python性能相关
python jit
得益于python低廉的学习成本和高效的开发效率,以及python在web开发,人工智能,爬虫,自动化运维等方面的应用,python无疑成为了当今高校和公司中最火的编程语言,但是尺有所长,寸有缩短,python的效率无疑是它最大的短板。java之父就评价过python:当跑跑基准测试就发现。相对于rust和java来说,python真的很慢。本文将简单阐述python为什么很慢,针对python慢的常用优化方法,将对python jit展开实践。
python 和其他编程语言的对比
- 性能对比(以下程序执行相同的基准测试,从时间和内存消耗两方面对不同编程语言进行排名,可以看到python排到了最后)
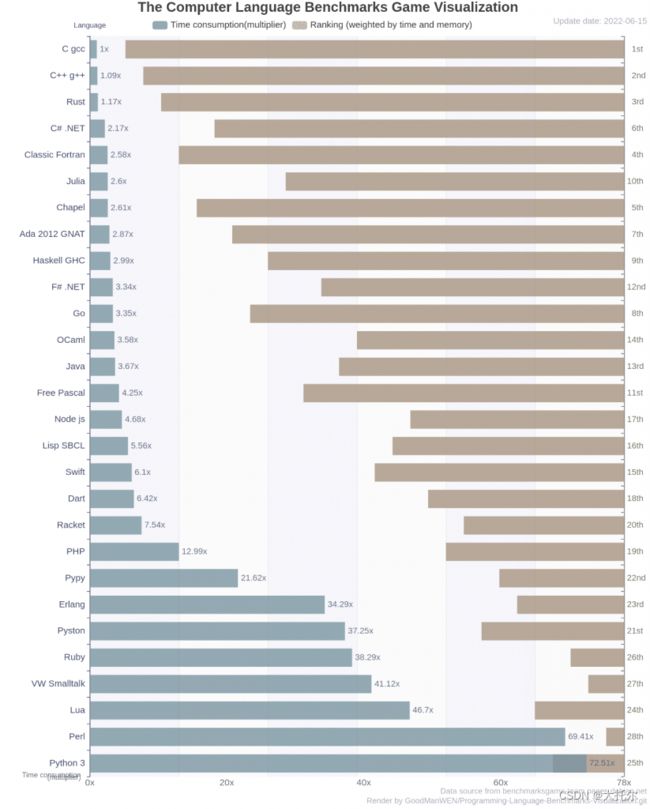
此外我也执行了一个简单的性能测试,执行以下python代码,耗时32秒
sum, i = 0, 0
while i < 100000000:
sum += i
i += 1
print(sum)
同样执行这样的一个java代码,耗时不到1s,同时java计算10亿的加和也仅仅在3s内完成
double sum = 0;
int i = 0;
while(i < 1000000000){
sum += i;
i++;
}
System.out.println(sum);
python 为什么很慢
相对于c语言和c++来说,python内部帮助程序员隐藏内存分配,内存回收,指针等这些内容,因此使用python会让你感觉更简便。在运行过程中python会被编译成python字节码(一种更低级与平台无关的代码),python 解释器在运行python代码时会基于字节码解释运行而不是原始机器指令,这种设计会使python稍稍有些慢。实际python的运行流程如下图:

而对于c或c++来说,通过编译器可以生成直接能够运行的代码:

至此我们知道了python运行慢的第一个原因,但是java的运行流程是和python的运行流程相似的,但为什么python在执行代码的时候也要比python快十倍左右。
java/.net 拥有即时编译器,然而由于python语言的动态类型限制,很难为python编写这样的优化组件,总的来说,python的动态类型导致了python比java慢很多。
此外在并行计算方面,python的表现是要比java差的,由于python全局解释器锁的存在,python在同一时间一个线程内只能有一个线程持有这个解释器锁,这就表示python的多线程实际上是伪多线程。
总之python慢的原因主要由3个:1. python是动态类型的 2. python GIL(全局解释器锁)的存在 3. python是解释型语言。
python jit
jit 即时编译,我们可以通过numba实现python的即时编译,numba 为一开源的python即时编译技术,可以通过为我们编写的函数添加编译器的方式实现python代码的即时编译
使用方式只需要通过为需要加速的函数添加装饰器即可,但函数中使用的数据类型有限制,只能使用python原生的数据类型和numpy支持的数据类型。执行以下代码只需要1.5秒的时间,快了将近五十倍。
from numba import jit
@jit
def test():
sum, i = 0.0, 0
while i < 100000000:
sum += i
i += 1
print(sum)
test()
python之列表和元祖的区别
这是python的一个常见的八股文,通常我们会说列表可变,元祖不可变,这两者都用来描述一个序列,通常元祖的访问速度要比列表更快一些,当创建一个定长不需要修改的序列优先考虑使用元祖。以下将通过实验演示他们之间的差别。
因为list是可变的,python需要预先分配更多的内存,而tuple是不可变的,只需要为python分配可以存储数据的最小空间就可以了,可以通过如下代码查看python对象的内存占用情况。可以看出元祖占用的内存空间稍微要少一点。
import sys
a_list = list()
a_tuple = tuple()
a_list = [1,2,3,4,5]
a_tuple = (1,2,3,4,5)
print(sys.getsizeof(a_list))
print(sys.getsizeof(a_tuple))
Output:
104 (bytes for the list object
88 (bytes for the tuple object)
下面将演示tuple的时间优势
import sys, platform
import time
print(platform.python_version())
start_time = time.time()
b_list = list(range(10000000))
end_time = time.time()
print("Instantiation time for LIST:", end_time - start_time)
start_time = time.time()
b_tuple = tuple(range(10000000))
end_time = time.time()
print("Instantiation time for TUPLE:", end_time - start_time)
start_time = time.time()
for item in b_list:
aa = b_list[20000]
end_time = time.time()
print("Lookup time for LIST: ", end_time - start_time)
start_time = time.time()
for item in b_tuple:
aa = b_tuple[20000]
end_time = time.time()
print("Lookup time for TUPLE: ", end_time - start_time)
Output:
3.6.9
Instantiation time for LIST: 0.4149961471557617
Instantiation time for TUPLE: 0.4139530658721924
Lookup time for LIST: 0.8162095546722412
Lookup time for TUPLE: 0.7768714427947998
可以看出python tuple的查找时间要稍微快了一小丢丢
总之,list 和 tuple 最大的不同就是list 可变而tuple 不可变
python 多进程 多线程
多进程和多线程是两种加速python程序执行速度的方式,在理解python多线程和多进程,首先要了解进程和线程,并行和并发,接着我会对python中多进程和多线程做简单说明,并演示其应用场景
进程和线程
进程是资源分配的最小单位,线程是CPU调度的最小单位,一个进程可以包含,线程包含在进程内部,一个进程可以包含多个线程,进程内线程共享资源。进程会占用更多的系统资源。
并行和并发
并行表示多件事情在同一时间执行,并发表示多件事情在很近的时间间隔去执行,但执行时并不会发生时间上的重叠。
python中进程和线程的适用情况
python中进程可以做到多核并行执行,适合计算密集型的任务,而由于GIL锁的存在python中一个进程任意时刻其中智能有一个线程执行,python的多线程适合执行I/O密集型任务。像计算圆周率,这种只依靠内存的任务就是计算密集型任务,对于下载文件,爬虫这类任务,多涉及到读写磁盘,网络I/O时的I/O密集型任务,适合使用多线程
python 多线程下载文件案例
不开启多线程下载六个文件耗时约8s
import requests
from tool import time_sum
def download_img(img_url: str):
"""
Download image from img_url in curent directory
"""
res = requests.get(img_url, stream=True)
filename = f"{img_url.split('/')[-1]}.jpg"
with open(filename, 'wb') as f:
for block in res.iter_content(1024):
f.write(block)
@time_sum
def main_download():
images = [
# Photo credits: https://unsplash.com/photos/IKUYGCFmfw4
'https://images.unsplash.com/photo-1509718443690-d8e2fb3474b7',
# Photo credits: https://unsplash.com/photos/vpOeXr5wmR4
'https://images.unsplash.com/photo-1587620962725-abab7fe55159',
# Photo credits: https://unsplash.com/photos/iacpoKgpBAM
'https://images.unsplash.com/photo-1493119508027-2b584f234d6c',
# Photo credits: https://unsplash.com/photos/b18TRXc8UPQ
'https://images.unsplash.com/photo-1482062364825-616fd23b8fc1',
# Photo credits: https://unsplash.com/photos/XMFZqrGyV-Q
'https://images.unsplash.com/photo-1521185496955-15097b20c5fe',
# Photo credits: https://unsplash.com/photos/9SoCnyQmkzI
'https://images.unsplash.com/photo-1510915228340-29c85a43dcfe',
]
for img in images * 1:
download_img(img)
if __name__ == '__main__':
main_download()
开启多线程下载耗时约3s
import requests
from tool import time_sum
def download_img(img_url: str):
"""
Download image from img_url in curent directory
"""
res = requests.get(img_url, stream=True)
filename = f"{img_url.split('/')[-1]}.jpg"
with open(filename, 'wb') as f:
for block in res.iter_content(1024):
f.write(block)
@time_sum
def main_download():
images = [
# Photo credits: https://unsplash.com/photos/IKUYGCFmfw4
'https://images.unsplash.com/photo-1509718443690-d8e2fb3474b7',
# Photo credits: https://unsplash.com/photos/vpOeXr5wmR4
'https://images.unsplash.com/photo-1587620962725-abab7fe55159',
# Photo credits: https://unsplash.com/photos/iacpoKgpBAM
'https://images.unsplash.com/photo-1493119508027-2b584f234d6c',
# Photo credits: https://unsplash.com/photos/b18TRXc8UPQ
'https://images.unsplash.com/photo-1482062364825-616fd23b8fc1',
# Photo credits: https://unsplash.com/photos/XMFZqrGyV-Q
'https://images.unsplash.com/photo-1521185496955-15097b20c5fe',
# Photo credits: https://unsplash.com/photos/9SoCnyQmkzI
'https://images.unsplash.com/photo-1510915228340-29c85a43dcfe',
]
for img in images * 1:
download_img(img)
if __name__ == '__main__':
main_download()