第五章:标准I/O(1)
第五章 标准I/O
这一章涉及到C标准库当中的内容,是在Linux操作系统之上进行的封装扩充,牛客Linux的课程没有涉及到,所以认真学
不仅是UNIX,很多其他操作系统都实现了标准I/O库,这个库由ISO C标准进行说明
标准库的I/O处理了很多细节,比如缓冲区分配,以优化的块长度执行I/O等等,在系统调用的基础上使得用户的调用更加的方便和严谨安全;这些处理使得用户不用担心如何正确选择正确的块长度;但是我们也要深入了解以下标准I/O库函数的操作,以及是如何与系统调用联系起来的,否则出了问题不知道怎么办
流和FILE对象
前面提到的I/O都是围绕文件描述符的,我们打开一个文件返回给我们一个文件描述符,然后我们通过对文件描述符对文件进行后续的操作;
但是对于标准I/O,所有的操作都是围绕流(stream)展开的,我们打开一个文件,标准I/O返回我们一个流用于进行和文件的关联
下面我们看一下单字节流和多字节流:
- 对于ASCII字符集,一个字符用一个字节表示。对于国际字符集,一个字符可以用多个字节表示。标准
I/O文件流可用于单字节或多(宽)字节字符集。流的定向决定了所读、写的字符是单字节还是多字节。 - 当一个流最初被创建时,它并没有定向。如若在未定向的流上使用一个多字节
I/O函数,则将该流的定向设置为宽定向的。若在未定向的流上使用一个单字节I/O函数,则将该流的定向设置为字节定向的。 - 只有两个函数可以改变流的定向。
freopen函数清除一个流的定向;fwide函数设置流的定向。
#include 我们写一个程序来加深一下印象:
代码中fopen是标准I/O库提供的打开文件的函数,其中第二个参数表示只读,对应open函数的O_RDONLY,这个后面再说
#include 结果:
返回1,文件刚打开的时候是未定向的流,标志值是0,然后我进行设置之后就返回宽定向的标志值,正数,这里返回了1;
但是第二次我设置未单字节流,为什么还是返回1呢?这表示我们尝试设置不成功,但是程序没有异常终止,这就是这个函数的特性了

从上面我们可以看出,fwide函数没有办法改变已定向流的定向,并且没有出错返回;
如果流无效的时候,我们该怎么办呢?我们可以在调用fwide之前,清除errno,然后执行函数之后检查errno的值,这个倒不算重要
另外,当我们用fopen打开一个文件时,返回给我们一个操作文件的流,这个流包含了I/O管理这个文件的所有信息,包括内核实际上使用的文件描述符,指向该流使用缓冲区(这个缓冲区是用户区的那个)的指针,缓冲区的长度,当前缓冲区的字符数以及出错的标志等等
单字节和多字节
所以说了这么多,我们还是要区分一下单字节和多字节:
- 单字节就是用一个字节就可以表示出所有的字符,也就是8位,也就是可以表示最多256个字符,这一点在英语当中是没有问题的,这也是ASCII字符集使用的字节表示方式
- 但是单字节没有办法统一表示国际上的所有字符,比如不同国家就有自己的字符,汉字也有自己的字符,所以这个时候单字节就显得少了,所以引入了多字节,多字节中又可以分为统一有多少个字节表示的标准和可以由一个或者多个字符表示的标准,但是这不是我们了解的重点;
- 重点是不同的标准下就对文件有了不同的编码,如果我们不使用统一的编码,文件中就很可能会出现乱码,现在普遍使用的编码方式就是
utf-8,就是对应8位,单字节,对应的就是ASCII编码集;像GB2312这些就是多字节编码,我们后面都不考虑,只考虑单字节
标准输入,标准输出和标准错误(流)
与文件描述符的0 1 2类似的,内核对进程预定义了三个流,stdin,stdout和stderr,这三个流就对应了系统调用中的文件描述符STDIN_FILENO,STDOUT_FILENO和STDERR_FILENO
缓冲
标准I/O库提供缓冲的目的就是尽可能少的调用write和read函数,也是对每个I/O流自动进行缓冲管理,而不需要应用程序考虑这一点,可能带来麻烦;
三种类型的缓冲
标准I/O库提供了三种不同的缓冲:
-
全缓冲
在这种情况下,当缓冲区被填满之后才会进行相应的
I/O操作,比如读需要等缓冲区被写满了再去读,写需要等缓冲区被读完了再去写;对于磁盘上的文件通常是由标准I/O库实现全缓冲的;对于一个流,第一次执行I/O操作的时候,通过malloc函数去获得其需要使用的缓冲区当然我们可以手动的冲洗缓冲,冲洗(
flush)这个术语用来说明标准I/O的写操作;缓冲区可以由标准I/O自动冲洗,比如缓冲区被填满的时候;我们也可以手动调用fflush函数冲洗一个流在UNIX中,冲洗有两种意思:在标准
I/O方面,表示将缓冲区的数据写到磁盘中(缓冲区可能是部分填满的),在终端驱动程序方面,flush意味着丢弃存储在缓冲区的数据,这个我们后面再说 -
行缓冲
在这种情况下,在输入和输出遇到换行符的时候,标准库
I/O自动执行相应的I/O操作;当流涉及一个终端的时候,就是标准输入和标准输出,通常对应的就是行缓冲
我们写一个程序来验证:
#includeusing namespace std; int main() { // cout << "hello"; printf("hello"); while (1) ; cout << endl; return 0; } 结果:
可见标准输出对应的是行缓冲,当我把字符串和换行符分开,就没办法及时输出了,遇到换行符就会立即刷新缓冲区

注意:
- 标准库
I/O提供的行缓冲区大小是有限的,所以如果填满了缓冲区,即使没有换行符,也会进行I/O操作(这里有点像上面的行缓冲) - 任何时候通过标准
I/O库从一个不带缓冲的流,或者一个行缓冲的流中得到输入数据,那么系统会冲洗缓冲区输出流进行输出;对于第二个行缓冲,它可能需要从内核中读取数据,也可能不需要,因为数据可能在缓冲区中,但是对于不带缓冲的流肯定需要从内核的缓冲中获得数据
- 标准库
-
不带缓冲
标准
I/O库不对字符进行缓冲存储(内核中还有缓冲),意思是我们希望数据尽快的输入或者输出;例如我们调用fputs函数输出一些字符到不带缓冲的流当中,我们就期望这些数据能够尽快输出,这时候在底层很可能就调用了系统API的write进行后续操作标准错误stderr通常是不带缓冲的,因为错误信息应该尽可能快的显示出来,而不需要管他们有没有换行符
ISO C标准要求缓冲有下列特征:
- 标准输入和标准输入通常是行缓冲的,当且仅当他们不指向交互式设备(例如,键盘,鼠标,显示器等等),才是全缓冲
- 标准错误绝不可能是全缓冲的
但是上面的说法并没有告诉我们,当标准输入和输出指向交互式设备的时候是行缓冲还是不带缓冲;标准错误是行缓冲还是不带缓冲,所以一般来说系统默认使用如下的缓冲:
- 标准输入和标准输出,指向交互式设备的时候是行缓冲(例如在终端屏幕上输出信息),否则就是全缓冲
- 标准错误是不带缓冲的
关于标准I/O缓冲后续会说的更具体
函数setbuf和setvbuf
对于一个流,系统一般会默认给流缓冲的方式,比如标准输入输出使用行缓冲默认定向到终端,如果我们想要修改可以通过如下的函数进行修改
这两个函数的第一个参数都要求传入要给已经打开的流
#include 我们可以用下面这个图进行更详细的总结他们的运作:

我们要知道,虽然我们指定了缓冲区的大小,但是缓冲区中还可能存放着他自己的管理操作信息,所以可以存放在当中的实际字节数要小于缓冲区的大小,这个并不是很重要,因为缓冲区的大小一般都是往上开够用了
一般而言,我们可以让系统自己选择缓冲区的长度,然后自动分配缓冲区,这样关闭流的时候,标准I/O库会自动释放缓冲区
函数fflush
任何时候,我们都可以强制冲洗一个流
这个函数会让所有未写的数据都被送至内核当汇总(内核中也有缓冲区,然后就可以进行后续的操作)
如果传递的是nullptr,那么所有输出流都会被冲洗
#include 例子
全缓冲
我们写一个例子来实际操作一下
在这个程序当中,我将标准输出的缓冲区定向为我设置的outbuf数组,然后分两次puts一些内容;然后刷新,然后再写
#include 结果:
前面三行(包括第三行的空行)经过3秒输出,最后一行又经过3行输出,符合我们的预期
我们可以看出这里的setbuf给我们的是全缓冲

不带缓冲
下面我给一个不带缓冲的例子
#include 结果:
这两行都是执行puts函数之后立即输出的,可以看出不带缓冲

行缓冲
那怎么能少了行缓冲呢?还是全缓冲的例子,我这次设置为行缓冲
#include 结果:
由于puts会自带一个换行符,所以也是立即输出的

打开流
我们可以用以下的函数来打开一个标准I/O流
#include 上面的mode参数是一个字符串类型,用于指定标准I/O流的读写方式,具体如下图,他们和文件状态标志对应:
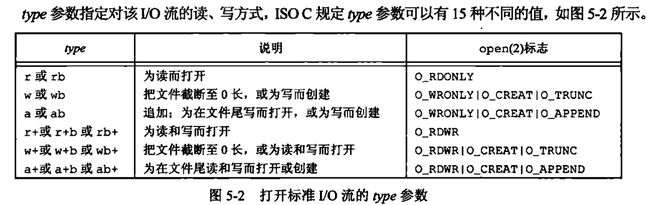
书上还给出了一些注意事项,如下:

例子
打开文件返回标准I/O流的例子就不写了,这里写一个重定向标准输入和标准输出的例子
这里我从文件中读取数据并经过简单计算然后写入另一个文件
注意打开之后需要关闭,这里就是关闭标准输入和输出,注意最好是在程序末尾,不然关闭了之后就没办法正常输入输出了,下面也给出了具体说明
#include 结果:
确实关闭了之后hello没有打印出来
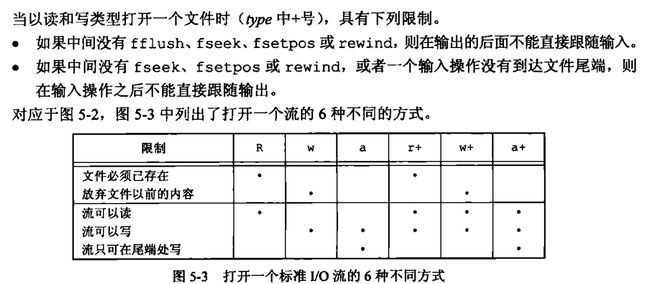
其他注意事项(了解)
我就放书上的图了

函数fclose
我们可以用flose函数来关闭一个打开的流,这也是为什么前面关闭之后就没办法打印到终端了
#include 注意:
- 在文件关闭之前,系统会自动冲洗输出缓冲中的所有数据,然后进行输出;输入缓冲区中的所有数据将被丢弃
- 如果标准I/O库已经为该流自动分配了一个缓冲区,那么系统会自动释放该缓冲区
- 同样当一个进程终止或者结束的时候,也会自动冲洗输出缓冲中的所有数据,输入缓冲区的数据会被丢弃;所有打开的标准I/O流都会被关闭
读和写流
一旦打开了流,我们有三种不同的方式的非格式化I/O进行选择,然后进行读写操作:
- 每次一个字符的
I/O,意思是一次读写一个字符;如果流是带缓冲的,那么标准I/O会处理缓冲 - 每次一行的
I/O,我们可以借助标准I/O函数fgets和fputs来实现,每行都以一个换行符终止 - 直接
I/O,每次I/O操作的时候读或者写指定的对象,这个对象具有一定的长度;比如fread函数和fwrite函数,他们可以让底层的read和write函数调用次数更少,因此执行效率更高
输入函数
getc系列
以下的函数可以用于一次读一个字符
#include 所以和read函数类似的,我们要检验读取到文件末尾,但是这里不同的是当读取到文件末尾或者发生错误的时候这三个函数都返回相同的值,都是EOF,所以我们要想办法区分
函数ferror和feof
这两个函数就是用来检测到底是发生错误还是读取到末尾了;
标准I/O为每个FILE对象维护了两个标志,也就是出错标志和文件末尾标志,他们就可以分别被下面的ferror和feof来获得,这样我们就可以判断到底是什么状况
#include 例子
我们写一个程序来实操一下
我们做两次测试,一次正常读完,一次读取出错,如下所示:
#include 结果:
正常读完

读取错误

函数ungetc
当从流当中读取数据之后,我们可以调用ungetc把字符压回流当中
这里我准备从一个文件当中读取数据,然后读取之前我压入了一些字符到流中
#include 结果:
我压入的顺序是a到j,但是输出的顺序是j到a,可以压入和输出的关系是一个栈的关系,这一点注意一下

注意:
- 我们不能回送
EOF,因为下一次就读到他表示错误或者文件结束,但是其实并没有,就会出问题 - 当读取到文件末尾的时候,我们可以回送一个字符,这样下次就会读取这个字符,再次读就会返回
EOF,之所以能这样做是一次成功的ungetc会调用clearerr函数清除两个标志,因为压入之后这两个标志应该会不存在
输出函数
对应上面的输入函数,也有一个输出函数,就是一次输出一个字符到输出缓冲区
#include putc函数和ungetc函数都可以向流中写数据,putc一次写一个字符到输出流缓冲区中,ungetc和他的区别大了,他是往读取缓冲区写,这样读的时候就会先读取我写的数据,注意如果不加设置为不带缓冲他们会先写到缓冲区当中
例子
我们用一个程序深刻理解上面的意思
这里我打开一个文件用读和追加的方式打开,然后向文件中写数据,我人为指定为全缓冲,由系统给我分配,然后写完我休眠几秒,然后再读取,我们看一下程序的结果
#include 结果:
程序睡了5秒之后才输出,这也证明了是数据是先到缓冲区当中了,然后后面调用了fseek或者getc函数刷新了缓冲区,因此就能正常读到数据,注意这里putc和getc使用的都是系统给我分配的全缓冲,我们在两次操作之间缓冲区被冲洗了;最后输出到终端上用的标准输出的行缓冲,这个与上面无关

每行一行I/O
每次输入一行(fgets系列)
下面的函数提供了每次输入一行的功能
#include 注意:
-
注意这里
buf是我们存储数据的地方,不是缓冲区,就像read函数需要buf来存放数据一样,缓冲区需要我们指定大小,就是n,如果我们没用setvbuf设置缓冲区的属性,那么默认就由系统给我们分配,然后程序结束系统给我们回收(这里要理解好) -
对于
fgets,我们必须指定缓冲区的长度,这个函数直到读到下一个换行符为止,由于字符串的末尾有一个'\0'符号,所以我们实际上只能读取到n-1个字符,这也是标准I/O为我们提供的保护;但是如果该行包括最后一个换行符超出了n-1个字符,则fgets只返回一个不正常的行,但是缓冲区只以null字节结尾,下一次的调用会从这里继续 -
我们不推荐使用
gets函数,因为他没有手动指定缓冲区的大小,这就可能造成缓冲区溢出,然后导致内存泄漏,这一点的危害是致命的,所以我们不推荐,而且它也很局限,只能从标准输入中读取
例子
#include 结果:
程序睡了五秒之后然后输出,为什么只有4个字符?因为缓冲区满了,但是他会留出末尾一个’\0’符号,然后送到存储位置buf中,然后由于标准输出是行缓冲,没有换行符,所以就睡了五秒再输出
![]()
每次输出一行(fputs系列)
#include 例子
#include 结果:
程序睡了3秒输出,因为标准输出是行缓冲,fputs函数输出的字符串不带回车符,puts带有

二进制I/O
上面的函数以一次一个字符或者一次一行进行操作,如果我们进行二进制I/O操作,那么我们更愿意一次读写一个完整的结构
- 如果使用
getc和putc函数,那么我们一次只能读或者写一个字符,必须通过循环进行整个结构的读写; - 如果使用
fputs和fgets函数,fgets函数遇到换行符’\n’或者缓冲区满或者遇到null字节会停止,fputs函数遇到null字节就会停止,这样想要读完也要循环,也是相对比较麻烦的
因此类似于系统调用的read和write函数,我们这里有两个二进制I/O操作可以读取一个完整的结构
#include 这两个函数的作用在下面给出:
-
有两种常见的用法:
-
读或者写一个二进制数组

-
读或者写一个结构

这两种用法其实有相同的地方,第一个参数传入的是想要读或者写入的结构单位,第二个参数传入的是这个单位的大小,第三个参数传入的是想要读或者写的个数,第四个参数给定的是指定的流,当然首先是读入或者写入缓冲区,后面根据情况判断什么时候才会到达目标位置
-
-
这两个函数返回读或者写的对象个数
- 对于读,如果出错或者到达文件末尾,返回的值不为
count,这个时候可以用ferror或者feof来判断是哪一种情况 - 对于写,如果返回的值不为
count,那么就是出错了
- 对于读,如果出错或者到达文件末尾,返回的值不为
例子
第一个例子,我们把一些二进制数据和结构进行标准输出
#include 结果:
字符串是可以正常输出的,其他类型的数据可能因为编码或者类型问题会出现乱码,但是我们一般都是处理字符串,所以问题不大

第二个例子,我们从文件当中读取数据,然后输出,注意体会第二个参数size和第三个参数count的含义
#include 结果:
我们读取和写出的单位都是字符,所以size给的是1,读取的时候不知道stream数据到底有多少,所以我们给大一点,可以给buf数据区的大小,所以返回值不为count有可能是读到末尾或者失败;写的时候就给buf的实际长度。
注意,buf可不是file_stream的读写缓冲区,buf是我们指定的存储数据的地方,从写之后strlen(buf)不为0这一点也可以看出来
注意fread,fwrite函数和read,write函数的联系和区别,他们的使用方式还是有区别的
定位流
有三种方法定位I/O流,如下图:

我们了解下面的函数即可:
#include 还有两个函数,他们除了类型和前面的函数不一样之外,是off_t,其他相同,但是我们还是倾向于用上面的函数:
#include 例子
#include 注意里面第二次fread的注释,为什么会被覆盖
结果:
显然在我们的预期内

格式化I/O
格式化输出
printf系列
格式化I/O是通过printf系列函数来处理的
#include 格式化标准
这显然就涉及到格式化的标准了,当然这里需要我们自己进行对数据进行合适的格式化处理
这些标志其中括号里面是可选的,convtype是不可选的,如下图:



vprintf函数(了解)

格式化输入
scanf系列
以下几个函数用作格式化输入
#include 这几个函数返回值我们可以不用判断,判断了也没有什么作用,所以只提一嘴:返回赋值的输入项数,若输入出错或者在任一转换之前已经到达文件末端,则返回EOF
格式化标准
同前面,截图:


vscanf系列(了解)

