Redis
Nosql概述
1、为什么要用Nosql
1、单机mySQL的年代

90年代,一个基本的网站访问一般不会有太大,单个数据库完全够了,
整个网站的瓶颈是什么?
- 数据量太大,一个机器放不下!
- 数据索引(B+树)
- 访问量(读写混合),一个服务器承受不了
只要发生以上情况之一,就必须晋级。
2、Mencached(缓存)+MySQL+垂直拆分(读写分离)
网站80%的情况都在读,每次都去查询数据库就十分麻烦!所以在中间加个缓存保证效率!
发展过程:优化数据结构和索引–>文件缓存(IO)–>Mencached(当前热门的技术!)

3、分库分表+水平拆分+MySQL集群
技术和业务在发展的同时,对人的要求也越来越高!
本质:数据库(读写)
早些年Myisam:表锁、十分影响效率!高并发就会出现问题
转战innodb:行锁
慢慢的开始使用分库分表来解决写的压力!MySQL在那个年代推出了表分区!这个并没有多少公司在用!
MySQL的集群,很好的满足了那个年代的需求!
4、如今最近的年代
2010–2020十年之间,时间已经发生了翻天复地的变化;(定位,也是一种数据,隐喻、热榜!)
MySQL等关系型数据库已经不够了!数据量很多,变化很快!
MySQL有的使用它来存储一些比较大的问文件。博客、图片!数据库变很大,下来就低了!

目前基本的互连网项目

为什么要用NoSQL!
用户的个人信息,社交网络,地理位置。用户自己产生的数据,用户的日志等等爆发式增长,就没有办法使用关系型数据库存储!
这个时候就需要使用NoSQL数据库了,NoSQL可以很好的处理以上的情况!
什么是NoSQL
Nosql
NoSQL=Not only SQL(不仅仅是sql)
关系型数据库:表格, 行, 列
泛指非关系型数据库的,随着web2.0互连网的诞生!传统的关系型数据库很难对付web2.0时代!尤其是超大规模的高并发的社区!站长!暴露出来很多难以克服的问题,NoSQL在当今大数据环境下发展十分迅速,redis是当前发展最快的!
很多的数据类用户的个人信息,社交网络,地理位置。这些数据类型的存储不需要一个固定的格式!不需要多余的操作就可以横向的扩展的!Map
NoSQL的特点
1、方便扩展(数据之间没有关系,很好扩展!)
2、大数据量高性能(Redis一秒写8万次,读取11万,NoSQL的缓存记录级,是一种颗粒度的缓存,性能会比较高!)
3、数据类型是多样型的!(不需要事先设计数据库!随取随用!如果是数据量非常大,很多人就无法设计了)
4、传统RDBMS和NOSQL
传统的RDBMS(关系型数据库)
- 结构化组织
- SQL语言
- 数据和关系都存储在单独的表中 (row\col)
- 操作操作,数据定义语言
- 严格的一致性
- 基础事务
- 。。。
NoSQL
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库了(社交关系)
- 最终一致性
- CAP定理和BASE
- 高性能,高可用,高可扩展
- 。。。
了解:3V+3高
大数据时代的3V:主要是描述问题的
海量、多样和实时
大数据时代的3高:主要是对程序的要求
高并发、高可扩(随时水平拆分)、高性能(保证用户体验和性能)
真正在公司中的时间:NoSQL+RDBMS一起使用才是最强的。阿里巴巴吧架构演进!
技术没有高低之分,就看如何使用!(提高内功,思维的方法!)
阿里巴巴的演进分析
思考问题:淘宝网页的数据都放在一个数据库中的吗
技术急不得,越是慢慢学,才能越扎实!
开源才是技术王道!
任何一家互连网公司,
大量公司做的都是相同的业务;(竞品协议)
竞争越来越高,业务越来越完善,开发要求也越来越高!

如果想当一个架构师:没有什么是加一层不能解决的 !没有就家两层!
#1、商品的基本信息
名称、价格、上架信息;
关系型数据库就可以解决了!MySQL/oeacle
淘宝内部的MySQL不是真正的MySQL
#2、商品的描述、评论(蚊子比较多)
文档型数据库中,MongoDB
#3、图片
分布式文件系统FastDFS
- 淘宝自己的 TFS
- Google的 GFS
- Hadoop HDFS
- 阿里云的 OSS
#4、商品的关键字(搜索)
- 搜索引擎 solr
- Isearch
#5、商品热门的波段信息
- 内存数据库
- redis
#6、商品的交易,外部的支付接口
- 三方应用
大型互联网的应用问题”:
- 数据类型太多了!
- 数据源繁多,经常重构!
- 数据要改造,大面积改造!
解决问题:
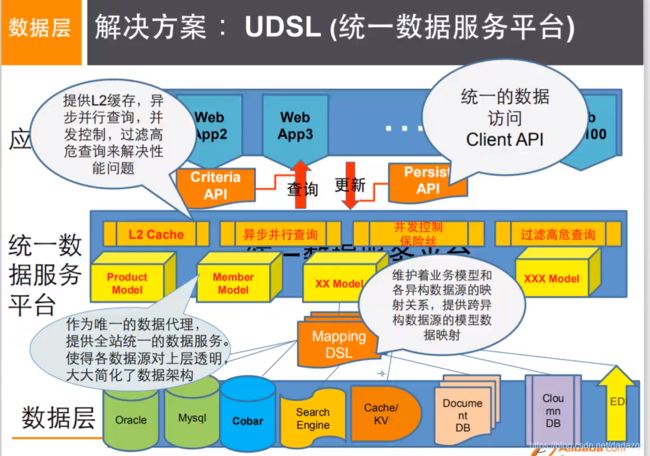
加一层,同一接口

NOSQL的四个分类
KV键值对:
- 新浪:redis
- 美团:redis+tair
- 阿里百度:redis+memechche
文档型数据库(bson和json格式)
- MongoDB(一般必须掌握)
- MongoDB是一个基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档!
- MongoDB是一个介于关系型数据库和非关系型数据库数据中间的产品!MongoDB是非关系型数据库中功能最丰富,是最想关系型数据库的!
- ConthDB
列存储数据库
- HBase
- 分布式文件系统
图关系数据库

- 他不是存图形,放的是关系,比如:朋友圈
- Neo4j、InfoGrid

Redis入门
基础的知识
redis默认有16个数据库
默认使用的是第0个数据库
可以使用select进行切换
#查看数据库所有的key
keys *
#清除所有数据库的内容
flush all
Redis是单线程的
redis是很快的,redis是基于内存操作,CPU不是redis的性能瓶颈,redis的瓶颈是根据机器的内存和网络带宽,即然可以使用单线程实现,就使用单线程实现!
SimpleKV
一个键值数据库包括了:访问框架、操作模块、索引模块和存储模块四部分。
访问模式:
一、通过函数库调用的方式供外部使用:RocksDB
二、通过网络框架以Socket通信的形式对外提供键值对操作:Memcache和Redis
Memcached和Redis使用哈希表作为key-value索引
RocksDB则用跳表作为内存中的k-v索引
如何快速定位键值对的位置?
redis使用哈希表作为索引,原因是,其键值数据基本都是保存在内存中,而内存的高性能随机访问特性很好地与哈希表O(1)的操作复杂度相匹配
不同操作的具体逻辑?
- 对于GET/SCAN操作而言,此时根据value的存储位置返回value值即可。
- PUT,一个新数据需要,SampleKV为该键值对分配内存空间
- DELETE操作,SimpleKV删除键值对,释放空间,由分配器完成
如何实现重启后快速提供服务?
SimpleKV直接采用文件形式,将键值数据通过调用本地文件系统的操作接口保存在磁盘上。此时SimpleKV就之要考虑何时将内存中的键值对保存到文件中。
一种方式,对于每一个键值对,SimpleKV都对齐进行落盘保存,这虽然让SimpleKV的数据更可靠,但是,因为每次都要写盘,SimpleKV的性能受到很大的影响
另一种方式是,SimpleKV 只是周期性地把内存中的键值数据保存到文件中,这样可以避免频繁写盘操作的性能影响。但是,一个潜在的代价是 SimpleKV 的数据仍然有丢失的风险。
从这张对比图中,我们可以看到,从 SimpleKV 演进到 Redis,有以下几个重要变化: - - Redis 主要通过网络框架进行访问,而不再是动态库了,这也使得 Redis 可以作为一个基础性的网络服务进行访问,扩大了 Redis 的应用范围。
- Redis 数据模型中的 value 类型很丰富,因此也带来了更多的操作接口,例如面向列表的 LPUSH/LPOP,面向集合的 SADD/SREM 等。在下节课,我将和你聊聊这些 value 模型背后的数据结构和操作效率,以及它们对 Redis 性能的影响。
- Redis 的持久化模块能支持两种方式:日志(AOF)和快照(RDB),这两种持久化方式具有不同的优劣势,影响到 Redis 的访问性能和可靠性。
- SimpleKV 是个简单的单机键值数据库,但是,Redis 支持高可靠集群和高可扩展集群,因此,Redis 中包含了相应的集群功能支撑模块。
数据结构:快速的Redis有哪些慢操作?
为啥 Redis 能有这么突出的表现呢?
一方面,这是因为它是内存数据库,所有操作都在内存上完成,内存的访问速度本身就很快。
另一方面,这要归功于它的数据结构。这是因为,键值对是按一定的数据结构来组织的,操作键值对最终就是对数据结构进行增删改查操作,所以高效的数据结构是 Redis 快速处理数据的基础。这节课,我就来和你聊聊数据结构。
底层数据结构一共有 6 种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。

String 类型的底层实现只有一种数据结构,也就是简单动态字符串。而 List、Hash、Set 和 Sorted Set 这四种数据类型,都有两种底层实现结构。通常情况下,我们会把这四种类型称为集合类型,它们的特点是一个键对应了一个集合的数据。
键和值用什么结构组织?
Redis 使用了一个哈希表来保存所有键值对。
一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,我们常说,一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据
哈希桶中的元素保存的并不是值本身,而是指向具体值的指针。
哈希桶中的 entry 元素中保存了key和value指针,分别指向了实际的键和值,这样一来,即使值是一个集合,也可以通过*value指针被查找到。

哈希表的最大好处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对——我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
为什么哈希表操作变慢了?
Redis 解决哈希冲突的方式,就是链式哈希。链式哈希也很容易理解,就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
为了使 rehash 操作更高效,Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
1. 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
2. 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
3. 释放哈希表 1 的空间。
渐进式 rehash
Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。如下图所示:

这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问。
集合数据操作效率
集合的底层数据结构
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,如下图所示:

如果我们要在链表中查找 33 这个元素,只能从头开始遍历链表,查找 6 次,直到找到 33 为止。此时,复杂度是 O(N),查找效率很低。
为了提高查找速度,我们来增加一级索引:从第一个元素开始,每两个元素选一个出来作为索引。这些索引再通过指针指向原始的链表。例如,从前两个元素中抽取元素 1 作为一级索引,从第三、四个元素中抽取元素 11 作为一级索引。此时,我们只需要 4 次查找就能定位到元素 33 了。
如果我们还想再快,可以再增加二级索引:从一级索引中,再抽取部分元素作为二级索引。例如,从一级索引中抽取 1、27、100 作为二级索引,二级索引指向一级索引。这样,我们只需要 3 次查找,就能定位到元素 33 了。
可以看到,这个查找过程就是在多级索引上跳来跳去,最后定位到元素。这也正好符合“跳”表的叫法。当数据量很大时,跳表的查找复杂度就是 ** O(logN) **
查找的时间复杂度给这些数据结构分下类了:

不同操作的复杂度
- 单元素操作是基础;
- 范围操作非常耗时;
- 统计操作通常高效;
- 例外情况只有几个。
第一,单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。 例如,Hash 类型的 HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET 和 HDEL 是对哈希表做操作,所以它们的复杂度都是 O(1);Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。
第二,范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据,比如 Hash 类型的 HGETALL 和 Set 类型的 SMEMBERS,或者返回一个范围内的部分数据,比如 List 类型的 LRANGE 和 ZSet 类型的 ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免。
Redis 从 2.8 版本开始提供了 SCAN 系列操作(包括 HSCAN,SSCAN 和 ZSCAN),这类操作实现了渐进式遍历,每次只返回有限数量的数据。这样一来,相比于 HGETALL、SMEMBERS 这类操作来说,就避免了一次性返回所有元素而导致的 Redis 阻塞。
第三,统计操作,是指集合类型对集合中所有元素个数的记录,例如 LLEN 和 SCARD。这类操作复杂度只有 O(1),这是因为当集合类型采用压缩列表、双向链表、整数数组这些数据结构时,这些结构中专门记录了元素的个数统计,因此可以高效地完成相关操作。
第四,例外情况,是指某些数据结构的特殊记录,例如压缩列表和双向链表都会记录表头和表尾的偏移量。这样一来,对于 List 类型的 LPOP、RPOP、LPUSH、RPUSH 这四个操作来说,它们是在列表的头尾增删元素,这就可以通过偏移量直接定位,所以它们的复杂度也只有 O(1),可以实现快速操作。
Redis 之所以能快速操作键值对,一方面是因为 O(1) 复杂度的哈希表被广泛使用,包括 String、Hash 和 Set,它们的操作复杂度基本由哈希表决定,另一方面,Sorted Set 也采用了 O(logN) 复杂度的跳表。不过,集合类型的范围操作,因为要遍历底层数据结构,复杂度通常是 O(N)。这里,我的建议是:用其他命令来替代,例如可以用 SCAN 来代替,避免在 Redis 内部产生费时的全集合遍历操作。
我们不能忘了复杂度较高的 List 类型,它的两种底层实现结构:双向链表和压缩列表的操作复杂度都是 O(N)。因此,我的建议是**:因地制宜地使用 List 类型**。例如,既然它的 POP/PUSH 效率很高,那么就将它主要用于 FIFO 队列场景,而不是作为一个可以随机读写的集合。
为什么单线程的 Redis 能那么快?
Redis 是单线程,主要是指 **Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。**但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
Redis 为什么用单线程?
采用多线程后,如果没有良好的系统设计,实际得到的结果,其实是右图所展示的那样。我们刚开始增加线程数时,系统吞吐率会增加,但是,再进一步增加线程时,系统吞吐率就增长迟缓了,有时甚至还会出现下降的情况。
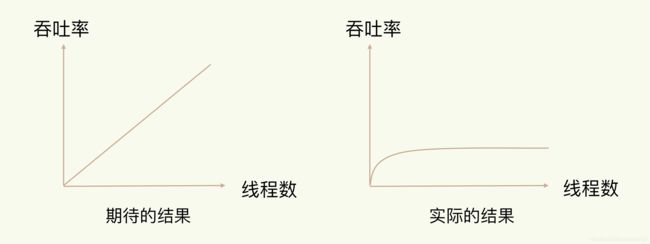
系统中通常会存在被多线程同时访问的共享资源,比如一个共享的数据结构。当有多个线程要修改这个共享资源时,为了保证共享资源的正确性,就需要有额外的机制进行保证,而这个额外的机制,就会带来额外的开销。
多线程编程模式面临的共享资源的并发访问控制问题。

单线程 Redis 为什么那么快?
一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。
另一方面,就是 Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。
基本 IO 模型与阻塞点
以 Get 请求为例,SimpleKV 为了处理一个 Get 请求,需要监听客户端请求(bind/listen),和客户端建立连接(accept),从 socket 中读取请求(recv),解析客户端发送请求(parse),根据请求类型读取键值数据(get),最后给客户端返回结果,即向 socket 中写回数据(send)。
bind/listen、accept、recv、parse 和 send 属于网络 IO 处理,而 get 属于键值数据操作。既然 Redis 是单线程,那么,最基本的一种实现是在一个线程中依次执行上面说的这些操作。

在这里的网络 IO 操作中,有潜在的阻塞点,分别是 accept() 和 recv()。当 Redis 监听到一个客户端有连接请求,但一直未能成功建立起连接时,会阻塞在 accept() 函数这里,导致其他客户端无法和 Redis 建立连接。类似的,当 Redis 通过 recv() 从一个客户端读取数据时,如果数据一直没有到达,Redis 也会一直阻塞在 recv()。
非阻塞模式

当 Redis 调用 accept() 但一直未有连接请求到达时,Redis 线程可以返回处理其他操作,而不用一直等待。
Redis 调用 recv() 后,如果已连接套接字上一直没有数据到达,Redis 线程同样可以返回处理其他操作。
基于多路复用的高性能 I/O 模型
该机制允许内核中,同时存在多个监听套接字和已连接套接字。
图中的多个 FD 就是刚才所说的多个套接字。Redis 网络框架调用 epoll 机制,让内核监听这些套接字。

select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
这些事件会被放进一个事件队列,Redis 单线程对该事件队列不断进行处理。这样一来,Redis 无需一直轮询是否有请求实际发生,这就可以避免造成 CPU 资源浪费。同时,Redis 在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调。因为 Redis 一直在对事件队列进行处理,所以能及时响应客户端请求,提升 Redis 的响应性能。
AOF日志,Redis如何避免数据丢失?
AOF 日志正好相反,它是写后日志,“写后”的意思是 Redis 是先执行命令,把数据写入内存,然后才记录日志,如下图所示:

传统数据库的日志,例如 redo log(重做日志),记录的是修改后的数据,而 AOF 里记录的是 Redis 收到的每一条命令,这些命令是以文本形式保存的。
我们以 Redis 收到“set testkey testvalue”命令后记录的日志为例,看看 AOF 日志的内容。其中,“*3”表示当前命令有三个部分,每部分都是由“$+数字”开头,后面紧跟着具体的命令、键或值。这里,“数字”表示这部分中的命令、键或值一共有多少字节。例如,“$3 set”表示这部分有 3 个字节,也就是“set”命令。

而写后日志这种方式,就是先让系统执行命令,只有命令能执行成功,才会被记录到日志中,否则,系统就会直接向客户端报错。所以,Redis 使用写后日志这一方式的一大好处是,可以避免出现记录错误命令的情况。
AOF 还有一个好处:它是在命令执行后才记录日志,所以不会阻塞当前的写操作。
AOF 也有两个潜在的风险。
- 首先,如果刚执行完一个命令,还没有来得及记日志就宕机了,那么这个命令和相应的数据就有丢失的风险。
- 其次,AOF 虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。这是因为,AOF 日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就会导致写盘很慢,进而导致后续的操作也无法执行了。
控制一个写命令执行完后 AOF 日志写回磁盘的时机解决以上问题
三种写回策略
Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
三种写会策略,优缺点

命令越来越多,AOF文件过大,带来性能问题
主要在于以下三个方面:
一是,文件系统本身对文件大小有限制,无法保存过大的文件;
二是,如果文件太大,之后再往里面追加命令记录的话,效率也会变低;
三是,如果发生宕机,AOF 中记录的命令要一个个被重新执行,用于故障恢复,如果日志文件太大,整个恢复过程就会非常缓慢,这就会影响到 Redis 的正常使用。
日志文件太大了怎么办?
AOF 重写机制就是在重写时,Redis 根据数据库的现状创建一个新的 AOF 文件,也就是说,读取数据库中的所有键值对,然后对每一个键值对用一条命令记录它的写入。比如说,当读取了键值对“testkey”: “testvalue”之后,重写机制会记录 set testkey testvalue 这条命令。这样,当需要恢复时,可以重新执行该命令,实现“testkey”: “testvalue”的写入。
为什么重写机制可以把日志文件变小呢? 实际上,重写机制具有**“多变一”功能**。所谓的“多变一”,也就是说,旧日志文件中的多条命令,在重写后的新日志中变成了一条命令。
AOF 文件是以追加的方式,逐一记录接收到的写命令的。当一个键值对被多条写命令反复修改时,AOF 文件会记录相应的多条命令。但是,在重写的时候,是根据这个键值对当前的最新状态,为它生成对应的写入命令。这样一来,一个键值对在重写日志中只用一条命令就行了,而且,在日志恢复时,只用执行这条命令,就可以直接完成这个键值对的写入了。

AOF 重写会阻塞吗?
和 AOF 日志由主线程写回不同,重写过程是由后台子进程 bgrewriteaof 来完成的,这也是为了避免阻塞主线程,导致数据库性能下降。
“一个拷贝,两处日志”。
“一个拷贝”就是指,每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。此时,fork 会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了数据库的最新数据。然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
“两处日志”因为主线程未阻塞,仍然可以处理新来的操作。此时,如果有写操作,第一处日志就是指正在使用的 AOF 日志,Redis 会把这个操作写到它的缓冲区。这样一来,即使宕机了,这个 AOF 日志的操作仍然是齐全的,可以用于恢复。第二处日志,就是指新的 AOF 重写日志。这个操作也会被写到重写日志的缓冲区。这样,重写日志也不会丢失最新的操作。等到拷贝数据的所有操作记录重写完成后,重写日志记录的这些最新操作也会写入新的 AOF 文件,以保证数据库最新状态的记录。此时,我们就可以用新的 AOF 文件替代旧文件了。

每次 AOF 重写时,Redis 会先执行一个内存拷贝,用于重写;
然后,使用两个日志保证在重写过程中,新写入的数据不会丢失。而且,因为 Redis 采用额外的线程进行数据重写,所以,这个过程并不会阻塞主线程。
内存快照:宕机后,Redis如何实现快速恢复?
给哪些内存数据做快照?
Redis 的数据都在内存中,为了提供所有数据的可靠性保证,它执行的是全量快照,也就是说,把内存中的所有数据都记录到磁盘中。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。
- save:在主线程中执行,会导致阻塞;
- bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。
快照时数据能修改吗?
Redis 就会借助操作系统提供的写时复制技术(Copy-On-Write, COW),在执行快照的同时,正常处理写操作。
bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。
如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。

Redis 会使用 bgsave 对当前内存中的所有数据做快照,这个操作是子进程在后台完成的,这就允许主线程同时可以修改数据。
可以每秒做一次快照吗?
如果频繁地执行全量快照,也会带来两方面的开销。
一方面,频繁将全量数据写入磁盘,会给磁盘带来很大压力,多个快照竞争有限的磁盘带宽,前一个快照还没有做完,后一个又开始做了,容易造成恶性循环。
另一方面,bgsave 子进程需要通过 fork 操作从主线程创建出来。虽然,子进程在创建后不会再阻塞主线程,但是,fork 这个创建过程本身会阻塞主线程,而且主线程的内存越大,阻塞时间越长。如果频繁 fork 出 bgsave 子进程,这就会频繁阻塞主线程了。
此时,我们可以做增量快照,所谓增量快照,就是指,**做了一次全量快照后,后续的快照只对修改的数据进行快照记录,这样可以避免每次全量快照的开销。**我们需要记住哪些数据被修改了。

混合使用 AOF 日志和内存快照
内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。这样一来,快照不用很频繁地执行,这就避免了频繁 fork 对主线程的影响。而且,**AOF 日志也只用记录两次快照间的操作,**也就是说,不需要记录所有操作了,因此,就不会出现文件过大的情况了,也可以避免重写开销。
T1 和 T2 时刻的修改,用 AOF 日志记录,等到第二次做全量快照时,就可以清空 AOF 日志,因为此时的修改都已经记录到快照中了,恢复时就不再用日志了。

关于 AOF 和 RDB 的选择问题,我想再给你提三点建议:
- 数据不能丢失时,内存快照和 AOF 的混合使用是一个很好的选择;
- -如果允许分钟级别的数据丢失,可以只使用 RDB;
- 如果只用 AOF,优先使用 everysec 的配置选项,因为它在可靠性和性能之间取了一个平衡。
数据同步:主从库如何实现数据一致?
我们学习了 AOF 和 RDB,如果 Redis 发生了宕机,它们可以分别通过回放日志和重新读入 RDB 文件的方式恢复数据,从而保证尽量少丢失数据,提升可靠性。
高可靠:一是数据尽量少丢失,二是服务尽量少中断。
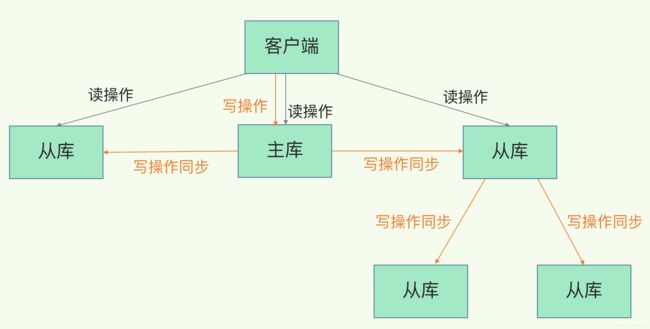
Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。
- **读操作:**主库、从库都可以接收;
- **写操作:**首先到主库执行,然后,主库将写操作同步给从库。
而主从库模式一旦采用了读写分离,所有数据的修改只会在主库上进行,不用协调三个实例。主库有了最新的数据后,会同步给从库,这样,主从库的数据就是一致的。
主从库间如何进行第一次同步?
当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
 第一阶段是主从库间建立连接、协商同步的过程,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。
第一阶段是主从库间建立连接、协商同步的过程,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。
从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。
- runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。
- offset,此时设为 -1,表示第一次复制。
主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。
FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
第二阶段,主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。 这个过程依赖于内存快照生成的 RDB 文件。
具体来说,主库执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。这是因为从库在通过 replicaof 命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。
在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
**第三个阶段,主库会把第二阶段执行过程中新收到的写命令,再发送给从库。**具体的操作是,当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
主从级联模式分担全量复制时的主库压力
通过“主 - 从 - 从”模式将主库生成 RDB 和传输 RDB 的压力,以级联的方式分散到从库上。
我们在部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置较高的从库),用于级联其他的从库。然后,我们可以再选择一些从库(例如三分之一的从库),在这些从库上执行如下命令,让它们和刚才所选的从库,建立起主从关系
这样一来,这些从库就会知道,在进行同步时,不用再和主库进行交互了,只要和级联的从库进行写操作同步就行了,这就可以减轻主库上的压力,
 一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
主从库间网络断了怎么办?
从 Redis 2.8 开始,网络断了之后,主从库会采用增量复制的方式继续同步。听名字大概就可以猜到它和全量复制的不同:全量复制是同步所有数据,而增量复制只会把主从库网络断连期间主库收到的命令,同步给从库。
当主从库断连后,主库会把断连期间收到的写操作命令,写入 replication buffer,同时也会把这些操作命令也写入** repl_backlog_buffer** 这个缓冲区。
repl_backlog_buffer 是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。
从库在复制完写操作命令后,它在缓冲区中的读位置也开始逐步偏移刚才的起始位置,此时,从库已复制的偏移量 slave_repl_offset 也在不断增加。正常情况下,这两个偏移量基本相等。

主从库的连接恢复之后,从库首先会给主库发送 psync 命令,并把自己当前的 slave_repl_offset 发给主库,主库会判断自己的 master_repl_offset 和 slave_repl_offset 之间的差距。
在网络断连阶段,主库可能会收到新的写操作命令,所以,一般来说,master_repl_offset 会大于 slave_repl_offset。此时,主库只用把 master_repl_offset 和 slave_repl_offset 之间的命令操作同步给从库就行。
主库和从库之间相差了 put d e 和 put d f 两个操作,在增量复制时,主库只需要把它们同步给从库,就行了。

因为 repl_backlog_buffer 是一个环形缓冲区,所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致。
解决的办法:
进行一次全量复制
避免这一情况
我们可以调整 repl_backlog_size 这个参数。这个参数和所需的缓冲空间大小有关。缓冲空间的计算公式是:缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小。在实际应用中,考虑到可能存在一些突发的请求压力,我们通常需要把这个缓冲空间扩大一倍,即 repl_backlog_size = 缓冲空间大小 * 2,这也就是 repl_backlog_size 的最终值。
这节课,我们一起学习了 Redis 的主从库同步的基本原理,总结来说,有三种模式:
- 全量复制(第一次连接)(“主 - 从 - 从”缓解主库压力)
- 基于长连接的命令传播(连接中同步数据)
- 增量复制(从库挂机了)
哨兵机制:主库挂了,如何不间断服务?
如果主库挂了,我们就需要运行一个新主库,比如说把一个从库切换为主库,把它当成主库。这就涉及到三个问题:
- 主库真的挂了吗?
- 该选择哪个从库作为主库?
- 怎么把新主库的相关信息通知给从库和客户端呢?
在 Redis 主从集群中,哨兵机制是实现主从库自动切换的关键机制,它有效地解决了主从复制模式下故障转移的这三个问题。
哨兵机制的基本流程
哨兵其实就是一个运行在特殊模式下的 Redis 进程,主从库实例运行的同时,它也在运行。哨兵主要负责的就是三个任务:监控、选主(选择主库)和通知。
- 监控是指哨兵进程在运行时,周期性地给所有的 主从库发送PING 命令,检测它们是否仍然在线运行。如果从库没有在规定时间内响应哨兵的 PING 命令,哨兵就会把它标记为**“下线状态”;同样,如果主库也没有在规定时间内响应哨兵的 PING 命令,哨兵就会判定主库下线,然后开始自动切换主库的流程**。
- **选主。**主库挂了以后,哨兵就需要从很多个从库里,按照一定的规则选择一个从库实例,把它作为新的主库。这一步完成后,现在的集群里就有了新主库。
- 通知。在执行通知任务时,哨兵会把新主库的连接信息发给其他从库,让它们执行 replicaof 命令,和新主库建立连接,并进行数据复制。同时,哨兵会把新主库的连接信息通知给客户端,让它们把请求操作发到新主库上。

主观下线和客观下线
哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况,用来判断实例的状态。如果哨兵发现主库或从库对 PING 命令的响应超时了,那么,哨兵就会先把它标记为“主观下线”。
哨兵机制通常会采用多实例组成的集群模式进行部署,这也被称为哨兵集群。引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
在判断主库是否下线时,不能由一个哨兵说了算,**只有大多数的哨兵实例,都判断主库已经“主观下线”了,主库才会被标记为“客观下线”,**这个叫法也是表明主库下线成为一个客观事实了。这个判断原则就是:少数服从多数。同时,这会进一步触发哨兵开始主从切换流程。

客观下线”的标准就是,当有 N 个哨兵实例时,最好要有 N/2 + 1 个实例判断主库为“主观下线”,
如何选定新主库?
一般来说,我把哨兵选择新主库的过程称为**“筛选 + 打分”**。
- 我们在多个从库中,先按照一定的筛选条件,把不符合条件的从库去掉。
- 我们再按照一定的规则,给剩下的从库逐个打分,将得分最高的从库选为新主库,
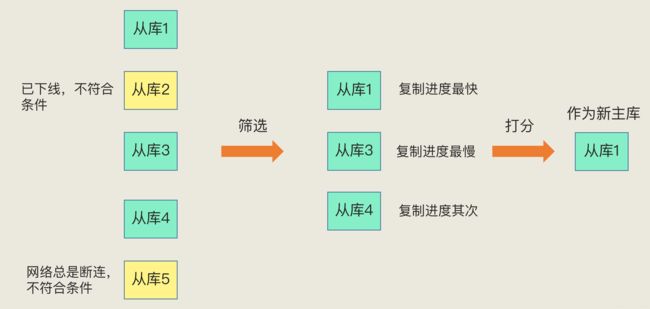
在选主时,**除了要检查从库的当前在线状态,还要判断它之前的网络连接状态。**如果从库总是和主库断连,而且断连次数超出了一定的阈值,我们就有理由相信,这个从库的网络状况并不是太好,就可以把这个从库筛掉了。
你使用配置项 down-after-milliseconds * 10。其中,down-after-milliseconds 是我们认定主从库断连的最大连接超时时间。如果在 down-after-milliseconds 毫秒内,主从节点都没有通过网络联系上,我们就可以认为主从节点断连了。如果发生断连的次数超过了 10 次,就说明这个从库的网络状况不好,不适合作为新主库。
我们可以分别按照三个规则依次进行三轮打分,这三个规则分别是从库优先级、从库复制进度以及从库 ID 号。
第一轮:优先级最高的从库得分高。
用户可以通过 slave-priority 配置项,给不同的从库设置不同优先级。比如,你有两个从库,它们的内存大小不一样,你可以手动给内存大的实例设置一个高优先级。在选主时,哨兵会给优先级高的从库打高分,如果有一个从库优先级最高,那么它就是新主库了。如果从库的优先级都一样,那么哨兵开始第二轮打分。
第二轮:和旧主库同步程度最接近的从库得分高。
如果选择和旧主库同步最接近的那个从库作为主库,那么,这个新主库上就有最新的数据。
我们想要找的从库,它的 slave_repl_offset 需要最接近 master_repl_offset。如果在所有从库中,有从库的 slave_repl_offset 最接近 master_repl_offset,那么它的得分就最高,可以作为新主库。
第三轮:ID 号小的从库得分高。
每个实例都会有一个 ID,这个 ID 就类似于这里的从库的编号。目前,Redis 在选主库时,有一个默认的规定:在优先级和复制进度都相同的情况下,ID 号最小的从库得分最高,会被选为新主库。
首先,哨兵会按照在线状态、网络状态,筛选过滤掉一部分不符合要求的从库,然后,依次按照优先级、复制进度、ID 号大小再对剩余的从库进行打分,只要有得分最高的从库出现,就把它选为新主库。
哨兵集群:哨兵挂了,主从库还能切换吗?
基于 pub/sub 机制的哨兵集群组成
哨兵只要和主库建立起了连接,就可以在主库上发布消息了,比如说发布它自己的连接信息(IP 和端口)。同时,它也可以从主库上订阅消息,获得其他哨兵发布的连接信息。当多个哨兵实例都在主库上做了发布和订阅操作后,它们之间就能知道彼此的 IP 地址和端口。
除了哨兵实例,我们自己编写的应用程序也可以通过 Redis 进行消息的发布和订阅。所以,为了区分不同应用的消息,Redis 会以频道的形式,对这些消息进行分门别类的管理。所谓的频道,实际上就是消息的类别。当消息类别相同时,它们就属于同一个频道。反之,就属于不同的频道。只有订阅了同一个频道的应用,才能通过发布的消息进行信息交换。

哨兵是如何知道从库的 IP 地址和端口的呢?
这是由哨兵向主库发送 INFO 命令来完成的。哨兵 2 给主库发送 INFO 命令,主库接受到这个命令后,就会把从库列表返回给哨兵。接着,哨兵就可以根据从库列表中的连接信息,和每个从库建立连接,并在这个连接上持续地对从库进行监控。哨兵 1 和 3 可以通过相同的方法和从库建立连接。

通过 pub/sub 机制,哨兵之间可以组成集群,同时,哨兵又通过 INFO 命令,获得了从库连接信息,也能和从库建立连接,并进行监控了。
但是,哨兵不能只和主、从库连接。因为,主从库切换后,客户端也需要知道新主库的连接信息,才能向新主库发送请求操作。所以,哨兵还需要完成把新主库的信息告诉客户端这个任务。
基于 pub/sub 机制的客户端事件通知
哨兵就是一个运行在特定模式下的 Redis 实例,只不过它并不服务请求操作,只是完成监控、选主和通知的任务。所以,每个哨兵实例也提供 pub/sub 机制,客户端可以从哨兵订阅消息。哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件。
频道有这么多,一下子全部学习容易丢失重点。为了减轻你的学习压力,我把重要的频道汇总在了一起,涉及几个关键事件,包括主库下线判断、新主库选定、从库重新配置。

让客户端从哨兵这里订阅消息了。具体的操作步骤是,客户端读取哨兵的配置文件后,可以获得哨兵的地址和端口,和哨兵建立网络连接。然后,我们可以在客户端执行订阅命令,来获取不同的事件消息。
有了 pub/sub 机制,哨兵和哨兵之间、哨兵和从库之间、哨兵和客户端之间就都能建立起连接了,再加上我们上节课介绍主库下线判断和选主依据,哨兵集群的监控、选主和通知三个任务就基本可以正常工作了。
由哪个哨兵执行主从切换?
任何一个实例只要自身判断主库“主观下线”后,就会给其他实例发送 is-master-down-by-addr 命令。接着,其他实例会根据自己和主库的连接情况,做出 Y 或 N 的响应,Y 相当于赞成票,N 相当于反对票。
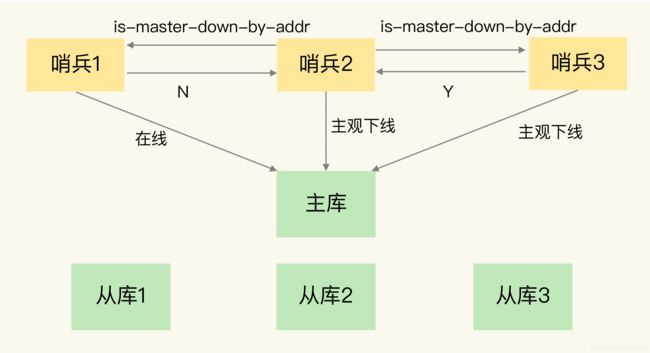
一个哨兵获得了仲裁所需的赞成票数后,就可以标记主库为“客观下线”。这个所需的赞成票数是通过哨兵配置文件中的 quorum 配置项设定的。
此时,这个哨兵就可以再给其他哨兵发送命令,表明希望由自己来执行主从切换,并让所有其他哨兵进行投票。这个投票过程称为**“Leader 选举”。因为最终执行主从切换的哨兵称为 Leader,投票过程就是确定 Leader。
在投票过程中,任何一个想成为 Leader 的哨兵,要满足两个条件:第一,拿到半数以上的赞成票;第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
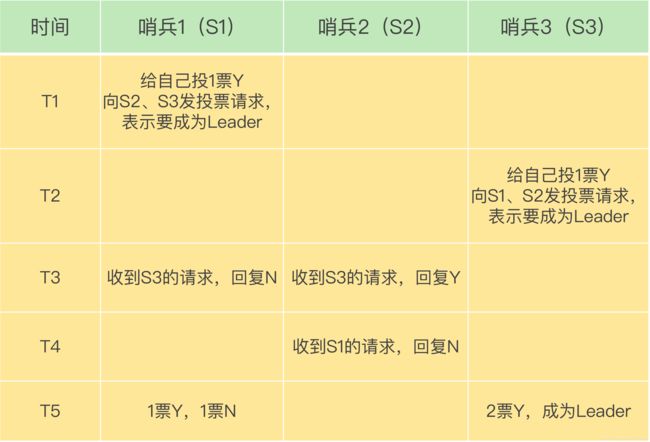
那么这轮投票就不会产生 Leader。哨兵集群会等待一段时间**(也就是哨兵故障转移超时时间的 2 倍),再重新选举。这是因为,哨兵集群能够进行成功投票,很大程度上依赖于选举命令的正常网络传播。如果网络压力较大或有短时堵塞,就可能导致没有一个哨兵能拿到半数以上的赞成票。所以,等到网络拥塞好转之后,再进行投票选举,成功的概率就会增加。
如果哨兵集群只有 2 个实例,此时,一个哨兵要想成为 Leader,必须获得 2 票,而不是 1 票。所以,如果有个哨兵挂掉了,那么,此时的集群是无法进行主从库切换的。因此,通常我们至少会配置 3 个哨兵实例。这一点很重要,你在实际应用时可不能忽略了。
这节课上,我就向你介绍了支持哨兵集群的这些关键机制,包括:
- 基于 pub/sub 机制的哨兵集群组成过程;
- 基于 INFO 命令的从库列表,这可以帮助哨兵和从库建立连接;
- 基于哨兵自身的 pub/sub 功能,这实现了客户端和哨兵之间的事件通知。
切片集群:数据增多了,是该加内存还是实例?
切片集群,也叫分片集群,就是指启动多个 Redis 实例组成一个集群,然后按照一定的规则,把收到的数据划分成多份,每一份用一个实例来保存。
如何保存更多数据?
大内存:纵向扩展
云主机:横向扩展
纵向扩展:升级单个 Redis 实例的资源配置,包括增加内存容量、增加磁盘容量、使用更高配置的 CPU。就像下图中,原来的实例内存是 8GB,硬盘是 50GB,纵向扩展后,内存增加到 24GB,磁盘增加到 150GB。
横向扩展:横向增加当前 Redis 实例的个数,就像下图中,原来使用 1 个 8GB 内存、50GB 磁盘的实例,现在使用三个相同配置的实例。
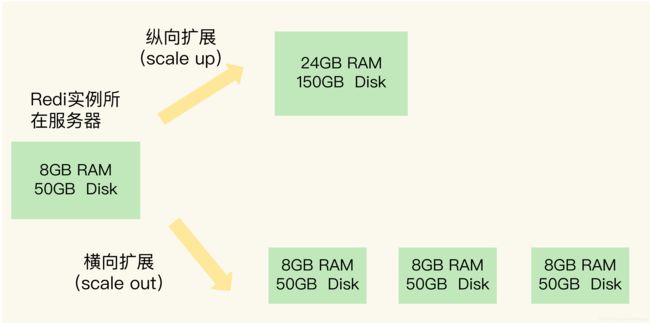
那么,这两种方式的优缺点分别是什么呢?
首先,纵向扩展的好处是,实施起来简单、直接。不过,这个方案也面临两个潜在的问题。第一个问题是,当使用 RDB 对数据进行持久化时,如果数据量增加,需要的内存也会增加,主线程 fork 子进程时就可能会阻塞(比如刚刚的例子中的情况)。不过,如果你不要求持久化保存 Redis 数据,那么,纵向扩展会是一个不错的选择。不过,这时,你还要面对第二个问题:纵向扩展会受到硬件和成本的限制。这很容易理解,毕竟,把内存从 32GB 扩展到 64GB 还算容易,但是,要想扩充到 1TB,就会面临硬件容量和成本上的限制了。
与纵向扩展相比,横向扩展是一个扩展性更好的方案。这是因为,要想保存更多的数据,采用这种方案的话,只用增加 Redis 的实例个数就行了,不用担心单个实例的硬件和成本限制。 在面向百万、千万级别的用户规模时,横向扩展的 Redis 切片集群会是一个非常好的选择。
切片集群不可避免地涉及到多个实例的分布式管理问题。要想把切片集群用起来,我们就需要解决两大问题:
数据切片后,在多个实例之间如何分布?
客户端怎么确定想要访问的数据在哪个实例上?
数据切片和实例的对应分布关系
切片集群是一种保存大量数据的通用机制,这个机制可以有不同的实现方案。在 Redis 3.0 之前,官方并没有针对切片集群提供具体的方案。从 3.0 开始,官方提供了一个名为 Redis Cluster 的方案,用于实现切片集群。Redis Cluster 方案中就规定了数据和实例的对应规则。
Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
具体的映射过程分为两大步:
- 首先根据键值对的 key,按照CRC16 算法计算一个 16 bit 的值;
- 再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
哈希槽又是如何被映射到具体的 Redis 实例上的呢?
自动分配:我们在部署 Redis Cluster 方案时,可以使用 cluster create 命令创建集群,此时,Redis 会自动把这些槽平均分布在集群实例上。例如,如果集群中有 N 个实例,那么,每个实例上的槽个数为 16384/N 个。
**手动分配:**我们也可以使用 cluster meet 命令手动建立实例间的连接,形成集群,再使用 cluster addslots 命令,指定每个实例上的哈希槽个数。
数据、哈希槽、实例这三者的映射分布情况。
 示意图中的切片集群一共有 3 个实例,同时假设有 5 个哈希槽,我们首先可以通过下面的命令手动分配哈希槽:实例 1 保存哈希槽 0 和 1,实例 2 保存哈希槽 2 和 3,实例 3 保存哈希槽 4。
示意图中的切片集群一共有 3 个实例,同时假设有 5 个哈希槽,我们首先可以通过下面的命令手动分配哈希槽:实例 1 保存哈希槽 0 和 1,实例 2 保存哈希槽 2 和 3,实例 3 保存哈希槽 4。
我再给你一个小提醒,在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
客户端如何定位数据?
客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端。但是,在集群刚刚创建的时候,每个实例只知道自己被分配了哪些哈希槽,是不知道其他实例拥有的哈希槽信息的。
客户端为什么可以在访问任何一个实例时,都能获得所有的哈希槽信息呢?这是因为,Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了。
客户端收到哈希槽信息后,会把哈希槽信息缓存在本地。当客户端请求键值对时,会先计算键所对应的哈希槽,然后就可以给相应的实例发送请求了。
实例和哈希槽的对应关系并不是一成不变的,最常见的变化有两个:
- 在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;
- 为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍。
**Redis Cluster 方案提供了一种重定向机制,**客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令。
那客户端又是怎么知道重定向时的新实例的访问地址呢?当客户端把一个键值对的操作请求发给一个实例时,如果这个实例上并没有这个键值对映射的哈希槽,那么,这个实例就会给客户端返回下面的 MOVED 命令响应结果,这个结果中就包含了新实例的访问地址。
MOVED 重定向命令的使用方法。可以看到,由于负载均衡,Slot 2 中的数据已经从实例 2 迁移到了实例 3,但是,客户端缓存仍然记录着“Slot 2 在实例 2”的信息,所以会给实例 2 发送命令。实例 2 给客户端返回一条 MOVED 命令,把 Slot 2 的最新位置(也就是在实例 3 上),返回给客户端,客户端就会再次向实例 3 发送请求,同时还会更新本地缓存,把 Slot 2 与实例的对应关系更新过来。

如果正在哈希槽正在迁移,那么就会发送一个ASK报错信息给客户端。
客户端向新实例发送ASKING命令,允许执行客户端接下来发送的命令。
接着发送get溪红心获取数据

和 MOVED 命令不同,ASK 命令并不会更新客户端缓存的哈希槽分配信息。所以,在上图中,如果客户端再次请求 Slot 2 中的数据,它还是会给实例 2 发送请求。这也就是说,ASK 命令的作用只是让客户端能给新实例发送一次请求,而不像 MOVED 命令那样,会更改本地缓存,让后续所有命令都发往新实例。