hadoop抽象文件系统filesystem框架介绍
为了提供对不同数据访问的一致接口,Hadoop借鉴了Linux虚拟文件系统的概念,引入了Hadoop抽象文件系统,并在Hadoop抽象文件系统的基础上,提供了大量的具体文件系统的实现,满足构建于Hadoop上应用的各种数据访问需求。
通过Hadoop抽象文件系统,MapReduce目前可以运行在基于HDFS的集群上,也可以运行在基于Amazon S3的云计算环境里。
Hadoop文件系统API
java.io.FileSystem是java.io包的私有抽象类,不能被包以外的类引用。也就是说,不能像类似UnixFileSystemWin32FileSystem那样,通过继承java.io.FileSystem,实现一个和Java文件系统兼容的,又能访问如HDFS的子类。
为了解决这个问题,Hadoop特别提供了一个抽象的文件系统,HDFS只是这个抽象文件系统的一个具体实现。Hadoop文件系统抽象类是org.apache.hadoop.fs.FileSystem。
与Linux和Java文件API类似,Hadoop抽象文件系统的方法可以分为两部分:一部分用于处理文件和目录的相关事务;另一部分用于读写文件数据。下表总结了Hadoop抽象文件系统的文件操作与Java、Linux的对应关系。
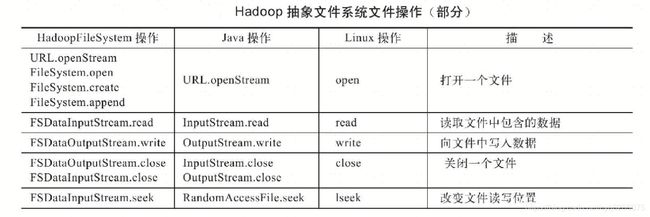
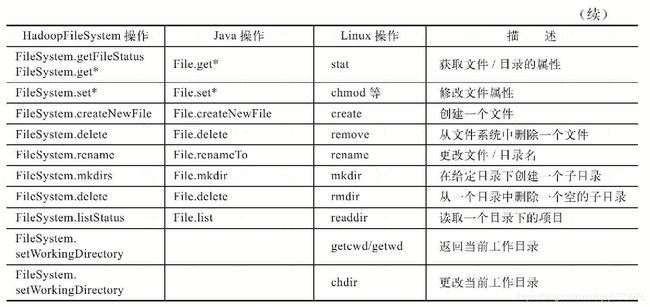
通过上表对比可以发现,在处理文件和目录相关事务方面,Hadoop抽象文件系统和Java文件API有大量相似之处,如删除文件、文件改名、创建子目录等。不同之处是调用的格式有所不同。 org. apache.hadoop.fs.Path是一个很简单的类,它在java.net.URI的基础上抽象了文件系统中的路径。需要注意的是,Java中没有对应的Path类。但是,在Java中,java.io.File提供了toURL()方法,用于获得对应的使用file模式的URL。而从一个使用file模式的URL对象,可以通过URLDecoder.decode()构造对应的File对象。但是,Java的File类和URL类分别抽象了不同的事物,它们都具有各自的不同的内部状态和行为。
这一部分的API中,Hadoop FileSystem和Java文件API比较大的差别,是获取文件或目录属性的方法。通过FileSystem.getFileStatus()方法,Hadoop抽象文件系统可以一次获得文件/目录的所有属性,这些属性被保存在类FileStatus中,如图所示。

通过FileStatus可以获得的信息包括:文件路径path、文件长度length、是否是目录isdir、副本数block_replication(这是为了HDFS而准备的特殊参数)、块大小blocksize(为了HDFS准备的特殊参数)、最后修改时间modification_time、最后访问时间access_time、许可信息permission、文件所有者owner、用户组group。具体代码如下:
public class FileStatus implements Writable, Comparable{
private Path path;
private long length;
private boolean isdir;
private short block_replication;
private long blocksize;
private long modification_time;
private long access_time;
private FsPermission permission;
private String owner;
private String group;
……
}
FileStatus实现了Writable接口,这就是说,FileStatus可以被序列化后在网络上传输。同时,一次性将文件的所有属性读出并返回到客户端,可以减少在分布式系统中进行网络传输的次数,应该说,这是一个相当有针对性的设计。
FileSystem自有方法
出现在FileSystem中但在Java文件API中找不到对应的方法有getContentSummary()、setReplication()和getReplication(),其声明如下:
public boolean setReplication(String src, short replication)throws IOException;
……
@Deprecated
public short getReplication(Path src)throws IOException
……
public ContentSummary getContentSummary(String path)throws IOException;
FileSystem. getContentSummary()提供了类似Linux命令du、df提供的功能。du表示"disk usage",它会报告特定的文件和每个子目录所使用的磁盘空间大小;命令df则是"diskfree"的缩写,用于显示文件系统上已用的和可用的磁盘空间的大小。du、df是Linux中查看磁盘和文件系统状态的重要工具。
getContentSummary()方法的输入是一个文件或目录的路径,输出是该文件或目录的一些存储空间信息,这些信息定义在ContentSummary,包括文件大小、文件数、目录数、文件配额,已使用空间和已使用文件配额等。
getContentSummary()方法不是FileSystem的抽象方法,它可以在getFileStatus()的基础上,计算出ContentSummary中包含的信息。
setReplication()方法用于设置文件系统上的文件副本数,getReplication()方法则可获得文件的副本数。这是两个有HDFS特色的方法。
FileSystem自定义方法
实现一个Hadoop具体文件系统,需要实现哪些功能呢?下面整理了org.apache.hadoop.fs.FileSystem中的抽象方法:
//获得文件系统URI
public abstract URI getUri();
//为读打开一个文件,并返回一个输入流,下一节讨论
public abstract FSDataInputStream open(Path f, int bufferSize)throws IOException;
//创建一个文件,并返回一个输出流,下一节讨论
public abstract FSDataOutputStream create(Path f,FsPermission permission,boolean overwrite,
int bufferSize,short replication,long blockSize,Progressable progress)throws IOException;
//在一个已经存在的文件中追加数据
public abstract FSDataOutputStream append(Path f, int bufferSize,Progressable progress)throws IOException;
//修改文件名或目录名
public abstract boolean rename(Path src, Path dst)throws IOException;
//删除文件
public abstract boolean delete(Path f)throws IOException;
public abstract boolean delete(Path f, boolean recursive)throws IOException;
//如果Path是一个目录,读取一个目录下的所有项目和项目属性;
//如果Path是一个文件,获取文件属性
public abstract FileStatus[]listStatus(Path f)throws IOException;
//设置当前的工作目录
public abstract void setWorkingDirectory(Path new_dir);
//获取当前的工作目录
public abstract Path getWorkingDirectory();
//如果Path是一个文件,获取文件属性
public abstract boolean mkdirs(Path f, FsPermission permission)throws IOException;
//获取文件或目录的属性
public abstract FileStatus getFileStatus(Path f)throws IOException;
上述抽象方法基本覆盖了表中用于处理文件和目录相关事务的主要操作,实现一个具体的文件系统,至少需要实现上面这些抽象方法。另一方面,Hadoop抽象文件系统基于以上方法,提供了一些工具方法,以方便用户调用。如listStatus()方法。
Hadoop输入/输出流
和Java文件系统类似,Hadoop抽象文件系统也是使用流机制进行文件的读写。Hadoop抽象文件系统中,用于读文件数据的流是FSDataInputStream,它是一个抽象类,对应地,写文件通过抽象类FSDataOutputStream实现。
1.FSDataInputStream
输入流FSDataInputStream通过FileSystem.open()方法打开,输出流FSDataOutputStream可以通过创建文件的FileSystem.create()打开,或通过在已有文件后添加数据的FileSystem.append()打开。
FSDataInputStream的类继承了DataInputStream类,并实现了Seekable、PositionedReadable和java.io.Closeable接口。其中,DataInputStream前面已经讨论过,它提供了读取Java基本类型的方法族。
Seekable接口提供在(文件)流中进行随机存取的方法,其功能类似于RandomAccessFile中的getFilePointer()方法(Seekable.getPos()方法)和seek()方法,它提供了某种随机定位文件读取位置的能力。
Seekable接口中的seekToNewSource()是一个比较特殊的方法,当文件数据有多个副本的时候,如在HDFS中,seekToNewSource()可用于重新选择一个副本。代码如下:
/**接口,用于支持在流中定位*/
public interface Seekable{
//将当前偏移量设置到参数位置,下次读数据将从该位置开始
void seek(long pos)throws IOException;
//得到当前偏移量
long getPos()throws IOException;
//重新选择一个副本
boolean seekToNewSource(long targetPos)throws IOException;
}
FSDataInputStream实现的另一个接口是PositionedReadable,它提供了从流中某一个位置开始读数据的一系列方法,这些方法的第一个参数position,用于指定流中的一个位置。其中,read()和readFully()的差别在于:一个试图读取指定长度的数据,另一个读取指定长度的数据,直到读满缓冲区或流结束。接口如下:
//接口,用于在流中进行定位读
public interface PositionedReadable{
//从指定位置开始,读最多指定长度的数据到buffer中offset开始的缓冲区中
//注意,该函数不改变读流的当前位置,同时,它是线程安全的
public int read(long position, byte[]buffer, int offset, int length)throws IOException;
//从指定位置开始,读指定长度的数据到buffer中offset开始的缓冲区中
public void readFully(long position, byte[]buffer, int offset,int length)throws IOException;
public void readFully(long position, byte[]buffer)throws IOException;
}
如果流已经实现了Seekable接口,还需要实现PositionedReadable接口吗?答案是肯定的,注意,PositionedReadable中的3个读方法,都不会改变流的当前位置,而且还是线程安全的。当然,你可以通过一些同步机制,通过Seekable接口实现PositionedReadable接口中的方法。
2.FSInputStream
在org.apache.hadoop.fs包中,还包括了抽象类FSInputStream。Seekable接口和PositionedReadable中的方法都成为这个类的抽象方法。
在FSInputStream类中,通过Seekable接口的seek()方法实现了PositionedReadable接口中的read()方法。过程很简单,在进行该read()操作前,利用Seekable.getPos()保存当前读的位置,然后,调用Seekable.seek()设置读位置position并通过InputStream .read()读取数据,读取完数据后,再次调用Seekable.seek()恢复InputStream.read()前的位置。
FSInputStream有10多个子类,它们都是具体文件系统实现的具体输入流,如用于读取HDFS文件的org.apache.hadoop.hdfs.DFSInputStream。
注意 Hadoop中并没有和FSInputStream对应的FSOutputStream。这部分的Hadoop代码不是很一致。
3.FSDataOutputStream
FSDataOutputStream用于写数据,和FSDataInputStream类似,它继承自DataOutputStream,提供writeInt()和writeChar()等方法。类结构如图所示。
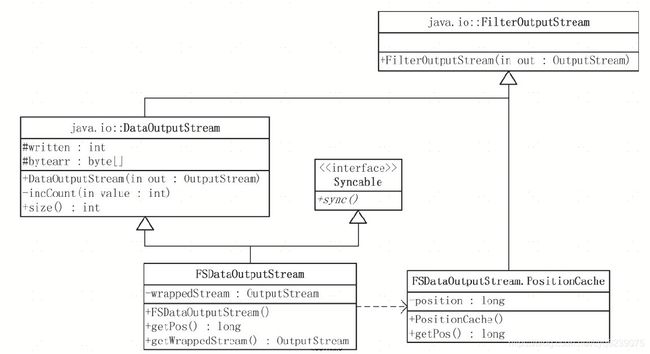
相对于FSDataInputStream, FSDataOutputStream比较简单,它没有实现Seekable接口,也就是说,Hadoop文件系统不支持随机写,用户不能在文件中重新定位写位置,并通过写数据来覆盖文件原有的内容。但用户可以通过getPos()方法获得当前流的写位置,为了实现getPos()方法,FSDataOutputStream定义了内部类PositionCache,该类继承自FilterOutputStream,并通过重载write()方法跟踪目前流的写位置。
PositionCache是一个典型的过滤器流,在基础的流功能上添加了getPos()方法,同时,利用FileSystem.Statistics实现了文件系统读写的一些统计。而FSDataOutputStream的构造函数也很干脆,直接生成PositionCache对象并调用父类构造方法。代码如下:
public class FSDataOutputStream extends DataOutputStream
implements Syncable{
private OutputStream wrappedStream;
private static class PositionCache extends FilterOutputStream{
private FileSystem.Statistics statistics;
long position;//当前流的写位置
public PositionCache(OutputStream out,
FileSystem.Statistics stats,
long pos)throws IOException{
super(out);
statistics=stats;
position=pos;
}
public void write(int b)throws IOException{
out.write(b);
position++;//更新当前位置
if(statistics!=null){
statistics.incrementBytesWritten(1);//更新文件统计值
}
}
……
public long getPos()throws IOException{
return position;//返回当前流的写位置
}
……
}
……
public FSDataOutputStream(OutputStream out,…….Statistics stats,
long startPosition)throws IOException{
super(new PositionCache(out, stats, startPosition));
wrappedStream=out;
}
……
}
FSDataOutputStream实现了Syncable接口,该接口只有一个函数sync(),其目的和Linux中系统调用sync()类似,用于将流中保存的数据同步到设备中。
需要注意FSDataInputStream继承的DataInputStream,和FSDataOutputStream继承的DataOutputStream,都只是对其他流进行增强。通过对FSDataInputStream和FSDataOutputStream构造函数的分析也可以发现,它们需要依赖于具体的、能够接收或发送数据的流来构造相应的对象。传递给这些构造函数的输入/输出流,一般由具体的文件系统实现来提供。代码如下:
public FSDataInputStream(InputStream in)
public FSDataOutputStream(OutputStream out)
public FSDataOutputStream(OutputStream out,FileSystem.Statistics stats)
public FSDataOutputStream(OutputStream out,FileSystem.Statistics stats,long startPosition)
Hadoop文件系统中的权限
Hadoop分布式文件系统实现了一个和Linux系统类似的权限模型。
每个文件和目录都有一个所有者(owner)和一个组(group),在FileStatus类中,可以通过getOwner()和getGroup()获得相应的属性。
图中给出了Hadoop文件系统中与权限相关的类。
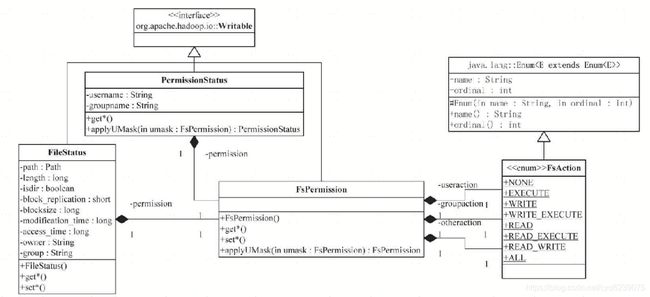
用户身份机制对Hadoop文件系统来说只是外部特性。目前,Hadoop并不提供创建用户身份、用户组或处理用户凭证等功能。也正是这个原因,图中,FileStatus类使用了字符串owner和group,保存了文件所有者和文件所在用户组的信息,代码如下:
public class FileStatus implements Writable, Comparable{
……
private FsPermission permission;
private String owner;//文件所有者
private String group;//文件所在用户组
……
}
而在Linux系统中,文件或目录元信息通过整型的用户ID和组ID,保存文件所有者和文件所在用户组。Linux系统的实现方式比较节省存储空间,但需要增加用户ID到用户名、组ID到组的映射关系,并提供命令维护该关系。
FsPermission保存了FileStatus对应文件的权限,也是采用Linux的表示和显示习惯,包括使用八进制数来表示权限。当新建一个文件或目录时,它的所有者是客户进程的用户,它所属组是父目录的组。文件或目录的文件所有者、文件组和其他用户的权限信息,可以保存在FsPermission对象中。应该说,FsPermission是一个简单的包装类,PermissionStatus则在FsPermission的基础上包含了文件的文件所有者和文件所在用户组的信息,其实现也很简单。
和Linux系统一样,文件或目录对其所有者、同组的其他用户以及所有其他用户可以分别有着不同的读、写和执行权限,也就是前面讨论的rwx权限。在Hadoop中,rwx权限通过枚举FsAction定义。通过enum关键字,用户可以方便地定义一个常量集合。对于枚举类型,Java内部将其转换为java.lang.Enum的子类(如上图所示),并提供了一些方法。其中,成员变量ordinal用于返回枚举常量的序数,也就是它在枚举声明中的位置,初始常量序数为0。FsAction中权限常量的定义利用了枚举常量序数,如FsAction.NONE,它是这个枚举类型的第一个枚举值,它的序数为0,正好也是对应Linux形式权限的表示000,而WRITE_EXECUTE,其表示为011,序数为3。
FsAction还提供了implies()方法,用于判断权限1是否隐含权限2,如权限FsAction.WRITE_EXECUTE隐含了权限FsAction.WRITE和FsAction.EXECUTE,但不隐含权限FsAction.READ_EXECUTE。利用这些权限的枚举常量序数,可以很容易实现implies()方法。FsAction类的主要代码如下:
public enum FsAction{
//POSIX风格的权限
NONE(“--”),
EXECUTE("-x"),
WRITE("w-"),
WRITE_EXECUTE("wx"),
READ("r--"),
READ_EXECUTE("r-x"),
READ_WRITE("rw-"),
ALL("rwx");
……
public boolean implies(FsAction that){
if(that!=null){
return(ordinal()&that.ordinal())==that.ordinal();
}
return false;
}
}
抽象文件系统中的静态方法
org. apache.hadoop.fs.FileSystem中提供的一系列抽象方法定义了Hadoop抽象文件系统的系统界面,即一个文件系统需要提供的服务。FileSystem中还有另外一类值得研究的方法,这些方法都是静态方法,它们提供了获得具体文件系统的实例,或者关闭文件系统等重要方法;也提供如create()打开文件、mkdir()创建目录等工具方法;文件系统的一些统计数据,如文件读操作数、读字节数、写操作数、写字节数,也是通过静态方法提供的。
FileSystem中获得具体文件系统主要通过get()方法,它有多种重载形式,下面是一个例子(在org.hadoopinternal.fs.RamFileSystemDemo的main()方法中):
……
URI uri=URI.create("ramfs://demo");
Configuration conf=new Configuration();
InMemoryFileSystem inMemFs
=(InMemoryFileSystem)FileSystem.get(uri, conf);
……
实际上,get()是典型的工厂模式实现,用于创建多种“产品”,在FileSystem中,这些产品就是具体的文件系统,如Hadoop分布式文件系统、内存文件系统等。以上述代码为例,get()方法需要一个URI,文件系统根据这个URI的模式"ramfs",了解到用户需要打开一个内存文件系统,则创建或返回对应的文件系统。getLocal()用于获取本地文件系统,是get()的一个工具方法,用法类似于get()。下面的代码来自org.hadoopinternal.fs.LocalFileSystemDemo:
……
Configuration conf=new Configuration();
LocalFileSystem localFs=FileSystem.getLocal(conf);
有了get()方法,getLocal()的实现非常简单,其中,常量LocalFileSystem.NAME的值是"file:///":
public static LocalFileSystem getLocal(Configuration conf)throws IOException{
return(LocalFileSystem)get(LocalFileSystem.NAME, conf);
}
几种形式的FileSystem.get()最终调用下面的get()方法,它的输入参数包括要打开文件系统的URI和打开时使用的配置:
public static FileSystem get(URI uri, Configuration conf)throws IOException
{
String scheme=uri.getScheme();//获得URI模式
String authority=uri.getAuthority();//鉴权信息
if(scheme==null){//URI模式为空,返回默认文件系统
return get(conf);
}
……
String disableCacheName//是否使用被Cache的文件系统
=String.format("fs.%s.impl.disable.cache",scheme);
if(conf.getBoolean(disableCacheName, false)){
return createFileSystem(uri, conf);//创建对应文件系统
}
return CACHE.get(uri, conf);//在Cache中获取对应文件系统
}
该方法通过getScheme()获得文件系统的URI模式,如果模式为空,则返回默认文件系统。默认文件系统的URI模式可以通过配置项${fs.default.name}进行配置,该配置项的默认值是file:///,该默认值和常量LocalFileSystem.NAME相同,即默认文件系统的默认配置是本地文件系统LocalFileSystem。
FileSystem. get()处理过程中另一个可配置并需要判断的条件是:是否使用FileSystem.CACHE中保存的、已经缓存的文件系统。打开一个文件系统是一个比较耗费资源的操作,如打开HDFS,需要和名字节点建立IPC通信,所以,共享文件系统是一个不错的优化。但是,由于文件系统间是相互共享的,应用不小心关闭共享的文件系统,将会影响其他使用者。所以,Hadoop引入了一系列的配置项${fs.%s.impl.disable.cache},其中,%s在使用过程中,会被替换成相应的URI模式。如果该配置项为true(默认值为false),则每次创建一个新的具体文件系统实例;否则,使用共享的文件系统实例。以HDFS为例,它的模式为hdfs,对应的配置项就是${fs.hdfs.impl.disable.cache},该配置项决定,如果FileSystem.get()获取的是(可共享的)HDFS文件系统,方法返回一个新的HDFS文件系统实例,或者是共享HDFS文件系统实例。
如果不共享文件实例,需要通过FileSystem的私有方法createFileSystem()创建相应的文件系统。代码如下:
private static FileSystem createFileSystem(URI uri, Configuration conf)
throws IOException{
//获取文件系统实现的Class类对象
Class<?>clazz=conf.getClass("fs."+uri.getScheme()+"impl",null);
……
if(clazz==null){
thrownew IOException("No FileSystem for scheme:"+uri.getScheme());
}
//通过反射创建对象,并初始化文件系统
FileSystem fs=(FileSystem)ReflectionUtils.newInstance(clazz, conf);
fs.initialize(uri, conf);
return fs;
}
FileSystem. createFileSystem()其实很简单,通过Configuration.getClass()获得具体文件系统实现对应的Class类对象,并进一步创建文件系统对象。再次以HDFS为例,它的URI模式为hdfs,对应配置项名字为fs.hdfs.impl,一般来说,该配置项的值为org.apache.hadoop.hdfs.DistributedFileSystem,根据这个值,Configuration.getClass()返回它对应的Class类对象,保存在局部变量clazz中。然后,createFileSystem()用反射工具类ReflectionUtils中的newInstance()方法创建具体文件系统对象,即DistributedFileSystem实例。ReflectionUtils.newInstance()创建对象后,如果对象实现了Configurable接口,会调用该接口的setConf()方法配置对象,使用的是newInstance()的参数conf中保存的配置信息。随后,具体文件系统的initialize()方法被调用,完成构造后的初始化工作。该方法默认实现是构造用于统计的FileSystem.Statistics对象,该对象会保存在文件系统上的相关操作的计数。
回到FileSystem.get()方法的分析,如果方法允许共享文件系统实例,则调用CACHE.get()获取文件系统实例。FileSystem的内部类Cache保存了已经打开的、可以共享的文件系统,其实现不是很复杂。唯一需要注意的是可共享的条件,这个条件体现在FileSystem.CACHE.Key中(在讨论Hadoop IPC的时候也有一个类似的结构),代码如下:
static class Key{
fnal String scheme;
fnal String authority;
fnal long unique;
fnal UserGroupInformation ugi;
……
}
也就是说,只有在上述这4个值都相等的情况下,文件实例才会被共享。其中,schema是URI模式,这个很自然要相等;其次是URI的authority部分,用相同授权打开的具体文件系统才能共享,用户可以打开URI模式相同,但有不同授权的具体文件系统;unique是一个整数,如果没有特殊情况,默认为0;类型为UserGroupInformation的变量ugi,则保存了打开具体文件系统的本地用户的信息,也就是说,即使其他3部分都相等,不同本地用户打开的具体文件系统也是不能共享的。FileSystem.CACHE.Key通过这4个字段,明确地定义了可共享具体文件系统的条件。
其中,unique字段比较特殊,它提供了一种机制,如果用户需要创建其他3个字段都相同,但又不共享的具体文件系统时,可以使用该字段,以作区分。FileSystem.CACHE.getUnique()实现了这个机制,通过它调用者可以得到一个被Cache管理的,且不被共享的具体文件系统,代码如下。其中getInternal()会调用前面介绍的createFileSystem()函数创建具体文件系统:
static class Cache{
private fnal ClientFinalizer clientFinalizer=new ClientFinalizer();
……
/**用于unique字段的自增变量*/
private static AtomicLong unique=new AtomicLong(1);
……
/**得到一个被Cache管理的,不被共享的具体文件系统*/
synchronized FileSystem getUnique(URI uri, Configuration conf)
throws IOException{
Key key=new Key(uri, conf, unique.getAndIncrement());
return getInternal(uri, conf, key);
}
}
FileSystem. newInstance()调用FileSystem.CACHE.getUnique(),它和FileSystem.get()类似,只不过newInstance()返回的,永远是不被共享的,但又被FileSystem.CACHE对象管理的文件系统。读者可能会问,为什么文件系统要被FileSystem.CACHE管理呢?简单地说,FileSystem.CACHE对象提供了清理机制,如果用户打开文件系统后不关闭,FileSystem.CACHE会利用Runtime.addShutdownHook()机制,在Java虚拟机退出时,关闭被打开的文件系统。这样,就不会出现因为文件系统没有关闭导致的数据丢失、数据不一致的情况。这部分功能的相关代码在FileSystem.CACHE.getInternal()中,由于篇幅的原因,就不再继续探讨了。另外,由于FileSystem.newInstance()方法永远都返回一个不被共享的具体文件系统实例,在抽象文件系统的close()方法中,会调用FileSystem.CACHE.remove(),在CACHE对象中移除对应的文件系统,避免Java虚拟机退出时再次被关闭,代码如下:
public void close()throws IOException{
processDeleteOnExit();
CACHE.remove(this.key, this);//从CACHE中删除文件系统实例
……
}
总的来说,利用Java的反射机制,FileSystem.get()和FileSystem.newInstance()的实现过程还是比较简单并且具有一定的可扩展性的。抽象文件系统FileSystem中的其他静态方法,包括工具方法和对文件系统度量信息的收集等实现都不复杂。