C语言学习之实用调试技巧
目录
一. 调试的基本概念
1. 调试的基本步骤
2. debug和release
3.调试方法
4.调试的时候查看程序当前信息
5.查看寄存器信息
编辑二. 调试示例
1.程序一
2.程序二
三. 如何写出容易调试的代码
(1)优秀的代码
(2)示例:模拟strcpy函数
(3)练习:模拟strlen函数
四. 常见的编程错误
1.编译型错误(语法问题)
2.链接型错误(标识符不存在,拼写错误)
3.运行型错误
一. 调试的基本概念
1. 调试的基本步骤
发现程序错误的存在
以隔离、消除等方式对错误进行定位(一部分一部分看)
确定错误产生原因
纠正错误的解决方法
对程序错误予以改正
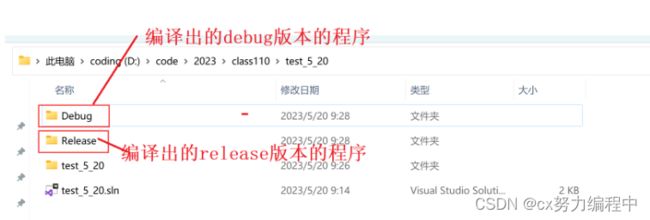
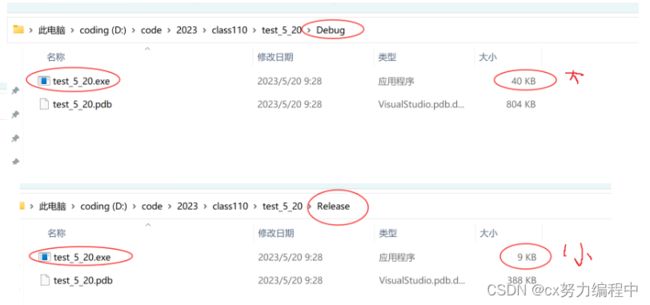
2. debug和release
debug通常称为调试版本,包含调试信息且不做任何优化。
release称为发布版本,进行了各种优化使得程序再代码大小和运行速度上都是最优的,以便用户很好的使用。
开发软件:1.立项 2.需求收集和分析 3.设计 4.开发 5.测试 6.验收 7.发布-上线
在debug模式下
写上一个代码,按F10可以进行调试
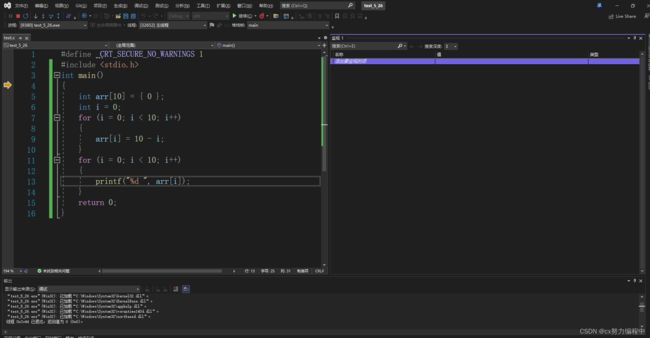
按F11往下遍历代码
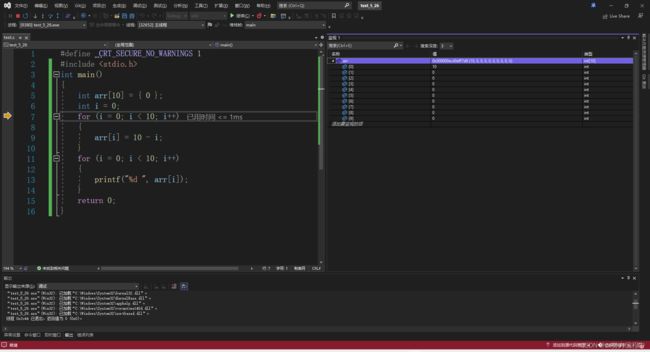 整个程序走完之后
整个程序走完之后
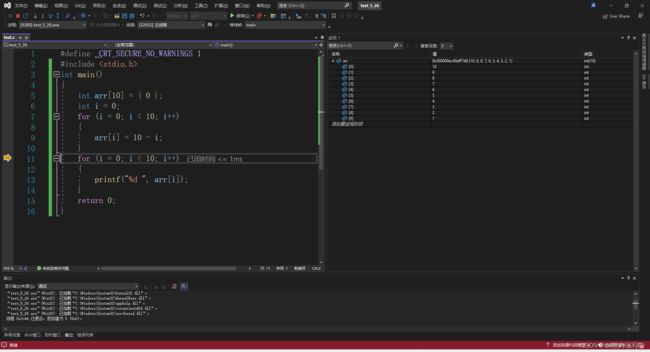
但是当我们切换到release的时候
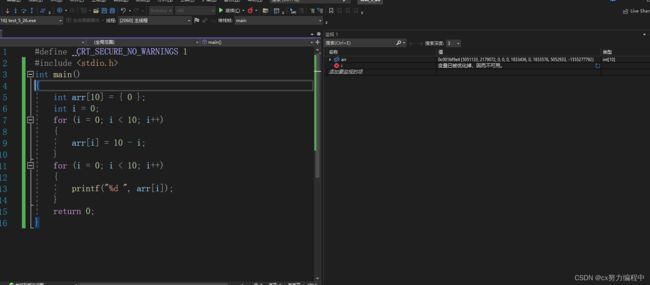
我们发现这个代码无法一步一步调试,因为release的版本没有调试信息。
当我们找到这个文件地址,如图
3.调试方法
要记住这些快捷键

(1)F10和F11
在普通的代码如
#include
int main()
{
int arr[10] = { 0 };
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = 10 - i;
}
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
} 这种代码F10和F11的区别不大
但是遇到多函数代码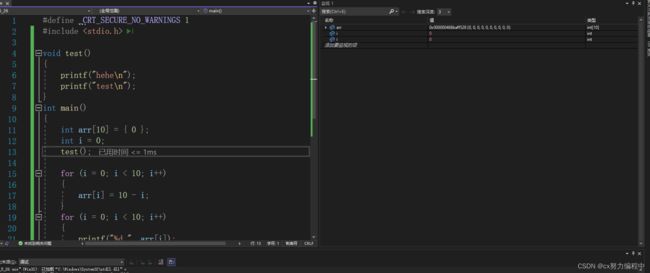
当光标停在test()函数时,再按一下F10,直接跳到main函数的下一条语句,同时屏幕打印hehe和test

但是当我们遇到这个函数的时候按F11,我们就能进入这个函数

所以F11更加细致,会进入函数观察函数的执行过程
F10遇到函数就调用,直接执行完成
(2)F5和F9
还是上面的程序,如果我们只按F5,我们会发现程序一秒钟就走完了,根本不给你调试的机会
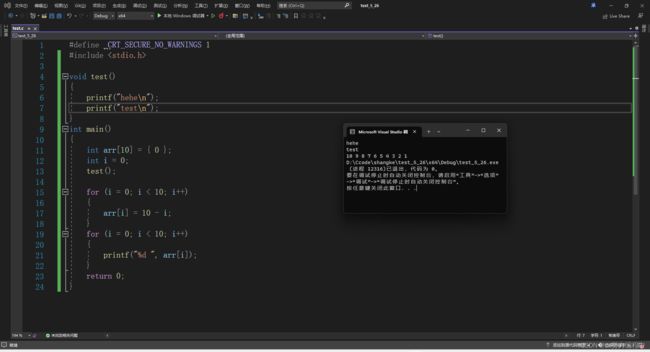
这是因为没有人拦着它,而想要实现拦路虎的功能就需要F9断点出马了
假设我们的代码问题出现在第21行
那我们就在21行的时候按一个F9
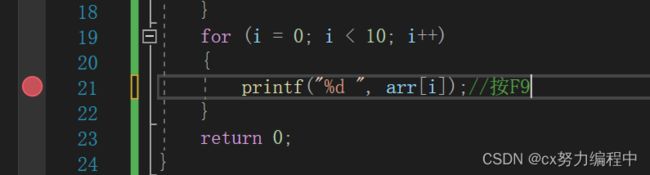
这个红色的点就是断点,按F5,程序快速执行来到第21行
 来到这里不断按F10就可以遍历代码调试了
来到这里不断按F10就可以遍历代码调试了
如果有两个断点像这样
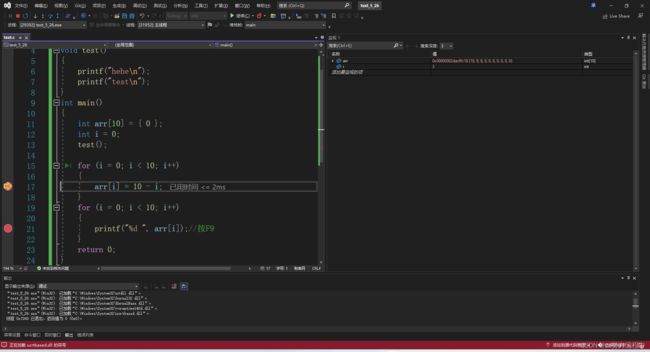
在第一个断点处按F5是不会跳到第二个断点的(需要走完这个循环才能跳到下一个断点),这时候需要你取消掉一个断点,在原来设置断点的那一行再按一次F9就能取消断点了
如果在断点处的循环我不想从第一个开始循环怎么办呢
鼠标右击断点

选择条件,设置i==5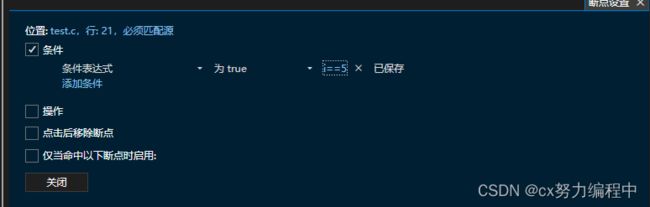 再按F5就从第五次开始了
再按F5就从第五次开始了

注意:ctrl+F5直接执行,不调试
4.调试的时候查看程序当前信息
(1)非常好用的监视窗口
F10调试之后点击调试-->窗口-->监视-->随便哪个监视窗口都行
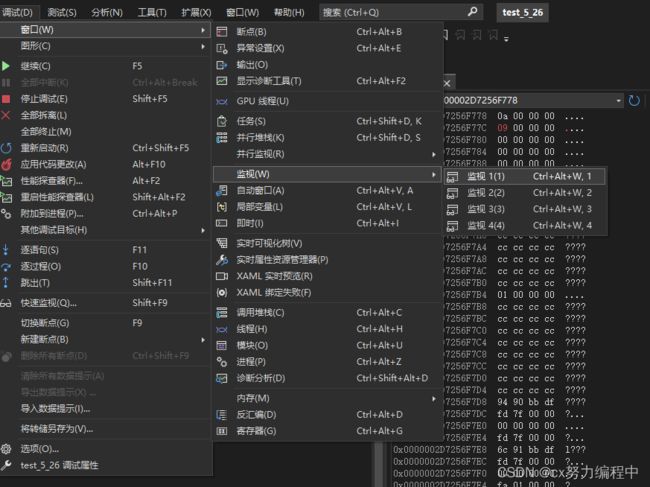
(2)内存窗口
如图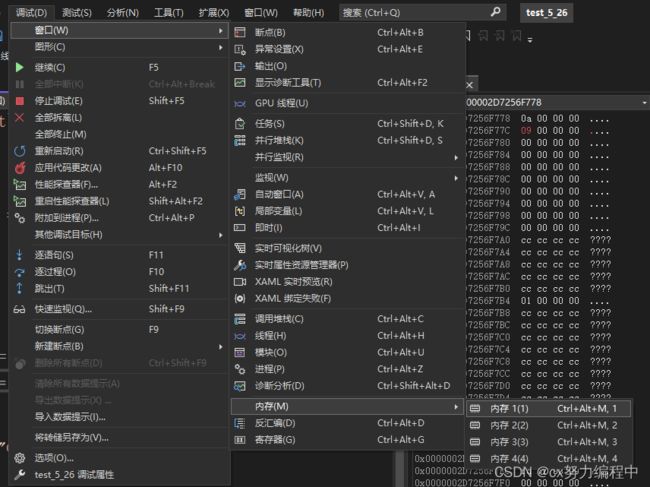
两个窗口打开后,往里面输入参数
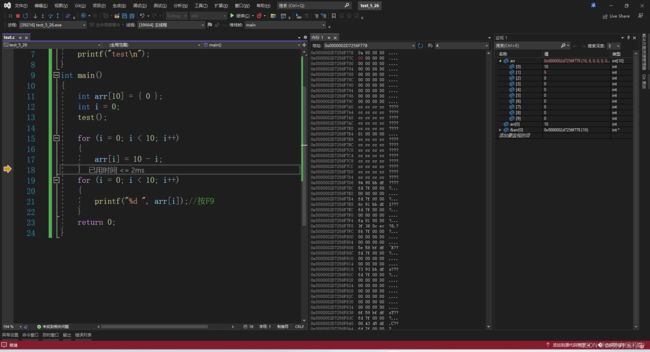
可以看到内存前十个地址的值与监视窗口的前十个元素的值相对应
给出一段代码
void test2()
{
printf("test2\n");
}
void test1()
{
test2();
}
void test()
{
test1();
}
int main()
{
test();
}现在想看这段代码的函数调用逻辑
我们可以用调试里面的调用堆栈来看
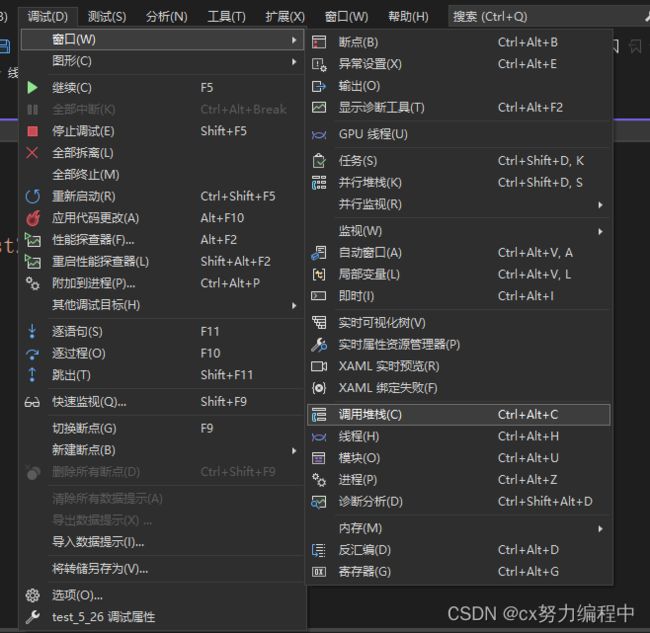
这里F10和F11结合操作
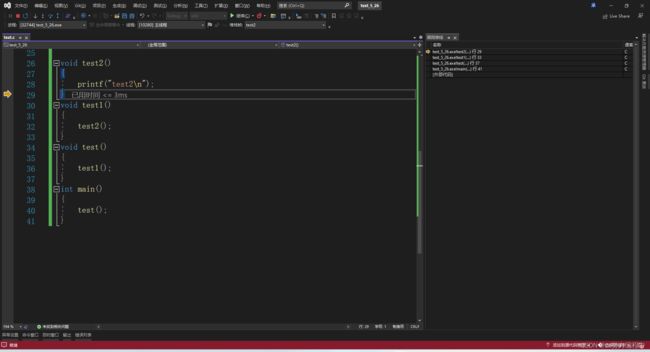
在这里再按一次F10离开test2函数
调用堆栈只剩下三个函数

这是栈LIFO(Last in first out)的特点导致的,test2最慢调用,也最快被使用完
5.查看寄存器信息
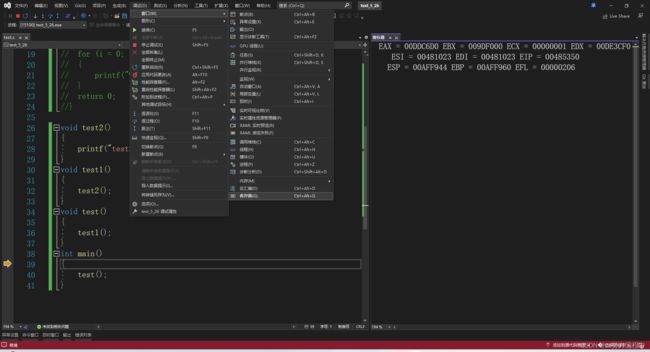
二. 调试示例
1.程序一
int main()
{
int i = 0;
int sum = 0;//保存最终结果
int n = 0;
int ret = 1;//保存n的阶乘
scanf("%d", &n);
for (i = 1; i <= n; i++)
{
int j = 0;
for (j = 1; j <= i; j++)
{
ret *= j;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}我们的思路:在这个程序里面,我们用sum记录最终结果,ret记录n的阶乘结果。每次循环计算ret的值然后再累加到sum里面
正常情况下,我们输入3,程序结果理应是1+2+6=9对吧
结果却是: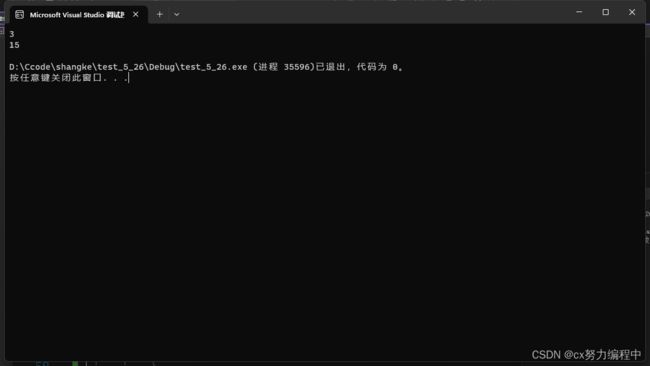
这是为什么呢?我们用调试来找找问题,F10后打开监视窗口

不停按F10我们发现问题出现在j的第三次循环里
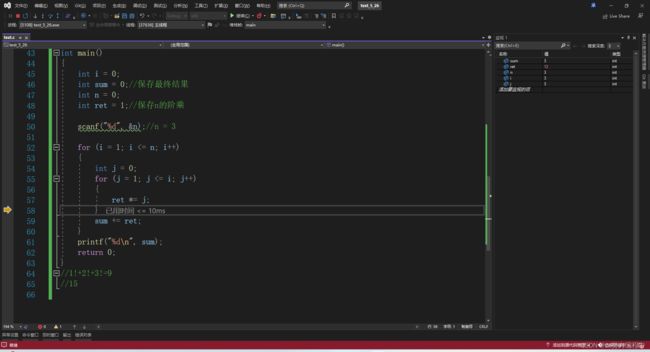
3!=6但是这里显示3!= 12
再观察一下程序,ret的初始在循环外部,这就有问题了
每次j循环前ret没有初始化成1,继续使用上一次循环的ret的值,上一次循环ret = 2,程序使用了这个2乘上3!就等于12了
所以每次循环前我们都要将ret修改成1.
修改程序:
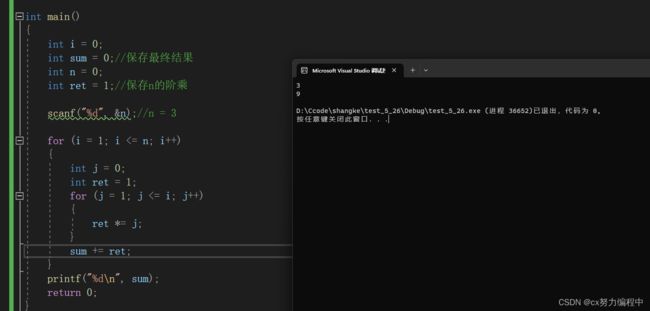
这样就没问题啦~
2.程序二
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}这段代码没有语法错误,但是打印结果死循环了
我们马上打开调试来一探究竟
监视输入arr和i,不停按F10
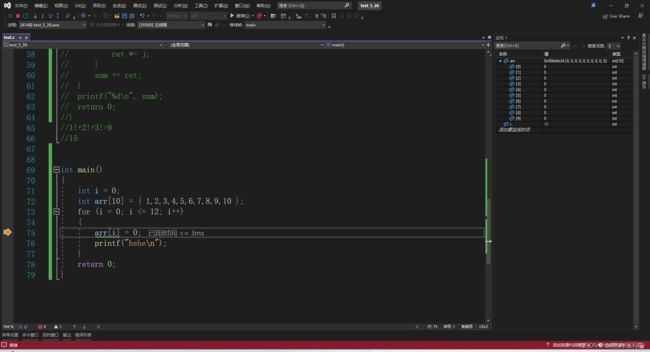
当i = 10,也就是超过数组下标上限时,我们输入arr[10]看看值等于多少
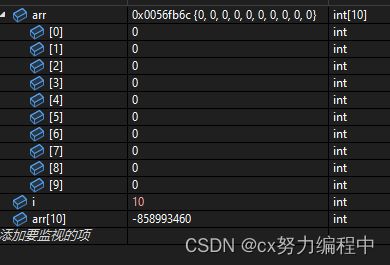
可以看出arr[10]不存在
但是再按一遍F10,好家伙,程序自动把arr[10]改成0了

我们再试一下11和12,发现结果一样

我们再输入i和arr[12]的取地址
![]()
我们发现这两个的地址居然一样,这下真相大白了,i和arr[12]占用同样的空间导致了死循环
i和arr是局部变量,是放在内存中的栈区上的。
栈区内存的使用习惯:先使用高地址处的空间,再使用低地址处的空间
又因为数组随着下标的增长,地址由低到高变化,虽然数组下标越界了,但只要i还在范围内,就会不断把arr越界下标处的值改成0。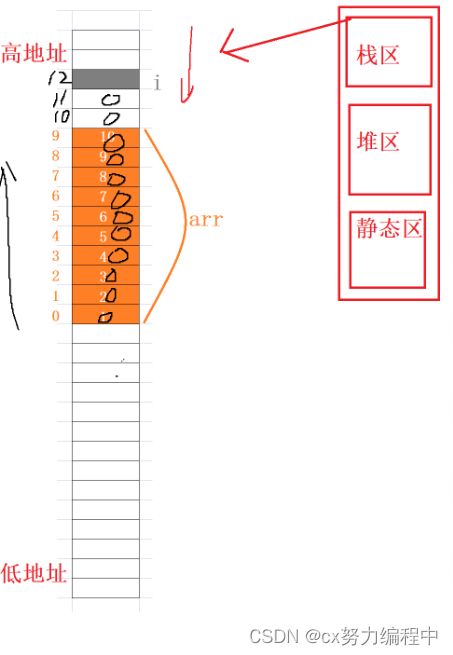
直到第12个,arr[12]和i地址相同的时候,越界访问直接访问到i去了,在把arr[12]改成0的时候也顺便把i改成0,i又经历一次循环,又被改成0,死循环了。
release模式下,代码会自动优化,直接帮助我们规避死循环

具体是怎么规避的呢,我们调用i,arr[0]和arr[9]的地址来观察一下

debug模式下i处于高地址,而arr处于低地址,容易发生死循环
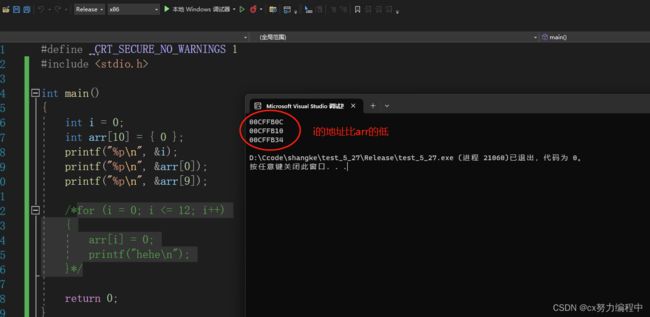
release模式下,arr地址比i高,arr怎么越界访问也无法与i的地址相同,规避了死循环

三. 如何写出容易调试的代码
(1)优秀的代码
1.使用assert
2.尽量使用const
3.养成良好的代码风格
4.添加必要的注释
5.避免代码陷阱
(2)示例:模拟strcpy函数
char * strcpy( char * destination, const char * sourse)
有两个参数,实现把第二个参数(源的)内容拷贝到第一个参数(目标空间地址的)内容里面
#include
int main()
{
char arr1[] = "hello bit";
char arr2[20] = { 0 };
strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
} 现在我们要模拟这个函数写一个与其功能相同的函数
我们需要给新韩淑传入两个指针*dest和*src,*dest负责遍历arr1里面的内容,*src负责遍历arr2里面的内容,*dest每遍历一个字符就拷贝到*src里面。也就是说,我们需要一个循环。
要注意,字符串后面的\0也需要拷贝,所以在遍历循环之后还要加一条*dest = *src来拷贝\0
void my_strcpy(char* dest, char* src)
{
while (*src != '\0')
{
*dest = *src;
dest++;
src++;
}
*dest = *src;// \0 的拷贝
}后面就是主函数的函数调用什么的,此处省略
这个代码写完了,但这个是一个好的代码吗,那可不见得
试想一下,如果用户传入一个空指针,而对空指针进行解引用是有问题的,会让程序崩溃

所以我们要对空指针进行防护
①我们可以采用assert断言语句告诉我们程序会在哪一行崩溃(定位错误消息)

②进行一个小优化,参考srcpy原函数的定义
#include //assert的头文件
//函数返回的是目标空间的起始地址
//
char* my_strcpy(char* dest, char* src)
{
char* ret = dest;
//断言
assert(dest != NULL);
assert(src != NULL);
while (*dest++ = *src++)//代码优化 3行变1行
;//空语句 -- 当这里需要一条语句但这条语句不需要干任何事情的时候,就使用空语句
//return dest;//这里不能返回dest,因为dest作为指针一直在加到数组后面去了,不是起始位置了
//而递归需要返回起始地址
return ret;
}
int main()
{
char arr1[] = "hello bit";
char arr2[20] = "xxxxxxxxxxxxx";
char* p = NULL;
/*my_strcpy(p, arr1);
printf("%s\n", p);*/
printf("%s\n", my_strcpy(arr2, arr1));//这里能直接调用需要前面的函数是char*类型
return 0;
} ③现在又发现一个问题:有些程序员写代码写着写着糊涂了,把*dest和*src的位置搞反了,导致虽然程序不报错,但是拷贝的是错误内容
如果我们在形参char* src的左边加一个const,系统将会自动给你报错
char* my_strcpy(char* dest, const char* src)![]()
这是为什么呢?
先来看一个例子
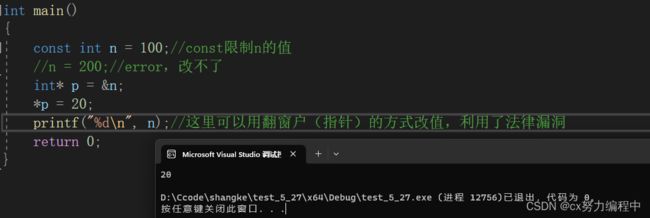
那怎么做才能修补这个法律漏洞呢?
我们可以直接在int* p前面加一个const他就打印不了了
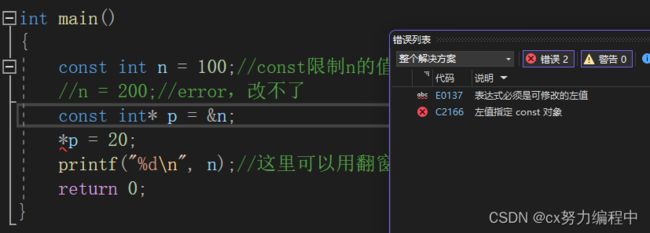
通过这个例子,我们知道,const不仅能修饰常数,也能修饰指针,限制指针的值
const 修饰指针的时候
当const 放在*的左边的时候,限制的是指针指向的内容,不能通过指针变量改变指针指向的内容,但是指针变量的本身是可以改变的
当const 放在*的右边的时候,限制的是指针变量本身,指针变量的本身是不能改变的,但是指针指向的内容是可以通过指针来改变的
拿一个简单的例子来说明一下

现在有一个女孩p,两个男孩m和n
女孩p和一个兜里有10块钱的男孩m逛街,女孩跟男孩说我想吃凉皮,一份凉皮10块钱(女孩一旦购买就花光了m的10块钱,也就是*p = 0),男孩m摸了摸兜里的10块钱,说不行,这时相当于给int *p的前面加了const,限制女孩购买凉皮这个行为(也就是说*p = 0 err)。女孩认为男孩m太抠了,决定换男朋友n,这个动作(p = &n)在此时ok。
男孩m后悔了,请p吃凉皮博回女孩(*p = 0 ok),并限制女孩p以后不能换男朋友了(int * const p),所以女孩p换男朋友n的行为此时是错误的(p = &n err)

如果男孩m很强势,既不给女孩卖凉皮也不给她换男朋友n(const int * const p ),那女孩的两种行为将不被允许(*p = 0 err , p = &n err)。
通过这个例子,我们发现const有一个保护的作用,回到原函数,我们不希望*src被人修改,所以我们用const限制*src,一旦内容修改立即报错。
(3)练习:模拟strlen函数
依葫芦画瓢就行了,可以自己先想一下再看答案

size_t my_strlen(const char* str)
{
assert(str != NULL);
int count = 0;
while (*str)
{
count++;
str++;
}
return count;
}
int main()
{
char arr[] = "abc";
int len = my_strlen(arr);
printf("%zd\n", len);
return 0;
}上面的size_t是专门为sizeof设计的一种类型,本质是unsigned int/unsigned long
四. 常见的编程错误
1.编译型错误(语法问题)
双击错误信息就能解决问题
2.链接型错误(标识符不存在,拼写错误)
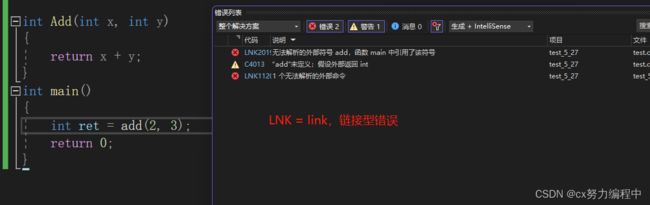
3.运行型错误
只能借助调试定位问题