答,模式解析,机器翻译等。除了这些传统的NLP任务,GPT-3在一些其他的领域也取得了非常震惊的效果,例如进行数学加法,文章生成,编写代码等。
GPT-3有什么问题?
既然 ChatGPT 是由 GPT-3 迭代过来的,那么原有的 GPT-3 究竟有哪些问题?ChatGPT 又是如何做的改进?
如果你明白了上面两个问题,那么 ChatGPT 的核心你就算真正掌握了。
GPT-3 最大的问题就是训练目标和用户意图不一致。也就是 GPT-3 并没有真正拟合用户真实的问题(prompt)。
GPT-3 本质上是语言模型,优化目标也是标准语言模型的目标,即最大化下一个词出现的概率。GPT-3 的核心技术是 Next-token-prediction 和 Masked-language-modeling。
在第一种方法中,模型被给定一个词序列作为输入,并被要求预测序列中的下一个词。如果为模型提供输入句子:
“猫坐在”
它可能会将下一个单词预测为「垫子」、「椅子」或「地板」,因为在前面的上下文中,这些单词出现的概率很高。
Masked-language-modeling 方法是 Next-token-prediction 的变体,其中输入句子中的一些词被替换为特殊 token,例如 [MASK]。然后,模型被要求预测应该插入到 mask 位置的正确的词。如果给模型一个句子:
“The [MASK] sat on the ”
它可能会预测 MASK 位置应该填的词是「cat」、「dog」。
这些目标函数的优点之一是,它允许模型学习语言的统计结构,例如常见的词序列和词使用模式。这通常有助于模型生成更自然、更流畅的文本,并且是每个语言模型预训练阶段的重要步骤。
然而这些目标函数也可能导致问题,这主要是因为模型无法区分重要错误和不重要错误。一个非常简单的例子是,如果给模型输入句子:
“罗马帝国[MASK]奥古斯都的统治”
它可能会预测 MASK 位置应该填入「开始于」或「结束于」,因为这两个词的出现概率都很高。
更一般地说,这些训练策略可能会导致语言模型在某些更复杂的任务中出现偏差,因为仅经过训练以预测文本序列中的下一个词(或掩码词)的模型可能不一定会学习一些其含义的更高层次的表示。因此,该模型难以泛化到需要更深入地理解语言的任务或上下文。
这也导致了 GPT-3 这样的语言模型,很难理解用户的真实意图,经常出现答非所问的情况,一本正经的胡说八道。
另外还有一些缺陷如下:
- 对于一些命题没有意义的问题,GPT-3不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于40TB海量数据的存在,很难保证GPT-3生成的文章不包含一些非常敏感的内容,例如种族歧视,性别歧视,宗教偏见等;
- 受限于transformer的建模能力,GPT-3并不能保证生成的一篇长文章或者一本书籍的连贯性,存在下文不停重复上文的问题。