【JVM】JVM基础知识:垃圾回收、JVM调优
垃圾回收
对象被创建之后就可以使用了,当对象被使用完了、没有作用了之后 JVM 就把它当作垃圾给清除掉了。
所以怎么判断一个对象没有作用了就是垃圾回收的第一步————判断对象是否是垃圾。
怎么判断一个对象/类是垃圾?
对象
判断一个对象是否是垃圾,主要有两种方法:
-
引用计数法。
这种方法是给对象增加一个计数器,当一个对象被引用时,它的计数器就会 +1;当引用失效时,它的计数器就会 -1。在 GC 的时候,一旦一个对象的计数器为 0 时,JVM 就会把它判定为垃圾对象,然后把它清除掉。
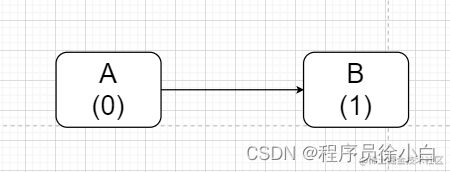
比如这里 A 对象引用了 B 对象,那么 B 对象的计数器就会 +1。
这种方法的优点是实现简单、效率高,但是目前没有虚拟机使用这种方法来判定垃圾对象,因为这种方法没办法解决循环引用的问题。

比如这里,如果 A 引用了 B,B 再引用了 A,那么它们的计数器都等于 1,只要它们俩一直相互引用,就算它们俩都没有作用了,没有其它对象引用它们,那 A 和 B 对象也不会被清除掉。
-
可达性分析算法。
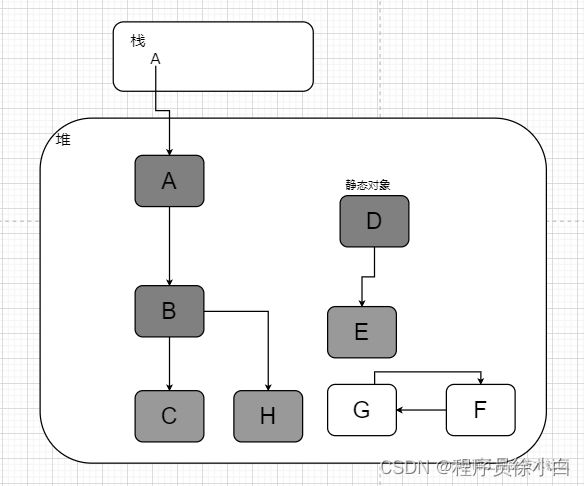
这种方法就能够解决循环引用的问题,这种方法会把线程栈中引用的对象、静态变量和本地方法中引用的对象当作 GC Roots,在 GC 前,就会以 GC Roots 作为起点,向下搜索这些节点引用的对象,所有找到的对象都被标记为非垃圾对象,没有标记的对象就会被清除掉。

像这里,栈中的对象引用了 A 对象,那么 A 对象一条下来的引用链上的对象都会被标记为非垃圾对象,静态对象也是同理,而 F 和 G 对象则没有被 GC Root 引用,就算它们俩相互引用了也会被标记为垃圾对象。
以上就是常见的两种判断对象是否是垃圾的方法了。
类
而判断一个类符合以下三个条件才会被判定为垃圾:
- 该类所有的实例都被回收了。
- 加载该类的类加载器也被回收了。
- 该类的 Class 对象也被回收了,也就是没有地方通过反射访问该类的方法。
垃圾回收算法
在正式开始讲垃圾回收器之前,还要讲一下垃圾回收相关的理论(算法),所有垃圾回收器回收垃圾的逻辑都是都是依赖这些理论的,可谓是万变不离其宗。
本节的内容有:分代收集理论、标记-复制算法、标记-清除算法和标记-整理算法。
分代收集理论
这种理论就是根据对象存活周期的不同把内存分为不同的区域。
java 的大多数垃圾收集器都是把堆分为年轻代和老年代,这样我们就可以根据不同的年代合适的垃圾收集算法。
比如,在年轻代中的大量对象都是临时使用的,基本上活不过几轮 GC,这就可以选择使用标记-复制算法,每次只需要复制少量的对象就可以很快地完成一次垃圾回收。
而在老年代中对象的存活几率是很大的,所以使用标记-复制算法的成本可能很大(1.空间利用率低,2.若存活率高,则清除效率低),所以更加推荐使用标记-清除算法或者标记-整理算法,但这两个算法所需要的成本是标记-复制算法的十倍以上。
总的来说,分代收集理论就是希望把对象分类,让 JVM 找到最合适的算法去回收垃圾各类的对象。
年轻代的对象何时转移到老年代?
在 Minor_GC 时会把对象移入老年代的情况有:是否长期存活的对象?对象动态年龄判断机制、老年代空间分配担保机制。
这三种情况不是分代收集理论衍生而来的方法论,而是现在的 JVM 已经实现的功能。
是否是长期存活的对象?
一个对象经历了很多次 Minor_GC 后就得进入老年代了,总不能赖在年轻代吧。
于是 JVM 给每个对象分配了一个年龄计数器,一个对象每当经历一次 Minor_GC,年龄计数器就会 +1。
当对象的年龄到达最大年龄之后就会被转移到老年代,我们可以通过-XX:MaxTenuringThreshold=15参数设置对象的最大年龄,默认是 15,CMS 默认的是 6。
对象动态年龄判断机制
在经历过一次 Minor_GC 后,就会把 Eden 中的存活对象放入 Survivor0,当 Survivor0 中的对象占用了 Survivor0 的 50% 以上的空间。那么就会按照年龄从小到大计算对象占用的内存,当达到 50% 后,就会获取到这一批对象(计算的对象)中最大的年龄,再把 Survivor0 中大于或者等于这个最大年龄的对象都移入老年代。

假设这里的 Survivor0 放满了对象,这时就会按照年龄从小到大计算对象占用的内存,那么计算这几个对象内存就已经达到了 Survivor0 的 50%。
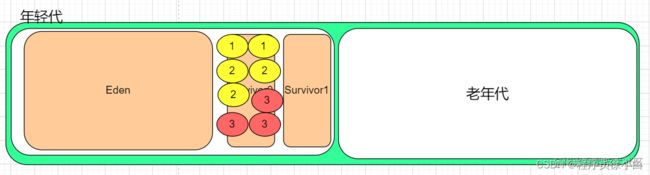
虚拟机就会把 Survivor0 中年龄大于或者等于 2 的对象移入到老年代。
我们可以通过参数-XX:TargetSurvivorRatio来设置占用 Survivor 的多少内存会触发这个机制。
老年代空间分配担保机制

在每次 Minor_GC 之前,会先看看当前年轻代中的对象内存大小是否大于老年代的可用空间。
-
如果大于,就会再去看看 JVM 有没有设置参数
-XX:-HandlePromotionFailure。-
如果没有设置就会直接 Full_GC,然后再进行一次 Minor_GC。
-
如果设置了,就会判断之前每次 Minor_GC 之后进入老年代的对象的平均大小是否小于当前老年代可用的内存大小。
- 如果是,那就直接进行 Minor_GC,但如果 Minor_GC 后要进入老年代的对象内存大小还是大于老年代可用的内存大小,那就会再进行一次 Full_GC。
- 如果否,如果大于,那就先进行一次 Full_GC,腾出老年代中的内存空间后,再进行 Minor_GC。
-
-
如果小于,那就直接进行 Minor_GC,因为老年代的空间比年轻代的大,所以可以放心 GC。
通过老年代空间分配担保机制,我们可以积攒多一次 Minor_GC 后放入老年代的对象,等着下一次 Full_GC 一起清理。
标记-复制算法

这种算法需要先将内存空间分为两部分,一部分用于分配要创建的对象,另一部分作为保留空间。
标记-复制算法主要有三个步骤:
-
先扫描一边可用空间中的对象,把非垃圾对象标记后。
-
再把标记的对象复制到保留空间中。
-
接着清除掉原来的可用空间,并将其作为新的保留空间,原来的保留空间就变成了新的可用空间。

(绿色的是存活的对象,红色的是垃圾对象,蓝色的是保留空间)
比方说,当遇到图中左边的情况——内存空间已经用完了,准备 GC。
这就会把存活的对象复制到右边的内存中,接着左边的空间一次性清除掉,接下来要创建的对象就会被分配在右边了。
这种算法的效率很高,但是对空间的利用率比较低,所以在年轻代中内存空间划分一般都是 Eden:Survivor0:Survivor1 = 8:1:1,也就是保留空间只会占十分之一。
标记-清除算法
标记-清除算法和标记-整理算法就不需要把内存划分为多块区域了。
标记-清除算法主要有两个步骤:
-
扫描内存中的对象,把非垃圾对象标记出来,下一个步骤这些对象就不会被清除,反过来就是标记垃圾对象,下一个步骤把这些对象清除掉。
-
清除掉需要回收的垃圾对象。

这种算法也比较简单,但是它会有碎片问题,标记清除之后会产生大量不连续的空间。
标记-整理算法
标记-整理算法是为了弥补标记-清除算法的不足,它和标记-清除算法的不同主要是在第二个步骤。
标记-整理算法主要有两个步骤:
-
扫描内存中的对象,把非垃圾对象标记出来,下一个步骤这些对象就不会被清除,反过来就是标记垃圾对象,下一个步骤把这些对象清除掉。
-
把非垃圾对象向内存空间的某一端移动,当清理完成后,内存空间就会剩下一大段连续规整的内存空间。

这种算法就能有效解决碎片问题,让可用空间保持规整连续,但耗时会相对高一点。
垃圾收集器
讲完了基础的清除垃圾算法,接下来就要讲垃圾收集器了。
可能有人会问,这些理论和算法和垃圾收集器有什么关系啊?
这些理论和算法是实现垃圾收集器的方法论,而垃圾收集器则是这些理论的实现,可以说是万变不离其宗。

这些是常见垃圾收集器,分代垃圾收集器中有连线的就说明这些垃圾收集器可以组合在一起,而 G1 和 ZGC 就不是分代的垃圾收集器了。
详情往下看吧。
Serial 垃圾收集器
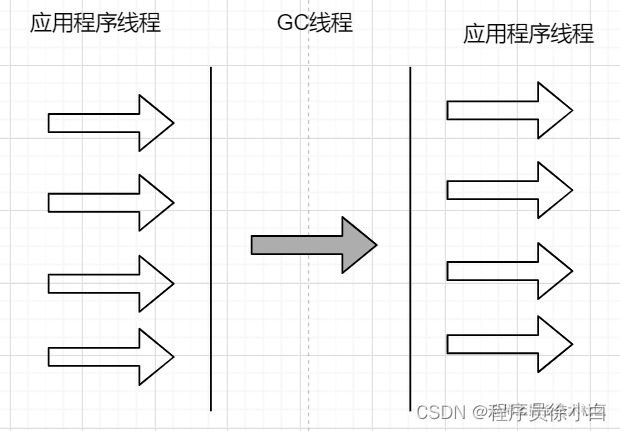
Serial(串行)垃圾收集器,我们看名字就知道它是一个单线程的垃圾收集器,当我们使用这个垃圾收集器时,除了 STW,JVM 还只会开启一个线程来清除垃圾,所有应用程序线程都会被暂停,直到垃圾对象被清理完了。
-
Serial 垃圾收集器可以用于年轻代,使用的垃圾回收算法是标记-复制算法。
-
Serial Old 垃圾收集器可以用于老年代,使用的垃圾回收算法是标记-整理算法。
使用
-XX:+UseSerialGC开启年轻代使用 Serial 垃圾收集器,-XX:+UseSerialOldGC开启老年代使用 Serial Old 垃圾收集器。
这个垃圾收集器唯一的优点就是实现简单,而它的缺点就是会有很长的 STW、效率也不会特别高。虚拟机的设计者也知道 STW 会给用户带来不好的体验,所以后续的垃圾收集器一直都在缩短 STW 上做努力。
现在基本上不会主动使用 Serial 垃圾收集器了,目前只有作为 CMS 的备选方案的 Serial Old 还会被使用。
ParNew 垃圾收集器
ParNew 垃圾收集器是年轻代 Serial 垃圾收集器的多线程版本,当我们使用 ParNew 垃圾收集器时,JVM 仍然会进入 STW,只不过会开启多线程来进行垃圾回收,极大地提高 CPU 的使用效率。

- ParNew 垃圾收集器可以用于 年轻代,使用的垃圾回收算法是标记-复制算法。
使用
-XX:+UseParNewGC开启年轻代使用 ParNew 垃圾收集器。
ParNew 垃圾收集器 除了可以和 Serial Old 垃圾收集器一起使用,还可以和 CMS 垃圾收集器一起使用。
CMS 还可以和 Serial 一起使用,但是 Serial 是单线程啊,所以在 JDK1.8 中推荐的组合是 ParNew + CMS,虽然 ParNew 还是会 STW,但是因为标记-复制算法运行速度很快,所以可以忽略 STW 的时间。
Parallel 垃圾收集器
Parallel 垃圾收集器则是一款全新的垃圾收集器,它的目标是榨干 CPU。Paraller 垃圾收集器和 ParNew 垃圾收集器一样,会进入 STW,也会开启多线程来进行垃圾回收。

Parallel 垃圾收集器同样也被分为年轻代和老年代:
- Parallel 垃圾收集器可以用于 年轻代,使用的垃圾回收算法是标记-复制算法。
- Parallel Old 垃圾收集器可以用于老年代,使用的垃圾回收算法是标记-整理算法。
使用
-XX:+UseParallelGC开启年轻代使用 Parallel 垃圾收集器,-XX:+UseParallelOldGC开启老年代使用 Parallel Old 垃圾收集器。
那 Parallel 和 ParNew 有什么区别呢?
Parallel 更加关注于提高 CPU 的吞吐量,从而缩短 STW 的时间。
而 ParNew 则是 Serial 的多线程版本,除了多线程之外和 Serial 没有太大的差别。
还有就是 Parallel 不支持和 CMS 一起使用。
CMS 垃圾回收器
CMS(Concurrent Mark Sweep)收集器是一种以实现最短 STW 为目标的垃圾收集器,也是第一款实现垃圾收集线程和应用程序线程并发的垃圾收集器,可以给用户带来更好的体验。
Mark Sweep 是标记清除的意思,也就是说 CMS 使用的算法是标记-清除算法,当然 CMS 也是只适用于老年代的。
因为要缩短 STW,所以 CMS 分了很多个阶段来完成垃圾回收,光标记对象就分为了三个阶段:
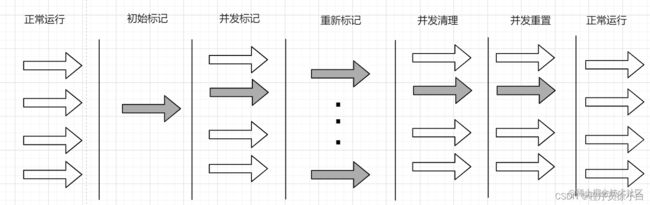
初始标记:这个阶段会 STW,主要做的工作就是标记 GC Roots 中的对象(线程栈中引用的对象、静态变量和本地方法中引用的对象),这个过程比较快速。

并发标记:在这个阶段,垃圾回收线程会和应用程序线程并发执行,虚拟机只会沿着在初始阶段中标记的 GC Roots 往下标记对象,没有被标记的对象就是垃圾。
这里不得不提一下初始标记阶段的作用了,初始标记是为了划定要清除垃圾的范围,如果在后面的并发标记中程序还在运行,还产生了新的 GC Root,那还要沿着这个 GC Root 往下标记吗?
当然不要啦,否则只要程序不停,标记就不会停,所以要划分好清除垃圾的范围,除了初始标记的 GC Roots 和新创建的对象(也就是新建的对象直接标记为非垃圾对象),一律都当做垃圾对象给清除掉。
重新标记:这个阶段也会进行 STW,而且比初始标记的长,这个阶段主要是要解决漏标的问题。
因为 CMS 是垃圾回收线程和应用程序线程并发运行的,必然会出现漏标或者多标的问题,具体解决漏标或者多标的问题还涉及三色标记、读屏障,这个放到后面去讲。
并发清理:这个阶段是垃圾回收线程和应用程序线程并发运行的,一边清理垃圾对象一边为用户提供服务。
并发重置:这个阶段是垃圾回收线程和应用程序线程并发运行的,重置本次 GC 过程中给对象所做的标记。
CMS 垃圾收集器是一款非常优秀的垃圾收集器,实现了应用程序线程和垃圾回收线程并发执行,主要的优点是并发收集和低停顿,可以给用户带来很好的体验,但它也同样有缺点:
- 对 CPU 资源敏感:垃圾回收线程会和应用程序线程抢资源。
- 会产生浮动垃圾:在并发标记和并发清理的过程中也会产生新的垃圾,这些垃圾就只能等到下次 GC 再清除了
- 会产生空间碎片:因为 CMS 是采用标记-清除算法,所以会出现碎片问题,但是我们可以使用参数
-XX:+UseCMSCompactAtFullCollection让 CMS 在执行完标记-清除后再做一次整理。 - 存在不确定性:因为 CMS 不会等到整个老年代都被放满了再 GC,而是会保留一部分的空间来存放应用程序使用新创建的对象,然后实现清理垃圾对象和应用程序同时运行,当这一部分空间也被放满了,那整个应用程序就跑不了了,这就是在垃圾回收的过程中又触发了垃圾回收——“concurrent mode failure”,这时,整个虚拟机就会进入 STW,然后使用 Serial Old 来完成垃圾回收。
漏标问题
什么情况下会漏标和多标呢?
-
什么情况下会漏标呢?
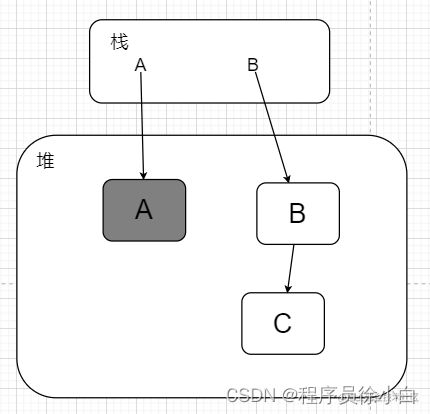
当 A 对象被扫描了,被判定为非垃圾对象,然后随着应用程序线程运行,A 又引用了一个新创建的对象 B,那这个 B 对象就是被漏标的对象。
具体场景可以参照下方的代码。
public class Test08 { private Object o=null; public static void main(String[] args) { Test08 a = new Test08(); Test08 b = new Test08(); b.o = new Test08(); // 假设运行到这里时,就触发了 FULL_GC,开始扫描GC root,接着并发标记 a.o=b.o; b.o = null; } }如果在运行后面两行命令之前 A 对象就被扫描了。
接着再把 B 引用的 C 赋值给 A 的成员变量,B 对象再取消 C 对象的引用。
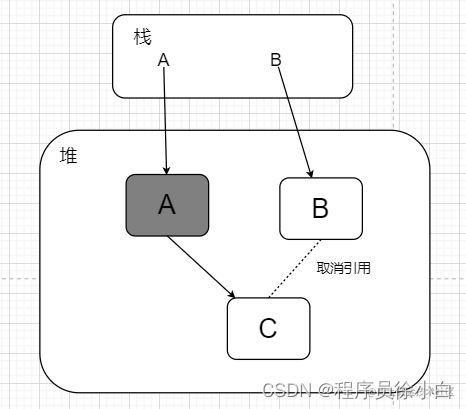
那么从 B 出发就扫描不到 C,就会造成漏标。
-
什么情况下会多标?
当 A 对象被扫描后,被判定为非垃圾对象,虚拟机再沿着 A 对象引用往下扫描,扫描了 A 引用的对象 B 后,A 再把 B 的引用置空,这时的 B 对象就是多标的对象了。
public class Test08 { private Object o=null; public static void main(String[] args) { Test08 a = new Test08(); Test08 b = new Test08(); a.o = b; // 假设运行到这里时,就触发了 FULL_GC, // 如果 a 和 b 对象都被扫描过了,都被判定为非垃圾对象了。 // 而后面的操作就就是取消了 b 的引用,那这 b 对象便变成了垃圾,但 b 对象已经被标记了,这时就出现了多标的情况。 b = null; a.o = null; } }
三色标记
在并发标记的阶段中,对象间的引用随时会发生改变,可能会出现漏标和多标的情况,这时就需要使用三色标记来记录对象的状态了。
三色标记按照“是否被扫描过”把对象分为三类:
白色:表示这个对象还没有被扫描过,如果这个对象在并发标记和重新标记后还是白色,就会被判定为垃圾对象。
灰色:表示这个对象被扫描过,但是这个对象存在一个以上的引用对象没有被扫描,灰色的对象也是非垃圾对象,但是它的引用还需要扫描。
黑色:表示这个对象和对象引用的对象都被扫描过了,这个对象是非垃圾对象,在并发清理阶段不会被清除。
正常情况下就是沿着 GC Roots 往下扫描。

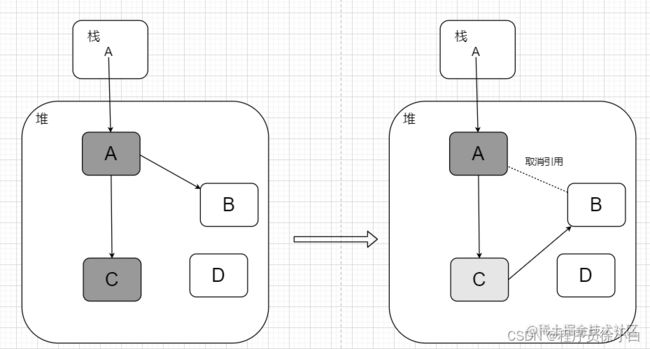
但如果扫描 A,C 对象后,A 不引用 B 了,C 引用了 B。
那么 C 就要被标为灰色,还需要进行一次扫描 C 对象。
如何解决漏标?
三色标记只是记录了对象的状态,想要实际地解决漏标的问题还需要依赖写屏障和读屏障。
至于多标,多标没有关系,留着下次再清理就好了,但是漏标就危险了,一个被引用的对象突然间变成了空指针,就可能报空指针异常了。
什么是写屏障和读屏障呢?
-
写屏障。
写屏障是 JVM 会监听 Java 代码的赋值操作,在赋值前和赋值后都设置一个节点,以便实现更多操作,类似于 AOP。
正常的赋值操作如下:
void oop_field_store(oop* field, oop new_value) { *fieild = new_value // 赋值操作 }增加了写屏障后,就变成了:
void oop_field_store(oop* field, oop new_value) { pre_write_barrier(field); // 写屏障-写前屏障 *fieild = new_value // 赋值操作 pre_write_barrier(field); // 写屏障-写后屏障 } -
读屏障。
读屏障是 JVM 监听 Java 代码的每次访问对象地址的操作,在每次访问对象之前设置一个可以扩展操作的节点。
正常的获取对象的操作:
oop oop_field_load(oop* field) { return *field; }增加读屏障后,就变成了:
oop oop_field_load(oop* field) { pre_load_barrier(field); // 读屏障-读取前操作 return *field; }
当然啦,这几个操作都不需要我们去添加,都是在 JVM 底层已经实现了的,这里只是写一个大概,我们只要知道这两个屏障就类似于 AOP,可以监听代码的写入和访问对象的操作。
解决漏标百花齐放
CMS、G1 解决漏标问题分别使用了读屏障、写屏障+特定算法,没有最优只有最合适:
- CMS:写屏障+增量更新
- G1:写屏障+SATB
至于 ZGC 会不会有漏标的问题呢?
可能有,但是目前资料并不多,这里不做讨论了。
增量更新
增量更新就是当一个被标记为黑色的对象(自己及自己引用的对象都被扫描了的)引用了白色的对象(自己及自己引用的对象没有被扫描)时,就会把这个黑色的对象记录下来(可以被理解为被标记为灰色了),等到并发标记结束后,在重新标记中再次扫描被记录下来(灰色)的对象。
原始快照(SATB)
原始快照就是当灰色对象取消引用白色对象时,虚拟机把白色对象给记录下来,等到并发标记结束后,再把记录的白色对象都标记为黑色。
虽然这些白色对象可能会变成垃圾,进而出现多标,但是这种方法也能解决漏标的问题,并且效率还不错。

以上两种方法都是为了解决,未扫描的对象被赋值给已扫描的对象导致的漏标问题,其他情况我暂时还没想到,欢迎补充。
为什么 CMS 使用增量更新,而 G1 使用原始快照呢?
首先是内存大小,推荐 8G 以上的内存使用 G1,小于 8G 的使用 CMS,越大的内存就需要使用越高效的算法,否则内存增大一倍还是用原来的算法,效率都慢了不止两倍了,STW 会严重影响用户的体验。
其次是两种垃圾回收器的内存区域划分不一样,G1 会将堆划分为多个内存相等的区域(Region),再分配给年轻代 or 老年代,内存容量太大了导致 G1 深度扫描对象的成本就很高,所以增量更新不适合 G1,原始快照不需要深度扫描对象,而 CMS 的年轻代 or 老年代分别只有一块区域,内存容量也不是特别大,而且跨区域的情况也少。
记忆集&卡表

在分代的垃圾回收器中,会出现老年代引用着年轻代这种跨代引用的现象,那么在虚拟机进行 Minor_GC 时,总不能把老年代的对象也加入 GC_Roots 中吧?
于是就出现了记忆集(Remember Set)的概念,记忆集在收集区域(比如年轻代)记录了非收集区(比如老年代)对收集区域的引用集合,这样就能避免去扫描整个非收集区域了。
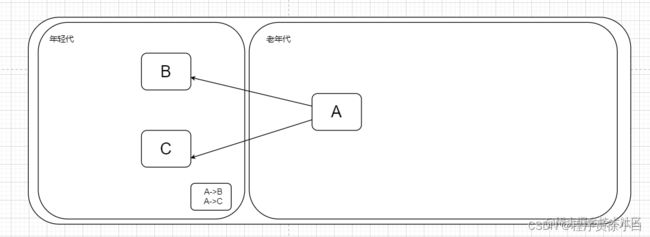
例如这里记录了A->B,A->C,那么在年轻代进行 GC 时也会沿着这两条记录往下扫描。
同理,跨区域引用也可以使用这种方法解决。
而在 hotspot 中则是使用卡表(Card Table)的方式来实现记忆集的功能,不过卡表是存储在非收集区的,虚拟机把非收集区划分为多个同等大小的区域,这些区域被成为卡页,卡表是使用一个字节数组实现的:CARD_TABLE[],每个元素标识着每个卡页是否引用了收集区域的对象,若标记为引用了,则会扫描这块区域。
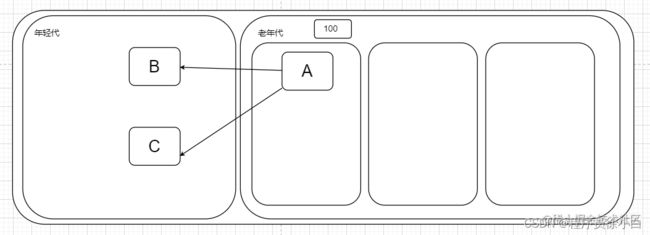
例如,这里记录了100,1 代表卡页引用着年轻代的对象,0 代表没有,那么就会扫描老年代中的第一个卡页的对象。
在 CMS、Parallel、Serial 中,主要是解决跨代引用,但跨区引用的情况很少,而在 G1 中,跨区域引用的问题就很多了。
G1 垃圾回收器
G1(Garbage-First)是一款面向服务端的垃圾收集器,适用于多核处理器及大容量内存的服务器,并且还具备可设置 GC 预计停顿时间和高吞吐量的特点。
使用参数-XX:+UseG1GC就能启用 G1。
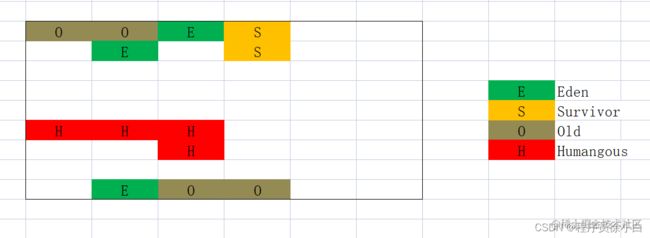
G1 还是分代垃圾收集器,仍然保留了年轻代和老年代的概念,但不再是像之前的垃圾收集器那样了 。
G1会把 Java 的堆划分为多个大小相等的区域(Region),年轻代和老年代的 Region 在堆中任意排布,不需要相连在一起。Region 的预期数量是 2048 个,而 Region 的大小范围在 2M ~ 32M,也就是堆内存的大小在 4G ~ 64G,如果堆大小小于 4G 或者超过了 64G,那么就会改变 Region 的数量 。
对于大对象的处理,之前垃圾收集器都是直接把大对象直接丢到老年代,而 G1 则是设置了一个专门存储大对象的 Humangous 区域,在 G1 中,一个对象的大小超过 Region 大小的一半时就会被判定为大对象,然后被放入一个 Humangous 区。
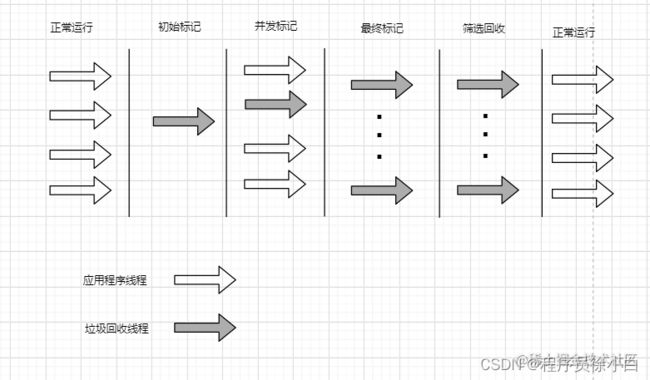
- 初始标记:STW,标记所有 GC_Roots。
- 并发标记:和 CMS 的并发标记一样,同应用程序线程并发执行,沿着 GC_Roots 往下扫描。
- 最终标记:STW,和 CMS 的重新标记一样,重新标记漏标的对象。
- 筛选回收:STW,这个阶段会根据每个 Region 的回收价值和回收成本排序,再根据用户设置的期望停顿时间(可以使用 JVM 参数:
-XX:MaxGCPauseMillis设置)来制定回收计划。比如说,设置了预期停顿时间为 200 ms,回收 1000 个 Region 需要花费 300 ms,而回收其中价值最高的 800 个 Region 只需要 200 ms的停顿时间,那么就会回收这 800 个 Region。
G1 垃圾收集器的前三个阶段和 CMS 的差不多,而筛选回收阶段就是 G1 的精髓所在了。
你可能也会注意到 G1 的筛选回收阶段是 STW 的,而 CMS 的并发清理阶段则是并发的。
这是因为,G1 使用的垃圾回收算法是标记-复制算法,回收效率高,没有碎片问题,而且 G1 的停顿时间是可控的,直接 STW 集中资源去回收垃圾反而会更加高效。
G1 垃圾收集器的还增加了 GC 种类:
- Young GC:针对年轻代的 GC,但在 G1 中不会等到 Eden 满了才触发这个 GC,而是预计停顿时间接近
-XX:MaxGCPauseMills参数设置的时间才会触发 Young GC。 - Mixed GC:这个 Mixed GC 就是原来的 Full GC 了,针对整个堆空间的 GC,只有在老年代空间占有率达到
-XX:InitiatingHeapOccupancyPercent参数设置的值时才会触发 Mixed GC。 - Full GC:Full GC 就类似于 CMS 的“concurrent mode failure”了,当没有足够空间存放要复制的对象时,会暂停整个 JVM,用一个单线程来回收整个堆,这个过程非常耗费时间。
再来总结一下 G1 垃圾收集器的特点:
- 并行与并发:G1 即会与应用程序线程并发标记对象,让应用程序继续运行,也会充分利用 CPU 资源来回收垃圾对象,缩短 STW 的时间。
- 分代收集:虽然 G1 把堆分成了多个 Region,并且没有分年轻代和老年代的垃圾收集器,但它还是有分代收集的概念。
- 空间整理:与 CMS 使用的标记-清理算法不同,G1 整体上也是标记-整理,但是局部上是标记-复制算法。
- 可预期停顿:除了拥有 CMS 的低停顿,G1 还可以设置预期的停顿时间。不过这个预期停顿时间要合理设置,设置的太短,垃圾收集器根本回收不了垃圾,设置的太长, Survivor 区放不下就只能放入老年代了。
- 存在不确定性:与 CMS 类似,G1 也是并发的一个垃圾收集器,当预留的空间不够正在运行的程序使用时,就会触发 Full GC。
最后,什么场景推荐使用 G1 呢?
- 堆内存在 8G 以上,堆内存越大,G1 越占有优势。
- 单次 GC 的 STW 超过一秒或者STW 时间要求低于 500ms,G1可以预测停顿时间,可以控制单次 GC 的 STW 时间。
ZGC 垃圾回收器
ZGC 垃圾收集器是一款在 JDK11 中引入的还在实验阶段的低延迟垃圾收集器,ZGC 可以说源自于是 Azul System 公司开发的 C4(Concurrent Continuously Compacting Collector)收集器。
使用参数-XX:+UnlockExperimentalVMOptions -XX:+UseZGC就能启用 ZGC。
ZGC 的主要目标如下:
- 支持 TB 量级的堆内存。目前我们的生产环境中还没有 TB 量级的堆,但 TB 量级的堆足以满足未来数十年的 Java 应用程序使用了。
- 最大停顿不超过 10ms。G1 只是能预设停顿时间,如果设置的停顿时间太短,就会无法清除垃圾,而 ZGC 能做到最大停顿不超过 10ms,是因为 ZGC 的停顿时间只和 GC_Roots 的扫描有关,后面的扫描、清除垃圾等都是并发操作。
- 奠定未来垃圾收集器的基础。
- 最糟糕情况下吞吐量会下降 15%。虽然 CPU 资源的吞吐量会下降,但是停顿时间仍然不会超过 10ms,官方提到 ZGC 的停顿时间并不会随着堆内存的增大而增大,而是无论多大内存都会控制在 10ms 以下。
ZGC 的内存布局
ZGC 也是一款基于 Region 内存分布的垃圾收集器,把内存分成很多不同作用的内存块,ZGC 是一款使用了NUMA-aware、读屏障和颜色指针等技术,以低停顿为首要目标的,暂时还不分代的垃圾收集器。
(ZGC 暂时不分代,但以后会实现分代。)
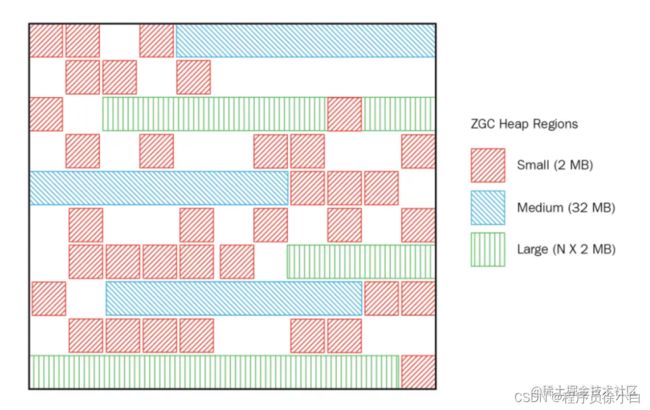
如上图所示,在 ZGC 中,内存会被划分为三种大小的内存块:
- 小型 Region(Small Region):内存容量固定为 2M,用于存放小于 256KB 的小对象。
- 中型 Region(Medium Region):内存容量固定为 32MB,用于存放大于 256KB 但小于 4MB 的对象。
- 大型 Region(Large Region):内存容量不固定,可以动态变化,但内存容量必须是 2M 的整数倍,用于存放大于 4MB 的大对象,一个 Large Region 只会存放一个大对象,并且 Large Region 不会参与并发重分配阶段,也就是不会被复制到另外一块内存空间上,只会在判定为垃圾时被删除掉。
ZGC 运用的三大技术
-
NUMA-aware。
NUMA 展开是 Non Uniform Memory Access Architecture,意思是非统一内存访问架构,具体来说就是让每个 CPU 都对应一块内存,在 CPU 访问内存时,优先访问分配给自己的内存,当自己的内存用完了再去访问其他内存空间。
NUMA 的对立面就是 UMA,UMA 的情况就是多个 CPU 同时访问一块内存,这就会造成内存竞争问题,有竞争就会有锁,有锁就会降低性能,所以 NUMA 是目前大型服务器提高性能的最常用的解决方案。
-
颜色指针。
这里的颜色对应的就是我们之前讲到的三色标记,在 ZGC 中,标记对象状态的颜色标记不再存储在对象头上了,而是存储在指向对象的指针上了。

当使用了颜色指针,对象的 64 位指针的结构就会变成如图所示的组成部分:
- Unused(18bit):未使用部分,预留给以后使用。
- Finalizable(1bit):不可视标记,标记后说明该对象可以被当作垃圾对象清除了。
- Remapped(1bit):重映射标记,标记后说明该指针指向的对象已经被挪动了,该指针需要重新映射到新的地址上,这个标记需要和读屏障一起配合使用。
- Marked1(1bit)+ Marked0(1bit):两个标记位一起组成了三色标记所需的标记位,要知道 2bit 就能记录四种状态。
- Object Address(42bit):对象地址,42bit 的指针可以支持 4T 内存。
-
读屏障。
oop oop_field_load(oop* field) { pre_load_barrier(field); // 读屏障-读取前操作 return *field; }在前面也讲过读屏障啦,就是 JVM 监听每次访问对象的操作,并在前面设置一个可扩展的操作节点。
有了读屏障和颜色指针,ZGC 就可以在清理对象时直接移动对象了(根本不需要 STW),不必先把所有指针都修改成最新的地址后再移动对象,而在下次程序访问移动过的对象时,JVM 就能在读屏障中根据颜色指针(Remapped 标记)识别这个对象是被移动过的了,进而再在读屏障中把这个指针修改为移动过后的对象的地址,把指针改为正确的。
使用颜色指针和读屏障的优势:
- 几乎无需 STW:一旦标记-复制某个 Region 之后,原来的 Region 就可以直接被清除释放掉内存了,无需再等待整个堆中指向这个 Region 的引用被修正过来。
- 减少了屏障的使用:有了颜色指针,ZGC 只需要使用读屏障就可以完成垃圾收集了,不需要再使用写屏障了。
ZGC 的运行过程
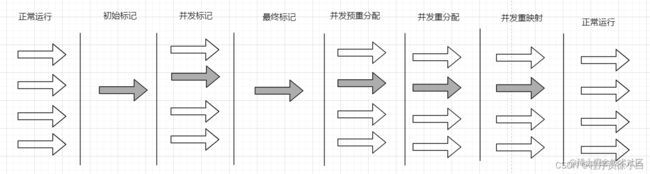
ZGC 的垃圾回收阶段分为六个阶段:
- 初始标记:这个阶段会 STW,主要是标记初始的 GC_Roots,与之前的垃圾回收器不同的是,ZGC 是标记在指针上的。
- 并发标记:这个阶段和应用程序并发运行,与之前的垃圾收集器一样,都是沿着 GC_Roots 遍历对象做可达性分析。
- 最终标记:这个阶段也会 STW,和之前的垃圾收集器一样,使用三色标记检查是否存在漏标的情况。
- 并发预重分配:这个阶段和应用程序并发运行,使用特定的算法计算出要回收的 Region,并将这些 Region 组成重分配集(Relocation Set),之前的垃圾收集器不同的是,ZGC 会扫描所有 Region,以此来节省记忆集的维护成本。
- 并发重分配:这个阶段是六个阶段中最重要的阶段,在这个阶段中会把重分配集中的 Region 的存活对象复制到新的 Region 中,并为每个 Region 分别维护一个转发表(Forward Table),这个转发表记录着旧对象到新对象的转向关系。如果在这个阶段中,应用程序线程访问了位于重分配集 Region 中的对象,那这次访问就会被读屏障拦截,ZGC 就会立刻把旧对象复制到新的 Region 上,再修正指针,ZGC 的这种行为被成为指针的“自愈”。
- 并发重映射:因为 ZGC 会存在指针“自愈”的现象,所以修正所有指针可以稍微缓一缓,所以 ZGC 把并发重映射阶段和并发标记阶段合并在一起了,在并发标记遍历所有对象的指针的同时,也会修正旧的指针,在修正完成后,就会释放掉新旧对象的转发表。
总体来说,ZGC 不仅实现了可达性分析的并发,还实现了清理垃圾对象的并发,让垃圾回收阶段的 STW 时间大大地降低了。
当然啦,ZGC 就算再,也会有一些问题的。
ZGC 最大的问题就是浮动垃圾,这也是目前并发垃圾收集器的通病。
ZGC 把停顿时间控制在 10ms 以下,但 ZGC 没有分代的概念,每次清理都只能全盘扫描,那 ZGC 的垃圾回收持续时长可就不止 10ms 了,可能长达 5 分钟,那在垃圾回收期间肯定会创建大量的对象, 当这些对象变成垃圾后,就出现了大量的浮动垃圾。
要解决这个问题,目前只能增大堆的内存大小了,可见 ZGC 的堆空间利用率不高。
ZGC 的触发时机
在 ZGC 中,有四种情况会触发 GC:
- 定时触发:默认不开启,需要设置参数
-ZCollectionInterva=120才能开启,单位是秒。 - 预热触发:在刚启动 JVM 后,当堆内存占用率分别达到 10%,20%,30% 时就会触发,用于统计 GC 时间,后续的 GC 操作就会参考这个时间。
- 分配速率:ZGC 会基于正态分布,再根据当前堆剩余的内存空间和对象分配速率,在当前堆剩余的内存空间 = 垃圾回收持续时长 * 对象分配速率的条件下触发 GC。
- 主动触发:默认开启,可以使用
-XX:-ZProactive关闭,当距离上次 GC 已经增加了 10% 内存,或者距离上次 GC 超过了五分钟并且超过了49 * 垃圾回收持续时长,就触发 GC。
可以看出 ZGC 的 GC 频率很高,四种触发机制加在一起,基本上能够杜绝并发清理失败的情况,但是这样意味着 CPU 的吞吐率不高。
如何选择垃圾收集器
全部常用的垃圾收集器都讲完了,那要怎么选择合适的垃圾收集器呢?
按内存来选的话,可以参照下面的表格:
| 内存 | 适合的垃圾收集器 |
|---|---|
| 0-100M | Serial |
| 100M-4GB | Parallel |
| 4GB-8GB | ParNew + CMS |
| 8GB以上 | G1 |
| 几百GB | ZGC |
G1 和 ZGC 的区别就是那个好用,用那个。
若没有停顿时间的要求,可以选择 Serial、Parallel。
其他情况,就直接调好堆内存,让 JVM 自己来选择就可以了。
安全点与安全区域
安全点
JVM 要并不能随时随地地统计 GC_Roots,而是需要等所有线程都进入到“安全点”,对象的引用不会再改变时,才能触发 STW 再统计 GC_Roots。
安全点设置的太少了,线程就需要很长的时间才能响应 STW,设置的太多了,就会影响线程的性能,目前 JVM 设置的安全点主要有以下几种:
- 方法返回之前。
- 调用某个方法之后。
- 抛出异常的位置。
- 循环的末尾。
大概是下图中的位置:

让所有线程都进入安全点“待机”的方法有两种:
-
抢占式中断(已经不常见了)。
JVM 先中断所有线程,如果还有线程不在安全点,就让这些线程跑到安全点后再中断挂起。
-
主动式中断。
JVM 不会主动中断线程,而是线程主动中断挂起。当 JVM 要开始 GC 时,就会设置一个预备 GC 标记:表示准备 GC 了,当线程跑到安全点时,就会查看预备 GC 标记,如果要准备进行 GC 了,就会中断挂起,否则继续运行。
安全区
当线程跑到安全点后,就能保证引用不会被修改,但是如果有些线程的状态为 Sleep 或者 Blocked,这些线程不会在往下跑了,那么这些线程就跑不到安全点了,那还要不要开始 GC 呢?
当然要啊,于是就出现了安全区,安全区就是线程能够在这个范围的代码内放心地运行,也不会改变对象的引用,但当线程要跑出安全区时,就要等待 GC 运行完成或者 JVM 给出可以跑出安全区的信号。
JVM调优(入门)
前面的知识都是 JVM 的基础,想要调优 JVM,还得学会使用一些工具,才能让我们更加准确地做出调优。
JDK自带的命令
jmap
jmap [options] pid命令可以查询 JMV 的内存信息、实例个数及占用内存。
输入jmap -h,我们可以得到jmap的可选参数[options]有那些:

这里会讲其中的五种可选参数:< none >、-heap、-histo[:live]、-clstats、-dump:< dump-options >,剩余的就不讲述了。
顺带提以下获取 pid 的方法,在 windows 中可以使用 tasklist,在 linux 中可以使用 ps,也可以使用 jsp 来获取,一般我都是使用 jps 的(比较方便,直接查询出 java 的进程)。

接着开始讲可选参数:
-
< none >
也就是不加可选参数,直接输入
jmap pid,这个命令会打印出 JVM 的进程信息,可以看到下图中大多数都是什么 dll 的进程,跟我们调优 JVM 没有太大关系。
-
-heap
命令:
jmap -heap pid,这个命令会打印出当前 JVM 使用的是那种垃圾收集器、堆中 Eden、survivor0、survivor1、old 区域的内存以及占用情况等信息。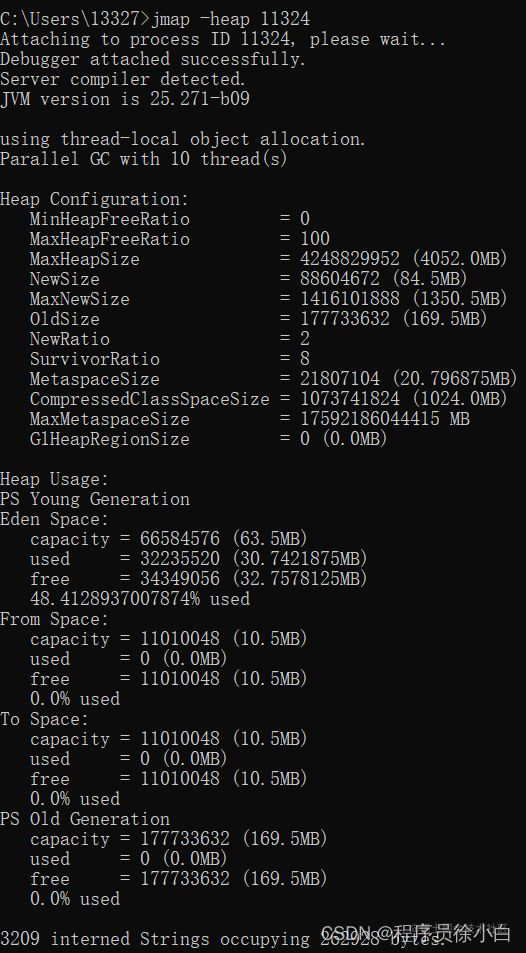
-
-histo[:live]
命令:
jmap -histo pidorjmap -histo:live pid,这两个命令都是打印 JVM 中的实例个数信息(实例个数、占用字节、类名称),前者会打印出全部实例,而后者只会打印出存活的实例。全部的实例:

存活的实例:

-
-clstats
命令:
jmap -clstats pid,这个命令会打印类加载器的统计信息:class_loader:类加载器实例的地址。
classes:加载的类数量。
bytes:占用的字节大小。
parent_loader:父类加载器,如果没有就是 null。
alive?:是否存活。
type:类加载器的类名。
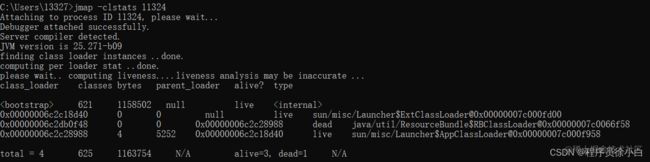
可以看到我这里也就是四个类加载器。
-
-dump
命令:
jmap -dump pid,可以加上< dump-options >:jmap -dump:live,format=b,file=heap.dump,这个命令会导出 JVM 堆内存的快照。live:加上的话就表示只导出堆中存活的对象,否则就导出全部对象。
format:导出二进制格式,貌似加不加都一样。
file:导出的快照文件名称。
命令:

dump 文件:

file 参数为必选项,否则导不出来,导出来的 dump 文件可以使用 jvisualvm 打开(摸索一下就会了,这里不做演示)。
我们也可以设置两个 JVM 启动参数:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./路径,这样就能在 JVM 内存溢出时打印堆内存的快照信息,以便后续的分析调优了。
jstack
jstack pid可以查看 JVM 中的线程信息。

上图中框出的五点,依次从左往右:
- 线程名称:“Service Thread”
- 线程优先级:prio=9
- 线程id:tid=0x000001d7a7155000
- 线程对应本地线程的id:nid=0x3330
- 当前线程状态:runnable
判断死锁
这个命令还有一个很直接的功能:查看是否有线程死锁。
让我们先写一个死锁:
private static Object lock1 = new Object();
private static Object lock2 = new Object();
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
synchronized (lock1){
try {
System.out.println("Thread 1 get lock1.");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2){
System.out.println("Thread 1 get lock2.");
}
}
}).start();
new Thread(()->{
synchronized (lock2){
try {
System.out.println("Thread 2 get lock2.");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1){
System.out.println("Thread 2 get lock1.");
}
}
}).start();
}
让我们跑起来再执行jstack pid命令:

可以看到这里的线程状态是 BLOCKED,就说明有死锁了。
jinfo
jinfo pid可以查看 Java 系统参数和 JVM 参数。
让我们执行jinfo -h
这里只讲述上面的两个选项:flags & sysprops
-
jinfo -flags pid查看当前进程运行的 JVM 的参数,就是堆和栈内存大小、使用那种垃圾收集器等等信息。

-
jinfo -sysprops pid查看 Java 运行环境的参数,比如,我们配置的 JAVA_HOME、当前操作系统的信息等。

jstat
jstat可以查看和 GC 相关堆内存的信息,比如年轻代中 eden、survivor 和老年代的内存大小,以及 Young_GC 和 Full_GC 的时间和次数等等信息。
命令格式:jstat [-option] [pid] [间隔时间(毫秒)] [查询次数]
其中 option 在jstat -h中并没有打印出来,我也不知道为啥,下面列举一些常见的 option:
-
-gc
命令:
jstat -gc pid [间隔时间(毫秒)] [查询次数],堆 GC 统计。
S0C:survivor0 的内存大小,单位KB S1C:survivor1 的内存大小 S0U:survivor0 已使用的内存大小 S1U:survivor1 已使用的内存大小 EC:eden 的内存大小 EU:eden 已使用的内存大小 OC:老年代的内存大小 OU:老年代已使用的内存大小 MC:方法区内存大小(元空间) MU:方法区已使用的内存大小 CCSC: 压缩类空间大小 CCSU: 压缩类空间使用大小 YGC:年轻代垃圾回收次数 YGCT:年轻代垃圾回收消耗时间,单位s FGC:老年代垃圾回收次数 FGCT:老年代垃圾回收消耗时间,单位s GCT:垃圾回收消耗总时间(YGCT+FGCT),单位s -
-gccapacity
命令:
jstat -gccapacity pid [间隔时间(毫秒)] [查询次数],堆内存统计。和-gc相比,这个命令就少了各个区域已使用的内存大小,而是在打印堆分布内存大小上,还多了新生代、老年代和方法区的最大和最小内存。
NGCMN:新生代最小容量 NGCMX:新生代最大容量 NGC:当前新生代容量 OGCMN:老年代最小容量 OGCMX:老年代最大容量 MCMN:最小元数据容量 MCMX:最大元数据容量 CCSMN:最小压缩类空间大小 CCSMX:最大压缩类空间大小 CCSC:当前压缩类空间大小 -
-gcnew
命令:
jstat -gcnew pid [间隔时间(毫秒)] [查询次数],新生代 GC 统计,这个命令只会打印关于新生代部分的 GC 信息:eden 和 survivor 的内存信息和 Young_GC 的信息。
TT:对象在新生代存活的次数 MTT:对象在新生代存活的最大次数 DSS:期望的 survivor 大小 -
-gcnewcapacity
命令:
jstat -gcnewcapacity pid [间隔时间(毫秒)] [查询次数],新生代内存统计,同-gccapacity一样,只会打印堆分布的内存大小。
NGCMN:新生代最小容量 NGCMX:新生代最大容量 S0CMX:survivor0 区最大容量 S1CMX:survivor1 区最大容量 ECMX:eden 区最大容量 -
-gcold
命令:
jstat -gcold pid [间隔时间(毫秒)] [查询次数],老年代 GC 统计。
CCSC:压缩类空间大小 CCSU:压缩类空间使用大小 -
-gcoldcapacity
命令:
jstat -gcoldcapacity pid [间隔时间(毫秒)] [查询次数],老年代内存统计。
OGCMN:老年代最小容量 OGCMX:老年代最大容量 -
-gcutil
命令:
jstat -gcoldcapacity pid [间隔时间(毫秒)] [查询次数],堆内存使用比例统计。
S0:survivor0 当前使用比例 S1:survivor1 当前使用比例 E:eden 使用比例 O:老年代使用比例 M:元数据区使用比例 CCS:压缩使用比例
还有jstat -gcmetacapacity,打印的是元空间的堆内存统计,和上面的内存统计也大差不差。
GC 日志
增加这三个 JVM 参数:-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause,就能打印 GC 的日志,以便服务器宕机后能查出应用程序宕机的原因或者 JVM 频繁 GC 的原因。
如果再加上-Xloggc:D:\gc-%t.log -XX:+UseGCLogFileRotation -XX:GCLogFileSize=100M,就能就能够按照日期把 GC 日志打印到文件中,并且文件大小不超过 100M。

以上是打印的一些 GC 日志,不同的垃圾收集器打印出来的 GC 日志是不同的,下面展示一下各种垃圾收集器打印出来的 GC 日志。
Parallel
命令:-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause -Xloggc:D:\gc-%t.log -XX:+UseGCLogFileRotation -XX:GCLogFileSize=100M -XX:+UseParallelGC -XX:+UseParallelOldGC
在 JDK1.7 和 JDK1.8 中 JVM 默认的垃圾收集器是 Parallel,不加后面的-XX:+UseParallelGC``-XX:+UseParallelOldGC也可以。
Java HotSpot(TM) 64-Bit Server VM (25.271-b09) for windows-amd64 JRE (1.8.0_271-b09), built on Sep 16 2020 19:14:59 by "" with MS VC++ 15.9 (VS2017)
Memory: 4k page, physical 16596340k(5196168k free), swap 30251936k(5154728k free)
CommandLine flags: -XX:GCLogFileSize=104857600 -XX:InitialHeapSize=265541440 -XX:MaxHeapSize=4248663040 -XX:+PrintGC -XX:+PrintGCCause -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseGCLogFileRotation -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
2022-07-27T21:56:28.742+0800: 38.471: [GC (Allocation Failure) [PSYoungGen: 65024K->10732K(75776K)] 65024K->60144K(249344K), 0.0118181 secs] [Times: user=0.02 sys=0.14, real=0.01 secs]
2022-07-27T21:57:17.690+0800: 87.419: [GC (Allocation Failure) [PSYoungGen: 75756K->10736K(75776K)] 125168K->123638K(249344K), 0.0141742 secs] [Times: user=0.01 sys=0.14, real=0.01 secs]
2022-07-27T21:57:17.704+0800: 87.433: [Full GC (Ergonomics) [PSYoungGen: 10736K->0K(75776K)] [ParOldGen: 112902K->123411K(255488K)] 123638K->123411K(331264K), [Metaspace: 3081K->3081K(1056768K)], 0.0138371 secs] [Times: user=0.16 sys=0.00, real=0.01 secs]
2022-07-27T21:58:07.248+0800: 136.977: [GC (Allocation Failure) [PSYoungGen: 65024K->10744K(75776K)] 188435K->187478K(331264K), 0.0126848 secs] [Times: user=0.02 sys=0.14, real=0.01 secs]
2022-07-27T21:58:56.953+0800: 186.682: [GC (Allocation Failure) [PSYoungGen: 75768K->10743K(75776K)] 252502K->251887K(331264K), 0.0148304 secs] [Times: user=0.03 sys=0.13, real=0.01 secs]
2022-07-27T21:58:56.968+0800: 186.696: [Full GC (Ergonomics) [PSYoungGen: 10743K->0K(75776K)] [ParOldGen: 241143K->251854K(386560K)] 251887K->251854K(462336K), [Metaspace: 3082K->3082K(1056768K)], 0.0322356 secs] [Times: user=0.17 sys=0.00, real=0.03 secs]
2022-07-27T21:59:46.427+0800: 236.156: [GC (Allocation Failure) [PSYoungGen: 65024K->10750K(74240K)] 316878K->319009K(460800K), 0.0130786 secs] [Times: user=0.02 sys=0.14, real=0.01 secs]
2022-07-27T22:00:35.127+0800: 284.856: [GC (Allocation Failure) [PSYoungGen: 74238K->58868K(107008K)] 382497K->382058K(493568K), 0.0160757 secs] [Times: user=0.03 sys=0.11, real=0.02 secs]
2022-07-27T22:00:35.143+0800: 284.872: [Full GC (Ergonomics) [PSYoungGen: 58868K->0K(107008K)] [ParOldGen: 323190K->379021K(519168K)] 382058K->379021K(626176K), [Metaspace: 3082K->3082K(1056768K)], 0.0247676 secs] [Times: user=0.30 sys=0.00, real=0.03 secs]
2022-07-27T22:01:11.952+0800: 321.681: [GC (Allocation Failure) [PSYoungGen: 48128K->52644K(121344K)] 427149K->431665K(640512K), 0.0069980 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
2022-07-27T22:01:48.006+0800: 357.735: [GC (Allocation Failure) [PSYoungGen: 99748K->80886K(112128K)] 478769K->477401K(631296K), 0.0147958 secs] [Times: user=0.14 sys=0.00, real=0.01 secs]
2022-07-27T22:02:12.081+0800: 381.810: [GC (Allocation Failure) [PSYoungGen: 112109K->96758K(127488K)] 508624K->508345K(646656K), 0.0157151 secs] [Times: user=0.16 sys=0.00, real=0.01 secs]
2022-07-27T22:02:35.643+0800: 405.371: [GC (Allocation Failure) [PSYoungGen: 127478K->108104K(128512K)] 539065K->537848K(647680K), 0.0171465 secs] [Times: user=0.03 sys=0.13, real=0.02 secs]
2022-07-27T22:02:46.307+0800: 416.036: [GC (Allocation Failure) [PSYoungGen: 121917K->44194K(58368K)] 551661K->551619K(577536K), 0.0185981 secs] [Times: user=0.02 sys=0.14, real=0.02 secs]
2022-07-27T22:02:46.325+0800: 416.055: [Full GC (Ergonomics) [PSYoungGen: 44194K->29342K(58368K)] [ParOldGen: 507425K->519131K(664576K)] 551619K->548474K(722944K), [Metaspace: 3082K->3082K(1056768K)], 0.0336585 secs] [Times: user=0.17 sys=0.00, real=0.03 secs]
2022-07-27T22:02:57.000+0800: 426.728: [GC (Allocation Failure) [PSYoungGen: 43151K->13770K(135168K)] 562283K->562245K(799744K), 0.0079382 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
前三行分别是:JVM 的版本信息、操作系统内存信息和 JVM 使用的参数,再往下面就是 GC 日志了。
一行 GC 日志:
2022-07-27T22:00:35.143+0800: 284.872: [Full GC (Ergonomics) [PSYoungGen: 58868K->0K(107008K)] [ParOldGen: 323190K->379021K(519168K)] 382058K->379021K(626176K), [Metaspace: 3082K->3082K(1056768K)], 0.0247676 secs] [Times: user=0.30 sys=0.00, real=0.03 secs]
可以解读成以下信息:
- 当前时间:2022-07-27T22:00:35.143+0800
- JVM 运行时长:284.872
- GC 原因:Full GC (Ergonomics)
- 年轻代内存变化:[ PSYoungGen: 58868K->0K(107008K) ]
- 老年代内存变化:[ ParOldGen: 323190K->379021K(519168K) ]
- 整个堆的内存变化:382058K->379021K(626176K)
- 元空间内存变化:[ Metaspace: 3082K->3082K(1056768K) ]
- GC 使用的时间:0.0247676 secs
- GC 时间详情:[ Times: user=0.30 sys=0.00, real=0.03 secs ]
GC 时间详情
这里分为了三种时间:user、sys 和 real。
- user:进程在用户态占用 CPU 资源的时间总和。
- sys:进程在内核态占用 CPU 资源的时间总和。
- real:进程真实运行的时间。
当服务器为多核时,大多数情况都是 user + sys > real,单核时,大多数情况都是 user + sys = real。
如果出现了 user + sys < real,就说明 IO 阻塞的时间过长了。
ParNew + CMS
命令:-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause -Xloggc:D:\gc-%t.log -XX:+UseGCLogFileRotation -XX:GCLogFileSize=100M -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection
打印日志如下:
Java HotSpot(TM) 64-Bit Server VM (25.271-b09) for windows-amd64 JRE (1.8.0_271-b09), built on Sep 16 2020 19:14:59 by "" with MS VC++ 15.9 (VS2017)
Memory: 4k page, physical 16596340k(7994928k free), swap 28130676k(15183708k free)
CommandLine flags: -XX:GCLogFileSize=104857600 -XX:InitialHeapSize=265541440 -XX:MaxHeapSize=4248663040 -XX:+PrintGC -XX:+PrintGCCause -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCMSCompactAtFullCollection -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseGCLogFileRotation -XX:-UseLargePagesIndividualAllocation -XX:+UseParNewGC
2022-07-28T21:47:36.890+0800: 51.215: [GC (Allocation Failure) 2022-07-28T21:47:36.890+0800: 51.216: [ParNew: 69376K->8640K(78016K), 0.0151908 secs] 69376K->64807K(251456K), 0.0153253 secs] [Times: user=0.02 sys=0.09, real=0.01 secs]
2022-07-28T21:48:29.465+0800: 103.790: [GC (Allocation Failure) 2022-07-28T21:48:29.465+0800: 103.790: [ParNew: 78016K->8632K(78016K), 0.0142252 secs] 134183K->132029K(251456K), 0.0142693 secs] [Times: user=0.02 sys=0.14, real=0.01 secs]
2022-07-28T21:49:23.201+0800: 157.526: [GC (Allocation Failure) 2022-07-28T21:49:23.201+0800: 157.526: [ParNew: 78008K->8621K(78016K), 0.0163369 secs]2022-07-28T21:49:23.217+0800: 157.543: [Tenured: 192139K->192434K(192448K), 0.0050829 secs] 201405K->200760K(270464K), [Metaspace: 3082K->3082K(1056768K)], 0.0222327 secs] [Times: user=0.02 sys=0.14, real=0.02 secs]
2022-07-28T21:50:55.179+0800: 249.505: [GC (Allocation Failure) 2022-07-28T21:50:55.179+0800: 249.505: [ParNew: 128384K->15994K(144384K), 0.0321017 secs] 320818K->327421K(465108K), 0.0321879 secs] [Times: user=0.19 sys=0.13, real=0.03 secs]
和 Parallel 的差不多,这里不做过多的解释。
G1
命令:-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause -Xloggc:D:\gc-%t.log -XX:+UseGCLogFileRotation -XX:GCLogFileSize=100M -XX:+UseG1GC
1 ‐Xloggc:d:/gc‐g1‐%t.log ‐Xms50M ‐Xmx50M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:+PrintGCDetails ‐XX:+Pr
intGCDateStamps
2 ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCCause ‐XX:+UseGCLogFileRotation ‐XX:NumberOfGCLogFiles=10 ‐XX:GCLogFileSize=100M
‐XX:+UseG1GC
打印的日志如下:
Java HotSpot(TM) 64-Bit Server VM (25.271-b09) for windows-amd64 JRE (1.8.0_271-b09), built on Sep 16 2020 19:14:59 by "" with MS VC++ 15.9 (VS2017)
Memory: 4k page, physical 16596340k(5969240k free), swap 30177104k(6153512k free)
CommandLine flags: -XX:GCLogFileSize=104857600 -XX:InitialHeapSize=265541440 -XX:MaxHeapSize=4248663040 -XX:+PrintGC -XX:+PrintGCCause -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC -XX:-UseGCLogFileRotation -XX:-UseLargePagesIndividualAllocation
2022-07-27T22:11:16.574+0800: 13.713: [GC pause (G1 Evacuation Pause) (young), 0.0056405 secs]
[Parallel Time: 4.5 ms, GC Workers: 10]
[GC Worker Start (ms): Min: 13713.8, Avg: 13713.8, Max: 13713.9, Diff: 0.1]
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.4, Diff: 0.3, Sum: 1.2]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 3.9, Avg: 4.1, Max: 4.1, Diff: 0.2, Sum: 40.8]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 10]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.2]
[GC Worker Total (ms): Min: 4.2, Avg: 4.2, Max: 4.3, Diff: 0.1, Sum: 42.3]
[GC Worker End (ms): Min: 13718.0, Avg: 13718.1, Max: 13718.1, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.2 ms]
[Other: 1.0 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.5 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.2 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 24.0M(24.0M)->0.0B(13.0M) Survivors: 0.0B->3072.0K Heap: 24.0M(254.0M)->22.0M(254.0M)]
[Times: user=0.00 sys=0.00, real=0.01 secs]
2022-07-27T22:11:26.774+0800: 23.914: [GC pause (G1 Evacuation Pause) (young), 0.0039556 secs]
[Parallel Time: 2.7 ms, GC Workers: 10]
[GC Worker Start (ms): Min: 23914.0, Avg: 23914.0, Max: 23914.1, Diff: 0.1]
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.4]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.2, Diff: 0.2, Sum: 0.2]
[Processed Buffers: Min: 0, Avg: 0.2, Max: 1, Diff: 1, Sum: 2]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 2.2, Avg: 2.4, Max: 2.4, Diff: 0.2, Sum: 23.7]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Termination Attempts: Min: 1, Avg: 6.4, Max: 9, Diff: 8, Sum: 64]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.2]
[GC Worker Total (ms): Min: 2.4, Avg: 2.5, Max: 2.6, Diff: 0.2, Sum: 24.7]
[GC Worker End (ms): Min: 23916.5, Avg: 23916.5, Max: 23916.6, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.5 ms]
[Other: 0.8 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.4 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.3 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 13.0M(13.0M)->0.0B(26.0M) Survivors: 3072.0K->2048.0K Heap: 35.0M(254.0M)->34.6M(254.0M)]
[Times: user=0.00 sys=0.00, real=0.00 secs]
·····
2022-07-27T22:13:45.380+0800: 162.520: [GC concurrent-root-region-scan-start]
2022-07-27T22:13:45.380+0800: 162.520: [GC concurrent-root-region-scan-end, 0.0000710 secs]
2022-07-27T22:13:45.380+0800: 162.520: [GC concurrent-mark-start]
2022-07-27T22:13:45.383+0800: 162.523: [GC concurrent-mark-end, 0.0026986 secs]
2022-07-27T22:13:45.383+0800: 162.523: [GC remark 2022-07-27T22:13:45.383+0800: 162.523: [Finalize Marking, 0.0003535 secs] 2022-07-27T22:13:45.383+0800: 162.524: [GC ref-proc, 0.0002325 secs] 2022-07-27T22:13:45.384+0800: 162.524: [Unloading, 0.0003237 secs], 0.0012439 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
2022-07-27T22:13:45.384+0800: 162.524: [GC cleanup 225M->225M(254M), 0.0003145 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
2022-07-27T22:13:53.370+0800: 170.510: [GC pause (G1 Evacuation Pause) (young), 0.0023769 secs]
[Parallel Time: 1.2 ms, GC Workers: 10]
[GC Worker Start (ms): Min: 170509.7, Avg: 170509.7, Max: 170509.8, Diff: 0.1]
[Ext Root Scanning (ms): Min: 0.1, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.9]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.3]
[Processed Buffers: Min: 0, Avg: 0.8, Max: 1, Diff: 1, Sum: 8]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 0.7, Avg: 0.8, Max: 0.8, Diff: 0.1, Sum: 8.0]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 10]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 0.9, Avg: 0.9, Max: 1.0, Diff: 0.1, Sum: 9.4]
[GC Worker End (ms): Min: 170510.7, Avg: 170510.7, Max: 170510.7, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.4 ms]
[Other: 0.7 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.4 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.2 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 10.0M(10.0M)->0.0B(10.0M) Survivors: 2048.0K->2048.0K Heap: 235.2M(254.0M)->235.1M(254.0M)]
[Times: user=0.00 sys=0.00, real=0.00 secs]
G1 的 GC 日志比较复杂,信息也比较多,下面截图了标记阶段的日志:

还有其他类型的 GC 这里也不列举了(日志太多了,不好找)
开始调优
上面讲述了 JVM 的内存模型、各种垃圾收集器和 JDK 自带的一些命令,终于要把这些东西结合在一起开始调优 JVM 了。
JVM 调优的重点
JVM 调优主要注意的是两个点:
- 避免 OOM。
- 减少 Full GC,最好没有 Full GC。
在代码没有问题(不查询一堆数据放内存中、不同时创建很多对象)的情况下,基本上只要能减少 Full_GC,就不会存在 OOM 的情况,所以 JVM 调优的重点在于减少 Full GC。
JVM 运行情况的指标
想要对 JVM 进行调优,首先需要知道 JVM 的运行情况,这就需要我们关注以下几个指标:
- 各个区域的内存大小。
- 年轻代对象的增长速率。
- Young GC 的触发频率和每次耗时。
- 每次 Young GC 后有多少存活的对象进入老年代。
- Full GC 的触发频率和每次耗时。
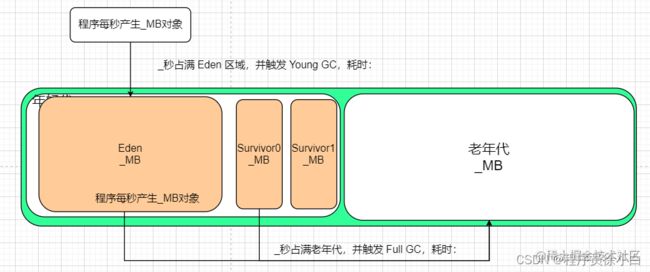
只要把上面的 JVM 运行情况图中的下划线的内容补全(单位自行替换),就能知道 JVM 的运行情况了。
各个区域的内存大小
首先,我们先设置一下 JVM 的参数:
-Xms1024M
-Xmx1024M
-XX:SurvivorRatio=8
-XX:NewRatio=2
-Xss128K
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCCause
-Xloggc:D:\CMSgc-%t.log
-XX:+UseGCLogFileRotation
-XX:GCLogFileSize=100M
-XX:+UseParNewGC
-XX:+UseCMSCompactAtFullCollection
启动程序后,再使用jstat -gccapacity pid就能获取各个区域的内存大小,顺带可以看一下 JVM 的参数。
![]()
参照这些数据就能把各个区域的内存大小填上。
年轻代对象的增长速率
获取剩下的四个指标,需要执行jstat -gc pid获取 JVM 堆的 GC 统计信息。

这是应用程序运行了很久后的堆 GC 统计信息。
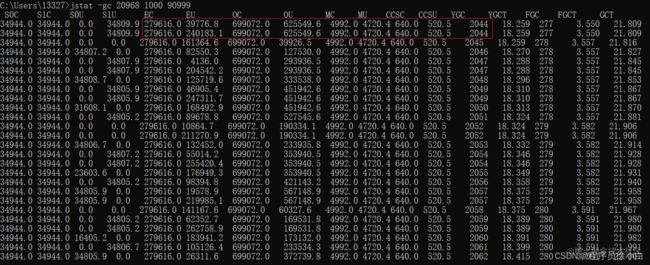
因为 Young GC 太频繁了,所以只看红框中的数据——唯一在两秒内没有 GC 的信息,可以得出每一秒产生了 200407KB ≈ 196MB 的数据。
Young GC 的触发频率和每次耗时

可以看到几乎每一秒都会触发 Young GC,4 秒内触发 3 次 Young GC,可以得出触发频率为 1.33s/GC。
而每次耗时则可以使用 YGCT/YGC 来获取 Young GC 的平均耗时,这里的平均耗时为 YGCT/YGC = 18.415/2062 ≈ 0.0089s。
每次 Young GC 后有多少存活的对象进入老年代
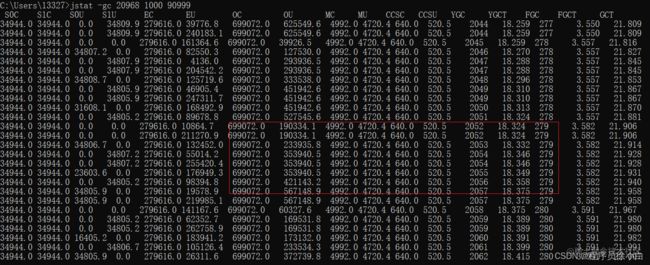
这里截取了 6 次 Young GC,总共进入老年代的内存为 567,148.9KB - 190,334.1KB = 376,814.8KB 约等于 367.98 MB,所以平均每次 Young GC 会向老年代转移 61.33MB 的对象。
Full GC 的触发频率和每次耗时
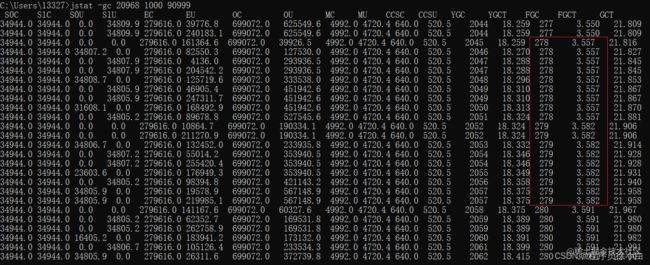
18 秒内触发了 2 次 Full GC,触发频率为 9s/GC,而每次 Full GC 的平均耗时为 FGCT/FGC = 3.591/280 ≈ 0.014s。
于是,我们得到了一幅完整的 JVM 运行情况图:

逐个分析问题出在哪里
是否有老对象或者大对象?
看堆的统计信息,也知道每次 Full GC 后,基本上大多数的对象都被清除了,这也说明这个程序并没有那么多缓存的对象,所以可以排除老对象(达到进入老年代年龄的对象)的情况。
如果你的应用程序中存在很多缓存对象,那就要考虑加大一下服务器的内存了。
至于大对象呢,就要依照对程序很熟悉才能知道了,若真是因为大对象导致了频繁地 Full GC,那就得优化一下代码,或者直接加大服务器内存。
若不是因为老对象或者大对象导致频繁的 Full GC,那就只能往下接着分析了。
是否是触发了动态年龄判断机制?

我们都知道到每次 Young GC 的时候存活的对象都会被存入 Survivor 区,当存活的对象内存大小超过 Survivor 区的一半时就会触发动态年龄判断机制,把符合条件的对象转移到老年代,动态年龄判断机制的概念不重复了。
看之前的堆的 GC 统计信息可能看不出来,这里再截了一张图,就可以看到触发了几次,至于为啥没有每次都触发,可能是因为 JVM 还有其他的判断机制。

既然在年轻代存活的对象太多了(可能是因为它们会被使用一段比较长的时间),那就增加年轻代的大小。
因为每次 Young GC 都会向老年代转移 61.33MB 的对象,所以 Survivor 区域至少得有 123MB 的内存大小。
还有应用程序每秒就产生 196MB 的对象,可见这个应用程序的压力很大,扩容才能从根本上解决问题,否则不可避免会有大量的 GC。
这是扩容的 JVM 参数。
-Xms2048M
-Xmx2048M
-XX:SurvivorRatio=6
-XX:NewRatio=1
-Xss128K
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCCause
-Xloggc:D:\CMSgc-%t.log
-XX:+UseGCLogFileRotation
-XX:GCLogFileSize=100M
-XX:+UseParNewGC
-XX:+UseCMSCompactAtFullCollection
‐XX:+UseConcMarkSweepGC
‐XX:CMSInitiatingOccupancyFraction=92 (增大老年代的可用空间)
‐XX:+UseCMSInitiatingOccupancyOnly
运行后,发现几乎没有再进行 Full GC 了。
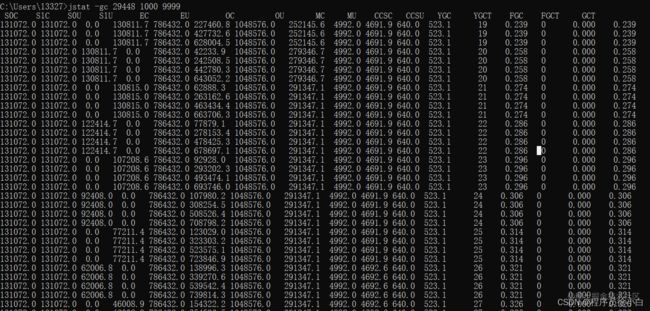
其实这里扩容的话就一下子能够解决了,但是扩容的话这次优化就没有意义了,所以这次优化的目的就改成了在堆内存不变的情况下减少 Full GC。
Survivor 的内存大小改成 128MB,至少得两秒再 Young GC吧,Eden 的内存改成 426MB,那老年代就改成 256MB。
-Xms1024M
-Xmx1024M
-XX:SurvivorRatio=5
-XX:NewSize=682M
-XX:MaxNewSize=682M
-Xss128K
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCCause
-Xloggc:D:\CMSgc-%t.log
-XX:+UseGCLogFileRotation
-XX:GCLogFileSize=100M
-XX:+UseParNewGC
-XX:+UseCMSCompactAtFullCollection
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
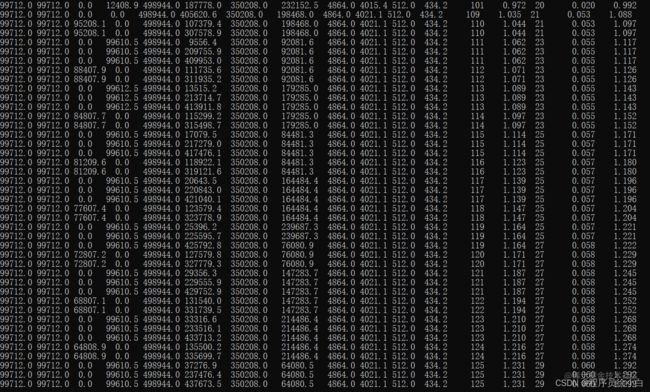
这次调整后还是会出现 Full GC,但频率却下降了很多,但是会出现一次 Young GC 做两次 Full GC 的情况。
Full GC 的触发频率和每次耗时都降低了:
| \ | 触发频率 | 平均耗时 |
|---|---|---|
| 优化前 | 9s/GC | 0.014s |
| 优化前 | 14s/GC | 0.0017s |
Young GC 的频率和平均耗时的变化就不大了。
这次并不是一次完美的 JVM 优化,只为了演示怎么优化触发了动态年龄判断机制的情况,就是直接把年轻代增大,把 Survivor 区域增大即可。
是否触发了老年代空间担保机制?
如果出现 Full GC 比 Young GC 还要多的情况,就要考虑以下几个原因:
- 元空间内存不足,这种情况可能是因为元空间的初始大小设置的太小了,可以设置的和最大的大小一样:
-XX:MetaspaceSize=21M -XX:MaxMetaspaceSize=256M。 - 应用程序代码调用了
System.gc(),这种情况可以给正式环境的 JVM 加上-XX:+DisableExplicitGC来忽视System.gc()这个代码。 - 触发了老年代空间担保机制。
至于是否触发老年代空间担保机制,还记得前面提到的做一次 Young GC 会顺带做两次 Full GC 嘛。
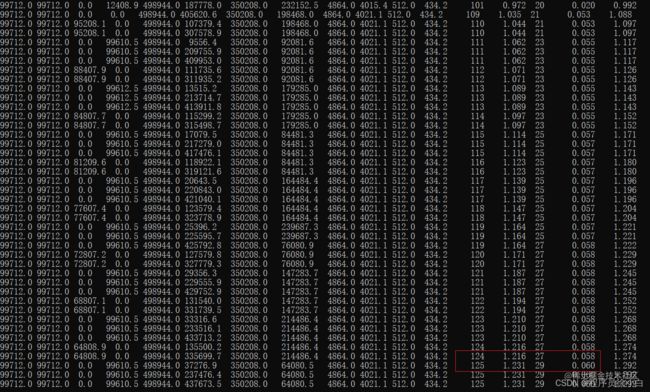
JDK1.8 是默认开启老年代空间担保机制的,而这里做的第一次 Full GC 是在做 Young GC 前,就知道了每次 Young GC 后进入老年代的历史平均大小大于了老年代可用的空间,于是进行了一次 Full GC,而在 Young GC 后,老年代的空间仍然不够用,于是就进行了第二次 Full GC。
对于这种现象,彷佛是关掉老年代空间担保机制就好了,但真正的问题出现是为什么第一次 Full GC 清除不掉垃圾?
很有可能是在第一次 Full GC 时,仍有很多垃圾对象存活着,直到第二次 Full GC 才死掉了,这说明对象从年轻代转移到老年代的频率高、数量大,所以让老年代空间担保机制雪上加霜,造成了一次无用的 Full GC。
所以我们得查看一下,是哪里冒出了这么多垃圾对象,只有解决掉异常的对象创建才能解决这个问题。
找占用内存最多的对象和占用 CPU 最多的线程
可以使用jmap -histo pid来找到异常的对象创建。
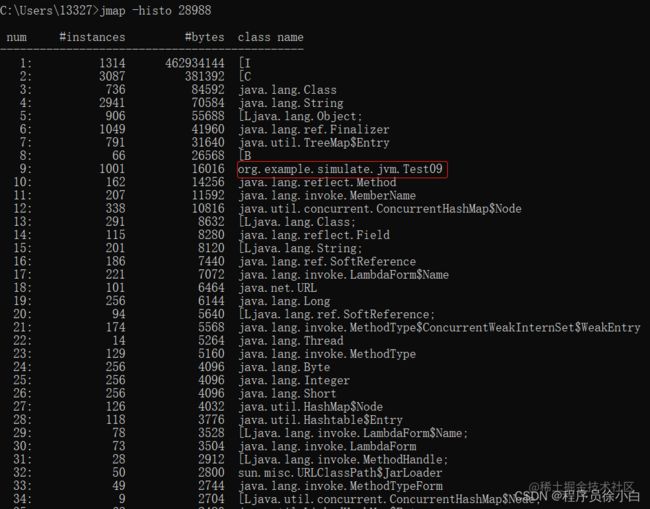
可以看到这里占用最多的是一个 int 数组,但我们通过这个基础数据类型的数组是定位不到问题所在的,我们只需要找我们写过的类即可,这里的org.example.simulate.jvm.Test09一看就是我们写的类,问题可能就出在这里。
如果我们对应用程序的代码足够熟悉,那么就能很快速地检查相关的代码是否有问题,如果相关的代码实在是太多了,那就需要通过jvisualvm工具来查找是那个方法出现了问题。
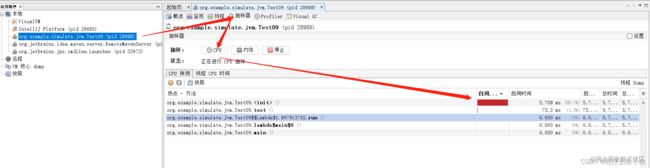
可以看到是 Test09 的构造方法占用了大量的 cpu,我们先分析一下它的构造方法是否真的出现了问题,如果构造方法没有问题,那就查看排名第二的方法是否有问题,依次排除。
当然啦,这里是一段演示的问题代码,就不放出来了,达到演示的目的就行。
最后
至此整个 JVM 调优系列就完成了,感觉写的比较稚嫩,如果后期有 JVM 调优的实战案例,我会再写一篇 JVM 调优实战系列。