java复习---基础
1.面向对象和面向过程的区别
- 面向过程:性能较高。面向过程语言大多是可以直接编译成机械码,直接就能在电脑上运行;而面向过程语言在运行时需要进行类的实例化,开销大并且消耗资源;而对于Java语言的性能较差问题,主要原因是它属于半编译语言,最终的执行代码不是可以直接被CPU执行的二进制机械码。
- 面向对象:易维护,易复用,易拓展。这些优点完全建立在面向对象语言的三大特性之上的,我不说大家应该都耳熟能详了,也就是封装,继承,多态,也正是基于此,我们才能用Java语言设计成低耦合的系统,让系统更加灵活。
2.Java语言有哪些特点?
- 面向对象(封装继承多态)
- 平台无关性(Java虚拟机实现了一次编译,多次运行)
- 可靠性
- 安全性
- 支持网络编程
- 编译与解释并存
3.对JVM JDK JRE 的通俗解答。
-
JVM:是运行java字节码的虚拟机。多系统多实现(windows,Linux,macOS等),设计的目的是为了使用相同的字节码,产生一直的运行效果,即俗话说的一次编译,到处运行。

我们需要着重理解的是.class–>机器码这一步,JVM类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这样的效率十分慢,并且有的方法和代码是需要多次执行的(也就是我们常说的热点代码块)。因此就衍生出了JIT编译器,它是运行时编译,首先字节码文件编译一次,然后将编译好的二进制机器码保存好下次使用,而我们知道,机器码的运行效率肯定高于Java解释器,这也充分说明了Java是编译与解释共存的语言。 -
JDK: Java开发工具包。拥有JRE所拥有的的一切,还有编译器(javac)和工具,它能够创建和编译程序。
-
JRE:Java运行时环境。它是运行已编译Java程序所需的所有内容的集合。包括JVM,java类库,java命令和其他一些基础组件,但是,它不能用于创建新程序。
4.Java和C++有什么区别?
- 都是面向对象语言,支持封装继承多态
- Java不提供指针来直接访问内存,程序内存更安全
- Java的类是单继承的,C++实现多继承;虽然Java到的类不可以多继承,但是接口可以实现多继承。
- Java有自动内存管理机制,不需要程序员手动释放内存。
- 在C语言中,字符串用‘\0’来标识结束,但是java中没有结束符概念。
5.Java应用程序跟小程序之间有哪些差别?
-
应用程序的启动入口是main()方法。
-
小程序的启动入口是init()或run()方法。
6.重载与重写的区别
- 重载:发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。

- 重写:发生在子类中,是子类对父类的允许访问的方法的实现过程进行重新编写,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。另外,私有方法(private修饰)不可被重写。一句话总结,方法提供的行为改变,方法的外貌没有改变。
7.Java面向对象编程三大特性:封装继承多态
- 封装:把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
- 继承:使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。三大要点:1.子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。2.子类可以拥有自己属性和方法,即子类可以对父类进行扩展。3.子类可以用自己的方式实现父类的方法(方法重写)。
- 多态:指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定。通俗讲,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。实现多态的方式(Java):继承和接口
8.String,StringBuilder和StringBuffer的区别是什么?String为什么不可变?
-
可变性:String类中使用final关键字修饰的字符数组来保存字符串。
private final char value[]。后两者都继承AbstractStringBuilder类,这个类也是用字符数组保存字符串,但是没有用final关键字修饰,所有这连个对象是可变的。 -
线程安全性:String对象是不可变的,也就可以理解为常量,线程安全;StringBuffer对方法加了同步锁,所以线程安全;而StringBuilder没有加锁,所以非线程安全。
-
性能:StringBuilder > StringBuffer > String
每次对String类型进行改变时,都会生成一个新的String对象,然后将指针指向新的String对象内存地址。因此最慢。
StringBuilder虽然比StringBuffer性能提升了10~15%作用,但是要冒多线程不安全的风险。
-
使用总结:1.操作少量数据,用String。2.单线程操作字符串缓冲区下操作大量数据,使用StringBuilder 3.多线程操作字符串缓冲区下操作大量数据,使用StringBuffer
9.在Java中定义一个不做事的无参构造方法的作用?
Java程序在执行子类的构造方法之前,如果没有用**super()**来调用父类特定的构造方法,那么程序默认取父类的无参构造方法。但是父类中没有无参构造方法,就会编译报错了。解决方案以下二选一即可:
- 在父类中补上一个无参构造方法
- 在子类中使用**super()**方法调用父类一个特定的有参构造。
10.接口和抽象类的区别
1.接口的方法默认是public,所有方法在接口中不能有实现(java 8 开始接口方法可以有默认实现),而抽象类可以有非抽象的方法。
2.接口方法默认修饰符是public,抽象方法可以有public、protected和default这些修饰符(抽象方法就是为了被重写所以不能使用private关键字修饰!)
3.接口中变量必须是public static final 修饰,而抽象类中不一定。
4.一个类可以实现多个接口,但只能实现一个抽象类。
5.从设计层面来讲,抽象是对类的抽象,是一种模板设计;接口是对行为的抽象,是一种行为规范。
11.成员变量和局部变量的区别有哪些?
-
从语法形式上看,成员变量属于类,局部变量属于局部代码块。成员变量可以被public,private,static等修饰符修饰,而局部变量不可被修饰;但是都能被final关键字修饰。
-
从变量在内存中的存储方式来看:如果成员变量是使用
static修饰的,那么这个成员变量是属于类的,如果没有使用static修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。 -
从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
-
成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值
12.一个类的构造方法的作用是什么?若一个类没有声明构造方法,能正确执行吗?为什么?
- 主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。
13.在调用子类的构造方法之前会先调用父类的无参构造方法,其目的是?
帮助子类完成初始化工作。
14.==与equals方法
== : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象(基本数据类型比较的是值,引用数据类型比较的是内存地址)。
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
15.hashcode()与equal()方法
介绍
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode
我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode: 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
通过我们可以看出:hashCode() 的作用就是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
- hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
16.equals()方法中,有哪些方法能避免空指针?
public static void main(String[] args){
String text = null;
if (text.equals("text")){
System.out.println("text");
}
}
上述的写法,当equal()方法的调用方为空时,就会造成ava.lang.NullPointerException,就是我们常说的空指针异常。避免的方式通常有以下两种方式:
-
将不为空的变量作为equals()方法的调用方,但是在实际运行中我们又难以预测。
-
使用java.util.Objects#equals,JDK7引入的工具类。
这是改造后的代码,这样就可以有效避免空指针异常了。
public static void main(String[] args){
String text = null;
if (Objects.equals(null,"text")){
System.out.println("text");
}else {
System.out.println("不相等");
}
}
17.整型包装类型的比较相关问题
public static void main(String[] args){
Integer x = 3;
Integer y = 3;
System.out.println(x==y); //true
Integer a = new Integer(5);
Integer b = new Integer(5);
System.out.println(a==b);//false
System.out.println(a.equals(b)); //true
}
当使用自动装箱的方式创建一个对象时,倘若值在**-128~127**之间,会将创建的Integer对象缓存起来;当下次再出现该值时直接从缓冲池中拿,所以上述代码中x和y引用的是相同的Integer对象。
18.浮点数(如1.0f 0.9f等)之间进行等值判断或基本运算时,如何保证它的精密度?
《阿里巴巴Java开发手册》中提到:浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用 equals 来判断。
float a = 1.0f - 0.9f;
float b = 0.9f - 0.8f;
System.out.println(a);// 0.100000024
System.out.println(b);// 0.099999964
System.out.println(a == b);// false
正确做法是使用 BigDecimal 来定义浮点数的值,再进行基本运算操作。
-
等值比较
BigDecimal a = new BigDecimal("1.0");//切记这儿是String类型的字符串数字(你们一眼就能看明白咯,但得记住哦) BigDecimal b = new BigDecimal("0.9"); System.out.println(a.compareTo(b));// 1 -
基本运算
BigDecimal a = new BigDecimal("1.0"); BigDecimal b = new BigDecimal("0.9"); BigDecimal c = new BigDecimal("0.8"); BigDecimal x = a.subtract(b);// 0.1 BigDecimal y = b.subtract(c);// 0.1 System.out.println(x.equals(y));// true -
保留小数位
通过
setScale方法设置保留几位小数以及保留规则public static void main(String[] args){ BigDecimal cir = new BigDecimal("3.141592657"); BigDecimal scale = cir.setScale(2, BigDecimal.ROUND_HALF_DOWN); System.out.println(scale); //3.14 }19.线程有哪些基本状态?
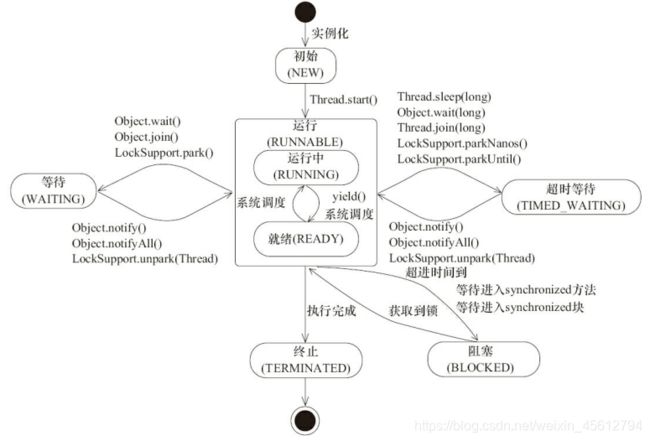
状态名称 说明 NEW 初始状态,线程刚被构建,还没有调用start()方法 RUNNABLE 运行状态,Java线程将操作系统中的就绪和运行两种状态统称为运行中。 BLOCKED 阻塞状态,表示线程阻塞于锁。(常见于并发编程) WAITING 等待状态。当前线程进入该状态时,表示需要等待其他线程做出一些特定操作(通知或中断) TIME_WAITING 超时等待状态,该状态不同于WAITING,它可以在指定的时间后自行返回。 TERMINATED 终止状态。表示当前线程已经执行完毕 线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示(图源《Java 并发编程艺术》4.1.4节):
19.对于final关键字的一些总结。
final关键字主要用在三个地方:变量,类,方法
1、对于一个final变量,如果是基本类型的变量,一旦被初始化后便不能再修改它的值;如果是引用类型的变量,一旦被初始化后便不能再指向另一个对象。
2.对于一个final类,表名这个类不能被继承。类中的所有成员方法都被隐式的指定为final方法。
3.对于final方法被使用的两个原因:
- 把方法锁定,以防继承类修改方法的含义。
- 提升效率。在早期的Java版本中,会将final方法转为内嵌调用,但是如果方法过于庞大,我们可能看不到任何内嵌调用带来的性能提升,因此现在的Java版本不再进行final优化了,类中所有的private方法都会被隐式的指定为final。
20.对finally的用法详解。
开门见山,finally与final无任何关系!
finally用于try catch 代码块, 无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。
以下四种特殊情况,finally块不会被执行:
- 在finally代码块的第一行发生异常,则之后的代码不会被执行。(严格来讲还在执行的finally代码块,虽然发生了异常)
- 在前面的代码中调用了System.exit(int)已退出程序。
- 程序所在的线程死亡。
- 关闭了CPU。
经典案例:
public class FinallyTest {
public static void main(String[] args){
int value = 3;
System.out.println(method(value));//输出0
}
private static int method(int value) {
try {
return value*value;
}finally {
return 0;
}
}
}
以上的返回值为0,这是因为finally语句的返回值覆盖了try代码块的返回值。
21.在Java中,如果有些字段不想被序列化,怎么办?
对应不想进行序列化的变量,使用transient关键字修饰。只能修饰变量,不能修饰类和方法。
22.为什么Java中只有值传递?
科普两个概念:
形式参数:简称形参。是定义函数名和函数体的时候用到的参数。目的是用来接受调用该方法的参数。
实际参数:在调用有参函数时,主调函数与被调函数之间有数据传递关系。当主调函数调用另一个函数时,函数名后面括号中的参数称为实际参数。
简单举个栗子:
public class ParamTest {
//main是主调函数
public static void main(String[] args){
//"我的名字叫suvue"是实际参数
printIn("我的名字叫suvue");
}
//printIn是被调函数
//String类型的value是形式参数
private static void printIn(String value) {
System.out.println(value);
}
}
理解了上面两个概念了,我们再来看这两个新概念:
值传递:调用函数时,将实际参数复制一份,传递给被调函数。这样设计的好处,对函数的修改只是操作的副本,而不会影响原来的值。
引用传递:调用函数时,将实际参数的内存地址传递给被调函数,那么函数对参数的修改,将直接影响到实际参数。
| 值传递 | 引用传递 | |
|---|---|---|
| 区别 | 会创建副本 | 不会创建副本 |
| 结果 | 函数中无法改变原始对象 | 函数中可以改变原始对象 |
所以,值传递和引用传递的区别并不是传递的内容。而是实参到底有没有被复制一份给形参
常见谬论:
在传递普通类型的时候是值传递,在传递对象类型的时候是引用传递。这是错误的!
引用Hollis大神的一个例子佐证:
你有一把钥匙,当你的朋友想要去你家的时候,如果你直接把你的钥匙给他了,这就是引用传递。这种情况下,如果他对这把钥匙做了什么事情,比如他在钥匙上刻下了自己名字,那么这把钥匙还给你的时候,你自己的钥匙上也会多出他刻的名字。
你有一把钥匙,当你的朋友想要去你家的时候,你配了一把新钥匙给他,自己的还在自己手里,这就是值传递。这种情况下,他对这把钥匙做什么都不会影响你手里的这把钥匙。
但是,不管上面哪种情况,你的朋友拿着你给他的钥匙,进到你的家里(被调函数),把你家的电视砸了(实参传递过来的是一个对象,修改了这个对象的一个属性)。那你说你会不会受到影响?比如我们在setName方法中,改变user对象的name属性的值的时候,不就是在“砸电视”么。因此你改变的不是那把钥匙,而是钥匙打开的房子。
结论:
Java中其实还是值传递的,只不过对于对象参数,值的内容是对象的引用。
23.Java中的IO流分为几种?
- 按照流的流向分,可以分为输入流和输出流。
- 按照操作单元分,可以分为字节流和字符流。
- 按照流的角色分,可以分为节点流和处理流。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
目前Java中的流操作如下图(来源于开源项目JavaGuide)

24.不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
Java虚拟机将字节转换成字符流是非常耗时的,并且由于不知道编码类型,很容易造成乱码问题;因此IO流干脆提供一个直接操作字符的接口,以便我们对字符的流操作。一般地,对于视频、图片等媒体文件用字节流比较好,如果涉及到字符的话就是用字符流。
25.深拷贝VS浅拷贝
- 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
- 深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。