docker搭建Elk+Kafka+Filebeat分布式日志收集系统
目录
一、介绍
二、集群环境
三、ES集群
四、Kibana
五、Logstash
六、Zookeeper
七、Kafka
八、Filebeat
八、Nginx
一、介绍
(一)架构图

(二)组件介绍
1.Elasticsearch
是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2.Logstash
主要是用来日志的搜索、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等。
3.Kibana
是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图标,为用户提供强大的数据可视化支持,它能够搜索、展示存储在Elasticsearch中索引数据。使用它可以很方便的使用图表、表格、地图展示和分析数据。
4.Kafka
数据缓冲队列。作为消息队列解耦了处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5.Filebeat
隶属于Beats,轻量级数据收集引擎。基于原先Logstash-forwarder的源码改造出来。换句话说:Filebeat就是新版的Logstash-forwarder,也会是ELK Stack在Agent的第一选择。
二、集群环境
(一)服务器
| 服务器 |
服务 |
| 192.168.0.1 |
Es、Kibana、Logstash、Zookeeper、Kafka、Nginx |
| 192.168.0.2 |
Es、Logstash、Zookeeper、Kafka |
| 192.168.0.3 |
Es、Logstash、Zookeeper、Kafka |
(二)优化服务器配置
1.修改limits.conf
vim /etc/security/limits.conf
添加以下内容:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
nofile:一个进程最多能打开的文件数
nproc:一个用户最多能创建的进程数
2.修改sysctl.conf
vim /etc/sysctl.conf
vm.max_map_count=655360
sysctl -p
修改完重启下服务器:reboot
(三)防火墙配置
#查看防火墙状态
firewall-cmd --state
#启用防火墙
systemctl start firewalld.service
#开放端口
firewall-cmd --permanent --add-port=9200/tcp
firewall-cmd --permanent --add-port=9300/tcp
firewall-cmd --permanent --add-port=9092/tcp
firewall-cmd --permanent --add-port=2888/tcp
firewall-cmd --permanent --add-port=3888/tcp
firewall-cmd --permanent --add-port=2181/tcp
# 重启防火墙
firewall-cmd --reload
三、ES集群
ES集群必须至少有两个具有选举为master资格的节点,集群才能启动,所以正式使用的集群具有选举为master资格的节点必须三个或更多,否则主节点出现故障时集群无法完成切换主节点,导致集群停止运行。
(一)准备
1.拉去镜像
docker pull docker.io/elasticsearch:8.4.12.生成P12证书
(1)启动一个单节点es服务
docker run -d --name es -p 9200:9200 -p 9300:9300 --privileged=true elasticsearch:8.4.1(2)进入容器
docker exec -it es bash(3)生成p12证书
# 签发ca证书
elasticsearch-certutil ca
`【ENTER】` 什么也不用输入直接回车
`【ENTER】` 什么也不用输入直接回车
# 用ca证书签发节点证书
elasticsearch-certutil cert --ca elastic-stack-ca.p12
`【ENTER】` 什么也不用输入直接回车
`【ENTER】` 什么也不用输入直接回车
`【ENTER】` 什么也不用输入直接回车(4)从容器中取出证书
docker cp es:/usr/share/elasticsearch/elastic-certificates.p12 /data/elk/es/config/certs/
chmod +r elastic-certificates.p123.生成https证书
(1)进入容器
docker exec -it es bash(2)执行elasticsearch-certutil http命令
#是否生成CSR,输入n
1.Generate a CSR? [y/N]n
#是否使用已有CA,输入y
2.Use an existing CA? [y/N]y
#输入CA文件的绝对路径
3.CA Path: /usr/share/elasticsearch/elastic-stack-ca.p12
#输入CA的密码,空密码直接回车即可
4.Password for elastic-stack-ca.p12:
#默认生效时间5年,输入10年
For how long should your certificate be valid? [5y] 10y
#为节点生成证书,输入y
5.Generate a certificate per node? [y/N]y
#输入节点名称,回车即可
6.node #1 name:
#输入您需要的主机名,没有的话回车后输y
7.Enter all the hostnames that you need, one per line.
Is this correct [Y/n]y
#输入您需要的IP地址,我输入的内网地址,回车后输y
8.Enter all the IP addresses that you need, one per line.
192.168.0.1
192.168.0.2
192.168.0.3
Is this correct [Y/n]y
#是否更改这些选项,输入n
9.Do you wish to change any of these options? [y/N]n
#是否生成其他证书,输入n
10.Generate additional certificates? [Y/n]n
#输入证书密码,如果不设置,回车即可
11.Provide a password for the "http.p12" file:
#设置证书压缩包名称,回车即可
12. What filename should be used for the output zip file? [/usr/share/elasticsearch/elasticsearch-ssl-http.zip]
提示这个表示证书生成完毕:Zip file written to /usr/share/elasticsearch/elasticsearch-ssl-http.zip (3)从容器中取出证书
docker cp es:/usr/share/elasticsearch/elasticsearch-ssl-http.zip /data/elk/es/config/certs/
unzip elasticsearch-ssl-http.zip
cp ./elasticsearch/http.p12 /data/elk/es/config/certs
cp ./kibana/elasticsearch-ca.pem /data/elk/kibana/config/certs 解压完后有elasticsearch和kibana两个文件夹,elasticsearch中的http.p12给elasticsearch使用,kibana中的elasticsearch-ca.pem给kibana使用。
(二)部署
1.配置elasticsearch.yml
##192.168.0.1配置信息如下
cluster.name: "elk"
node.name: es-1
node.roles: [master,data,ingest,remote_cluster_client]
path.data: /usr/share/elasticsearch/data
path.logs: /usr/share/elasticsearch/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
network.publish_host: 192.168.0.1
http.port: 9200
transport.profiles.default.port: 9300
discovery.seed_hosts: ["192.168.0.2:9300","192.168.0.3:9300"]
cluster.initial_master_nodes: ["es-1","es-2","es-3"] #
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Content-Type,Accept,Authorization,x-requested-with
xpack.security.enabled: true
xpack.security.http.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/elastic-certificates.p12
truststore.path: certs/elastic-certificates.p12
##192.168.0.2配置信息如下
cluster.name: "elk"
node.name: es-2
node.roles: [master,data,ingest,remote_cluster_client]
path.data: /usr/share/elasticsearch/data
path.logs: /usr/share/elasticsearch/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
network.publish_host: 192.168.0.2
http.port: 9200
transport.profiles.default.port: 9300
discovery.seed_hosts: ["192.168.0.1:9300","192.168.0.3:9300"]
cluster.initial_master_nodes: ["es-1","es-2","es-3"]
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: true
http.cors.allow-headers: Content-Type,Accept,Authorization,x-requested-with
xpack.security.http.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/elastic-certificates.p12
truststore.path: certs/elastic-certificates.p12
##192.168.0.3配置信息如下
cluster.name: "elk"
node.name: es-3
node.roles: [master,data,ingest,remote_cluster_client]
path.data: /usr/share/elasticsearch/data
path.logs: /usr/share/elasticsearch/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
network.publish_host: 192.168.0.3
http.port: 9200
transport.profiles.default.port: 9300
discovery.seed_hosts: ["192.168.0.1:9300","192.168.0.2:9300"]
cluster.initial_master_nodes: ["es-1","es-2","es-3"]
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: true
http.cors.allow-headers: Content-Type,Accept,Authorization,x-requested-with
xpack.security.http.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/elastic-certificates.p12
truststore.path: certs/elastic-certificates.p12cluster.name:集群名称
node.name:节点名称,唯一
node.roles:角色集合
path.data:数据存放路径
path.logs:日志存放路径
bootstrap.memory_lock:是否锁住内存
network.host:网关地址
network.publish_host:向集群其他节点通信的地址
http.port:接受http请求的端口
transport.profiles.default.port:集群内部通信端口
discovery.seed_hosts:启动时要发现的master列表
cluster.initial_master_nodes:集群节点列表
http.cors.enabled:是否开启跨域
http.cors.allow-origin: 允许访问的地址
http.cors.allow-headers:允许设置的头信息
xpack.security.enabled:是否开启安全认证
verification_mode:验证模式,full:它验证所提供的证书是否由受信任的权威机构(CA)签名,并验证服务器的主机名(或IP地址)是否与证书中识别的名称匹配;certificate:它验证所提供的证书是否由受信任的机构(CA)签名,但不执行任何主机名验证;none:它不执行服务器证书的验证。
keystore.path: 信任存储库文件的存放位置
truststore.path:密钥存储库文件的存放位置
| 角色 | 含义 |
| mater | 具有主角色的节点,它可以被选为控制集群的主节点。 |
| data | 具有数据角色的节点,数据节点保存数据并执行与数据相关的操作。 |
| ingest | 具有接收角色的节点,摄入节点能够将摄入管道应用于文档,以便在索引之前转换和丰富文档,堆栈监视和接收管道需要接收角色。 |
| remote_cluster_client | 具有remote_cluster_client角色的节点,使其有资格充当远程客户端。 |
| ml | 具有机器学习功能的节点,如异常检测,需要ml角色,如果要使用机器学习功能,集群中必须至少有一个机器学习节点。 |
| transform | 具有转换角色的节点,如果要使用变换,则簇中必须至少有一个变换节点,Fleet、Elastic Security应用程序 |
2.启动容器
docker run -d --name es \
-e ES_JAVA_OPTS="-Xms2048m -Xmx2048m" \
-p 9200:9200 \
-p 9300:9300 \
-v /data/elk/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /data/elk/es/config/certs:/usr/share/elasticsearch/config/certs \
-v /data/elk/es/plugins:/usr/share/elasticsearch/plugins \
-v /data/elk/es/data:/usr/share/elasticsearch/data \
-v /data/elk/es/logs:/usr/share/elasticsearch/logs \
-v /etc/localtime:/etc/localtime \
--ulimit memlock=-1:-1 --privileged=true elasticsearch:8.4.1ES_HEAP_SIZE:es中JVM内存限制
--ulimit memlock:最大锁定内存地址空间,-1为不限制
若启动出错,通过docker logs es查看错误信息
4.设置密码
#进入容器
docker exec -it es bash
#自动生成密码
elasticsearch-setup-passwords auto
#手动设置密码
elasticsearch-setup-passwords interactive
#重置密码-自动生成
elasticsearch-reset-password -u elastic
#重置密码-手动设置
elasticsearch-reset-password -u elastic -i备注:统一设置密码为login@q1w2e3
| 用户名 |
作用 |
| elastic |
超级用户 |
| kibana_system |
用于负责Kibana连接Elasticsearch |
| kibana_system |
用于负责Kibana连接Elasticsearch |
| logstash_system |
Logstash将监控信息存储在Es中时使用 |
| beats_system |
Beats在Elasticsearch中存储监视信息时使用 |
| apm_system |
APM服务器在Elasticsearch中存储监视信息时使用 |
| remote_monitoring_user |
Metricbeat用户在Elasticsearch中收集和存储监视信息时使用 |
(三)验证
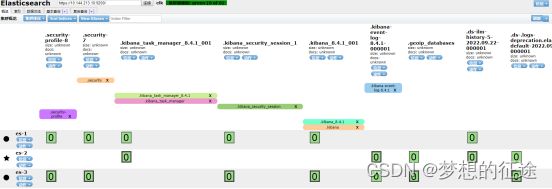
1.输入如下命令查询集群节点状态:
curl -k --user elastic:123456 -X GET https://127.0.0.1:9200/_cat/nodes?v2.使用elasticsearch-head插件查看集群状态
(1)拉去镜像
docker pull docker.io/mobz/elasticsearch-head:5(2)启动容器
sudo docker run -d --name es_admin -p 9100:9100 docker.io/mobz/elasticsearch-head:5(3)在浏览器输入如下地址查看集群状态
http://192.168.0.1:9100/?&auth_user=elastic&auth_password=login@q1w2e3
四、Kibana
(一)准备
1.拉去镜像
docker pull docker.io/kibana:8.4.12.生成证书
#进入容器为Kibana生成服务器证书和私钥
docker exec -it es bash
elasticsearch-certutil csr -name kibana-server -dns example.com,www.example.com
#从容器中取出证书压缩包
docker cp es:/usr/share/elasticsearch/csr-bundle.zip ./
#解压后生成kibana-server.csr和kibana-server.key
unzip csr-bundle.zip
#生成kibana-server.crt
openssl x509 -req -in kibana-server.csr -signkey kibana-server.key -out kibana-server.crt3.移动证书
cp ./kibana-server.key /data/elk/kibana/config/certs/
cp ./kibana-server.crt /data/elk/kibana/config/certs/(二)部署
1.配置kibana.yml
server.host: "0.0.0.0"
server.publicBaseUrl: "https://192.168.0.1:5601"
server.shutdownTimeout: "5s"
elasticsearch.hosts: ["https://192.168.0.1:9200","https://192.168.0.2:9200","https://192.168.0.3:9200"]
elasticsearch.username: kibana_system
elasticsearch.password: login@q1w2e3
elasticsearch.ssl.certificateAuthorities: ["/usr/share/kibana/config/certs/elasticsearch-ca.pem"]
server.ssl.enabled: true
server.ssl.certificate: /usr/share/kibana/config/certs/kibana-server.crt
server.ssl.key: /usr/share/kibana/config/certs/kibana-server.key
i18n.locale: "zh-CN"2.启动容器
docker run -d \
--name kibana \
-p 5601:5601 \
-v /data/elk/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
-v /data/elk/kibana/config/certs:/usr/share/kibana/config/certs \
-v /data/elk/kibana/data:/usr/share/kibana/data \
-v /data/elk/kibana/logs:/usr/share/kibana/logs \
-v /etc/localtime:/etc/localtime \
docker.io/kibana:8.4.1(三)验证
1.在浏览器输入https://192.168.0.1:5601,弹出如下界面,使用elastic账号进行登录

2.登录成功后界面如下
五、Logstash
(一)准备
1.拉去镜像
docker pull docker.io/logstash:8.4.12.移动证书
cp ./kibana/elasticsearch-ca.pem /data/elk/logstash/config/certs 3.创建账号
(1)登录kibana,进入权限管理,创建角色

(2)创建账号

(二)部署
1.配置logstash.yml
node.name: logstash-1 #节点名称,另外两个节点取名logstash-2、logstash-3
http.host: "0.0.0.0" #监听地址
pipeline.workers: 8 #设置output或filter插件的工作线程数
pipeline.batch.size: 125 #设置批量执行event的最大值
pipeline.batch.delay: 5000 #批处理的最大等待值
queue.type: persisted #开启持久化
path.queue: /usr/share/logstash/data #队列存储路径;如果队列类型为persisted,则生效
queue.page_capacity: 250mb #队列为持久化,单个队列大小
queue.max_events: 0 #当启用持久化队列时,队列中未读事件的最大数量,0为不限制
queue.max_bytes: 1024mb #队列最大容量
queue.checkpoint.acks: 1024 #在启用持久队列时强制执行检查点的最大数量,0为不限制
queue.checkpoint.writes: 1024 #在启用持久队列时强制执行检查点之前的最大数量的写入事件,0为不限制
queue.checkpoint.interval: 1000 #当启用持久队列时,在头页面上强制一个检查点的时间间隔
xpack.monitoring.enabled: true #开启logstash指标监测,将指标数据发送到es集群
xpack.monitoring.elasticsearch.hosts: ["https://192.168.0.1:9200","https://192.168.0.2:9200","https://192.168.0.3:9200"]
xpack.monitoring.elasticsearch.username: "logstash_system"
xpack.monitoring.elasticsearch.password: "login@q1w2e3"
xpack.monitoring.elasticsearch.ssl.certificate_authority: /usr/share/logstash/config/certs/elasticsearch-ca.pem2.配置logstash.conf
input {
kafka {
bootstrap_servers => "192.168.0.1:9092,192.168.0.2:9092,192.168.0.3:9092"
group_id => "logstash" #分组id
topics => ["test_auth","test_data","test_business"]
codec => "plain"
consumer_threads => 3 #消费者线程数,与分区数量保持一致
partition_assignment_strategy => "round_robin" #分区分配策略
auto_offset_reset => latest #自动将偏移重置为最新偏移
decorate_events => "basic" #将元数据添加到事件中
}
}
filter {}
output {
elasticsearch {
hosts => ["https://192.168.0.1:9200","https://192.168.0.2:9200","https://192.168.0.3:9200"] #es集群
index => "logs_%{[@metadata][kafka][topic]}_%{+YYYY.MM.dd}" #动态创建索引
user => "logstash_user"
password => "Akdsj@123"
#是否开启https
ssl => true
#是否校验证书
ssl_certificate_verification => true #是否校验证书
#证书路径
cacert => "/usr/share/logstash/config/certs/elasticsearch-ca.pem"
}
}3.启动容器
docker run -d --name logstash \
-p 5044:5044 -p 9600:9600 \
-v /data/elk/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /data/elk/logstash/config/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /data/elk/logstash/config/certs:/usr/share/logstash/config/certs \
-v /data/elk/logstash/data:/usr/share/logstash/data \
-v /etc/localtime:/etc/localtime \
--privileged=true docker.io/logstash:8.4.1(三)验证
1.在redis中使用RPUSH logstash_list插入数据
2.登录kibana查看logs*索引是否有数据
3.登录kibana点击监测堆栈查看集群状态

六、Zookeeper
(一)准备
1.拉去镜像
docker pull docker.io/zookeeper:3.7.1(二)部署
1.配置zoo.cfg
#保存数据的目录
dataDir=/data
#事物日志存储地点
dataLogDir=/datalog
#服务器之间或客户端与服务器之间维持心跳的时间间隔,单位:毫秒
tickTime=2000
#集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数
initLimit=5
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数
syncLimit=2
#用于配置Zookeeper在自动清理的时候需要保留的快照数据文件数量和对应的事务日志文件,此参数的最小值为3
autopurge.snapRetainCount=3
#用于配置Zookeeper进行历史文件自动清理的频率。如果配置为0或负数,表示不需要开启定时清理功能,单位为小时
autopurge.purgeInterval=0
#从Socket层面限制单个客户端与单台服务器之间的并发连接数,如果设置为0,表示不做任何限制
#仅仅是单台客户端与单个Zookeeper服务器连接数的限制,不能控制所有客户端的连接数总和
maxClientCnxns=60
# 3.5.0中的新功能:当设置为false时,可以在复制模式下启动单个服务器,单个参与者可以使用观察者运行,并且群集可以重新配置为一个节点,并且从一个节点。
# 对于向后兼容性,默认值为true。可以使用QuorumPeerConfig的setStandaloneEnabled方法或通过将“standaloneEnabled = false”或“standaloneEnabled = true”添加到服务器的配置文件来设置它。
standaloneEnabled=false
#内嵌的管理控制台,停用这个服务
admin.enableServer=false
#集群服务的列表
server.1=0.0.0.0:2888:3888;2181
server.2=192.168.0.2:2888:3888;2181
server.3=192.168.0.3:2888:3888;2181配置服务列表时,属于本机IP的服务地址设置为0.0.0.0,否则启动的时候会报绑定端口失败。
2.启动容器
docker run -d \
--name zk \
-p 2181:2181 \
-p 2888:2888 \
-p 3888:3888 \
-e ZOO_MY_ID=1 \
-v /data/elk/zk/conf/zoo.cfg:/conf/zoo.cfg \
-v /data/elk/zk/data:/data \
-v /data/elk/zk/datalog:/datalog \
-v /data/elk/zk/logs:/logs \
-v /etc/localtime:/etc/localtime \
--privileged=true docker.io/zookeeper:3.7.1ZOO_MY_ID为zookeeper节点的Id,依次设置为1,2,3即可。
(三)验证
进入容器输入 zkServer.sh status命令查看节点状态

七、Kafka
(一)准备
1.拉去镜像
docker pull docker.io/bitnami/kafka:3.2.3(二)部署
1.配置server.properties
#保证集群中每台服务器brokerid唯一,依次为1、2、3
broker.id=1
#服务器监听地址
listeners=PLAINTEXT://0.0.0.0:9092
#监听器名称、主机名和代理将向客户端播发的端口,设置为服务器的ip
advertised.listeners=PLAINTEXT://192.168.0.1:9092
#broker处理消息的最大线程数
num.network.threads=4
#broker处理磁盘IO的线程数
num.io.threads=8
#分区数量
num.partitions=3
#创建主题的默认复制数
default.replication.factor=3
#偏移主题的复制数
offsets.topic.replication.factor=3
#事务主题的复制数
transaction.state.log.replication.factor=3
#自动创建主题
auto.create.topics.enable=true
#日志保留时间
log.retention.hours=168
#zookeeper配置
zookeeper.connect=192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:21812.启动容器
#192.168.0.1
docker run -d --name kafka \
-p 9092:9092 \
-e KAFKA_BROKER_ID=1 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.1:9092 \
-e KAFKA_ZOOKEEPER_CONNECT=192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181 \
-v /data/elk/kafka/config/server.properties:/opt/bitnami/kafka/config/server.properties \
-v /etc/localtime:/etc/localtime \
--privileged=true docker.io/bitnami/kafka:3.2.3
#192.168.0.2
docker run -d --name kafka \
-p 9092:9092 \
-e KAFKA_BROKER_ID=2 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.2:9092 \
-e KAFKA_ZOOKEEPER_CONNECT=192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181 \
-v /data/elk/kafka/config/server.properties:/opt/bitnami/kafka/config/server.properties \
-v /etc/localtime:/etc/localtime \
--privileged=true docker.io/bitnami/kafka:3.2.3
#192.168.0.3
docker run -d --name kafka \
-p 9092:9092 \
-e KAFKA_BROKER_ID=3 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.3:9092 \
-e KAFKA_ZOOKEEPER_CONNECT=192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181 \
-v /data/elk/kafka/config/server.properties:/opt/bitnami/kafka/config/server.properties \
-v /etc/localtime:/etc/localtime \
--privileged=true docker.io/bitnami/kafka:3.2.3(三)验证
进入容器发/接消息正常即可
1、查询topic列表
kafka-topics.sh --list --bootstrap-server 192.168.0.1:9092,192.168.0.2:9092,192.168.0.3:90922、发送消息
kafka-console-producer.sh --broker-list 192.168.0.1:9092,192.168.0.2:9092,192.168.0.3:9092 --topic test3、接受消息
kafka-console-consumer.sh --bootstrap-server 192.168.0.1:9092,192.168.0.2:9092,192.168.0.3:9092 --topic test --from-beginning八、Filebeat
(一)准备
1.拉去镜像
docker pull elastic/filebeat:8.4.1(二)部署
1.配置filebeat.yml
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_cloud_metadata: ~
- add_docker_metadata: ~
filebeat.inputs:
- type: filestream
id: test-auth
include_lines: ['^Error'] #匹配以Error开头的行
exclude_lines: ['^Info'] #不匹配以Info开头的行
paths:
- /var/log/messages/test-auth/log_error.log
parsers:
- multiline: #处理跨越多行的消息
type: pattern
pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'
negate: false #匹配与否做主语:true-未匹配到做主语,匹配到做宾语 false-匹配到做主语,未匹配到做宾语
match: after #after-主语在宾语之后 before-主语在宾语之前
fields:
topic: test-auth
prospector:
scanner:
check_interval: 10s #Filebeat检查指定用于获取的路径中的新文件的频率,默认值为10s,不建议将此值设置为<1s
backoff:
init: 2s #Filebeat在再次检查文件之前第一次等待的时间,间隔时间呈指数级增加,默认值为2s
max: 4s #Filebeat在再次检查文件之前等待的最长时间,默认值为10s
- type: filestream
id: test-data
include_lines: ['^Error']
exclude_lines: ['^Info']
paths:
- /var/log/messages/test-auth/log_error.log
parsers:
- multiline:
type: pattern
pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'
negate: false
match: after
fields:
topic: test-data
prospector:
scanner:
check_interval: 10s
backoff:
init: 2s
max: 4s
- type: filestream
id: test-business
include_lines: ['^Error']
exclude_lines: ['^Info']
paths:
- /var/log/messages/test-auth/log_error.log
parsers:
- multiline:
type: pattern
pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'
negate: false
match: after
fields:
topic: test-businessG
prospector:
scanner:
check_interval: 10s
backoff:
init: 2s
max: 4s
output.kafka:
topic: "%{[fields.topic]}" #主题
hosts: ["192.168.0.1:9092","192.168.0.2:9092","192.168.0.3:9092"] #kafka集群地址
works: 3 #工作线程数
compression: gzip #输出压缩编解码器,必须是none、snapy、lz4和gzip之一,默认为gzip
compression_level: 4 #压缩级别:1(最佳速度)到9(最佳压缩),默认为4
max_message_bytes: 1000000 #消息最大允许大小,默认为1000000(字节)
required_acks: 1 #ACK可靠性级别:0-无响应,1-等待本地提交,-1-等待所有副本提交,默认为1
partition.round_robin: #开启kafka的partition分区
reachable_only: true2.启动容器
docker run -d --name filebeat \
-v /data/elk/filebeat/config/filebeat.yml:/usr/share/filebeat/filebeat.yml \
-v /data/elk/log:/var/log/messages \
-v /etc/localtime:/etc/localtime \
--privileged=true elastic/filebeat:8.4.1(三)验证
1.向/data/elk/log路径下的日志文件插入数据
2.登录kibana查看logs*索引是否有数据
八、Nginx
(一)准备
1.拉去镜像
docker pull docker.io/nginx:1.22.0(二)部署
1.配置nginx.conf
upstream kibanaServer {
server 192.168.0.1:5601 weight=1;
}
server {
listen 443 ssl;
server_name 192.168.0.1;
ssl_certificate certs/kibana-server.crt;
ssl_certificate_key certs/kibana-server.key;
access_log /var/log/nginx/host.access.log main;
location / {
proxy_pass https://kibanaServer;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
client_max_body_size 50m;
}
}2.启动容器
docker run -d --name nginx \
-p 443:443 \
-v /data/elk/nginx/config/nginx.conf:/etc/nginx/nginx.conf \
-v /data/elk/nginx/config/certs:/etc/nginx/certs \
-v /data/elk/nginx/log:/var/log/nginx \
-v /home/nginx/html:/usr/share/nginx/html \
-v /etc/localtime:/etc/localtime \
--privileged=true docker.io/nginx:1.22.0(三)验证
在浏览器输入https://192.168.0.1弹出kibana登录界面。