Hbase与pegasus对比
1.hbase的优点
1.支持海量数据,博主实践中的单表可以达到上百亿行数据。
2.列式存储,面向列存储,column family与qualifier,按照列簇独立检索。
3.因为空列不占据存储空间,所以表结构可以非常稀疏,适合互联网这种稀疏场景。
4.半结构化或非结构化数据,如果数据字段不确定或者无规律,可以动态添加字段,而不用像结构化数据一样每一行都是确定的字段,特别适合互联网场景下数据比较杂乱的情况。
5.多版本:每个cell中的数据可以有多个版本,默认的版本号是插入数据的时间戳。
6.高可靠性
6.1 WAL(write-ahead log)机制。
6.2 Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏
6.3 底层的存储基于hdfs,也是有备份的
7.高性能
7.1 hbase的LSM数据结构与rowkey有序排列等,保证了hbase的写入性能。
7.2 region切分,主键索引和缓存机制使得Hbase在海量数据下具备一定的随机读取性能。
2.hbase相关点总结
WAL
write-ahead-log预写日志是hbase的regionserver在处理数据插入和删除的过程中用来记录操作内容的一种日志。在每次写入删除数据时,先会写wal日志。只有当wal日志写成功以后,客户端才会被告知提交数据成功,否则会通知客户端提交失败。
一个RegionServer所有的region都共享同一个Hlog。一次数据的提交是先写WAL,写入成功后,再写memstore。当memstore值到达一定量时,就会形成一个个StoreFile。
LSM Tree
LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
详见参考文档介绍
hbase各项原理介绍
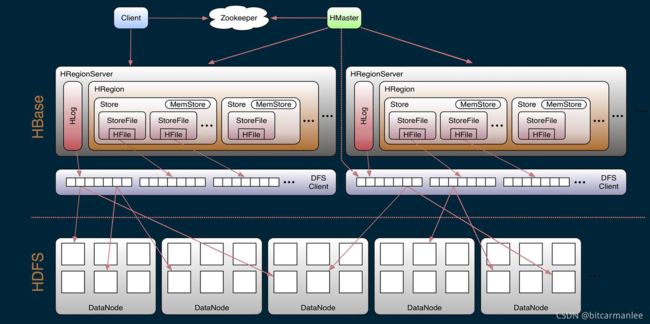
包括Master, Regionserver, Hregion, Store, MemStore, StoreFile, HFile, HLog等。
hbase架构图
2.hbase缺点
1.非关系型数据库,不支持sql语句。
2.rowkey的设计限制了多条件查询的方便性。
3.数据类型都是字符串。
4.不支持事务。
5.不能对列建索引。
6.不适合范围扫描查询。
3.hbase数据查询的三种方式
1.按指定RowKey获取唯一一条记录,get方法
get ’table name’,’rowid’
get 'table name', ‘rowid’, {COLUMN => 'column family:column name'}
2.scan方式
scan可以通过setCaching与setBatch方法提高速度(以空间换时间)
scan可以通过setStartRow与setEndRow来限定范围。范围越小,性能越高。
scan可以通过setFilter方法添加过滤器
scan 'table name',{STARTROW=>'start_row_key',STOPROW=>'stop_row_key'}
scan 'table name',{COLUMNS=>'cf:column',STARTROW=>'start_row_key',STOPROW=>'stop_row_key'}
scan 'table name',{COLUMNS=>'cf:column'}
3.扫全表
scan 'table name'
4.hbase一些组件
client
HBase 有两张特殊表:
.META.:记录了用户所有表拆分出来的的 Region 映射信息,.META.可以有多个 Regoin
-ROOT-:记录了.META.表的 Region 信息,-ROOT-只有一个 Region,无论如何不会分裂
Client 访问用户数据前需要首先访问 ZooKeeper,找到-ROOT-表的 Region 所在的位置,然 后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次 网络操作,不过 client 端会做 cache 缓存。
zookeeper
1、ZooKeeper 为 HBase 提供 Failover 机制,选举 Master,避免单点 Master 单点故障问题
2、存储所有 Region 的寻址入口:-ROOT-表在哪台服务器上。-ROOT-这张表的位置信息
3、实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master
4、存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family
Master
1、为 RegionServer 分配 Region
2、负责 RegionServer 的负载均衡
3、发现失效的 RegionServer 并重新分配其上的 Region
4、HDFS 上的垃圾文件(HBase)回收
5、处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等)
RegionServer
1、RegionServer 维护 Master 分配给它的 Region,处理对这些 Region 的 IO 请求
2、RegionServer 负责 Split 在运行过程中变得过大的 Region,负责 Compact 操作
5.pegasus想要解决的问题
1、对于 HBase 而言,它将“节点探活”这一重要的任务交给 Zookeeper 来做,是可以商榷的。因为如果运维不够细致的话,会使得 Zookeeper 成为影响 HBase 稳定性的一个坑。
在 HBase 中,Region Server 对“Zookeeper 会话超时”的处理方式是“自杀”。而 Region Server 上“多个 Region 合写一个 WAL 到 HDFS”的实现方式会使得“自杀”这一行为的成本比较高,因为自杀之后 Server 重启时会拆分和重放 WAL。这就意味着假如整个 HBase 集群挂了,想要将 HBase 重新给拉起来,时间会比较长。
2、即使我们能保证 Zookeeper 的稳定性,“节点探活”这一功能也不能非常稳定的运行。因为 HBase 是用 Java 实现的。GC 的存在,会使得 Zookeeper 把正常运行的 Region Server 误判为死亡,进而又会引发 Region Server 的自杀;在其之上的 Region,需要其他的 Server 从 HDFS 上加载重放 WAL 才能提供服务。而这一过程,同样也是比较耗时的。在此期间内,Region 所服务的 Key都是不可读写的。
对于这一问题,可以通过将“节点探活”的时间阈值拉长来解决。但这会使得真正的“Region Server 死亡”不能被及时发现,从而另一个方面引发可用性的问题。
3、GC 的另一个问题是,HBase 在读写延时上存在毛刺。我们希望在广告、推荐这种业务上能够尽量避免出现这种毛刺,即能够有一个比较稳定的延时。
改进方法:
1.心跳并没有依赖 Zookeeper,而是单独抽出来,直接由 MetaServer 进行管理
2.数据不写到第三方的 DFS 上,而是直接落入 ReplicaServer。
3.为了对抗单个 ReplicaServer 的失效,每个 Partition 都有三个副本,分散到不同的ReplicaServer 上。
参考文档
1.https://zhuanlan.zhihu.com/p/135371171 LSM Tree介绍
2. https://blog.51cto.com/liguodong/2992444 WAL机制
3. https://www.cnblogs.com/qingyunzong/p/8692430.html hbase底层各项原理
4. https://juejin.cn/post/6844903504964747278 pegasus介绍
5.https://www.bookstack.cn/read/Pegasus/4719d738c2ccdcff.md