Kafka 时间轮算法
文章目录
- 前言
- Java 任务调度
-
- Timer
- DelayedWorkQueue的最小堆实现
- 时间轮
-
- Kafka中时间轮实现
前言
Kafka中存在大量的延时操作。
- 发送消息-超时+重试机制的延时。
- ACKS 确认机制的延时。
Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer)
JDK的Timer和DelayQueue插入和删除操作的平均时间复杂度为O(log(n)),并不能满足Kafka的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为O(1)。
时间轮的应用并非Kafka独有,其应用场景还有很多,在Netty、Akka、Quartz、Zookeeper等组件中都存在时间轮的踪影。
Java 任务调度
给假设有1000个任务,都是不同的时间执行的,时间精确到秒,你怎么实现对所有的任务的调度?
第一种思路是启动一个线程,每秒钟对所有的任务进行遍历,找出执行时间跟当前时间匹配的,执行它。如果任务数量太大,遍历和比较所有任务会比较浪费时间。
第二个思路,把这些任务进行排序,执行时间近(先触发)的放在前面。这里会涉及到大量的元素移动(新加入任务,任务执行–删除任务之类,都需要重新排序)
Timer
JDK包里面自带了一个Timer工具类(java.util包下),可以实现延时任务(例如30分钟以后触发),也可以实现周期性任务(例如每1小时触发一次)。
它的本质是一个优先队列(TaskQueue),和一个执行任务的线程(TimerThread)。
普通的队列是一种先进先出的数据结构,元素在队尾追加,而从队头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。通常采用堆数据结构来实现。
在这个优先队列中,最先需要执行的任务排在优先队列的第一个。然后 TimerThread 不断地拿第一个任务的执行时间和当前时间做对比。如果时间到了先看看这个任务是不是周期性执行的任务,如果是则修改当前任务时间为下次执行的时间,如果不是周期性任务则将任务从优先队列中移除。最后执行任务。
但是Timer是单线程的,在很多场景下不能满足业务需求。
在JDK1.5之后,引入了一个支持多线程的任务调度工具ScheduledThreadPoolExecutor用来替代TImer,它是几种常用的线程池之一,里面是一个延迟队列DelayedWorkQueue,也是一个优先队列。

DelayedWorkQueue的最小堆实现
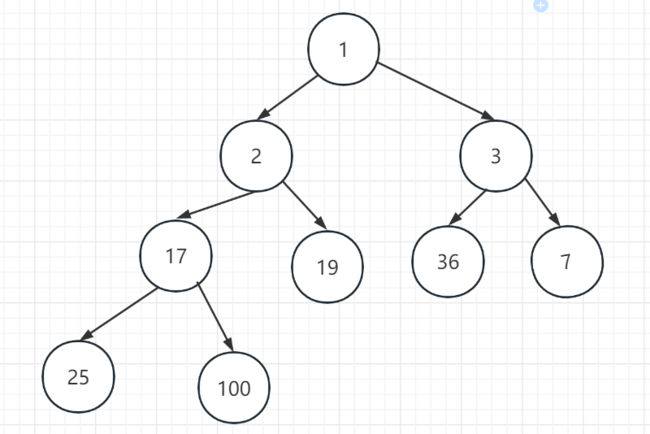
优先队列的使用的是最小堆实现。
最小堆的含义: 一种完全二叉树,父结点的值小于或等于它的左子节点和右子节点
比如插入以下的数据 [1,2,3,7,17,19,25,36,100]
最小堆就长成这个样子。
优先队列的插入和删除的时间复杂度是O(logn),当数据量大的时候,频繁的入堆出堆性能不是很好。
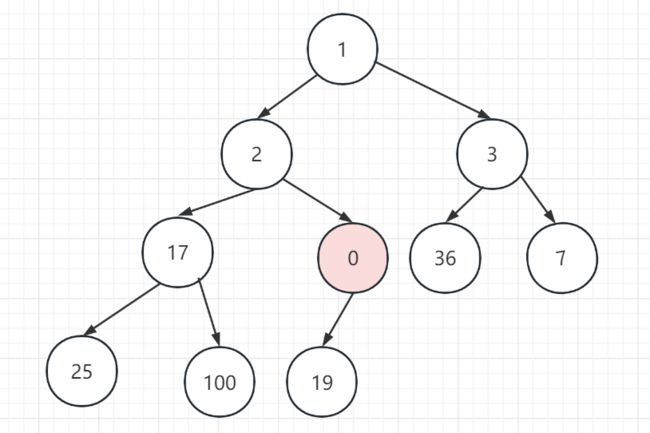
比如要插入0,过程如下:
-
插入末尾元素

-
0比19小,所以要向上移动且互换。
-
0比2小,所以要向上移动且互换。
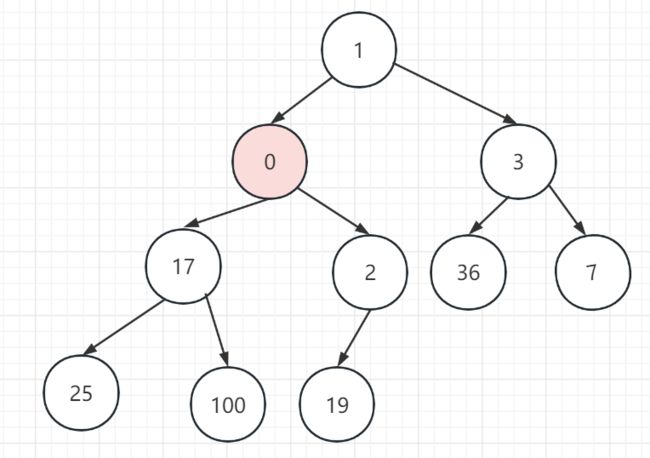
4、0比2小,所以要向上移动且互换。

算法复杂度
N个数据的最小堆, 共有logN层, 最坏的情况下, 需要移动logN次
时间轮
时间轮先考虑对所有的任务进行分组,把相同执行时刻的任务放在一起。比如下图,数组里面的一个下标就代表1秒钟。它就会变成一个数组加链表的数据结构。分组以后遍历和比较的时间会减少一些。
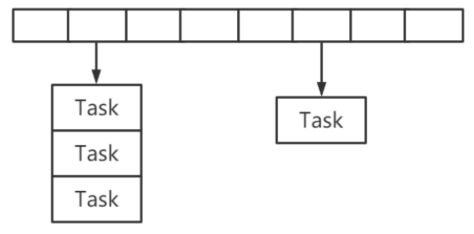
但是还是有问题,如果任务数量非常大,而且时间都不一样,或者有执行时间非常遥远的任务,那这个数组长度是不是要非常地长?比如有个任务2个月之后执行,从现在开始计算,它的下标是5253120。
所以长度肯定不能是无限的,只能是固定长度的。比如固定长度是8,一个格子代表1秒(现在叫做一个bucket槽),一圈可以表示8秒。遍历的线程只要一个格子一个格子的获取任务,并且执行就OK了。
固定长度的数组怎么用来表示超出最大长度的时间呢?可以用循环数组。
比如一个循环数组长度8,可以表示8秒。8秒以后执行的任务怎么放进去?只要除以8,用得到的余数,放到对应的格子就OK了。比如10%8=2,它放在第2个格子。这里就有了轮次的概念,第10秒的任务是第二轮的时候才执行。

这时候,时间轮的概念已经出来了。
如果任务数量太多,相同时刻执行的任务很多,会导致链表变得非常长。这里我们可以进一步对这个时间轮做一个改造,做一个多层的时间轮。
比如:最内层8个格子,每个格子1秒;外层8个格子,每个格子8*8=64秒;最内层走一圈,外层走一格。这时候时间轮就跟时钟更像了。随着时间流动,任务会降级,外层的任务会慢慢地向内层移动。

时间轮任务插入和删除时间复杂度都为O(1),应用范围非常广泛,更适合任务数很大的延时场景。Dubbo、Netty、Kafka中都有实现。
Kafka中时间轮实现
Kafka里面TimingWheel的数据结构

kafka会启动一个线程,去推动时间轮的指针转动。其实现原理其实就是通过queue.poll()取出放在最前面的槽的TimerTaskList


添加新的延迟任务

往时间轮添加新的任务

时间轮指针的推进

第二层时间轮的创建代码如下
