分类精度评价指标一览.
好久没有发博客了,主要是要搞论文啊,好难好难好难。 论文是神经网络分类任务,因此实验部分要涉及一些分类网络常用的评价指标。 用这篇博客来学习吧。
分类指标
一般你能经常看到的的指标有下面这些:
1: TP,FP,TN,FN :一套指标。
- TP:True Positive,即正确预测出的正样本个数
- FP:False Positive,即错误预测出的正样本个数(本来是负样本,被我们预测成了正样本)
- TN:True Negative,即正确预测出的负样本个数
- FN:False Negative,即错误预测出的负样本个数(本来是正样本,被我们预测成了负样本)
2 : 准确度 Accuracy。
精确度是最常见的指标了,就是看你预测对的样本占全部样本的比例。
Acc = (TP+TN)÷(TP+NP+TN+FN)
在某些情况下可能不能真实衡量模型能力,比如某个类所占比例过大时。很多指标都是为了弥补这个缺陷而被开发出来的。
3: 精确度 Precision。
分类器预测出的正样本中,真实正样本的比例。
Precision = TP÷(TP+FP)
4: 召回率 recall。
在所有正样本中,你能召回(找到)多少比例。
Recall:TP÷(TP+FN)
5: F1
F1 score 是精确率和召回率的一个加权。 衡量的是一个整体的稳健性。
F1 = 2(Precision*Recall) /(Precision + Recall)
6:Macro average 与 Micro average
这两个较为难理解, 前者指 宏平均, 后者指微平均。 使用时是与其他指标结合使用的。
Macro average: 宏平均。 不管类内部的情况,只在宏观上对每个类的指标进行一次平均。
Micro average: 微平均, 会考虑上类内部的数量。 这个会根据每个类的数量多少有所区别。
举例说明:
| TP | FP | |
| 类别0 | 2 | 1 |
| 类别1 | 0 | 2 |
看 对于类别0 他的Precision 是 2 /(2+1) = 0.666
对于类别1 他的Precision 是 0 /(2) = 0
宏的 只看宏观上 也就是 0.666和0 两个数字 的平均 也就是 mac_Pre0.333
微的 要看微观上 也就是考虑类内数量。 也就是 总共的TP =2 总共的FP = 3 mic_Pre = 2/5 = 0.4
对于F1 什么的,也同样是这样的计算方式。
7: AUC 与ROC。
ROC曲线(Receiver Operating Characteristic)全称:受试者工作特征曲线
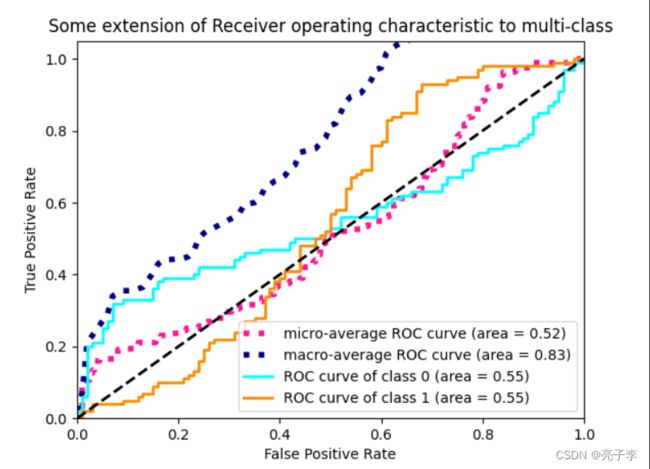
看一张 我画的ROC图。 可以看到 他的横坐标是FPR,纵坐标是TPR.
FPR:伪正类率。 FPR = FP /(FP + TN) . 即 为负类的数据中, 有多少被预测为正数据。
TPR: 真正类率。 TPR = TP / (TP+FN) 。 即正类数据,多少被正确的预测为正类了 。、
现在是设定了一个概率阈值。超过这个阈值的就被分为正,低于这个阈值的分为负。我们知道,神经网络中,一般这个阈值都是0.5。 如果这个阈值发生了变化,我们想一下,
如果变为0.9,那么大部分的样本都会被预测为负类。 那么 FPR就会降低。 TPR也会降低。
他们都更难预测为正类了。
如果阈值变为1 那么全部样本都是预测为负类。 FPR是0 TPR就是0
如果阈值为0 ,那么全部样本都预测为正类,FPR就是1 ,TPR就是1.
上面这个图 ,就是不同的阈值下, (FPR,TPR)数据对 形成的图。
而这些阈值 一般取自数据本身的概率值排序。
而AUC 指的就是 ROC 曲线 右下角的那部分面积。
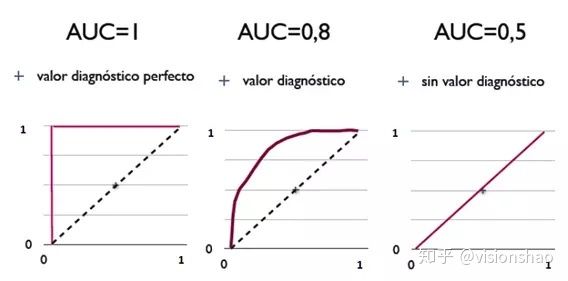
AUC的含义为,当随机挑选一个正样本和一个负样本,根据当前的分类器计算得到的score将这个正样本排在负样本前面的概率。
很难懂 ,但反正就是越大越好。
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测
而且 ROC曲线不受正负样本数量分布的影响。 因此是一个经常使用的指标。
8: kappa系数。
Kappa系数是一个用于一致性检验的指标,也可以用于衡量分类的效果,我的感觉是很不常用。因为对于分类问题,所谓一致性就是模型预测结果和实际分类结果是否一致。kappa系数的计算是基于混淆矩阵的,取值为-1到1之间,通常大于0。


这个 公式要细看 才知道他是搞什么的 。其实 就是Pe 就是一个惩罚性系数, 你越不平衡, 他就越高。 kappa 就越低。 而已 。
------------------------------------------------------------------------------------------
代码实现。
我基本是基于torch 和 sklearn的
import torch
import matplotlib.pyplot as plt
import time
import numpy as np
import torch.nn as nn
import torch.nn.init as init
from sklearn.metrics import roc_curve, auc, f1_score, precision_recall_curve, average_precision_score,precision_score
from itertools import cycle model.eval()
labels = []
preds = []
score_list = []
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].to(device))
# batch_loss = loss(val_pred, data[1].cuda(),w, model)
batch_loss = loss(val_pred, data[1].to(device))
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
labels.extend(data[1].numpy())
preds.extend(np.argmax(val_pred.cpu().data.numpy(), axis=1))
score_tmp = nn.Softmax(dim=1)(val_pred)
score_list.extend(score_tmp.detach().cpu().numpy())
先收集 三个东西 ,即 数据的标签 labels 预测值 preds , 还有预测的概率 score_list.
preds_tensor = torch.tensor(preds)
label_tensor = torch.tensor(labels)
# TP predict 和 label 同时为1
TP = TN = FN = FP = 0
TP += ((preds_tensor == 1) & (label_tensor == 1)).cpu().sum()
# TN predict 和 label 同时为0
TN += ((preds_tensor == 0) & (label_tensor == 0)).cpu().sum()
# FN predict 0 label 1
FN += ((preds_tensor == 0) & (label_tensor== 1)).cpu().sum()
# FP predict 1 label 0
FP += ((preds_tensor == 1) & (label_tensor == 0)).cpu().sum()计算TP,TN,FN,FP ,然后可以通过这四个指标算出其他大部分的指标。 要转换成tensor才好算一点。
下面是ROC曲线。
score_array = np.array(score_list)
num_class =2
label_tensor = label_tensor.reshape((label_tensor.shape[0], 1))
label_onehot = torch.zeros(label_tensor.shape[0], num_class)
label_onehot.scatter_(dim=1, index=label_tensor, value=1)
label_onehot = np.array(label_onehot)
fpr_dict = dict()
tpr_dict = dict()
roc_auc_dict = dict()
for i in range(num_class):
fpr_dict[i], tpr_dict[i], _ = roc_curve(label_onehot[:, i], score_array[:, i])
roc_auc_dict[i] = auc(fpr_dict[i], tpr_dict[i])
# micro
fpr_dict["micro"], tpr_dict["micro"], _ = roc_curve(label_onehot.ravel(), score_array.ravel())
roc_auc_dict["micro"] = auc(fpr_dict["micro"], tpr_dict["micro"])
# macro
# First aggregate all false positive rates
all_fpr = np.unique(np.concatenate([fpr_dict[i] for i in range(num_class)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(num_class):
mean_tpr += np.interp(all_fpr, fpr_dict[i], tpr_dict[i])
# Finally average it and compute AUC
mean_tpr /= num_class
fpr_dict["macro"] = all_fpr
tpr_dict["macro"] = mean_tpr
roc_auc_dict["macro"] = auc(fpr_dict["macro"], tpr_dict["macro"])
plt.figure()
lw = 2
plt.plot(fpr_dict["micro"], tpr_dict["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc_dict["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr_dict["macro"], tpr_dict["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc_dict["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(num_class), colors):
plt.plot(fpr_dict[i], tpr_dict[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc_dict[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Some extension of Receiver operating characteristic to multi-class')
plt.legend(loc="lower right")
plt.savefig('set113_roc.jpg')
plt.show()
参考文献 :
机器学习-理解Accuracy,Precision,Recall, F1 score以及sklearn实现 - 知乎
在pytorch 中计算精度、回归率、F1 score等指标的实例(IT技术)
kappa系数简介 - 知乎
ROC曲线和AUC值 - 知乎