个人项目
一、题目简介
一套完整的编码译码系统应该具有以下功能:
(1)I:初始化(initialization)。从终端读入字符集大小n,以及n个字符和n个权值,建立赫夫曼树。并将他存于文件hfmtree.txt中。
(2)E:编码(encoding)。利用已经建立好的赫夫曼树(如不在内存,则从文件hfmtree.txt中读入),对文件tobetree.txt中的正文进行编码。然后将结果存入文件codefile.txt文件中。
(3)D:译码(decoding)。利用已经建立好的赫夫曼树将文件codefile.txt中的代码进行译码,将结果存入文件textfile.txt中。
(4)P:印代码文件(print)。将文件codefile.txt以紧凑格式显示在终端上。每行50个代码。同时将字符形式的编码文件写入到文件codeprin.txt中。
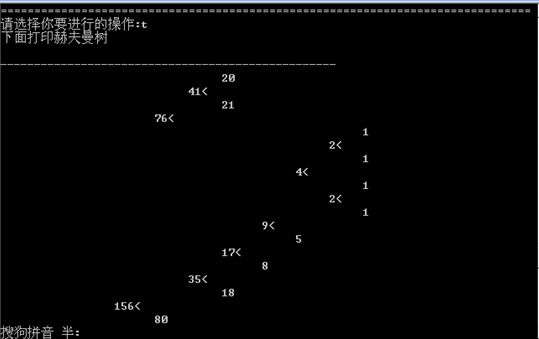
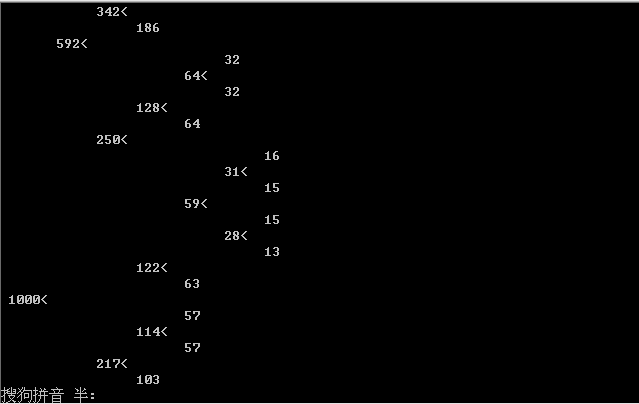
(5)T:印赫夫曼树(treeprint)。将已在内存中的赫夫曼树以直观的方式(树或凹入表形式)显示在终端上,同时将此字符形式的赫夫曼树写入文件treeprin.txt中。
二、源码的github链接
https://github.com/sunjing2013/Test/tree/master
三、所设计的模块测试用例、测试结果截图
2 概要设计
2.1 设计思想
赫夫曼树用邻接矩阵作为存储结构,借助静态链表来实现遍历。
2.2 函数间的关系
函数间的关系如图所示:
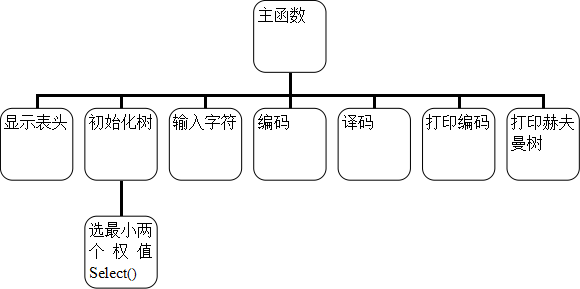
2.3 数据结构与算法设计
赫夫曼编\译码器的主要功能是先建立赫夫曼树,然后利用建好的赫夫曼树生成赫夫曼编码后进行译码 。
在数据通信中,经常需要将传送的文字转换成由二进制字符0、1组成的二进制串,称之为编码。构造一棵赫夫曼树,规定赫夫曼树中的左分之代表0,右分支代表1,则从根节点到每个叶子节点所经过的路径分支组成的0和1的序列便为该节点对应字符的编码,称之为赫夫曼编码。
最简单的二进制编码方式是等长编码。若采用不等长编码,让出现频率高的字符具有较短的编码,让出现频率低的字符具有较长的编码,这样可能缩短传送电文的总长度。赫夫曼树课用于构造使电文的编码总长最短的编码方案。
赫夫曼树编\译码器流程图:
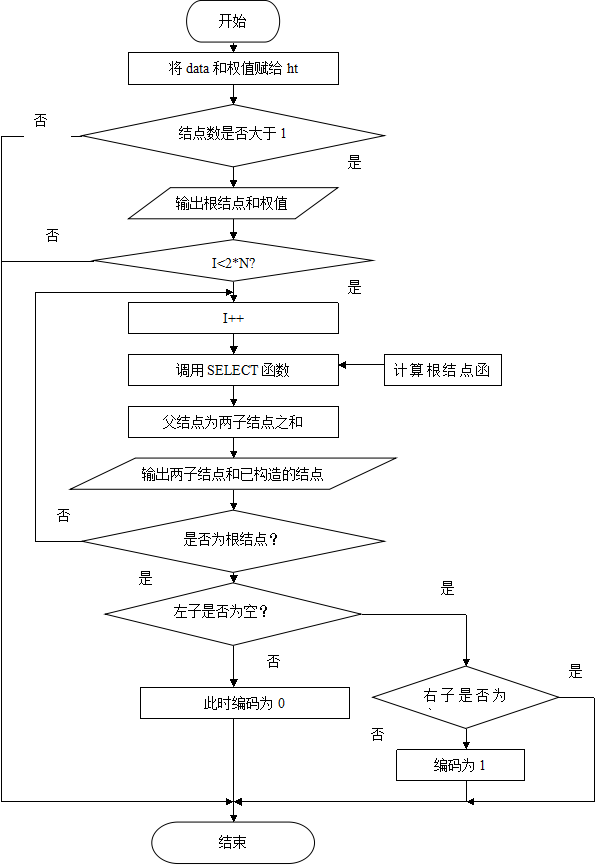
4 详细设计
赫夫曼树编、译码设计功能如下:
1.赫夫曼树抽象数据类型定义
ADT HuffmanCoding{
数据对象T:具有相同特性的数据元素的集合
数据关系R:满足最优二叉树的关系
基本操作P:
Init(&t)
操作结果:构造一个空赫夫曼树t。
encode()
操作结果:利用赫夫曼树进行编码
Decode()
操作结果:利用赫夫曼树进行译码
}
2. 主函数
Void mian()
{打印表头;
While(选择项不为q){
输入选择项;
Switch(选择项)
{Case i: 初始化;break;
Case w: 输入要编码的字符; break;
Case e: 编码字符; break;
Case d; 译码操作;break;
Case p; 打印代码;break;
Case t; 打印赫夫曼树; break;
Default:输入错误,重新选择;
}
3. 求赫夫曼编码[5]
if(t[j].weight<k&&t[j].parent==0)
k=t[j].weight,flag=j; //flag为标志符,为不小于可能的值
t[flag].parent=1;
4. 建赫夫曼树
HT[s1].parent=HT[s2].parent=i;//将选好的两个结点设置成有同一个双亲结点
HT[i].lchild=s1;//左孩子的权值
HT[i].rchild=s2;//右孩子的权值
HT[i].weight=HT[s1].weight+HT[s2].weight;//将两个权值相加作为新的权值
}
HC=(HuffmanCode)malloc((n+1)*sizeof(char*));//为赫夫曼代码分配空间
5. 将赫夫曼编码写入文件
用fputs(HC[i],htmTree); fputs(r,htmTree);fclose(htmTree) 这些函数来实现编码写入文件;
6. 完成译码功能并将译码写入文件
因为赫夫曼树建好后是左孩子结点旁标上0,右孩子结点上标上1,所以碰到1是用左孩子结点,2是用右孩子结点,可以用条件语句来实现。
if(i2=='0') m=HT[m].lchild;
if(i2=='1') m=HT[m].rchild;
fputs(outext,txtfile);//将译码写入文件
4 调试分析
1.本程序要执行首先要初始化一个赫夫曼树,按照用户设定的字符集大小,输入每个字符及其对应的出现概率即权值。分别存放在w和z这两个变量中。再利用这两个变量构造赫夫曼树。
2.执行输入字符命令时,程序将用户输入的字符存入文件tobetran.txt中。以便执行下一步编码操作时自己从文件调用。
3.编码时,程序直接从tobetran.txt中读取字符,依次和字符数组变量z中元素项比较,找到之后,将编码表HC中对应编号的代码添加到分配的工作区间中,全部字符编码完成后将代码写入文件codefile.txt中。
4.译码时,程序从codefile中读取代码,按照代码从树根开始向叶子节点查找对应的字符,直到全部代码译码完成,再将译好的字符写入文件txtfile.txt中
5.打印编码操作,即从codefile.txt中读取代码,按要求输出到屏幕上。
5.用户使用说明
5.1 测试方式
1.程序运行环境为DOS
2.程序运行后,出现的界面如图所示:
3.首先须进行初始化,按“i”执行,输入字符集数,对应的字符和权值,初始化赫夫曼树。然后才能进行后续的操作。
4.选择“w”,输入要编码的字符。
5.选择“e”,对刚输入的字符进行编码。
6.选择“d”,对刚编码出的代码再译码回去。
7.选择“p”,打印编码出的代码。
8.选择“t”,代印赫夫曼树
9.选择“q”,退出程序。
6 测试结果
1.初始化的内容如表所示:
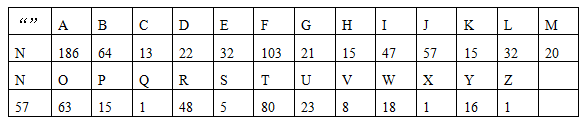
2.初始化的结果如图所示:

3.将字符对应编码写入htmtree.txt,如图所示:

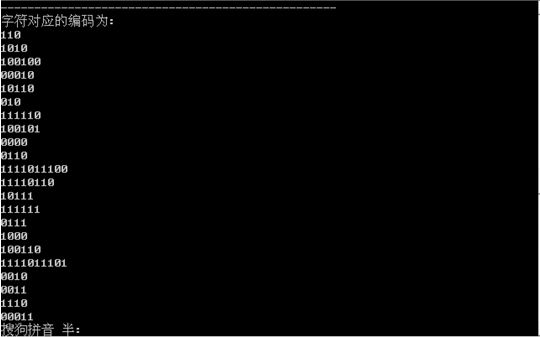
4.字符对应的编码如图所示:
5.输入要编码的字符如图所示:

6.译码:文件textfile.txt中内容:
THIS PROGRAM IS MY FAVORIT
其操作如图所示:

7.打印赫夫曼树如图所示:
四、问题及解决方案、心得体会
问题及解决方案:在课程设计中,就在编写好源代码后的调试中出现了不少的错误,遇到了很多麻烦及困难,我的调试及其中的错误和我最终找出错误,修改为正确的能够执行的程序中,通过分析,我学到了:在定义头文件时可多不可少,即我们可多写些头文件,肯定不会出错,但是若没有定义所引用的相关头文件,必定调试不通过;在执行译码操作时,不知什么原因,总是不能把要编译的二进制数与编译成的字符用连接号连接起来,而是按顺序直接放在一起,视觉效果不是很好。
体会: 通过这次的课程设计使我对哈夫曼树以及哈夫曼编码有了更深的认识和理解,也使我更加明白哈夫曼编码译码在信息技术中的重要性和地位。在课设过程中,我深刻认识到算法的逻辑性对程序的重要影响,算法的准确度对程序运行结果的重要影响,构建最小代价生成树时,一个细微的循环控量的错误都能影响到程序的正确性,而所有的代码机制都是为一个目标的实现而运作的,所以,细致是实现算法和程序准性必不可少的。许多的错误让我明白了一个道理,细心是非常重要的。同时,对于编程者而言,思路清晰是相当重要的。做课程设计不仅让我修补了以前学习的漏洞,也让我知道一个道理:编程需要兴趣和实际动手。这应该可以借鉴在老师的教学工作上。创新思维至关重要,这不仅能让我们写出精简的代码,也有助于开发出高效的程序。