Flink DataStream API 介绍
Flink DataStream API 介绍
StreamExecutionEnvironment
StreamExecutionEnvironment
StateBackend管理
setStateBackend()
Checkpoint管理
enableCheckpointing()
Serialzer序列化管理
addDefaultKryoSerialize()
类型和序列化注册
registerTypewithKryoSerializer()
registerType()
DataStream数据源创建
addSource()
readTextFile()
fromCollection()
fromElements()
socketTextStream()
TimeCharacteristic管理
setStreamTimeCharacteristic()
Transformation存储与管理
addOperation()
StreamGraph创建和获取
getStreamGraph()
CacheFile注册与管理
registerCacheFile()
任务提交与运行
execute()
executeAsync()
重启策略
setRestartStrategy()
DataStram数据源
StreamExecutionEnvironment 数据源
基本数据源接口(直接使用)
GenerateSequence
Collection集合
Socket
File(HDFS,Local)
数据源连接器(需要依赖第三方依赖)
Kafka Connector
Es Connector
Custom DataSource
根据具体数据源决定
addSource()方法
Datastream 基本数据源
//从给定的数据元素中转换
DatastreamSource<OUT> fromElements(OUT... data)
//从指定的集合中转换成DataStream
DatastreamSource<OUT> flomCollection(Collection<OUT> data)
//读取文件并转换
DataStreamSource<OUT> readFile(FileInputFormat<OUT> inputFormat, String filePath)
//从Scocket端口中读取
DataStreamSource<String> socketTextStream(String hostname, int port, String delimiter)
//直接通过InputFormat创建
DataStreamSource<OUT> createInput(InputFormat<OUT, ?> inputFormat)
最终都是通过 ExecutionEnvironment 创建 fromSource() 方法转换成DataStreamSource
Datastream 数据源连接器
Flink 内 置 Connector:
-
Apache Kafka (source/sink)
-
Apache Cassandra (Sink)
-
Amazon Kinesis Streams (source/sink)
-
Elasticsearch(Sink)
-
Hadoop FileSystem (sink)
-
RabbitMQ (source/sink)
-
Apache NiFi (source/sink)
-
Twitter Streaming API (source)
-
Google PubSub (source/sink)
-
JDBC (sinkJ
Apache Bahir 项 目 :
- Apache ActiveMQ (source/sink)
- Apache Flume (sink)
- Redis (sink)
- Akka (sink)
- Netty (source)
以Kafka 连接器为例 :
<dependency>
<groupld>org.apache.flinkgroupld>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.11.0version>
dependency>
Datastream 数据源连接器 - Source
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092);
properties.setProperty("group.id", "test0");
Datastream<String> stream = env.addSource(new FlinkKafkaConsumer<>("topic",new SimpleStringSchema(), properties));
Datastream 数据源连接器
以Kafka 连接器为例 :
Map<KafkaTopicPartition, Long> specificStartOffsets = new HashMap<>();
specificStartOffsets.put(new KafkaTopicPartition(“myTopic“, 0), 23L);
specificStartOffsets.put(new KafkaTopicPartition(“myTopic“, 1), 31L);
specificStartOffsets.put(new KafkaTopicPartition(“myTopic“, 2), 43L);
myConsumer.setStartFromSpecificOffsets(specificstartOffsets);
Datastream 数据源连接器 - Sink
Datastream<string> stream = …
Properties properties = new Properties();
properties.setpProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaProducer<String> myProducer = new FlinkKafkaProducer<>("my-topic",//target topic
new SimpleStringSchema(), // serialization schema
properties, // producer config
FlinkKafkaProducer.Semantic.EXACTLY_ONCE); // fault-tolerance
stream.addsSink(myProducer);
Datastream 主要转换操作
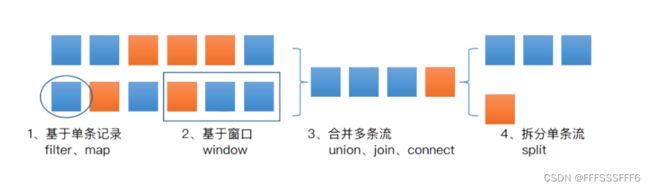
DataStream转换操作
基于单数据处理
map
一对一转换
filter
过滤
flatmap
一对多转换
Window操作
NonKeyed DataStream
Keyed DataStream
timeWindowAll
时间窗口
countWindowAll
计数窗口
windowAll
自定义窗口
timeWindowAll
时间窗口
countWindowAll
计数窗口
windowAll
自定义窗口
多流合并
NonKeyed DataStream
join
关联操作
connect
连接操作
coGroup
关联操作
union
合并操作
Keyed DataStream
interval join
间隔join操作
单流切分
split
切分操作
sideOutput
旁路输出
理解Keyedstream
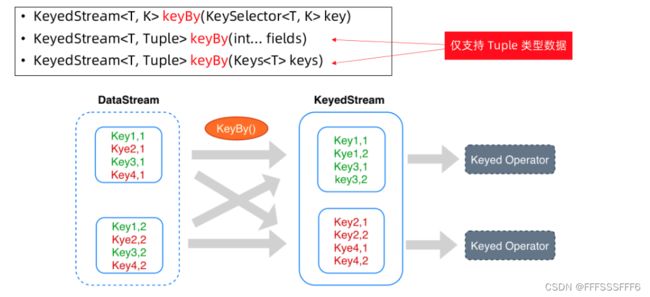
Datastream 之间的转换
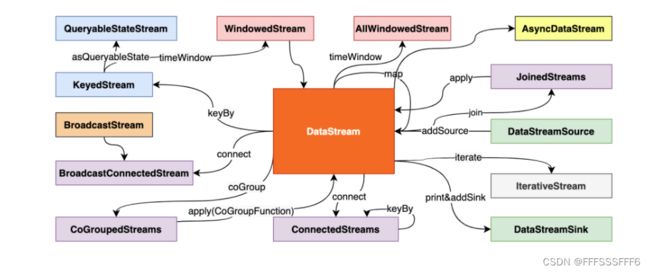
物理分组操作
| 类型 | 描述 |
|---|---|
| dataStream.global(); | 全部发往第1个task |
| dataStream.broadcast(); | 广播 |
| dataStream.forward(); | 上下游并发度一样时一对一发送 |
| dataStream.shuffle(); | 随机均匀分配 |
| dataStream.rebalance(); | Round-Robin(轮流分配) |
| dataStream.recale(); | Local Round-Robin(本地轮流分配) |
| dataStream.partitionCustom(); | 自定义单播 |
public DataStream<T> shuffle(){
return setConnectionType(new ShufflePartitioner<T>());
}
DataStream Kafka 实例
public class KafkaExample{
public static void main(String[] args) throws Exception {
// parse inputarg umenlts
final ParameterTool parameterTool = ParameterTooLfromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(5000); // create a checkpoint every 5 seconds
env.getConfig().setGlobalobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<kafkaEvent> input = env
.addSource(
new FlinkKafKaConsumer<>(
parameterTool.getRedquired("input-topic"),
new KafkaEventSchema(),
parameterTool.getPropelties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.keyBy("word")
.map(new RollingAdditionMapper())
.shuffle();
input.addSink(
new FlinKafkaProduCer<>(
parameterTool.getRequired("output-topic"),
new KeyedSerializationSchemaWrapper<>(new KafKaEventSChema()),
parameterTool.getProperties(),
FlinkKafkaProducer.Semantic.EXACTLY_ONCE));
env.execute("Modern Kafka ExamPle");
}
}