C++中的list类【详细分析及模拟实现】
list类

目录
- list类
-
- 一、list的介绍及使用
-
- 1、构造器及其它重点
-
- ①遍历
- ②插入删除操作
- ③insert和erase
- ④resize
- 2、Operations接口
-
- ①remove
- ②sort
- ③merge
- 3、vector与list排序性能比较
- 二、list的深度剖析及模拟实现
-
- 1、结点的定义
- 2、创建list类
- 3、list类方法的实现
- ==3.1 迭代器类的实现==
-
- ***One more thing...***
- 3.2 迭代器的begin和end接口
- 3.3 构造函数
-
- ①空初始化构造
- ②迭代器构造
- ③拷贝构造
- 3.4 赋值重载
- 3.5 size
- 3.6 empty和clear
- 3.7 析构函数
- 3.8 指定位置插入删除
-
- ①insert
- ② erase
- 3.9 头尾插入删除
- 三、list与vector的对比
①list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代**(带头双向循环链表)**
②list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向 其前一个元素和后一个元素
③list与forward_list非常相似:最主要的不同在于forward_list是单链表,只能朝前迭代,已让其更简单高效
④与其他的序列式容器相比(array ,vector ,deque) , list通常在任意位置进行插入、移除元素的执行效率更好
⑤与其他序列式容器相比, list和forward_list最大的缺陷是不支持任意位置的随机访问,比如:要访问list 的第6个元素,必须从已知的位置(比如头部或者尾部)迭代到该位置,在这段位置上迭代需要线性的时间 开销; list还需要一些额外的空间,以保存每个节点的相关联信息(对于存储类型较小元素的大list来说这 可能是一个重要的因素)

一、list的介绍及使用
1、构造器及其它重点

①遍历
在string和vector的学习种可以使用for循环+[]的方式实现遍历,而对于list而言其本质是链表不易采用此种遍历方式,而对于容器而言,真正统一的遍历方式还得是迭代器
实例:
//构造+遍历
void Test_list()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
list<int>::iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
由于范围for用法的本质即时调用迭代器,因此也同样支持范围for的遍历:
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
反向遍历、const遍历、反向const遍历依次调用其反向迭代器、const迭代器、反向const迭代器即可
总结:迭代器的价值是什么?
1、封装于底层实现,不暴露底层实现细节
2、提供统一访问方式,降低使用成本
②插入删除操作
//尾插
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
//头插
lt.push_front(10);
lt.push_front(20);
lt.push_front(30);
lt.push_front(40);
//头删
lt.pop_front();
lt.pop_front();
//尾删
lt.pop_back();
lt.pop_back();

③insert和erase
关键字:insert和erase
insert和erase通常是我们指定位置,这里就离不开find函数,而在list类中也没有包含find函数,我们使用算法库中的find函数找到指定位置再进行插入或删除操作即可;

find (InputIterator first, InputIterator last, const T& val);
first和last即对应其迭代器的begin和end,最后一个参数是要查找的值;
使用算法库中的find要包含头文件:
#include 因此实例如下:
void Test_list()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
//find找到指定位置pos
auto pos = find(lt.begin(), lt.end(), 3);
//在pos位置插入
//此时的pos在调用完后不失效
if (pos != lt.end())
{
lt.insert(pos, 30);
}
//可以访问pos位置
cout << *pos << endl;
cout << ++(*pos) << endl; //注意符号优先级
//删除pos位置
if (pos != lt.end())
{
lt.erase(pos);
}
}
④resize
由于链表是按需申请、释放空间,其没有reserve接口

2、Operations接口
以下这些接口使用都不是很多

①remove
![]()
删除所有值为val的结点,若该值不存在,也不会报错
实例:
void Test_list()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(3);
lt.push_back(4);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
lt.remove(3);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
lt.remove(30);
}

②sort

顾名思义:排序(从小到大排列)
实例:
void Test_list5()
{
//sort
list<int> lt;
lt.push_back(1);
lt.push_back(20);
lt.push_back(15);
lt.push_back(7);
lt.push_back(13);
lt.push_back(18);
lt.push_back(9);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
lt.sort();
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}

算法库中也有sort函数,而list类却单独提供了一个,说明算法库中是sort函数无法支持对list类的排列
sort(lt.begin(),lt.end()); //wrong
补充:迭代器功能分类
①单向迭代器 ++
②双向迭代器 ++ –
③随机迭代器 ++ – + -
③unique
去除重复的值**(需要先排序再实现去重)**

实例:
void Test_list5()
{
//sort
list<int> lt;
lt.push_back(1);
lt.push_back(20);
lt.push_back(20);
lt.push_back(15);
lt.push_back(7);
lt.push_back(13);
lt.push_back(7);
lt.push_back(18);
lt.push_back(20);
lt.push_back(9);
lt.push_back(20);
//未排序,去重
lt.unique();
//排序+去重
lt.sort();
lt.unique();
}

③merge
合并(两个有序的合并为一个有序的序列)

实例:
void Test_list6()
{
list<double> first;
list<double> second;
first.push_back(3.1);
first.push_back(2.2);
first.push_back(2.9);
second.push_back(3.7);
second.push_back(7.1);
second.push_back(1.4);
//先排序,在合并
first.sort();
second.sort();
first.merge(second);
for (auto e : first)
{
cout << e << " ";
}
cout << endl;
}

3、vector与list排序性能比较
//测试用例:
void test_op()
{
//取随机数
srand(time(0));
const int N = 1000000;
//预开空间
vector<int> v;
v.reserve(N);
list<int> lt1;
for (int i = 0; i < N; ++i)
{
auto e = rand();
v.push_back(e);
lt1.push_back(e);
}
//vector排序
int begin1 = clock();
sort(v.begin(), v.end());
int end1 = clock();
//list排序
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
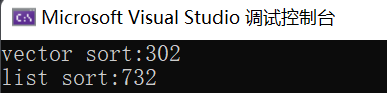
显然,vector的排序效率远大于list
改进:将list拷贝到vector中去排序再拷贝回list:(链表空间访问量大之后效率很低)
二、list的深度剖析及模拟实现
C++ 中的 STL 中的 List 是一个双向链表,可以存储多个元素,支持在任意位置添加、删除和访问元素。如果要模拟实现 List 类,我们通过以下步骤实现:
1、结点的定义
首先,我们需要定义双向链表节点的结构体。每个节点包含一个数据域(存储元素值)、一个指向前驱节点的指针和一个指向后继节点的指针,对于结点而言,我们不妨也为它提供它的构造函数:
同时,我们可以使用模板参数让代码更通用,支持不同类型的元素
template<class T>
struct ListNode
{
ListNode* _next;
ListNode* _prev;
T _data;
ListNode(const T& x)
:_next(nullptr)
,_prev(nullptr)
,_data(x)
{}
};
2、创建list类
我们创建一个 List 类来存储链表的数据和相关操作;List 类包含链表头、链表尾和链表长度等属性,以及添加、删除、访问元素等方法:
该链表是带头双向循环链表,因此类的成员变量是头结点
template<class T>
class list
{
typedef ListNode<T> Node;
public:
//迭代器是内嵌类型:①内部类(不用) ②typedef
typedef list_iterator<T> iterator;
typedef list_const_iterator<T> const_iterator;
//迭代器
iterator begin()
iterator end()
const_iterator begin() const
const_iterator end() const
//空初始化
void empty_initialize()
//构造函数
list()
//迭代器构造
template <class InputIterator>
list(InputIterator first, InputIterator last)
//swap
void swap(list<T>& lt)
//拷贝构造(深拷贝)
list(const list<T>& lt)
//赋值 现代写法:传值传参 lt2=lt1
list<T>& operator=(list<T> lt)
//长度
size_t size() const
//判断链表是否为空
bool empty() const
//clear
void clear()
//析构
~list()
//指定位置(之前)插入
iterator insert(iterator pos, const T& x)
//指定位置删除(返回删除后的下一个位置)
iterator erase(iterator pos)
//头尾插入删除
void push_back(const T& x)
void push_front(const T& x)
void pop_front()
void pop_back()
private:
Node* _head; //头结点
size_t _size; //增加一个计数的成员
};
3、list类方法的实现
3.1 迭代器类的实现
所谓迭代器,我们需要创造一个行为像指针一样的工具,用于遍历容器中的元素;对于我们已经实现的string类以及vector类中,它们是以数组为底层的结构,正好支持迭代器行为,然而对于list类,它是以链表为底层的一个容器,因此为了实现迭代器,我们需要通过类封装+运算符重载的方式支持我们需要的list迭代器
**行为像指针一样❓ **
即能像指针一样,解引用、++/–操作对象内的元素
解引用:得到目前结点的值
++:自动到下一个结点位置
迭代器可以分为 const_iterator 和iterator两种类型,前者用于遍历 const List,后者用于遍历非 const List。iterator 与 const_iterator 的区别是,iterator 通过 operator*() 返回的是元素的引用,因此可以修改元素的值,而 const_iterator 通过 operator*() 返回的是元素的 const 引用,不可以修改元素的值。
//非const迭代器:自定义类型
template<class T>
struct list_iterator
{
typedef ListNode<T> Node;
//结点类型指针(类成员变量)
Node* pnode;
//为它提供构造函数
list_iterator(Node* p)
:pnode(p)
{}
//实现指针行为的重载
//解引用
T& operator*()
{
return pnode->_data;
}
T& operator->()
{
return &pnode->_data;
}
//++
list_iterator<T>& operator++()
{
pnode=pnode->_next;
return *this;
}
//--
list_iterator<T>& operator--()
{
pnode=pnode->_prev;
return *this;
}
//!=
bool operator!=(const list_literator<T>& it)
{
return pnode!=it.pnode;
}
}
由于const 成员函数可以被 const 对象调用,但是非 const 成员函数不能被 const 对象调用,因此当我们需要定义一个 const 版本的迭代器时,由于迭代器的功能不同,需要定义一个 const_iterator 类型;因此需要分开定义 iterator 类和 const_iterator 类。这样可以避免不合适的迭代器类型被用于修改 const 对象或 const_iterator 类型的迭代器对象被用于修改容器中的元素,从而保证容器的不可变性和类型安全性
template<class T>
//const迭代器:与普通迭代器的区别——可以遍历,但不能解引用修改
//这里是通过两个类来实现const迭代器,而不是在一个类中加const
struct list_const_iterator
{
typedef ListNode<T> Node;
//结点类型指针(类成员变量)
Node* pnode;
//为它提供构造函数
list_const_iterator(Node* p)
:pnode(p)
{}
//针对自定义类型重载
//解引用,返回当前对象的值(注意加const)
const T& operator*()
{
return pnode->_data;
}
//++
list_const_iterator<T>& operator++()
{
pnode = pnode->_next;
return *this;
}
//--
list_const_iterator<T>& operator--()
{
pnode = pnode->_prev;
return *this;
}
//判断迭代器位置
bool operator!=(const list_const_iterator<T>& it)
{
return pnode != it.pnode;
}
};
因此在list类中要使用const和非const迭代器类,我们不妨使用typedef它们增加代码可读性:

One more thing…
当我们实现了list_iterator类与const_list_iterator类之后,我们发现两者的实现方式太相似了,但是它们的确是两个不同的类,我们如何实现复用呢使得它们简化一些呢?
因此我们提供了迭代器类Pro,下面详细介绍Pro之处:
设想这样一种情况:
template<class T>
vector<int> v1;
vector<char> v2;
在vector类的模拟实现中,我们为它提供了模板参数,方便它适用于不同类型的元素,而对于vector\和vector\,它们本质就是两个不同的类!
传不同的模板参数,不是同一个类!
什么意思呢?若我们能将非const和const迭代器通过传不同的模板参数+复用的方式,那么我们即可将它们合并在一起,当传入的模板参数不时,它将表现出const或非const的特性!
最后,我们在之前迭代器类设计的基础上,对++/–进行了前置与后置的区分,以及加入了==赋值重载方式,形成了我们最终的迭代器类Pro:
template<class T, class Ref, class Ptr>
struct list_iterator
{
typedef ListNode<T> Node;
typedef list_iterator<T, Ref, Ptr> Self;
Node* _pnode;
//构造函数
list_iterator(Node* p)
:_pnode(p)
{}
//解引用
Ref operator*()
{
return _pnode->_data;
}
Ptr operator->()
{
return &_pnode->_data;
}
//无论是++还是--,前置优于后置
//前置++
Self& operator++()
{
_pnode = _pnode->_next;
return *this;
}
//后置++:返回++之前的值
Self operator++(int)
{
Self tmp = *this;
_pnode = _pnode->_next;
return tmp;
}
//前置--
Self& operator--()
{
_pnode = _pnode->_prev;
return *this;
}
//后置--
Self operator--(int)
{
Self tmp = *this;
_pnode = _pnode->_prev;
return tmp;
}
//不改变成员,加上const
//判断迭代器位置
bool operator!=(const Self& it) const
{
return _pnode != it._pnode;
}
//判断相等
bool operator==(const Self& it) const
{
return _pnode == it._pnode;
}
};
迭代器Pro定义了一个模板类 list_iterator,它表示一个list类的迭代器。它的模板参数包括 T 表示链表中元素的类型,Ref 表示引用类型(const和非const),Ptr 表示指针类型;
因此在list类中要使用const和非const迭代器类,我们通过向该类穿不同的模板参数,并加之typedef的方式,实现const和非const对象的迭代器:
template<class T>
class list
{
typedef ListNode<T> Node;
public:
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
}
在该类中,定义了两个公共类型别名,iterator 和 const_iterator。它们分别表示普通迭代器和常量迭代器。它们的类型均为 list_iterator,其中 Ref 和 Ptr 分别指向 T& 和 T* 或 const T& 和 const T*,表示迭代器所指向元素的引用类型和指针类型
该类还定义了一个私有类型别名 Node,它表示链表节点的类型,其实现来自于 ListNode 类,这是在该类外定义的。通过定义 Node 类型别名,可以使得该类的实现代码中使用 Node 替代 ListNode
这种方式使用类型别名可以更好地隐藏类实现的细节,使代码更加简洁易懂,并提高代码的可维护性和可读性。在该类中使用迭代器时,可以根据需要选择普通迭代器或常量迭代器,并且该类的实现中使用的是 Node 类型,可以随时更改链表节点类型的实现
3.2 迭代器的begin和end接口
有了迭代器类,我们可以向指针一样定义使用迭代器对象,因此我们为其const和非const迭代器类对象提供begin()和end()方法
begin()和end()函数是一个常见的做法,它们返回的迭代器指向的首元素和尾后元素,使得用户可以使用标准的迭代器操作来遍历整个链表
iterator begin()
{
return iterator(_head->_next);
}
//end()位置代表最后一个位置的下一个位置
//对于带头双向循环链表而言其代表头结点
iterator end()
{
return iterator(_head);
}
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}
在 const_iterator begin() const 函数中,const 关键字的作用是将成员函数声明为 const 函数。这意味着,该函数不会修改 List 对象的状态,即不能修改 List 中的元素、大小等。在这种情况下,const_iterator 类型的迭代器返回的值应该是不可变的,因此我们需要在函数声明中添加 const 限定符来保证返回值不会被修改
3.3 构造函数
①空初始化构造
构造list类对象,即是对这个头结点进行初始化,由于对头结点初始化这个操作在后续实现中会多次使用,因此我们将此功能封装在函数中:
//空初始化:哨兵位的头结点
void empty_initialize()
{
_head = new Node(T()); //匿名对象实现空初始化
_head->_next = _head;
_head->_prev = _head;
_size = 0;
}
//构造函数
list()
{
empty_initialize();
}
②迭代器构造
template <class InputIterator>
list(InputIterator first, InputIterator last)
{
empty_initialize();
while (first != last)
{
push_back(*first);
++first;
}
}
该构造函数可以接受不同类型的迭代器。在构造函数中首先调用了 empty_initialize 函数,用于初始化链表内部的头尾节点指针和链表大小等数据成员。接着通过 while 循环将区间内的每个元素添加到链表尾部,这里使用了 push_back 函数来完成添加操作。
由于该构造函数使用了迭代器来初始化链表,因此可以接受任何支持 ++、* 操作的迭代器类型,例如指针、普通迭代器、常量迭代器等;
③拷贝构造
我们所指的拷贝构造是深拷贝,关于深拷贝的实现,我们在string类和vector类的模拟实现中已经详细介绍并区分了现代写法与传统写法,这里我们直接用现代写法实现:
//swap
void swap(list<T>& lt)
{
//两个链表交换只用交换其头指针即可
std::swap(_head, lt._head);
std::swap(_size, lt._size);
}
/拷贝构造(深拷贝) 现代写法:
list(const list<T>& lt)
{
//初始化,针对哨兵位的头结点
empty_initialize();
//用迭代器构造tmp
list<T> tmp(lt.begin(), lt.end());
swap(tmp);
}
3.4 赋值重载
个人认为赋值重载和拷贝构造(深拷贝)很相似,我们有两种实现方式:①遍历赋值对象,尾插入被赋值对象;②直接传值传参于被赋值对象(现代写法)
//方式1 现代写法:传值传参 lt2=lt1
list<T>& operator=(list<T> lt)
{
swap(lt);
return *this;
}
//方式2 lt1=lt2
list<T>& operator=(const list<T>& lt)
{
//防止左右相等
if (this != <)
{
clear();
for (const auto& each : lt)
{
push_back();
}
}
return *this;
}
我们先判断左右两边是否相等,如果相等则不需要赋值,直接返回当前对象的引用;如果不相等,先清空当前对象,然后遍历右侧对象lt的所有元素,并将它们依次加入到当前对象中。这里使用到了范围for循环,每次循环都会将右侧对象lt的一个元素拷贝到当前对象中
需要注意的是,赋值运算符重载函数一般都需要处理自赋值的情况,否则可能会导致对象状态异常甚至崩溃。
3.5 size
//长度
size_t size() const
{
return _size;
}
3.6 empty和clear
//判断链表是否为空
bool empty() const
{
return _size == 0;
}
我们需要使用迭代器逐个对每个结点进行清空操作:(保留了头结点)
//clear
void clear()
{
iterator it = begin();
while (it != end())
{
//用的是erase返回的是下一个位置的迭代器
it = erase(it);
}
}
首先定义一个迭代器it,初始值为begin();循环遍历list,通过调用erase()函数删除迭代器it指向的节点(erase()会在下面介绍,这里提前用一下)
需要注意的是,erase()函数会将当前节点从链表中删除,并返回下一个节点的迭代器。在每次循环迭代中,需要将迭代器it更新为erase()函数返回的迭代器,否则会导致迭代器失效,出现不可预期的错误(迭代器失效问题)
3.7 析构函数
我们复用clear()函数即可实现析构:
~list()
{
clear();
delete _head;
_head = nullptr;
}
3.8 指定位置插入删除
①insert
链表的插入很简单,只用创建一个新结点,并链接到原链表之中即可(是在pos位置之前插入)
void insert(iterator pos,const T& val)
{
//Node提供了构造函数
Node* newnode=new Node(x);
//对于当前结点
Node* cur=pos._pnode;
//当前结点的前一个结点
Node* prev=cur->_prev;
//链接过程
prev->_next=newnode;
newnode->_prev=prev;
newnode->_next=cur;
cur->_prev=newnode;
_size++;
return iterator(newnode);
}
+-----------------+ +-----------------+ +-----------------+
| node 1 (_head) |->| node 2 (data 1) |->| node 3 (data 2) |->nullptr
+-----------------+ +-----------------+ +-----------------+
↑
|
it
|
+-----------------+
| newnode (val) |
+-----------------+
在对照函数,it 指向的是节点 2,因此 prev 指向节点 1,cur 指向节点 2;newnode 是一个新创建的节点,它的值为 val。
② erase
在指定位置删除,我们需要返回删除后的下一个位置,防止迭代器失效引发的问题
iterator erase(iterator pos)
{
assert(pos!=end());
Node* prev=pos._pnode->_prev;
Node* next=pos._pnode->_next;
prev->_next=next;
next->_prev=prev;
delete pos._pnode;
_size--;
return iterator(next);
}
3.9 头尾插入删除
复用insert()和erase()即可:
(仅需注意end()的位置处于哨兵位的头结点)
void push_back(const T& x)
{
insert(end(), x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_front()
{
erase(begin());
}
void pop_back()
{
erase(--end());
}
三、list与vector的对比
| 容器类型 | 优点 | 缺点 |
|---|---|---|
| vector | 下标随机访问;尾插尾删效率高;CPU高速缓存命中高 | 前面部分插入删除数据效率低;扩容有消耗,还存在一定空间浪费 |
| list | 按需申请释放,无需扩容;任意位置插入删除O(1) | 不支持下标随机访问;CPU高速缓存命中率低 |
总结:vector和list可以互补配合,根据不同的使用场景选择合适的容器。vector适合频繁访问元素,list适合频繁插入删除元素