docker部署监控系统prometheus实战
一 介绍
通过docker部署prometheus、node-exporter、alertmanager和grafana。
Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区。Prometheus 于2016年加入了 Cloud Native Computing Foundation,这是继Kubernetes之后的第二个托管项目。
官网:https://prometheus.io
Exporter是一个采集监控数据并通过Prometheus监控规范对外提供数据的组件,能为Prometheus提供监控的接口。
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。不同的Exporter负责不同的业务。
- Prometheus 开源的系统监控和报警框架,灵感源自Google的Borgmon监控系统
- AlertManager 处理由客户端应用程序(如Prometheus server)发送的警报。它负责将重复数据删除,分组和路由到正确的接收者集成,还负责沉默和抑制警报
- Node_Exporter 用来监控各节点的资源信息的exporter,应部署到prometheus监控的所有节点
- prometheus-webhook-dingtalk 钉钉告警插件
- grafana 监控可视化
二 环境准备
docker部署
拉取最新的docker镜像
2.1 安装node-exporter
docker pull prom/node-exporter:latest docker run -d -p 9100:9100 --name node-exporter prom/node-exporter:latest docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 95252704e558 prom/node-exporter:latest "/bin/node_exporter" 3 seconds ago Up 2 seconds 0.0.0.0:9100->9100/tcp node-exporter netstat -lntp |grep docker tcp6 0 0 :::9100 :::* LISTEN 9076/docker-proxy |
2.2 安装alertmanager&prometheus-webhook-dingtalk
mkdir /data/prom && cd /data/prom
docker pull prom/alertmanager:latest
docker pull timonwong/prometheus-webhook-dingtalk #钉钉告警
vim config.yml
targets:
webhook:
url: ******** #修改为钉钉机器人的webhook
mention:
all: true
vim alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: '****:465' #邮箱smtp服务器代理,启用SSL发信, 端口一般是465
smtp_from: '****' #发送邮箱名称
smtp_auth_username: '****' #邮箱名称
smtp_auth_password: '********' #邮箱密码或授权码
smtp_require_tls: false
route:
receiver: 'default'
group_wait: 10s
group_interval: 1m
repeat_interval: 1h
group_by: ['alertname']
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'instance']
receivers:
- name: 'default'
email_configs:
- to: '*******@qq.com' #接受者邮箱
send_resolved: true
webhook_configs:
- url: 'http://****:8060/dingtalk/webhook/send' #alterdingtalk的ip地址
send_resolved: true
|
docker run -d -p 8060:8060 -v /data/prom/config.yml:/etc/prometheus-webhook-dingtalk/config.yml --name alertdingtalk timonwong/prometheus-webhook-dingtalk
docker run -d -p 9093:9093 -p 9094:9094 -v /data/prom/alertmanager.yml:/etc/alertmanager/alertmanager.yml --name alertmanager prom/alertmanager:latest2.3 安装prometheus
mkdir -p /data/prom/prometheus && chmod 777 /data/prom/prometheus && cd /data/prom docker pull prom/prometheus:latest |
####配置告警规则
vim alert-rules.yml
groups:
- name: node-alert
rules:
- alert: NodeDown
expr: up{job="node"} == 0
for: 5m
labels:
severity: critical
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} down"
description: "Instance: {{ $labels.instance }} 已经宕机 5分钟"
value: "{{ $value }}"
- alert: NodeCpuHigh
expr: (1 - avg by (instance) (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m]))) * 100 > 80
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} cpu使用率过高"
description: "CPU 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeCpuIowaitHigh
expr: avg by (instance) (irate(node_cpu_seconds_total{job="node",mode="iowait"}[5m])) * 100 > 50
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} cpu iowait 使用率过高"
description: "CPU iowait 使用率超过 50%"
value: "{{ $value }}"
- alert: NodeLoad5High
expr: node_load5 > (count by (instance) (node_cpu_seconds_total{job="node",mode='system'})) * 1.2
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} load(5m) 过高"
description: "Load(5m) 过高,超出cpu核数 1.2倍"
value: "{{ $value }}"
- alert: NodeMemoryHigh
expr: (1 - node_memory_MemAvailable_bytes{job="node"} / node_memory_MemTotal_bytes{job="node"}) * 100 > 90
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} memory 使用率过高"
description: "Memory 使用率超过 90%"
value: "{{ $value }}"
- alert: NodeDiskRootHigh
expr: (1 - node_filesystem_avail_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/"} / node_filesystem_size_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/"}) * 100 > 90
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/ 分区) 使用率过高"
description: "Disk(/ 分区) 使用率超过 90%"
value: "{{ $value }}"
- alert: NodeDiskBootHigh
expr: (1 - node_filesystem_avail_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/boot"} / node_filesystem_size_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/boot"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/boot 分区) 使用率过高"
description: "Disk(/boot 分区) 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeDiskReadHigh
expr: irate(node_disk_read_bytes_total{job="node"}[5m]) > 20 * (1024 ^ 2)
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 读取字节数 速率过高"
description: "Disk 读取字节数 速率超过 20 MB/s"
value: "{{ $value }}"
- alert: NodeDiskWriteHigh
expr: irate(node_disk_written_bytes_total{job="node"}[5m]) > 20 * (1024 ^ 2)
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 写入字节数 速率过高"
description: "Disk 写入字节数 速率超过 20 MB/s"
value: "{{ $value }}"
- alert: NodeDiskReadRateCountHigh
expr: irate(node_disk_reads_completed_total{job="node"}[5m]) > 3000
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk iops 每秒读取速率过高"
description: "Disk iops 每秒读取速率超过 3000 iops"
value: "{{ $value }}"
- alert: NodeDiskWriteRateCountHigh
expr: irate(node_disk_writes_completed_total{job="node"}[5m]) > 3000
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk iops 每秒写入速率过高"
description: "Disk iops 每秒写入速率超过 3000 iops"
value: "{{ $value }}"
- alert: NodeInodeRootUsedPercentHigh
expr: (1 - node_filesystem_files_free{job="node",fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_files{job="node",fstype=~"ext4|xfs",mountpoint="/"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/ 分区) inode 使用率过高"
description: "Disk (/ 分区) inode 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeInodeBootUsedPercentHigh
expr: (1 - node_filesystem_files_free{job="node",fstype=~"ext4|xfs",mountpoint="/boot"} / node_filesystem_files{job="node",fstype=~"ext4|xfs",mountpoint="/boot"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/boot 分区) inode 使用率过高"
description: "Disk (/boot 分区) inode 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeFilefdAllocatedPercentHigh
expr: node_filefd_allocated{job="node"} / node_filefd_maximum{job="node"} * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} filefd 打开百分比过高"
description: "Filefd 打开百分比 超过 80%"
value: "{{ $value }}"
- alert: NodeNetworkNetinBitRateHigh
expr: avg by (instance) (irate(node_network_receive_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]) * 8) > 20 * (1024 ^ 2) * 8
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} network 接收比特数 速率过高"
description: "Network 接收比特数 速率超过 20MB/s"
value: "{{ $value }}"
- alert: NodeNetworkNetoutBitRateHigh
expr: avg by (instance) (irate(node_network_transmit_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]) * 8) > 20 * (1024 ^ 2) * 8
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} network 发送比特数 速率过高"
description: "Network 发送比特数 速率超过 20MB/s"
value: "{{ $value }}"
- alert: NodeNetworkNetinPacketErrorRateHigh
expr: avg by (instance) (irate(node_network_receive_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m])) > 15
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 接收错误包 速率过高"
description: "Network 接收错误包 速率超过 15个/秒"
value: "{{ $value }}"
- alert: NodeNetworkNetoutPacketErrorRateHigh
expr: avg by (instance) (irate(node_network_transmit_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m])) > 15
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 发送错误包 速率过高"
description: "Network 发送错误包 速率超过 15个/秒"
value: "{{ $value }}"
- alert: NodeProcessBlockedHigh
expr: node_procs_blocked{job="node"} > 10
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 当前被阻塞的任务的数量过多"
description: "Process 当前被阻塞的任务的数量超过 10个"
value: "{{ $value }}"
- alert: NodeTimeOffsetHigh
expr: abs(node_timex_offset_seconds{job="node"}) > 3 * 60
for: 2m
labels:
severity: info
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 时间偏差过大"
description: "Time 节点的时间偏差超过 3m"
value: "{{ $value }}"
|
#配置prometheus.yml
vim prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.1.1:9093
rule_files:
- "*rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.1.1:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.1.1:9100']
- job_name: 'alertmanager'
static_configs:
- targets: ['192.168.1.1:9093']
- job_name: 'java'
scrape_interval: 10s
static_configs:
- targets: ['192.168.1.1:6060']
labels:
instance: 'java-server1'
- targets: ['192.168.1.1:8000']
labels:
instance: 'java-server2' |
#启动容器
docker run -d -p 9090:9090 -v /data/prom/prometheus.yml:/etc/prometheus/prometheus.yml -v /data/prom/alert-rules.yml:/etc/prometheus/alert-rules.yml -v /data/prom/prometheus:/prometheus --name prometheus prom
2.4 安装grafana #图形化
mkdir -p /data/grafana-storage && chmod 777 /data/grafana-storage docker pull grafana/grafana:latest docker run -d -p 3000:3000 --name=grafana -v /data/grafana-storage:/var/lib/grafana grafana/grafana |
三 界面配置
3.1 https://grafana.com/grafana/dashboards
导入模板8919

3.4 数据大盘 服务器监控/jvm监控

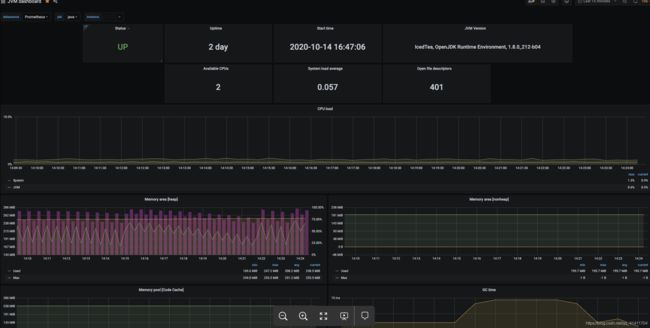
四 告警方式
4.1 邮件告警
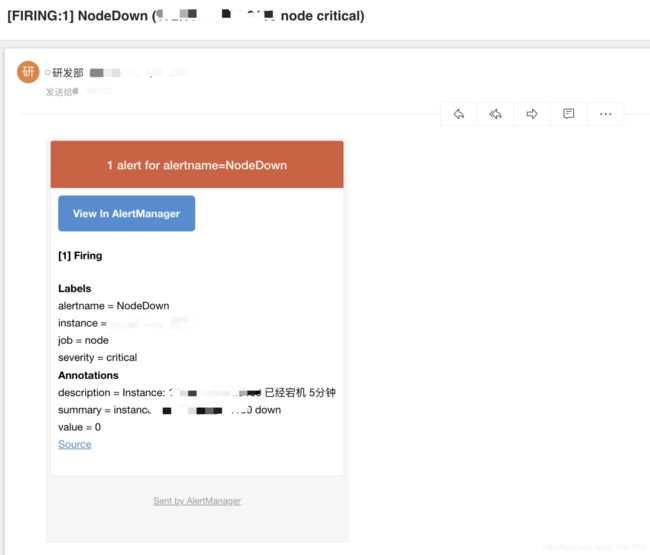
4.2钉钉告警
