【项目】#防翟天临老师翻车神器# ——实现文本查重

最近找实习的事基本上算是凉了,时间终于没那么紧迫了,学了点QT的皮毛给这个小工具搞了个简单的界面
不准说丑!!!!!!!! 2019-5-18
#############################################################################
最近的热点事件翟天临论文抄袭闹得社交网络沸沸扬扬,作为在学校生活的广大同学们肯定对于论文查重是都是有所耳闻的,为了不要像翟老师那样翻车,大家总会特别在意所谓的重复率,那么论文查重的功能到底是如何实现的呢?
这里我们将文本查重功能实现的程序分为四个步骤
- 文本分词
- 词频统计
- 构成词频向量
- 计算重复率
贴一下整体的代码 https://github.com/GreenDaySky/Function-text-rechecking(这里没有把jieba的工具包贴上来)
文本分词
文章都是以句子构成的,而句子是由许许多多的词构成的,所以其实查重机制的根本应当是根据词语进行的。
那我们就要思考一下如何进行从句子中提取词语完成分词操作了
这里贴一篇对于分词的介绍:https://www.cnblogs.com/BaiYiShaoNian/p/5071802.html
分词操作必然是和庞大的词库有关的,所以我们自己是无法完成的,需要借助工具来实现
这里我使用了jieba自然语言处理这个分词工具进行分词操作
首先我就遇到了一个问题,我下载的jieba分词工具基于Linux系统的UTF8的编码方式,而windows系统的编码方式是GBK类型的,每次使用时必须要进行转换,由于GBK和UTF8直接没有直接的映射关系,这里用UTF16作为中间量进行转换,UTF8和GBK为多字节,UTF16为宽字节
MultiByteToWideChar()为多字节转宽字节函数
https://docs.microsoft.com/en-us/windows/desktop/api/stringapiset/nf-stringapiset-multibytetowidechar
WideCharToMultiByte()为宽字节转多字节函数
https://docs.microsoft.com/en-us/windows/desktop/api/stringapiset/nf-stringapiset-widechartomultibyte
string TextSimilarity::UTF8toGBK(string s)
{
int len1 = MultiByteToWideChar(CP_UTF8, 0, s.c_str(), -1, 0, 0);
WCHAR* str1 = new WCHAR[len1];
len1 = MultiByteToWideChar(CP_UTF8, 0, s.c_str(), -1, str1, len1);
if (len1 <= 0)cout << "转码失败";
int len2 = WideCharToMultiByte(CP_ACP, 0, str1, -1, NULL, 0, NULL, FALSE);
CHAR* str2 = new CHAR[len2];
len2 = WideCharToMultiByte(CP_ACP, 0, str1, -1, str2, len2, NULL, FALSE);
if (len2 <= 0)cout << "转码失败";
string OutString(str2);
if (str1)
{
delete[] str1;
str1 = NULL;
}
if (str2)
{
delete[] str2;
str2 = NULL;
}
return OutString;
}
string TextSimilarity::GBKtoUTF8(string s)
{
int len1 = MultiByteToWideChar(CP_ACP, 0, s.c_str(), -1, 0, 0);
WCHAR* str1 = new WCHAR[len1];
len1 = MultiByteToWideChar(CP_ACP, 0, s.c_str(), -1, str1, len1);
if (len1 <= 0)cout << "转码失败";
int len2 = WideCharToMultiByte(CP_UTF8, 0, str1, -1, NULL, 0, NULL, FALSE);
CHAR* str2 = new CHAR[len2];
len2 = WideCharToMultiByte(CP_UTF8, 0, str1, -1, str2, len2, NULL, FALSE);
if (len2 <= 0)cout << "转码失败";
string OutString(str2);
if (str1)
{
delete[] str1;
str1 = NULL;
}
if (str2)
{
delete[] str2;
str2 = NULL;
}
return OutString;
}
解决了这个问题之后我们就可以进行调用jieba工具进行分词操作了,这里使用了jieba工具中的Cut函数进行分词
分词完成后我们又会遇到一个小问题,我们句子当中如果所有的被分好的词都被用来进行统计处理,出现最多的词会是什么?大概率是各种代词介词,所谓为了避免这些无用词的被记录我们要将这些个停用词删除掉,停用词就是一个句子当中那些没有实际意义的介词或者我你他这类的代词,我们要调用一个停用词库将分好的词与其进行对比,如果属于停用词就删掉它
词频统计
做完之前的操作我们剩下来的词就是有统计意义的词语了,接下来我们使用unordered_map进行词频统计
typedef std::unordered_map wordFreq;
typedef std::unordered_set wordSet;
cppjieba::Jieba _jieba;
wordSet _stopWordSet; TextSimilarity::wordFreq TextSimilarity::getWordFreq(const char* filename)
{
ifstream fin(filename);
if (!fin.is_open())
{
cout << "open file:" << filename << "failed";
return wordFreq();
}
string line;
wordFreq wf;
while (!fin.eof())
{
getline(fin, line);
// GBK--> UTF8
line = GBKtoUTF8(line);
vector words;
//对文本进行分词
_jieba.Cut(line, words, true);
//统计词频
for (const auto& e : words)
{
//去掉停用词
if (_stopWordSet.count(e) > 0)
continue;
//统计词频
else
{
if (wf.count(e) > 0)
wf[e]++;
else
wf[e] = 1;
}
}
}
return wf;
} 统计词频结束之后,我们要拿前N个词进行对比,如果是由全词对比显得事倍功半,这时需要一个排序功能的函数
bool cmpReverse(pair lp, pair rp)
{
return lp.second > rp.second;
}
vector> TextSimilarity::sortByValueReverse(TextSimilarity::wordFreq& wf)
{
//unordered_map
//map是kv结构的无法直接使用sort进行排序
//sort只支持序列容器
vector> wfvector(wf.begin(), wf.end());
sort(wfvector.begin(), wfvector.end(), cmpReverse);
return wfvector;
} 使用vector记录排序结果,并将候选词存到天然去重的unorder_set中
void TextSimilarity::selectAimWords(std::vector>& wfvec, wordSet& wset)
{
int len = wfvec.size();
int sz = len > _maxWordNumber ? _maxWordNumber : len;
for (int i = 0; i < sz; i++)
{
//pair
wset.insert(wfvec[i].first);
}
} 构建词频向量
vector TextSimilarity::getVectorQuantity(TextSimilarity::wordSet& wset, TextSimilarity::wordFreq& wf)
{
//遍历wordSet中的每一个词
vector VectorQuantity;
for (const auto& e : wset)
{
if (wf.count(e))
//VectorQuantity(value)
VectorQuantity.push_back(wf[e]);
else
VectorQuantity.push_back(0);
}
return VectorQuantity;
} 计算重复率
在进行文本查重操作的时候只需要获取用两个文本每一个的前N个高频词的和构建词频向量,然后对比向量之间的差异就能大致获取所谓的重复率
计算向量相似度的方法有许多:欧几里得距离,余弦相似度,jaccard系数,曼哈顿距离
这里我采用了易于实现的余弦相似度进行计算
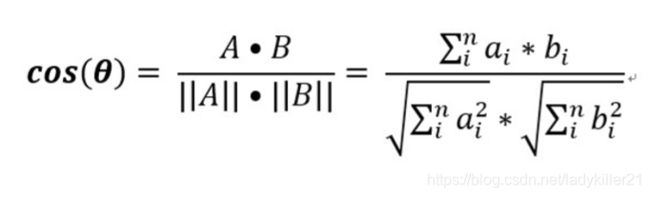
double TextSimilarity::cosine(std::vector VectorQuantity1, std::vector VectorQuantity2)
{
double modular1 = 0, modular2 = 0;
double products = 0;
assert(VectorQuantity1.size() == VectorQuantity2.size());
for (int i = 0; i < VectorQuantity1.size(); i++)
{
//点积
products += VectorQuantity1[i] * VectorQuantity2[i];
}
for (int i = 0; i