算法、数据结构、计算机系统、数据库MYSQL、概率论、数学实验MATLAB、数学建模、马原、英语、杂项、QT项目
算法
冒号表达式 (condition)?x:y
可以三个条件 以此类推 (condition1)?x:(condition2)?y:z
判断三角形最简单的办法
bool canFormTriangle(int a, int b, int c) {
return (a + b > c) && (b + c > a) && (a + c > b);
}
带空格的数据输入
#includegetline(cin,string); #include cin.getline(char[],num);
数据类型转换
string变成int
#include stoi() which means string to int
int 变成string
#includeto_string() 注意string里面每一项如果想用数字要用str[num]-'0'
大数据的幂运算
可以用循环

#includeusing namespace std; int main() { int n; cin >> n; int result = 1; for (int i = 0; i < n; ++i) { result = (result * 2) % 1007; } cout << result << endl; return 0; }
模运算展开式推导
我们要证明等式:
(a * b) mod m = ((a mod m) * (b mod m)) mod m
假设 a = q1 * m + r1,其中 q1 是 a 除以 m 的商,r1 是 a 除以 m 的余数。类似地,假设 b = q2 * m + r2,其中 q2 是 b 除以 m 的商,r2 是 b 除以 m 的余数。
将 a * b 展开得:
a * b = (q1 * m + r1) * (q2 * m + r2)
展开后,我们得到:
a * b = q1 * q2 * m^2 + q1 * m * r2 + q2 * m * r1 + r1 * r2
接下来,我们可以看到 a * b 对 m 取模后的结果:
(a * b) mod m = (q1 * m * r2 + q2 * m * r1 + r1 * r2) mod m
现在,我们注意到 q1 * m * r2 和 q2 * m * r1 都是 m 的倍数,因此对 m 取模后会变为 0。另外,r1 * r2 对 m 取模后结果仍然是 r1 * r2。因此,我们可以简化为:
(a * b) mod m = r1 * r2 mod m
另一方面,我们可以计算 (a mod m) * (b mod m):
(a mod m) * (b mod m) = (r1 * r2) mod m
最终,我们得到:
(a * b) mod m = ((a mod m) * (b mod m)) mod m
这证明了所要证的等式
复制字符串的一部分
substr(start,length) //字符串 string s="abc"; string m=s.substr(0,3) //从0开始复制长度为3的一段 //结果: m=abc;
多维数组初始化
memset(数组名,要初始化成的值(二进制)例如0,-1;如果5,则会变成101,要初始化多长字节)
int 4字节 10个int应有40bite
memset(a,-1,sizeof a) sizeof不需要加括号;
memset比循环更快;
数组复制
int a[10] , b[10]
memcopy(目标数组,原数组,复制多长字节)
memcopy(b,a,sizeof a)//把a复制给b
printf的格式化输出
printf函数提供了多种格式化选项,用于控制输出的格式。以下是一些常用的printf格式化选项:
整数格式化:
%d:有符号十进制整数。
%u:无符号十进制整数。
%o:无符号八进制整数。
%x或%X:无符号十六进制整数(小写或大写字母)。浮点数格式化:
%f:浮点数。
%e或%E:以指数形式表示的浮点数(小写或大写字母)。
%g或%G:根据值的大小选择%f或%e格式。字符和字符串格式化:
%c:字符。
%s:字符串。指针格式化:
%p:指针的值。宽度和精度:
%nd:最小宽度为 n 的整数,用空格填充。
%.nf:浮点数保留 n 位小数。
%m.nf:最小宽度为 m,浮点数保留 n 位小数,自动补齐空格。对齐和填充:
%Ns:右对齐,最小宽度为 N 的字符串,不足部分用空格填充。
%-Ns:左对齐,最小宽度为 N 的字符串,不足部分用空格填充。
%0Nd:右对齐,最小宽度为 N 的整数,不足部分用零填充。其他:
:输出百分号。
日期处理
写一个判断闰年函数
(这个判断闰年函数与增加一天日期变化函数有联系,1闰0不闰)
bool isLeapYear(int year)
{
return (year % 4 == 0 && year % 100 != 0) || (year % 400 == 0);
}
写一个平闰年对应月份的天数二维数组
int dayOfMonth[2][13] = {
{0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31},
{0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}
};
写一个增加一天日期变化函数
void addOneDay(int &year, int &month, int &day) {
day++;
if (day > dayOfMonth[isLeapYear(year)][month]) {
month++;
day = 1;
}
if (month > 12) {
year++;
month = 1;
}
}
进制转换
####
10进制转换成p进制
例如要变的初始数为10进制的num,辅助数base,目标进制是s
int num , base = 1;
int result = 0; // 用于存储结果
while (num != 0) {
result += num % 10 * base; // 将当前位的值乘以进制数,累加到结果中
num /= 10; // 去掉当前位
base *= s; // 更新进制数
}
从个位开始,个位乘以base,十位乘以s2,百位乘以s3,以此类推最后累加起来
####
p进制转换成10进制
连续读入的一次debug
while(cin>>m[num])
{
num++;
}
区别于
while(cin>>m[num++])
{
}
前者判断输入完再num++,而后者无论输入成功与否都会num++;
cmp函数编写 return a < b ,
快速排序 传入数组,左右边界,初始化索引指针在左右边界外,,初始化随机参照值,do 指针往中间靠 while左边索引的东西大于参照物,右边索引的东西小于参照物 ,交换两个索引,迭代左边和右边 注意下标
sort(str,str+n,sortmethod)
查找数字 字母 统计出现次数 (哈希表)
可以建立哈希表 字母可以将其-‘a’
因为要将统计的东西按顺序输出,所以先建立哈希表按顺序输出,最后按顺序查找输出即可
数据结构
数据结构
-
数据:对客观事物的符号表示 ------图像、声音等
-
数据元素:数据的基本单位 ----学生的信息记录
-
数据项(最小):构成数据元素的不可分割的最小单位 ------学号、姓名、性别等
-
数据对象:具有相同性质的数据元素的集合
-
数据结构(数据元素的集合):相互之间存在一种或多种特定关系的数据元素的集合
-
逻辑结构
-
存储结构
-
数据的运算


数据结构分三种:逻辑结构 、存储结构、数据的运算
1、逻辑结构
线性结构
-
线性表(一般线性表、栈、队列、串、数组) 一对一
非线性结构
-
集合
-
树形结构 ------- 一对多
-
图形结构或网状结构 ------- 多对多


如果分成两种,那就是线性结构和非线性结构
2、存储结构(可以称之为物理结构)
-
顺序存储 逻辑上相邻的元素存储再物理位置也相邻的存储单元中
-
链式存储 借助指示元素存储地址的指针
-
索引存储 建立索引表 索引项(关键字 地址)
-
散列存储 (哈希存储 )
$$
关键字\mathop{\longrightarrow}^{散列函数}存储地址
$$

一般题目中出现
-
顺序
-
链
-
索引
-
哈希
跟存储结构有关
而有序表指的是有序的线性表,仅仅是一种逻辑结构,对有序的线性表进行存储的时候既可以用线性存储也可以用链式存储
3、算法
算法是对特定问题求解步骤的一种描述
-
有穷性 有穷步骤 有穷时间
-
确定性
-
可行性
-
输入 一个算法有零个或多个输入
-
输出 一个算法有一个或多个输出

通常设计一个好的算法应考虑达到以下目标
-
正确性
-
可读性
-
健壮性
-
效率与低存储量需求
算法效率的度量是通过时间复杂度和空间复杂度来描述的
频度 该语句在算法中被重复执行的次数
算法中所有语句的频度之和 T(n)=O(f(n)) f(n)指的是基本运算的频度 O()指的是数量级
例如O(2n)=n


写时间复杂度的时候 不要忘记了大O

顺序表
1、线性表类型定义
线性表:具有相同数据类型的n(n≥0)个数据元素的有限序列
L=(a1,a2,...,ai,ai+1 ....,an)
除第一个元素外,每个元素有且仅有一个直接前驱
除最后一个元素外,每个元素有且仅有一个直接后继


其中 3、4、5、6较为重要
2、顺序表的结构
顺序表:顺序存储的线性表
数组下标 0-》1-》...-》i-1
顺序表 a1-》a2-》...-》ai
内存地址 LOC(A)-》LOC(A)+sizeof(ElemType)-》...-》LOC(A)+sizeof(ElemType)*(i-1)

线性表的顺序储存类型描述为
#define MaxSize 50
typedef struct{ //静态分配
Elemtype data[MaxSize];
int length;
}SqList;
#define InitSize 100
typedef struct{ //动态分配
ElemType *data;
int MaxSize,length;
}SeqList;
L.data=(ElemType*)malloc(sizeof(Elemtype)*InitSize);
//开辟一块更大的存储空间,用以替换原来的存储空间
顺序表的特点:
-
顺序表最主要的特点是随机存取,即通过首地址和元素序号可在时间O(1)内找到指定的元素
-
顺序表的存储密度高,每个结点只存储数据元素
-
顺序表逻辑上相邻的元素物理上也相邻,所以插入和删除操作需要移动大量元素

链表是没有随机存取这个特点的!!!
顺序表的实现
1、插入操作


16-48-09-63往右移一位,再用50把原先16所在的位置覆盖
举一反三
要在第i个位置插入值为e
i (1 ≤ i ≤ L.length+1)
bool ListInsert(SqList &L, int i , ElemType e)
{
if(i<1||i>L.length+1)
{
retun false;
}
for(int j-L.length;j>=i;j--)
{
L.data[j]=L.data[j-1]; //这一步是要求的关键 把后面的用前面的覆盖
}
L.data[i-1]=e;//for循环把空间腾出来了之后,可以将e赋值到所需的位置,第i-1就是数组的下标,合理
L.length++;//因为插入了一个数,所以总的长度会加一,合理
return true;
}
考虑时间 复杂度
最好的情况插入(在最后的下一位)不需要移动,为0 ,在末尾,移动一次,以此类推 ,最坏的情况,在第一个位置插入,需要移动所有的元素,也就是移动n次
0+1+2+...+n=n(n+1)/2
因为0到n有n+1个元素 ,所以用n(n+1)/2除以n+1
得到移动结点的平均次数 n/2 ,平均时间复杂度就为 O(n)

第i个位置,前面有i-1个元素,我们要移动第i+1到n的所有元素,往后一位,
这个需要移动的次数是 n-(i-1)
比如 5个数 插入第3个位置 ,前面有两个单位,后面有 3、4、5三个
要移动n- (i-1)次=3
2、删除操作

bool ListDelete(SqList &L, int i ,Elemtype &e)
{
//先判断i是否合法
if(i<1||i>L.length)
return false;
e=L.data[i-1];
for(int j=i;j



3、按值查找操作
在顺序表L中查找第一个元素值等于e的元素,并返回其位序
int LocateElem(SqList L,ElemType e)
{
int i;
for(i=0;i
4、按位查找操作
int Getelem(Sqlist L, int i)
{
if(i<1||i>L.length)
return 0;
return L.data[i-1];
}
5、合并有序的顺序表算法
将两个有序顺序表A,B合并为一个有序顺序表C,并用函数返回结果顺序表
算法思想:首先,按顺序不断取下两个顺序表表头较小的结点存入心得顺序表中。然后,看哪个表还有剩余,将剩下的部分添加到新的顺序表后面
bool Merge(SqList A,SqList B,SqList &C)
{
if(A.length+B.length>C.MaxSize)
return false;
int i=0,j=0,k=0;//分别对应 A、B、C的数组下标,最后k可以表示C的长度
while(i
链表
1、单链表的结构
单链表:链式存储的线性表


带头节点方便运算的实现;
如果不带头结点,则需要将第一个结点和后继节点分类
链式存储 存储地址不一定是连续的

补充:如果线性表采取顺序存储则一定是连续的

2、单链表的实现(操作)
1、按序号查找结点值

时间复杂度O(n)
2、按值查找表结点

时间复杂度O(n)
平均时间复杂度

查找第一个需要1次,第二个需要两次,第三个需要三次
第n个需要n次,一共需要(n+1)n/2;
有n个数,所以要除以n,最后得到(n+1)/2 平均时间复杂度
插入结点操作
后插操作(一般是把新结点插在一个已知结点的后面)
bi如将值为x的新结点插入到单链表的第i个位置上;
(实际上是插在第i-1个结点的后续位置,故称之为后插操作)
这几章第一步都是要判断检索标记是否合法,严谨

假设b为第i个结点,a为第i-1个结点,在插入前先判断第i个位置是否合法
不合法就return NULL

先找到第i-1个结点,用之前按位查找的办法

前插操作?
在不清楚某一个点前面位置的情况该如何处理呢?
单链表只能直接检索到后续结点,所以这里要转换思路。联系后插操作
先实现后操作后,再将后插的结点与前一个结点交换数据,即可实现“前插操作”

例题

先把前驱结点的下一个结点赋给 插入结点
画个图就好理解
4、删除结点操作

多种写法
p->next=q->next;
free(q) 这样q不就被边缘化了?
3、双链表
双链表中有两个指针
prior 和next,分别指向前驱结点和后继节点,多开空间,但是不得不说有点方便?
双链表的定义

例题:

双链表的插入操作
有点意思,跟单链表不同,单链表插入只需要改后继节点,或者交换两节点
但双链表要更换后继结点和前驱结点,相当于多一个操作

并且第一行和第二行必须在第四行之前,
都是要先把第i-1个结点的后继结点赋给插入结点的后继结点
最后再改i-1个结点的后继结点
相当于改已有数据前 确保其被保存了!! 后继先赋
双链表的删除操作

确保前驱结点和后继结点都进行过操作即可
4、循环链表
最大的特点就是,最后一个结点的后继结点是头节点
循环单链表
每个结点都有后继结点;其判断为空的 条件不再是后继结点为NULL

循环双链表
同理

概念例题

判断为空例题

循环链表性质题:
不能说链式存储和顺序存储哪个好哪个差,每个都有其适用的场景
线性表中插入和删除数据需要移动大量的数据,所以是不便于插入和删除的
而链式表只需要改变两个指针,后继结点即可,所以链式表是便于插入和删除的

栈和队列
1、栈的基本概念
栈:只允许在一端进行插入或删除操作的线性表 (后进先出LIFO)
2、栈的储存结构
3、队列的基本概念
4、队列的存储结构
串
树和二叉树
1、树的基本概念
树:n(n \geq 0)个结点的有限集
树是递归定义的
有空树的概念

根节点:A
除了根节点,所有结点都有唯一的前驱结点
对每个结点有0到任意个后继的结点
概念例题:

基本术语

1、祖先、双亲、孩子:A、B、E都是K的祖先,E是 K的双亲,K是E的孩子
2、结点的度:该结点的孩子个数 。比如A结点度数为3,D结点度数为3,F结点度数为0
树的度: 树中结点的最大度数,这棵树的度为3
3、分支结点(非终端结点):度大于0的结点(有孩子的)
叶子结点(终端结点):度数为0的结点
兄弟:有相同双亲的结点 例如K和L
4、深度、高度,都是这个树最大的层数,这个树的深度和高度都是4,不过深度是从高往低,高度是从低往高
5、有序树、无序树 对于这颗树的各子树,从左到右是有次序的,称之为有序树 ,否则是无序树,这里是有序树
6、路径、路径长度
有向边,比如A到K A-B-E-K 有几条边路径长度就是多少,这里是3
树的性质:
1、树中的结点数等于所有结点的度数和+1(所有结点孩子个数和+根节点) 合 理
2、度为m的树中第i层上至多有m^{(i-1)}个结点
1 1
2 m
3 m^2
3、高度为h的m叉树至多有(m^{h}-1)/(m-1)个结点
(m叉树其实表示每个结点都有m个后继结点)
1+m+m^2+...+m^{h-1}
4、具有n个结点的m叉树的最小高度为[log_{m}(n(m-1)+1]
根据(m^{h}-1)/(m-1)=n推导得来
概念例题

套公式

2、二叉树
3、二叉树的遍历(必考、解答)
4、树和森林
5、二叉排序树
6、哈夫曼树
图
图的应用
查找
排序
aaa我真的不知道这个数据结构为什么讲得这么粗糙!!
树型结构和图结构的基本区别就是“每个结点是否仅仅从属一个直接上级”。而线性结构和树型结构的基本区别是“每个结点是否仅仅有一个直接后继”。
$$
线性 -(后继) -树型 -(上级)-图
$$
四种基本存储映射方法:顺序、链接、索引、散列
顺序存储结构称为紧凑存储结构,其紧凑性是指它的存储空间除了存储有用数据外,没有用于存储其他附加的信息
利用指针,在结点的存储结构中附加指针字段称为链接法。两个结点的逻辑后继关系可以用指针的指向来表达
对于经常增删结点的复杂数据结构,顺序存储往往会遇到困难,链接方法结合new动态存储为这些复杂问题提供了解决方法
索引方法是要建造一个由整数域Z映射到存储地址域D的函数Y:ZàD,把结点的整数索引值 z∈Z映射到结点的存储地址 d∈D 。它称为索引函数,一般而言它并不象数组那样,是简单的线性函数。
索引方法在程序设计中是一种经常使用的方法,其主要原因是对于非顺序的存储结构来说,使用索引表是快速地由整数索引值找到其对应数据结点的唯一方法
队列
不能操作中间,只能操作两头 head tail (先进先出First In First Out ,FIFO原则)
解密码

#include
int main()
{
int q[102] = {0, 6, 3, 1, 7, 5, 8, 9, 2, 4}, head, tail;
int i;
// 初始化队列
head = 1;
tail = 10; // 队列中已经有9个元素了,tail指向队尾的后-一个位置
while (head < tail) // 当队列不为空的时候执行循环
// 打印队首并将队首出队
{
printf("8d", q[head]);
head++;
// 先将新队首的数添加到队尾
q[tail] = q[head];
tail++;
// 再将队首出队
head++;
}
return 0;
}
栈
插入和删除只能在一边 ,后进先出(LIFO),即最后插入的元素会最先被取出
判断回文数 用栈的思想
#include
#include
int main()
{
char a[101], s[101];
int i, len, mid, next, top;
gets(a); // 读入- 行字符串
len = strlen(a); // 求字符串的长度
mid = len / 2 - 1; // 求字符串的中点
top = 0; // 栈的初始化
// 将mid前的字符依次入栈
for (i = 0; i <= mid; i++)
s[++top] = a[i];
// 判断字符串的长度是奇数还是偶数,并找出需要进行字符匹配的起始下标
if (len % 2 == 0)
next = mid + 1;
else
next = mid + 2;
// 开始匹配
for (i = next; i <= len - 1; i++)
{
if (a[i] != s[top])
break;
top--;
}
// 如果top的值为0,则说明栈内所有的字符都被一-匹配了
if (top == 0)
printf("YES");
else
printf("NO");
return 0;
}
队列+栈的综合运用
纸牌游戏 跑火车
#include
struct queue // 先用一个结构体来实现队列 队列储存手牌
{
int data[1000];
// head 与tail 都是索引数
int head;
int tail;
};
struct stack // 再用一个结构体来实现栈 公共牌堆 栈存放公共牌堆
{
int data[10];
int top;
};
int main()
{
struct queue q1, q2;
struct stack s;
int book[10];
int i, t;
// 初始化队列
q1.head = 1;
q1.tail = 1;
q2.head = 1;
q2.tail = 1;
// 初始化栈
s.top = 0;
// 初始化标记数组,标记已经在桌上的牌
for (int i = 1; i <= 9; i++)
{
book[i] = 0;
}
// 一次插6个数
// A的六张牌
for (int i = 1; i <= 6; i++)
{
scanf("%d", &q1.data[q1.tail]);
q1.tail++;
}
// B的六张牌
for (int i = 1; i <= 6; i++)
{
scanf("%d", &q2.data[q2.tail]);
q2.tail++;
}
while (q1.head < q1.tail && q2.head < q2.tail)
{
t = q1.data[q1.head]; // A出牌
// 判断A当前打出的牌是否能赢?!
if (book[t] == 0) // 表明桌上没有牌面为t的牌
{ // 没有赢牌
q1.head++; // A已经打出一张牌,所以将手牌出队
s.top++;
s.data[s.top] = t; // 将打出的手牌放在公共牌堆 入栈
book[t] = 1; // 标记桌上现在已有的牌面为t的牌
}
else
{
// A此轮可以赢牌
q1.head++; // A已经打出手牌,所以还是要将手牌出队
q1.data[q1.tail] = t; // 紧接着把打出的牌放到手中牌的末尾
q1.tail++;
while (s.data[s.top] != t) // 将公共牌堆中能赢A的牌出栈,并放入手牌的队尾
{
book[s.data[s.top]] = 0; // 取消标记
q1.data[q1.tail] = s.data[s.top]; // 依次进入队尾
q1.tail++;
s.top--; // 栈少了牌,栈顶-1
}
}
t = q2.data[q2.head]; // B 出牌 类似的
if (book[t] == 0) // 表明桌上没有牌面为t的牌
{ // 没有赢牌
q2.head++; // B已经打出一张牌,所以将手牌出队
s.top++;
s.data[s.top] = t; // 将打出的手牌放在公共牌堆 入栈
book[t] = 1; // 标记桌上现在已有的牌面为t的牌
}
else
{
// B此轮可以赢牌
q2.head++; // B已经打出手牌,所以还是要将手牌出队
q2.data[q2.tail] = t; // 紧接着把打出的牌放到手中牌的末尾
q2.tail++;
while (s.data[s.top] != t) // 将公共牌堆中能赢A的牌出栈,并放入手牌的队尾
{
book[s.data[s.top]] = 0; // 取消标记
q2.data[q2.tail] = s.data[s.top]; // 依次进入队尾
q2.tail++;
s.top--; // 栈少了牌,栈顶-1
}
}
}
if (q2.head == q2.tail)
{
printf("A-win\n");
printf("A's Card Are:");
for (int i = q1.head; i <= q1.tail - 1; i++)
{
printf(" %d", q1.data[i]);
}
if (s.top > 0)
{
printf("Left Cards Are:");
for (int i = 1; i <= s.top; i++)
{
printf(" %d", s.data[i]);
}
}
else
{
printf("\n No Left Card");
}
}
return 0;
}
线性表(包括链表、顺序表) 任何地方都可以操作
顺序表和链表都是线性表的一种实现方式,它们之间存在一些区别。
-
定义:顺序表是按照元素在内存中的存储顺序进行访问的线性表,而链表是由一系列节点组成的线性表,每个节点包含一个数据域和一个指针域,用于指向下一个节点。
-
存储方式:顺序表通常使用数组来存储元素,而链表则使用指针来链接各个节点。
-
插入和删除操作:顺序表的插入和删除操作可以在任意位置进行,时间复杂度为O(n),而链表的插入和删除操作需要遍历链表,时间复杂度为O(n)。但是,链表可以通过跳转指针等技术来实现O(1)时间复杂度的插入和删除操作。
-
查找操作:顺序表的查找操作可以在任意位置进行,时间复杂度为O(n),而链表的查找操作需要从头节点开始遍历链表,最坏情况下时间复杂度为O(n)。但是,链表可以通过哈希表等技术来实现O(1)时间复杂度的查找操作。
-
空间利用率:顺序表的空间利用率较高,因为它只需要存储元素本身,而不需要额外的空间来存储指针。而链表的空间利用率较低,因为它需要额外的空间来存储指针。
另外(顺序表一旦生成,它的空间是无法释放的。因为顺序表通常使用数组来存储元素,而数组的大小是固定的,一旦创建就不能更改。如果需要释放顺序表占用的空间,可以通过将数组中的所有元素置为0或者删除整个数组来实现。但是这样做会导致数据的丢失,因此在实际应用中需要谨慎处理。
相比之下,链表是一种动态的数据结构,它可以在运行时动态地分配和释放内存空间。因此,链表的空间利用率更高,但也更容易出现内存泄漏等问题。在使用链表时需要注意及时释放不再使用的节点所占用的内存空间,以避免内存泄漏的发生。)
链表算法的关键要点:新增结点先连接到原来链表目的地后,在从链表某个结点连回新增结点?!
链表
递归是调用自己 迭代是循环
lists 线性表
链表多开空间来开一个指针
queues 队列
栈 stacks
栈和队列都是线性表的特殊形式
数据结构的学习是计算机科学和编程领域的基础之一。以下是一个合理的学习顺序,以及一些可能的重难点,供您参考:
-
数组 (Arrays):
-
学习如何声明、初始化和访问数组。
-
理解数组的时间复杂度和空间复杂度。
-
理解多维数组和数组的应用场景。
-
链表 (Linked Lists):
-
理解单链表、双链表和循环链表的概念。
-
学习插入、删除和搜索链表中的元素。
-
掌握链表的时间复杂度和空间复杂度。
-
栈 (Stacks) 和队列 (Queues):
-
了解栈的特性(LIFO)和队列的特性(FIFO)。
-
学习如何使用栈和队列解决问题,例如括号匹配、表达式求值等。
-
理解递归与栈的关系。
-
树 (Trees):
-
学习二叉树和二叉搜索树 (BST) 的概念。
-
掌握树的遍历算法,包括前序、中序和后序遍历。
-
理解平衡二叉树 (AVL) 和红黑树 (Red-Black Tree) 的平衡性质。
-
图 (Graphs):
-
了解图的基本概念,包括节点、边、有向图和无向图。
-
学习图的表示方式,如邻接矩阵和邻接表。
-
掌握图的遍历算法,如深度优先搜索 (DFS) 和广度优先搜索 (BFS)。
-
理解拓扑排序和最短路径算法(Dijkstra、Bellman-Ford)。
-
散列表 (Hash Tables):
-
学习散列函数的作用和设计。
-
理解碰撞解决方法,如链表法和开放地址法。
-
掌握散列表的时间复杂度分析。
-
堆 (Heaps) 和优先队列 (Priority Queues):
-
了解堆的性质,如最小堆和最大堆。
-
学习堆排序算法。
-
掌握优先队列的应用,如最小优先队列和最大优先队列。
-
高级数据结构:
-
学习树的高级变种,如B树、红黑树、Trie树等。
-
了解哈夫曼树和最小生成树算法(Prim和Kruskal)。
-
掌握高级数据结构的应用场景。
-
动态规划 (Dynamic Programming):
-
学习动态规划的基本思想。
-
解决经典问题,如斐波那契数列、最长公共子序列等。
-
理解动态规划的时间复杂度和空间复杂度。
-
高级算法和数据结构:
-
学习字符串匹配算法,如KMP和Boyer-Moore。
-
掌握图算法,如最大流算法和最小割算法。
-
了解分治算法、贪心算法和回溯算法。
难点通常在于对特定数据结构和算法的理解和实现,以及对它们的复杂度分析。动态规划、高级图算法和高级数据结构可能会更具挑战性。建议您在学习过程中多做练习和实际项目,以巩固所学知识。不要忘记查阅相关的文档和教材,以便更深入地理解这些概念和技术。
树
满二叉树:
只要有内部节点,就是两个 分支结点+1=叶结点=内部结点+1
分支结点=内部结点
完全二叉树:
尽量从左往右满的
二叉树 编码 很重要
散列
桶思想
一 一 匹配 间隔匹配 等等思路
计算机系统
深入理解计算机系统 从底到高 第一注意抽象 第二不要把硬件软件对立而谈
计算机系统:重要的事情:只要给不同计算机足够时间,理论上都可以实现相同的事情;计算机将自然语言通过自上到下七个层次转换成计算机能理解的东西
从上而下是 问题 算法 程序 isa指令集 微结构 逻辑电路(晶体管) 器件
学习路径是从下往上 从硬件到软件 从器件到程序以上就不讲了
补码
的主要特点是,正数的补码表示与其二进制表示相同,而负数的补码表示通过将正数的补码按位取反,然后加 1 来得到。这种表示方法使得在计算机硬件中可以使用相同的加法器来执行正数和负数的加法,从而简化了运算。
无符号乘法
也简单,部分乘然后按位相加 移位相加,最后的积为A和Q
n位二进制范围
有符号 表示 2^(n-1) 到 (2^(n-1))-1
00=0 01=1 10=-2 11=-1
000=0 001=1 010=2 011=3 100=-4 101=-1 110=-2 111=-3
三码
-
原码(Sign-and-Magnitude):
-
最高位表示符号,0表示正数,1表示负数。
-
其余位表示数值的绝对值。
-
例如,+5的原码是00000101,-5的原码是10000101。
-
反码(Ones' Complement representation):
-
最高位表示符号,0表示正数,1表示负数。
-
正数的反码与原码相同。
-
负数的反码是对其绝对值的每一位取反。
-
例如,+5的反码是00000101,-5的反码是11111010。
-
补码(Two's Complement representation):
-
最高位表示符号,0表示正数,1表示负数。
-
正数的补码与原码相同。
-
负数的补码是对其绝对值的每一位取反,然后加1。
-
例如,+5的补码是00000101,-5的补码是11111011。u
区别:
-
原码、反码和补码都有符号位,但它们对负数的表示方法不同。
-
反码和补码都可以表示0,而原码有两个不同的表示,+0和-0。
-
补码是最常用的有符号整数表示法,因为它在加法和减法操作中更方便,负数的补码可以通过取反和加1来获得,这使得加法和减法的实现更为简单。
在计算机中,通常使用补码来表示有符号整数,因为它在算术运算中更加方便和一致。反码和原码虽然有其理论上的意义,但在实际计算中较少使用。
易:将十进制数转换成n位二进制某码形式
难:将n位二进制某码转换回十进制

操作术语
AND 交
OR 并
NOT按位取反
XOR异或(相同0,不同1)
小数 二进制?
101000.101=40.625
$$
2^{ - 1} 2^{-2} 2^{-3}这样算
$$
并非所有小数都能转换成二进制
IEEE原则表示一个float数 使用二进制
先把一个十进制数转换成二进制数
再把这种二进制数用科学计数法形式表示
最后把科学计数法表示的二进制数转化成IEEE原则float储存在计算机里
$$
符号位+(0/1) 指数位(8位 数据-二进制的127(0111|1111)为实际指数) +尾数位
$$
例如120.5 转化成(无符号)111 1000.1 -》 1.111000x2^6
符号位0
八位指数部分要加上0111|1111,也就是用2进制的6(0000|0110)来加 127 = 1000|0101
最后尾数部分照着写 1110 0000 0000 0000 0000 000 共23位
1+8+23 =32位
ans=0 1000 0101 1110 0000 0000 0000 0000 000
32位IEEE浮点数的8位指数位不能全为0也不能全为1,规定的
指数位能表示的范围是(无符号的情况下是1-254) -127后变成 -126-127
用于表示-127的0000 0000被用来表示subnormal number了,
而用于表示128的1111 1111被用来表示non-number了.
所以实际上32位浮点数的指数部分只能取到只能取到[-126, 127]
指数部分全为1 两种情况 尾数全为0 == 正无穷 尾数不全为0== NaN 不是一个数
十六进制
最高位0-7为正数 8-f为负数 为什么
有些是0x开头 有些是x开头?
不区分大小写
以上第二章总结:
整数表示 有符号 无符号 原码 反码 补码
IEEE 32位浮点数 有个问题 不能表示0附近很小的数
浮点数加减容易产生误差 因为需要小数点对齐?
表达汉字的办法!!
区位码的十六进制表示+2020H=国标码(交换码)
国标码+8080H=机内码
当时保留了ascii码的前几个字符 所以加上了2020H
国标码又加上3473H的原因:将高位赋1??
第三章:逻辑电路
晶体管 我们专业最底层
金属氧化物半导体 MOS

晶体管越多
LC-3
一般pMOS接高电压 nMOS接地
MOS管 有n型 n型(高压导通) 和p型(无压导通)

p型有一个圈 表示反
n型是高电压连接,低电压断开
p型相反
逻辑电路里 2.9v左右视为高电压 为1
低电压视为0
接地是0
构建逻辑门电路
实现逻辑函数的CMOS电路称为“逻辑门电路”
逻辑门的前提是CMOS电路!! 要同时包含nMOS和pMOS
#

非门

换个思路
其实改变晶体管不就是改变二进制的00 01 10 11 ,然后再把结果转化成需要的东西
或非门

或门
比较复杂 ,机器通过或非门和非门连接以达到效果
或非门的输出连接到非门的输入
与非门
并联

与门
同理 与非门+非门

与门与或门的转化
在输入端加反

以后的简化表示法
与门是子弹(有平的部分) 或门是箭头
运算后还应有储存
3.1-3.2 3.4-3.9
3.13 .15 .23 .25
汇编语言与编译器有关 不同编译器的语法有区别
组合逻辑电路
译码器

输出有且仅有一个为1,可以通过结果反推输入
结果单一 ,但可通过出结果的位置定不同情况的输入
多路复用器(用于选择)
包含与门和或门
根据不同输入定结果,输入是多变的,输出也是多变的

$$
N个选择线,2^n个输入,1个输出,输入用AND,输出用OR
$$
-
全加器
包含与门和或门
从真值表入手


储存单元
R-S锁存器

门控D锁存器

寄存器

时序逻辑电路
Q
1111 1111 八位 二进制既可以表示-127也可以表示-0吗?
原码-127 反码-0 补码-1

数据库MYSQL
整体难点
3章关系模型
5关系数据库标准语言SQL
7关系数据库理论
8数据库系统的设计
第一章
重点
基本概念;数据库、DBMS(database management system)
NOSQL和NewSQL都是数据库的类型,但是它们有一些区别。NOSQL是泛指非关系型数据库,主要代表有MongoDB、Redis、CouchDB等。而NewSQL则是一种新方式的关系数据库,意在整合RDBMS所提供的ACID事务特性(即原子性、一致性、隔离性和可持久性),以及NoSQL提供的横向可扩展性 。
云数据库是一种基于云计算技术的数据库服务,它可以提供更高效、更可靠、更安全的数据处理和管理服务。
因此,NOSQL NewSQL 云数据库都属于云数据库的一种类型。
数据库系统的三级模式结构
外模式 (用户级数据库) 局部数据的逻辑结构和特征的描述
模式(概念级数据库)全体数据的逻辑结构和特征的描述
内模式(物理级数据库)数据物理结构和储存结构的描述


名词解释
Database (DB):长期存储在计算机内、有组织的、统一管理的相关数据的集合。
数据库管理系统:DataBase Management System (DBMS)是位于用户与操作系统之问的一层数据管理软件.
数据库系统 (DataBase System):是采用数据库技术的计算机系统。
DBA 数据库管理员 DataBase Adminisrator
外模式(External Schema)也称子模式或用户模式,是把现实世界中的信息按照不同用户的观点抽象为多个逻辑数据结构,每个逻辑结构称为一个视图,描述了每个用户关心的数据,即数据库用户看见和使用的局部数据的逻辑结构和特征的描述。
模式(Schema)也称概念模式或逻辑模式,它是数据库中全体数据的逻辑结构和特征的描述。
内模式(Internal Schema)也称存储模式,它是数据物理结构和存储结构的描述。
外模式到模式的映射:定义了该外模式与模式之间的对应关系。当模式改变时,由数据库管理系统对各个外模式/模式的映射作相应改变,可以使外模式保持不变,从而应用程序不必修改,保证了数据的逻辑独立性.
模式到内模式的映射:定义了数据全局逻辑结构与存储结构之问的对应关系。当数据库的存储结构改变了,由数据库管理系统对模式/内模式映射作相应改变,可以使模式保持不变,从而保证了数据的物理独立性。
使用数据库系统的好处
可以高效且条理分明地存储数据,使人们能够更加迅速和方便地管理数据。数据库可结构化存储大量的数据信息,方便用户进行有效的检索和访问 。此外,数据库可有效地保持数据信息的一致性、完整性,降低数据冗余,使得储存数据所占用的空间较少。
数据管理技术的发展过程
人工管理数据阶段、文件管理数据阶段和数据库管理阶段 .
在人工管理阶段,数据主要存储在纸带、磁带等介质上,或者直接通过手工来记录。
文件系统是一种将数据组织成文件的方式,每个文件都有自己的元数据和地址空间。文件系统提供了一种独立于应用程序的数据访问方式,但是由于文件系统不支持多用户同时访问同一个文件,因此它不能满足多个用户对同一组数据进行访问的需求。
数据库管理系统(DBMS)是一种专门用于管理数据库的软件系统。DBMS提供了一种统一的数据访问方式,使得多个用户可以同时访问同一个数据库中的数据。DBMS还提供了一定程度的并发控制机制,以保证多个用户之间不会发生冲突。DBMS是现代企业信息化建设中不可或缺的一部分 。
文件系统的缺点
1)松散包装,关系映射中没有ACID(原子性,一致性,隔离性,持久性)操作,这意味着无法保证数据的完整性和一致性;
2)安全性低,由于文件可以保存在用户应该提供写入权限的文件夹中,因此很容易出现安全问题并引发麻烦,例如黑客攻击;
3)不适合大规模数据存储 。
在数据库系统阶段,数据管理的特点
数据结构化:采用复杂的数据模型表示数据结构,使得不同数据之间的联系得以表示和描述。
数据独立性:数据独立性较高,数据结构分为用户的局部逻辑结构、整体逻辑结构和物理结构三级,使得应用程序与数据之间的耦合度降低。
数据共享性:数据库系统为用户提供方便的用户接口,可以使用查询语言、终端命令或程序方式操作数据,使得不同用户能够共享数据。
数据控制功能:数据库系统提供数据控制功能,包括数据库的恢复、并发控制、数据完整性和数据安全性,以保证数据库中数据是安全的、正确的和可靠的。
灵活的数据操作:对数据的操作不一定以记录为单位,还可以数据项为单位,增加了系统的灵活性。
总的来说,数据库系统阶段的数据管理具有结构化、独立性、共享性、控制功能和灵活性等特点。
文件系统和数据库系统的联系和区别
文件系统和数据库系统都是用来管理数据的技术,但是它们的应用场景和使用方法都有所不同。
文件系统以文件为单位存储数据,而数据库系统以记录和字段为单位存储数据;
文件系统中的程序和数据有一定的联系,而数据库系统中的程序和数据分离;
文件系统用操作系统中的存取方法对数据进行管理,而数据库系统用DBMS统一管理和控制数据;文件系统实现以文件为单位的数据共享,而数据库系统实现以记录和字段为单位的数据共享 。
数据的物理独立性
是指用户的应用程序与存储在磁盘上的数据库中数据是相互独立的。当数据的物理存储改变了,应用程序不用改变。而数据的逻辑独立性是指应用程序与逻辑结构相互独立,逻辑结构改变,应用程序不用变 。
数据库的三级模式结构
是指数据库系统是由外模式、模式和内模式三级抽象模式构成,这是数据库系统的体系结构或总结构。其中,模式是数据库中全体数据的逻辑结构和特征的描述,外模式是用户能够看见和使用的局部数据的逻辑结构和特征的描述,内模式是数据在数据库内部的表示方式 。
该结构的好处
是可以使得用户不必关心数据库内部的实现细节,而只需要关注其所使用的数据即可。同时,该结构也有利于保护数据库的安全性,因为用户可以针对不同层次的模式设置不同的访问权限 。
数据库系统的应用架构
有很多种,其中比较常见的有:单用户结构、主从式结构、分布式结构、客户-服务器、浏览器应用服务器/数据库服务器等。
数据库管理系统(DBMS)的主要功能
包括:1) 数据定义,提供数据定义语言DDL,供用户定义数据库的三级模式结构、两级映像以及完整性约束和保密限制等约束;2) 数据操纵,提供数据操作语言DML,供用户实现对数据的追加、删除、更新、查询等操作;3) 数据库的运行管理,包括多用户环境下的并发控制、安全性检查和存取限制控制、完整性检查和执行、运行日志的组织管理、事务的管理和自动恢复,即保证事务的原子性 。
常用的数据库管理系统
Oracle MySQL SQLite 高斯开源
第二章:信息的三种世界与数据模型
第三章:关系模型
-
超键(SuperKey):在一个关系中,可唯一地标识元组的一个属性或属性集合。
-
候选键 (Candidate Key):能唯一标识一个关系的元组而又不含有多余的属性的一个属性或属性集合。
-
如果关系的全部属性构成关系的候选键,则称为全键(All-Key)。
-
构成候选键的诸属性称为主属性(Prime Attribute)。
-
不包含在任意候选键中的属性称为非主属性(Non-Prime Attribute)。
-
主键 (Primary Key/PK):有时一个关系中有多个侯选键,此时可以选择一个作为插入,删除或检索元组的操作变量。被选用的候选键称为主键。每一个关系都有一个并且只有一个主键。
-
外键(Foreign Key/FK):是指关系R中的属性A不是关系R的主键,但A是另一个关系S的主键,则属性A就是关系R的外键。其中R是参照关系,S是被参照关系。
-
外键在关系R中的取值有两种可能:或为空值,或必须是被参照关系S中已有的属性值。
-
外键值是否允许为空值,主要依赖于应用环境的语义。
-
唯一键(UNIQUE KEY ):属性取值为唯一的,但可以存空值
候选键一定是超键
外键
第一范式:关系数据库中表的每一列(分量)都是不可分割的基本数据项(原子性),同一列中不能有多个值,即关系模型不允许含有多值属性,并且属性的类型必须是简单类型
关系模型

选择运算
$$
\sigma
$$
###

往往能选出一行 如下例子

投影运算
$$
\pi
$$

这个又能选出一列

连接运算
自然连接要注意! 表示两者共有的属性都要相等


分析过程:
先判断有几个属性,相加列数即可,注意B同时出现再R和S,要用R.B和S.B进行区分
第一个R与S (C
第二个R与S(R.B=S.B)的连接运算,找到对应相等的即可
第三个 由于两者共有元素位B 所以跟第二个一样,自然运算同样也是笛卡尔积 注意了

总结:
$$
\pi是查找信息(最后返回的目标),\sigma是判断的目标
$$

公式解释
$$
\pi_{要查的对象}(\sigma_{要判断属性的条件,比如pid='p01'}(表的范围))
$$

某个元素的象集,就是含有这个元素 的其他元素组成的集合 例如这里ABC的a1的象集,{(b1,c2),(b2,c3),(b2,c1)}

每一步运算尽量保证唯一性,
因为多余的属性会造成干扰,
如果直接将products自然连接orders后再自然连接customers 会导致city成为除了id之外的第二限制,即最终得到的结果除了cid相同,city也是相同的,这是多余的条件
写作这种类型的思路:

关键信息 :没有 产品p02 顾客编号 姓名
所有的顾客的cid和cname 用投影暂存 ;
$$
\pi_{cid,cname}(Customers)-\pi_{cid,cname}(\sigma_{pid='p02'}(Orders\infty Customers))
$$

思路(找共同点 然后求同存异 ) 被除数很重要 既要瞻前又要顾后
拓展的关系代数运算


运用

练习:外连接 左外连接 右外连接 有几个 10个 D

第四章:MYSQL上机

第四章重难点

##
创建数据库
利用图形可视化工具 新建即可
利用SQL语句 --在文件里 create database name;
快捷键:ctrl+enter==启动
备份数据库
用可视化工具
用 data export
用SQL语言
转到mysqldump.exe所在文件夹 打开后
cmd
mysqldump -u root -p mysqlname >path
数据库的导入
图形化工具
data import
sql语言
mysql -u root -p databasename< path
MySQL的管理工具
1-5、DBCBA

MySQL的组件结构
连接层、Server层和引擎层
连接层
连接器

Server层

查询缓存

分析器

优化器

执行器

###



引擎层


第五章 关系数据库标准语言——SQL


第五章重点:
-
SQL的数据查询
-
视图、索引
-
SQL的数据控制功能
-
存储过程
-
函数
难点:
-
关系除法转换为SQL
SQL概述
windows中,关键字是不区分大小写的,而在LINUX系统中是要区分的

数据查询:SELECT
数据定义:CREATE,DROP,ALTER
数据操纵:INSERT,UPDATAE,DELETE
数据控制:GRANT,REMOVE
SQL语言的基本概念
1、数据类型

(1)系统数据类型
-
定点类型
-
浮点类型
-
位值类型
-
日期和时间类型
-
字符串类型
-
enum类型
-
SET类型
2、表达式

3、运算符
<=>MySQL特有的,相当于等号, 与一般的等号区别在,这个<=>可以让空值与空值作比较
SQL中是三值逻辑 ,除了真假还有第三值unknown
在SQL语言中,逻辑真值除了真和假,还有第三个值unknown,因此这种逻辑体系被称为三值逻辑。在三值逻辑中,NULL表示缺失的值或遗漏的未知数据,不是某种具体类型的值。数据表中的NULL值表示该值所处的字段为空,值为NULL的字段没有值。

4、SQL语法规则与规定

SQL的数据定义功能

SQL的数据定义语句主要包括
-
创建数据库
-
创建表
-
创建视图
-
创建索引

数据库的创建和删除
1、数据库的创建
create database 数据库名字
2、数据库的删除
drop datebase 数据库名字
3、数据库的还原

基本表的创建、修改、删除

1、基本表的创建

#创建顾客表
create table customers{
cid nvarchar(255) not null primary key,
cname nvarcharr(255),
city nvarchar(255),
[discnt]float,
check([discnt]>0),
}
#创建产品表
create table products{
pid nvarchar(255)not null,
pname nvarchar(255),
city nvarchar(255),
quantity float,
[price]float,
primary key (pid),
}
#创建代理商表agents
create table agents{
aid nvarchar(255)not null,
aname nvarchar(255),
city nvarchar(255),
[percent]float,
primary key (aid),
}
表的分类


创建表


基本操作

创建表的示例:


复制表



基本表结构的修改


添加列

删除列

表更名:

删除约束

基本表的删除


练习题:

选D

选B
SQL的数据查询功能



简单查询
select * from customers;
#表示查询customers里面所有的数据
消除取值重复的行

加“distinct” 使得查询的值是唯一的,去重
查询需要计算的一步

totalqty==total quantity合计
先乘法后累加
常用的查询条件

单个条件查询
将关系代数表达成SQL语句

确定范围

取等是BETWEEN MIN AND MAX
不取等是 NOT BETWEEN MIN AND MAX(但是是取两边!!!)
如果想不取等且取到中间,就用where 和 and 两个判断条件 爽
用where 连接条件

三值逻辑


这里值得一提的是,当city=NULL的时候,where not ()里面的返回值为空,不会包含进去,无论是where还是where not
多个条件查询

抽象
AND运算
1>0>NULL
OR运算符


模糊查询(有点类似浏览器检索里的星号,这里是百分号)
%是0-任意个 类似于浏览器的‘*’检索
_下划线 是单个字符



转义字符
有特殊字符的查询肯定就有转义字符 类似cpp
WHERE cname NOT LIKE '__\%% ';
第一个\%表示“%本身”,第二个“%”表示0-任意个数的字符

模糊搜索的代价

需要耗费更长的时间
\textcolor{yellow}{空值的处理}

用sql特有 <=> 来查询NULL

聚合函数(关键字的运用)


*表示最长,这个有6行,count city表示数city数量,这个有5行
distinct city表示不同的city distinct 独特的 关键字 之前用到过 有3行

Homework&备忘
备份 、加载数据库的时候 语法 <“space” 这里想象有个箭在弦上,有个箭杆
$$
\pi_{Rname,Rno,Bno}(Reader\infin Borrow)\div \pi_{Bno}(\sigma_{Rno='R01'}(Reader\infin Borrow))
$$
$$
\pi_{Bno,Btitle,Bauthor,Bprice}(\sigma_{'数据库'\subset Btitle}(Book)\cup \sigma_{price<50}(Book))
$$
概率论
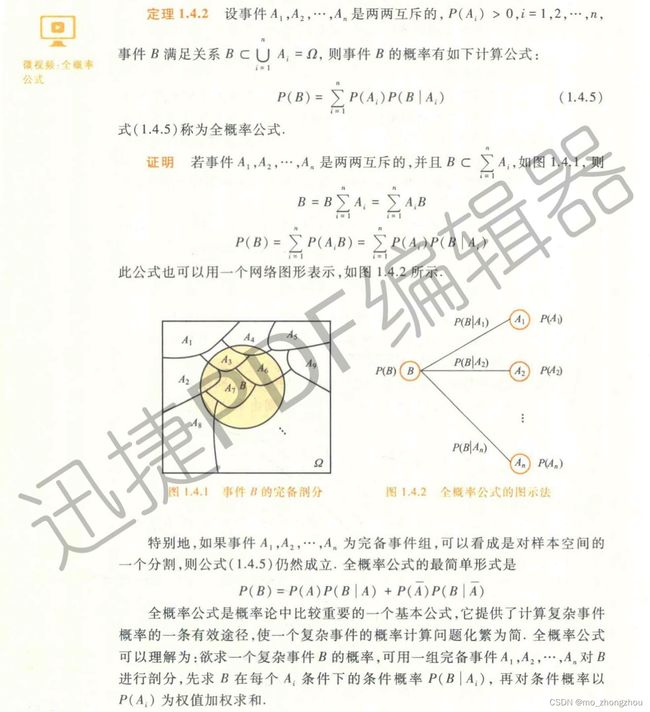
全概率公式
给一个事件B,然后有很多个事件A1、A2、...、Ai来划分全集。求P(B)。
可以用该公式,将P(B)转化为在Ai下的条件概率,累加起来
贝叶斯公式
$$
P(A_{k}|B)={P(A_{k}B )\over P(B)}={P(A_k)P(B|A_k)\over \sum \limits_{i=1}^{n}P(A_i)P(B|A_i) } k=1,2,..,n={P(A_{k}B)\over \sum \limits_{i=1}^{n}P(A_{i}B)}k=1,2,...,n
$$

基本性质和公式
德摩根律 长短杠、开口向都互换
$$
\eqalign{ & {\rm{P(}}\overline {{\rm{AB}}} {\rm{) = P(}}\overline A \cup \overline B {\rm{)}} \cr & {\rm{P(}}\overline {{\rm{A}} \cup {\rm{B}}} {\rm{) = P(}}\overline A \cap \overline B {\rm{)}} \cr}
$$
逆事件概率公式
$$
P(A) = 1 - P(\overline A )
$$
乘法公式
$$
p(ab)=p(a)*p(b|a)
$$
Addition formula
$$
P(A \cup B) = P(A) + P(B) - P(A \cap B)
$$
减法公式(事件差《概率差) 很合理
$$
P(A-B)=P(A)-P(AB)
$$
全概率公式--将复杂事件的概率求解问题转化
贝叶斯公式(逆概率公式):意义:在已知一些先验条件下,对一个新事件的后验概率进行求解
集合概率 典 两船停靠码头,甲x停1h ,乙y停2h,问昼夜两船停靠冲突的概率
思路:0-24h构建平面直角坐标系,第一象限正方形,0《x-y《1 或者 0《y-x《2; 几何面积
重要问题
概率为0推不到事件是不可能的(打靶) 但不可能事件可推概率0
$$
P(AB)=0 \Leftarrow AB=\emptyset右推左可,左推右不行
$$
可以推的(用逆事件概率公式和德摩根律进行变形)
$$
P(AB)=0 \Rightarrow{\rm{P(}}\overline {{\rm{AB}}} {\rm{) = 1}}\Rightarrow{\rm{P(}}\overline {\rm{A}} \cup \overline {\rm{B}} {\rm{) = 1}}
$$
同样 概率为1推不到事件是全集 但全集可推概率1
$$
{\rm{P(AB) = 1}} \Leftarrow {\rm{AB = }}\Omega右推左可,左推右不行
$$
标有1-n的球放入1-n的盒子,要保证所有盒子与球都没有对上号,问概率?
总事件n! 结果是错位排 如何数????????? 穷举比较麻烦, 第二个盒子与第一个有关,第三个又与前两个有关,所以不好做,于是转换
假设Ai代表i号球的结果i=1,2......,n;(这是很重要的思路) 因为可以简化运算
这个包含加法原理 性质 德摩根律
思路和算法都不错
##
常用公式
$$
P(A\overline B)=P(A)-P(AB)
$$
对于很多题都是把概率展开
概率的独立性
定义




多个事件的独立性

”至少有两台“
有三种表达方式
1、至少用并号表示,把所有两个的不一样的并起来A1A2并A1A3....
2、穷举,全加起来 2个的 3个的 4个的
3、对立事件
事件内部用交的符号
$$
P( \mathop ∩ \limits_{i=1}^{100}A_i)
$$
数学计算用大写的pi
独立重复实验
随机有放回地抽取3次==三重伯努利实验

作业有一道题跟这个类似
先用全概率公式得到抽一件是损坏的概率,然后再根据独立重复实验,二项分布公式
系统可靠性问题
串并联 串联 并联 有种重要思想:将未知转换成已知



第二章 一维随机变量及其分布
一、随机变量及其分布函数的概念,性质及其应用
2、分布函数的概念及其性质
F(x)必是某个x的分布函数的充要条件

分布函数的基础例题:

第一步、等差数列 归一性 d!=0

第二步,定义式,必写,且范围要注意

第三步,得到分布函数

(根据这个结果验证性地解释众多性质)
$$
1、F(x)单调不减\\ 2、F(x)右连续,F(a+0)=F(a)\\ 3、F(-\infin)=0,F(+\infin)=1
$$
3、分布概率的应用——求概率
$$
P\{X≤a\}=F(a);\\ P\{X<a\}=F(a-0);这个需要理解\\ P\{X=a\}=F(a)-F(a-0);
$$
解释:
1、互斥事件和的概率=概率的和

2、定义

3、理解
不取等就是取到左极限

二、常见的两类随机变量——离散型随机变量和连续型随机变量
1、离散型随机变量机器概率分布



$$
$$
用互斥事件 事件来推概率
$$
(X\leq b ) = (a $$
$$
P\{a $$

概率密度函数小f(x)一定是连续 但是大F(x)连续型随机变量的分布函数不一定连续
f(x)可积,高等数学知识
1640
2、连续性随机变量及其概率密度
三、常见的随机变量分布类型
1、离散型
2、连续性
四、一维随机变量函数的分布
1、概念
2、随机变量函数的分布
数学实验MATLAB
matlab作图
绘制二维折线图:
x = linspace(0, 2*pi, 100); % 生成 x 值范围
y = sin(x); % 计算 y 值
plot(x, y, 'b-', 'LineWidth', 2); % 绘制蓝色实线图
xlabel('X轴标签');
ylabel('Y轴标签');
title('折线图标题');
grid on; % 显示网格

绘制散点图:
x = randn(100, 1); % 生成随机 x 值
y = randn(100, 1); % 生成随机 y 值
scatter(x, y, 'r', 'filled'); % 绘制红色填充的散点图
xlabel('X轴标签');
ylabel('Y轴标签');
title('散点图标题');
grid on; % 显示网格
绘制柱状图:
x = categorical({'A', 'B', 'C', 'D'}); % 类别标签
y = [10, 25, 15, 30]; % 高度
bar(x, y, 'FaceColor', 'm'); % 绘制品红色柱状图
xlabel('X轴标签');
ylabel('Y轴标签');
title('柱状图标题');
grid on; % 显示网格
绘制饼图:
labels = {'A', 'B', 'C', 'D'}; % 数据标签
sizes = [15, 30, 20, 35]; % 数据比例
explode = [0.1, 0, 0, 0]; % 引爆扇区
pie(sizes, explode, labels); % 绘制饼图
title('饼图标题');
绘制热图:
data = rand(10, 10); % 随机数据
imagesc(data); % 绘制热图
colorbar; % 添加颜色条
xlabel('X轴标签');
ylabel('Y轴标签');
title('热图标题');
解方程
一元三次方程求根公式 配方法
一元四次方程? 更加复杂
solve 解方程
dsolve 求解微分方程
求解非限定方程 和非限定方程组
作图法
一元五次方程 求实根
line
ezplot 符号函数作图?
axis可以用来限定图例的大小
点迭代法求解方程
1、点迭代法的方程可以有无穷个
2、并非每个序列都收敛
3、如何修正序列 使其变得可以收敛 并且收敛地快
% 初始猜测值
x0 = 0.5;
% 迭代函数
g = @(x) cos(x);
% 迭代次数
maxIterations = 100;
% 容忍误差
tolerance = 1e-6;
% 迭代过程
for i = 1:maxIterations
x1 = g(x0); % 计算下一次近似解
% 检查是否满足收敛条件
if abs(x1 - x0) < tolerance
disp(['迭代收敛到解: x = ', num2str(x1)]);
break;
end
x0 = x1; % 更新近似解
end
if i == maxIterations
disp('达到最大迭代次数但未达到收敛条件');
end
% 初始猜测值
x0 = 1.0;
% 迭代函数
g = @(x) 2 * log(x^3 - x);
% 迭代次数
maxIterations = 100;
% 容忍误差
tolerance = 1e-6;
% 迭代过程
for i = 1:maxIterations
x1 = g(x0); % 计算下一次近似解
% 检查是否满足收敛条件
if abs(x1 - x0) < tolerance
disp(['迭代收敛到解: x = ', num2str(x1)]);
break;
end
x0 = x1; % 更新近似解
end
if i == maxIterations
disp('达到最大迭代次数但未达到收敛条件');
end
插值
一维插值(interp1)
1、最邻近插值,就是四舍五入 1.014变成1.01
(改进)
函数值取二者的中点:1.014约等于(1.01+1.02)/2 (这里还存在假设:原函数关系是线性的)
一般问题默认知道的信息越多,决策的精确度越高,部分情况不是这样。
插值感觉跟拟合预测有点像S
2、分段线性插值,唯一的 ,相邻两点连成直线(这是一个分段函数)
每一段的方程都可写出(但是实际情况不可以写这么多函数,也没有论文这样做)
实践中强调插值方法
(但这个表达式就不写出了,论文中)
3、二维插值
interp2
求解微分方程
精确解 一阶微分方程 dsolve
1、欧拉法
##
思路:连续问题离散化
引入自变量点列
$$
\{ x_n\}\rightarrow\{y_n\}
$$
$$
x\in [a,b] 将[a,b]等间隔划分,步长为h
$$
$$
在x_0 $$
差商代替微商,delta->0时成立
算法比较:
1、理论分析 复杂度(与数值分析有关)
2、算法复杂度 算力分析 将其提高一定高度 (利用测试库)
一些常见的改进思路(取区间中点、减少步长、将不同算法的结果取平均值)
如果一味地改小步长,会导致收敛速度变慢,无法达到要求
向前欧拉公式和向后欧拉公式只有线性地收敛速度 过于慢了
2、龙格=库塔法
用泰勒公式设计的
3、微分方程图解法
函数曲线图 (t,x)(t, y)
把 x 、y关联在一起叫做相图(x,y) 研究微分方程动力学、生态系统 之类的
高阶微分方程
matlab里 高阶微分方程必须等价地转换成一阶微分方程组
(不一定必须?)ode45
洛伦兹模型作相图
插值
拟合
近似关系
求解非齐次线性方程组
数学建模
这个肯定跟数值分析离不开关系
马原
《德意志意识形态》
首次系统阐明了历史唯物主义的基本观点
《共产党宣言》
标志马克思主义的公开问世
第一节:世界的多样性及物质的统一性
事物的普遍联系和变化发展
唯物辩证法是认识世界和改造世界的根本方法
世界多样性与物质统一性
1、物质及其存在方式
1、世界观及哲学的基本问题
2、物质及物质观
3、物质的存在方式。
2、物质与意识的辩证关系
1、物质决定意识、
2、意识对物质的反作用
3、主观能动性和客观规律性的统一
4、意识与人工智能;
3、世界的物质统一性
1、世界统一于物质
2、人类社会本质上是物质
3、人的意识统一于物质。
英语
"只 rather than“
杂项
改用户名
在注册表里面改了后
在user文件把名字再改一次 注意环境变量
开一个新账号改
浏览器检索技巧
减号
减号搜索,是想搜索的信息减去不想搜索的信息
格式:A -B(A和减号之间有空格)
双引号
双引号搜索法,搜索结果必须出现连续的文本A
格式:"A"(双引号为英文状态)
星号
通配符——可代替任何文字
一般可以用来搜只记得一部分的成语、诗句,或者是一些描述广泛的东西
格式:A * B
不必回首困倦
不同年龄追求的东西不同
markdown希腊字母

markdown 数学符号 :Markdown之数学符号 - 简书 (jianshu.com)
MYSQL workbench 备份和导入的时候 会创建临时文件,user文件内不能有中文路径
QT项目
23/7/17
回忆复习Qt基础知识;
构思并完善项目的模块内容:1、注册和登陆界面2、与服务器连接保存注册信息,验证登陆信息3、登陆成功后跳转客户端界面4、客制化个人信息例如姓名头像和添加好友功能5、初始化ip和端口并接入服务器6、聊天功能、私聊群聊7、传输简单文本文件;
万事开头难,要做好一件事肯定是从框架入手,然后先趁着热情高涨着手解决最难的问题。要了解我这个项目的框架不是一件容易的事情,一开始我是处于纯新手的状态,已有的资源只有一个老版本和新版本的qt。根据老师上课讲的框架,我再去问chatgpt,再加上我自己的构思,最后得出一个初步框架,在后面学习过程中进一步找到共通的地方再添加东西。
23/8/18
网络通信
在实现即时通讯应用程序时,你可以根据应用的性质和需求来选择合适的协议。以下是关于选择协议的一些建议:
-
TCP 协议:
-
适用场景:如果你的即时通讯应用程序需要可靠的数据传输,确保消息的有序性和完整性,那么 TCP 协议可能是一个不错的选择。适用于需要确保消息不丢失和乱序的场景。
-
优势:提供可靠的数据传输,自动处理丢包、重发和顺序问题。
-
注意:由于 TCP 的连接建立和关闭过程可能会引入一些延迟,对于特别强调实时性的应用,可能需要额外的优化。
-
UDP 协议:
-
适用场景:如果你的即时通讯应用程序更注重实时性,允许一些消息的丢失或乱序,那么 UDP 协议可能更合适。适用于需要快速传递数据的实时应用。
-
优势:速度较快,没有连接建立和关闭过程,适用于实时性要求较高的场景。
-
注意:由于 UDP 不提供可靠性保证,你需要在应用层处理消息的丢失和乱序问题。
-
混合方案:
-
你也可以在应用程序中结合使用 TCP 和 UDP。例如,可以使用 TCP 来处理登录、账号管理等稳定性较高的部分,而使用 UDP 来进行实时聊天消息的传递。
-
第三方库和协议:
-
除了直接使用 TCP 或 UDP,还可以考虑使用一些专门用于即时通讯的第三方库和协议,如 WebSocket、XMPP(Jabber)、MQTT 等。这些协议可能在实现即时通讯功能方面提供更多便利和性能优化。
总之,选择协议取决于你的应用的实际需求。如果你的应用更注重可靠性和数据完整性,可以考虑使用 TCP。如果你的应用更注重实时性和速度,可以考虑使用 UDP。在做出决定之前,最好进行一些测试和实验,以确定哪种协议最符合你的需求。
m_s= new QTcpServer(this); 创建一个m_s对象,this是他的父对象,父对
象析构的时候 子对象也析构 所以不用对子对象自己写析构
让我们用一个类比来解释这个例子中的 QTcpServer、QTcpSocket 以及它们的作用,以便更好地理解它们在网络通信中的功能。
想象您在一个咖啡馆里,QTcpServer 就像是咖啡馆的前台,而 QTcpSocket 则代表顾客和咖啡馆之间的沟通通道。
-
QTcpServer(咖啡馆的前台):
想象您在一个咖啡馆里,QTcpServer 就相当于咖啡馆的前台。它负责接待顾客的到来,安排座位,以及与顾客建立联系。在网络通信中,QTcpServer 负责监听来自客户端的连接请求,接受连接,并创建用于通信的 QTcpSocket。
-
QTcpSocket(顾客和咖啡馆之间的沟通通道):
QTcpSocket 就像是连接到咖啡馆的每个顾客。它代表一个通信通道,使得顾客能够与咖啡馆交流。在网络通信中,QTcpSocket 是客户端与服务器之间的通信通道。每当有一个新的客户端连接时,QTcpSocket 负责处理与该客户端的数据交换,包括接收和发送数据。
回到您的代码例子,当有新的客户端连接时,QTcpServer(类似于咖啡馆前台)创建了一个 QTcpSocket(类似于顾客和咖啡馆之间的沟通通道)来处理与该客户端的数据交换。通过连接 readyRead 信号,服务器能够在客户端发送数据时立即读取并处理它们,而连接 disconnected 信号则允许服务器在客户端断开连接时执行适当的清理工作。
综上所述,QTcpServer 用于接受客户端连接并创建通信通道,而 QTcpSocket 则用于处理与客户端的实际数据交换。这类似于咖啡馆的前台负责接待客户,而客户通过通信通道与咖啡馆交流点餐、传递信息等。
学习源码怎么用,下载一些辅助学习和编程的软件;
学习基于TCP的Qt网络通信,QTcpServer、QTcpSocket、套接字通信 socket;
完成客户端client和本地服务器server的代码,实现了局域网内部的即时信息通讯功能;
学习了VMwareWorkstationPro的方法;
了解m_s= new QTcpServer(this);意思作用:创建一个m_s对象,this是他的父对象,父对象析构的时候,对象也析构,所以不用对子对象自己写析构;
学习发布软件相关知识;
今天比昨天多会的东西没多少,我大致看了框架后,发现登录界面和注册界面跟之前做过的训练有关系,应该不难,我认为技术问题主要集中在数据库的调用和网络通信上面,所以我着手解决第一个网络通信的问题;
开始是个很艰巨的问题,老师这两天上课讲验收标准和Mysql相关的东西,跟我通讯这个问题关系较小,我带着问题问chatgpt,得到一些方向提示,
然后去找IM通讯相关的技术文档,没找到,又去b站找相关视频,有用的东西很少,因为当时我不知道很多知识,
我又转手去csdn,github上面去找相关学习资料,一开始找到的要不就是已经很完善的企业IM,要不就是技术文档看不懂,都不能解决让我学习的问题,在这里磨了很久,
最后找到第一个有用的源码,介绍是把server和client合在一个文件里面,有了源码我还不知道怎么用,问chatgpt,这里有涉及QtDesigner里面一些编辑的东西,这里记不得具体怎么解决的了,最后终于还是能把代码放到了该有的位置,跟着提示用服务器监听本地回环ip127.0.0.1和自定义的一个端口、客户端连接这个ip和端口,刚好在要下班那会跑通程序,用客户端发信息服务器能接收到,服务器发客户端也接受到了,获得巨大激励。
晚上回去又看了相关文档,又猜测这个只要是相同ip和端口就能通信,然后我试了把电脑连接手机的热点,然后ip从回环ip改成热点的ip,端口我自定义,反正服务器监听的和客户端接入的是同一个,居然成功了,我继续延展,是不是别人可以用了,然后我想让室友帮忙测试,这里又去学习如何把源代码发给别人,明白了通过static编译可以解决一些动态库的问题,然后把static编译的文件打包发给室友,室友正常打开,这里遇到一个问题,一开始我电脑本地打开服务器,ip监听的是我网络上的ip,ip比如xxx.xxx.xxx.1端口比如5656;
然后我室友电脑打开client客户端,我用跟我一样的操作,先检测他电脑连接我手机热点后的ip,他的是xxx.xxx.xxx.2,然后端口也连接5656,然后我服务器启动监听后他连接,结果居然失败了,然后我又突发奇想把他客户端准备连接的ip改成xxx.xxx.xxx.1(跟他电脑连接的网络不一样了),然后居然成功了,获得巨大激励
后面我理解了,客户端要接入的不是本地的ip,而是服务器端的ip,端口都要是同一端口。
23/8/19
一个客户端占用一个端口
单线程服务器监听一个端口
多线程服务器 监听多个端口
群聊 私聊
connect我发觉这个有点像不定时的if 函数,而之所以不定时,是因为触发有人为因素,不一定是线性的过程,而只要触发了,就像满足了if的条件,发出某种信号,后面的槽函数接收到后,开始执行,就像执行if里面的代码
你的理解很准确!信号和槽机制的确类似于非线性的条件触发。在经典的编程语言中,我们使用条件语句(如 if 语句)来响应特定的条件。而在信号和槽机制中,信号就像是一种条件的触发器,当某个特定事件发生时,发射一个信号,然后与之相关联的槽函数会被执行。
这种机制非常适用于事件驱动的程序设计,特别是在用户界面交互、多线程、异步操作等场景中。它使得程序的各个部分可以松耦合地交互,不需要紧密耦合在一起,从而提高了代码的可维护性和可扩展性。
通过信号和槽,程序的不同模块可以更灵活地协同工作,就像你所提到的触发条件和执行操作的关系一样。这也是为什么信号和槽机制在很多GUI框架中被广泛使用的原因之一。
深刻理解昨天学习的知识和代码;
完整认识了connect,真正上手了
昨天获得巨大激励,当天应该是热情饱满的,我有了把TCP协议和Qt相关网络通信控件弄懂的信心,我先是让chatgpt把最初的server和client代码每行基本都注释一遍,然后只要遇到有不懂的逻辑、代码、关键字我就问chatgpt,把这份文件吃透后
又去b站找到相关视频,总算找到一个基于Qt的通讯的教程,还是手把手边讲边实操的那种,我跟着视频手敲了包括客户端和服务器的所有代码,这次是比较系统的学习,当然在过程中遇到各种问题,我通过查网站、文档、chatgpt等办法解决,在过程中发现让ai用比喻解释socket那一块比较容易理解,
23/8/20
终于把发文件但接收不到的问题解决了,添加新建接收文件的目录
一、文件的传输,二、在线网络通讯
三、租用服务器
1、记下公网和私网ip地址
2、设置入方向和出方向安全设置(端口情况)
3、有些服务器需要自身是监听私网或者公网ip和端口
4、客户端连接到公网ip,连接对应端口
--mirror Index of /qtproject/这个是可用的 qt源 启动目录代码cmd
继续理解8/18网络通信相关的知识和代码(单线程实现的通讯的服务器和客户端)
学习并实现文件传输 (多线程写的文件传输的服务器,单线程写的客户端)
服务器主线程实现网络连接,副线程实现文件传输
实现通过服务器和公网IP远程通讯了
这天也是获得巨大激励
一开始被一个bug卡了一上午,具体是传输文件,我客户端和服务器的代码对着视频认真检查三遍,chatgpt问了无数次,我能将服务器和客户端正确连接,传输文件的字节也是对了,QDebug的信息是正常的符合预期的,但是始终无法得到文件传输到服务器后,保存的文件,我最初是以为服务器或者客户端连接代码出了问题,或者是析构的时候把文件删了之类的,一上午还没解决,中午咨询老师,虽然老师没能直接解决我的问题,但我获得新的很多思路,后面我在把Qt和MySQL连接的时候用到了这里老师的思路,现在感慨确实很多机缘巧合在里面,老师的思路是用everthing,查我传输的文件,看地址,但也查不到。
下午一到实验室查完各种资料后顿悟,
QFile *file = new QFile("E:\proj\sendFileServer\recv.txt"); 、
// 创建一个文件对象,用于写入接收到的数据
就是这里,原来的版本QFile *file = new QFile("recv.txt")没有具体路径,以前的文档认为这会直接在服务器源代码的根目录创建recv.txt,但是事与愿违,有可能是windows版本 qt版本 编译器版本各种原因,但是我的版本必须加上接受的绝对地址,
后面在老师的提醒下我注意后面集成功能的时候要改成相对地址,不然别人不好用
总算还是解决了卡一上午的bug,
然后下午研究服务器怎么用,我想突破局域网的限制
第一步问chatgpt我应该怎么做,按着gpt教程
我先去阿里云上租了一个服务器,生成一个服务器的实例,然后各种东西不知道,不过不影响,我查文档,问gpt各种办法学,上手后感觉什么问题都可以解决。
先是看服务器公网ip,和私有ip,考虑到我不会轻易重启服务器,所以没有设置弹性公网ip,然后设置服务器的入方向安全组,把接入端口自定义7000/8000
开始不知道服务器怎么一回事怎么用,我直接在本地电脑上把服务器运行(这个服务器是跟原来不一样,是手写的一份新代码,默认监听回环ip),我又增添修改监听ip的功能,然后设置监听ip为公网ip,端口7777,本地打开client,初测发现连接不上。
这里问gpt,发现要在服务器上运行server软件,然后查了半天资料怎么做,意识到服务器可当成一台电脑看,然后了解到可以通过远程连接接入服务器电脑,并且可以跟服务器电脑共享本地文件,输入账号密码进入后,我又意识到如果要在服务器上运行server,服务器又没有qt库,我又要用static运行一次server,把ip设置监听公网ip,然后在服务器上面运行server,在本地运行client,不过可惜还是失败。这里卡了很久,不知道为什么,检查了多次安全组,了解到不需要重启服务器就可以即时更改安全组协议,不是端口的问题,然后没找到问题。最后查网络上别人的案例,我又去问客服确认了,服务器只需要监听本地私有ip,因为公网ip是映射到私有ip的,然后客户端还是连接公网ip。这次测试终于成功了。
后续我优化了server 和client的代码,解决了一些内存释放的问题,目前可实现客户端-服务器的远程聊天。获得巨大激励。
23/8/21
mysql和qt 连接 不同版本 可能会有 不同问题 各有各的可能
连接数据库,巨离谱 qt+=MySQL==MMP
一系列操作
下载mysql qt要有source文件 这期间顺便把各种maintenanceTool搞好 有利有弊
www.subingwen.com 这个大哥真的厉害
QMessageBox::warning(this,tr("登录失败"),tr("用户名或密码输入错误!"),QMessageBox::Ok);
这段代码是使用 Qt 框架中的 QMessageBox 类来创建一个警告对话框。QMessageBox 是用于显示不同类型消息的窗口,包括信息、警告、错误等。
在你的代码中,QMessageBox::warning 用于创建一个警告类型的对话框。其中的参数解释如下:
-
this: 这是指向当前窗口或父窗口的指针,用于将警告对话框与特定窗口关联。通常,这个参数会是你当前的主窗口。
-
tr("登录失败"): 这是警告对话框的标题。tr 是 Qt 的国际化翻译函数,用于支持多语言应用程序。这个函数会将包含在其中的文本翻译为适当的语言。
-
tr("用户名或密码输入错误!"): 这是显示在警告对话框中的具体警告信息。同样,这里使用 tr 函数将文本进行国际化翻译。
-
QMessageBox::Ok: 这是一个按钮选项,它指定在警告对话框中显示的按钮。在这个情况下,它是一个 "确定" 按钮,表示用户可以点击它来关闭对话框。
这段代码的作用是在登录过程中,当用户输入的用户名或密码错误时,弹出一个警告对话框,告知用户登录失败,并提供一个 "确定" 按钮,用户可以点击以关闭对话框。这有助于向用户提供及时的反馈和信息。
"账号名" 在英文中通常被翻译为 "username" 或 "account name",而在某些上下文中也可能翻译为 "account"。对于 QQ 的登录账号,通常来说 "username" 或 "account name" 都是比较合适的翻译选项。
-
"Username": 这是一个普遍用于表示登录凭据的术语,特别是在网站、应用程序和系统中。"Username" 指的是用户在注册或创建账号时所选择的唯一名称,通常用于登录和身份验证。在技术上,"username" 通常比 "account" 更精确地描述了用户登录凭据的性质。
-
"Account name": "Account name" 也是一种常见的翻译,特别是在一些应用程序或系统中。"Account name" 强调了这个名称是用于账户的身份标识。
无论你选择 "username" 还是 "account name",都是可以接受的翻译,而且在大多数情况下,人们会理解其意义。选择哪个更适合取决于你的应用程序的风格和目标受众,以及在你所使用的语言环境中的一般偏好。最终的目标是让用户能够明确理解并正确输入他们的登录凭据。
"登录" 通常被翻译为 "login",而不是 "load"。这是因为 "login" 是一个常见的术语,用于表示用户通过输入正确的用户名和密码来获取访问权限,从而进入系统、应用程序或网站。相比之下,"load" 更多用于描述加载数据、文件或资源等操作。
所以,在用户界面和应用程序中,"登录" 应该被翻译成 "login",以确保用户能够准确理解并执行相应的操作。这样可以保持一致性,并使用户界面更加清晰和易于理解。
实现账号密码登录显示界面,输入错误的时候提示重新输入,输入正确则跳转界面
//login.cpp
#include "login.h"
#include "ui_login.h"
#include
#include"hello.h"
login::login(QWidget *parent) :
QDialog(parent),
ui(new Ui::login)
{
ui->setupUi(this);
this->setWindowTitle("...Login...");
}
login::~login()
{
delete ui;
}
void login::on_login_buttton_clicked()
{
if(ui->Username->text() == "admin"&& ui->password->text() =="1231512315" )
{
this->close();
Hello *h=new Hello;
h->show();
}
else
{
QMessageBox::warning(this, "Login Error!", "Your username or password is incorrect.", QMessageBox::Ok);
ui->Username->clear();
ui->password->clear();
ui->Username->setFocus();
}
}

学习并实现把Qt连接到MySQL
学习并实现注册、登录界面编辑
学习并实现界面跳转
今天总结剩余任务,
注册、登录界面、界面跳转、注册和登录调用数据库、客制化客户端、客户端-服务器-客户端私聊和群聊、历史信息保存在数据库、集成所有功能、界面美化。
剩的东西有点多,感觉压力还是大。
这里面我觉得最难的是数据库相关的东西,还是从难的做起
连接MySQL过程极其复杂,中途我几次错误操作,并且自身Qt也有很多bug,当初下载文件的时候有很多遗留问题,很多的任务,以及繁琐的流程让我一度想放弃连接MySQL,转而去连接SQlite,我SQlite都下好了。但是我还是想再试试Mysql,最后终于还是成功了。 实在是有很多机缘巧合。
网上相关资料也确认了不同版本解决办法不同,比如windows版本不同、qt、编译器版本、位数、MySQL版本不同等等各种不同会造成解决办法不同。
我这个叫“Qt中编译数据库驱动”,先去MySQL官网下载最新版8.1文件安装,安装就遇到很多问题,因为网上说最好安装目录不要带有空格,不然后面要出问题,但是我一开始没找到更改安装位置的办法,在这里磨了一阵,终于还是成功改了。
然后是qt,一定要用64位的编译套件,然后一定要有src 也就是sources资源文件,不巧的是我qt Maintenance文件出了问题打不开,又去官网下了最新版安装包,发现可以直接下载Maintenance,然后又一系列操作下载了5.12.2 MinGW64位编译器下的src源码
然后everything找到qt src里的sqldrivers \mysql 根据网上文档修改mysql.pro
增添INCLUDEPATH、INCLUDEPATH 注释掉原来的QMAKE
第一次编译后继续debug
打开qsqldriverbase.pri
注释掉原有include,新增#include(./configure.pri)
好,然后这里卡了半天,我没找到编译后的生成文件,然后还错误的把我MinGW64 里面 qsqlmysq.dll代码给覆盖了(当时误以为复制的代码是编译后的生成文件,结果是其他版本的qsqlmysq.dll),这里是最想放弃的地方,最后我不得不又从qMaintence里面下回来原版代码,然后是找编译后生成文件这里找了半天,最后想起用everything直接查,终于发现我找不到的原因是因为我跟教程文档保存目录不同。
最难的坎已经迈过,接下来是正常测试,终于过了。
接着写登陆界面,注册界面,跳转界面等等功能。因为我之前把通讯那一块客户端和服务器的ui编辑过很多次,QtDesigner已经比较熟了,所以这个算比较简单,然后跳转槽函数也好写,不是很难。
难的是后面为了可读性的提高,(文件变多了,登录 注册 客户端界面比较多)我想用峰驼命名原则调整原有代码的类名,因为不熟在这里卡了半天,差点把源码毁了,从此养成备份的习惯,不过最后问gpt一点一点调还是调通了。
23/8/22
头文件循环包含问题:
登录界面跳转注册界面,注册界面跳转登陆界面,头文件不能互相包含
解决办法:登录包含注册,注册声明登录类
// 前置声明,告诉编译器 Login 类的存在
class Login;

然后源文件不会出现循环包含问题
修改MySQL root账号的密码 mysqladmin -uroot -p123 password 123456
在mysql中 调用储存的信息
#include
#include
#include
void Login::on_login_clicked()
{
QString inputUsername = ui->username->text();
QString inputPassword = ui->password->text();
QSqlDatabase db = QSqlDatabase::addDatabase("QMYSQL");
db.setHostName("localhost");
db.setDatabaseName("UserRegistrationDB");
db.setUserName("root");
db.setPassword("12315");
if (db.open()) {
QSqlQuery query;
query.prepare("SELECT * FROM users WHERE username = :username AND password = :password");
query.bindValue(":username", inputUsername);
query.bindValue(":password", inputPassword);
if (query.exec() && query.next()) {
// 登陆成功
QMessageBox::information(this, "登陆成功", "欢迎回来!");
c = new Client;
c->show();
this->close();
} else {
// 登陆失败
QMessageBox::warning(this, "登陆失败", "账号或密码错误!", QMessageBox::Ok);
ui->password->clear();
ui->password->setFocus();
}
db.close();
} else {
qDebug() << "Database error:" << db.lastError().text();
}
}

今天实现了注册,登陆系统的逻辑完善,并成功将qt与本地MySQL连接,可以保存、读取信息
#include 这个用来连接数据库
#include 这个用来查找、注入数据
#include 这个用在调试的时候报告信息
巨大问题得到解决,ui h cpp文件重命名,包括类名 要考虑ui 和ui主窗口的重命名!!!
一定要注意指针初始化的问题,如果没有初始化 相当于没有定义,即使是判断!s也会出错
# 授权所有主机都可以通过root用户,密码123456,进行访问数据库
# 123456:给新增权限用户设置的密码
# %:代表所有主机,也可以具体到主机ip地址
# ① 适用于 MySQL 8.0之前的版本,可以直接授权
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
# ② 适用于 MySQL 8.0之后的版本,需要先创建一个用户,再进行授权【推荐方式②】
create user root@'%' identified by '123456';
grant all privileges on *.* to root@'%' with grant option;
# 刷新权限,这一句很重要,使修改生效,如果没有写,则还是不能进行远程连接。这句表示从mysql数据库的grant表中重新加载权限数据,因为MySQL把权限都放在了cache中,所以,做完修改后需要重新加载。
flush privileges;
#################################################################################
# 如果只允许授权某主机连接到mysql服务器
# 123456:给新增权限用户设置的密码
# %:代表所有主机,也可以具体到主机ip地址,如:192.168.xxx.xxx
# ① 适用于 MySQL 8.0之前的版本,可以直接授权
grant all privileges on *.* to 'root'@'192.168.xxx.xxx' identified by '123456' with grant option;
# ② 适用于 MySQL 8.0之后的版本,需要先创建一个用户,再进行授权【推荐方式②】
create user root@'%' identified by '123456';
grant all privileges on *.* to root@'192.168.xxx.xxx' with grant option;
# 刷新权限,这一句很重要,使修改生效,如果没有写,则还是不能进行远程连接。这句表示从mysql数据库的grant表中重新加载权限数据,因为MySQL把权限都放在了cache中,所以,做完修改后需要重新加载。
flush privileges;
————————————————
版权声明:本文为CSDN博主「ASMNDS」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40943000/article/details/120028791

这个大佬帮了大忙
23/8/23
今天 修改QTcpServer代码以实现多客户端连接 整合功能
#
需要创建一个QTcpSocket的列表来存储所有的客户端连接。这可以通过在你的ServerMainWindow类中添加一个QTcpSocket的列表成员变量来实现。然后,当有新的客户端连接时,你可以将这个新的客户端连接添加到QTcpSocket的列表中。你可以通过重写QTcpServer的incomingConnection方法来实现这一点。
然后重写发送文件和接收文件的代码,添加标记
发布程序,第0步,环境变量 path 把编译器的bin目录搞进去,再把g++所在目录搞进去,然后exe拖出去,shift+右键 windows shell 里面 ,windeployqt ./+tab补齐程序名 运行 即可得到能给别人用的软件
23/8/24
debug ,在个人信息自定义界面,修改id、头像,部分得到实现,
ui添加背景,部分得到实现;
程序美化方面,改样式表,语法 插入图片,语法
23/8/25
vscode有感,多光标编辑 alt+leftMouseClick; shift+alt+up/down =ctrl+c&ctrl+v;】w