四十九.强化学习基础
1. 强化学习基础知识
1.1 强化学习简介
机器学习分为监督学习,非监督学习,强化学习(RL)。深度学习+强化学习即为深度强化学习(DRL)。
强化学习没有事先准备好的数据标签作为监督来指导学习过程,只有奖励值,通常是延后给出。
1.2强化学习的分类
从不同的角度来看,强化学习有四种分类方法。
1.2.1model-base和model-free
mode-base:状态转移概率(state transitional probability)已知。
model-free:状态转移概率(state transitional probability)未知。
1.2.2policy-based和value-based
policy-based:输出动作的概率分布。
value-based:输出动作的价值函数,永远都会去选择价值最大的动作。
1.2.3Monte-Carlo和Temporal-Difference
回合更新(Monte-Carlo):到结束的时候才更新自己的策略(在深度强化学习指相应的神经网络参数)。
单步更新(Temporal-Difference):每执行一个动作就会改变一次参数。
1.2.4on-policy与off-policy
on-policy:探索环境使用的策略和要更新的策略是同一个策略,在和环境交互的过程中更新着自己的策略。
off-policy:探索环境使用的策略和要更新的策略不是同一个策略,通过看很多历史的数据(如玩家视频)来学习策略,而没有真的与环境交互。
1.3基本概念
强化学习模型中最关键的三个部分为:状态(state)、动作(action)、奖励(reward)。一个经典的RL过程可以视为:智能体在 t t t时刻观察到一个状态 s t s_t st,执行一个动作后 a t a_t at,环境反馈给它一个奖励 r t r_t rt与新的状态 s t + 1 s_{t+1} st+1,然后智能体根据这个状态执行动作 a t + 1 a_{t+1} at+1,然后获得 r t + 1 r_{t+1} rt+1…以此类推,最终形成一个由上述三部分组成的一个序列,也就是轨迹(trajectory),又叫马尔科夫链。
状态(State):代表当前智能体所处的外界环境信息。环境状态具体的表现形式可以有很多种,例如多维数组(如xy坐标)、图像(如像素游戏)和视频等。为了更好地学习策略,外界环境的状态需要能够准确的描述外界环境,尽可能的将有效信息包括在内,通常越充足的信息越有利于算法的学习。
动作(Action):智能体在感知到所处的外界环境状态后所要采取的行为,如跳跃、奔跑、转弯等,是对外界环境的一种反馈响应。当然,动作的表现形式既可以是离散的,也可是连续的。
奖励(Reward):当智能体感知到外界环境并采取动作后所获得的奖赏值。奖励是一种变量反馈信号,代表智能体在该时刻的动作表现(如当前这个行为对整个游戏的胜负有多大的增益),而智能体的任务一般都是最大化累计奖励。
历史(History):也叫轨迹(Trajectoty),它是关于状态 s s s、动作 a a a、奖励 r r r的序列。
2.马可夫决策过程(强化学习的数学模型)
2.1基本概念
强化学习的数学模型就是马尔科夫决策过程。
2.1.1马尔科夫性(Markov property)
马尔科夫性(Markov property):系统的下一个状态 S t + 1 S_{t+1} St+1仅与当前状态 S t S_{t} St有关,而与之前的所有状态无关,即:
P [ s t + 1 ∣ s t ] = P [ S t + 1 ∣ s 1 , s 2 , s 3 , . . . , s t ] P[s_{t+1}|s_{t}]=P[S_{t+1}|s_{1},s_{2},s_{3},...,s_{t}] P[st+1∣st]=P[St+1∣s1,s2,s3,...,st]
强化学习为什么需要马尔可夫性?
真实环境中的环境转化非常复杂, 复杂到难以建模, 转化到下一个状态 S t + 1 S_{t+1} St+1不仅与上一个状态 S t S_{t} St有关, 还和上上个状态 S t − 1 S_{t-1} St−1 , 以及更之前的状态有关, 我们需要利用马尔科夫性对环境转化模型进行简化, 来帮助强化学习算法进行学习。
2.1.2马尔科夫过程(Markov process)
马尔科夫过程(Markov process):它是一个二元组 < S , P >
P = [ P 11 … P 1 n ⋮ ⋱ ⋮ P n 1 … P n n ] P=\begin{bmatrix} P_{11} & \dots & P_{1n}\\ \vdots & \ddots & \vdots\\ P_{n1} &\dots &P_{nn} \end{bmatrix} P= P11⋮Pn1…⋱…P1n⋮Pnn
其中,单行概率和为1,即:
∑ j = 1 n P i j = 1 {\textstyle \sum_{j=1}^{n}}P_{ij}=1 ∑j=1nPij=1
2.1.3马尔科夫奖励过程(Markov reward process)
马尔科夫奖励过程(Markov reward process):马尔科夫奖励过程在马尔科夫过程的基础上增加了奖励函数 R R R和衰减系数 γ \gamma γ,表示为 ( S , P , R , γ ) (S,P,R,\gamma) (S,P,R,γ)。
其中, R R R为奖励函数,它表示 S t S_t St状态下的奖励,是处在状态 s t s_t st下,在下一个时刻 t + 1 t+1 t+1能获得的奖励期望,即:
R S = E [ R t + 1 ∣ S t = s t ] R_{S} = E[R_{t+1}|S_{t} =s_{t} ] RS=E[Rt+1∣St=st]
γ \gamma γ为衰减系数,强化学习是面向未来的,离当前时刻 t t t越远,影响越小,因此,需要衰减因子来减少对当前时刻的影响。
定义折扣累计回报:从 t t t时刻所得到的折扣回报总和,即:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . = ∑ k = 0 ∞ γ k R t + k + 1 G_{t} = R_{t+1} +\gamma R_{t+2}+\gamma^{2} R_{t+3}+...= \sum_{k=0}^{\infty } \gamma^{k} R_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+...=k=0∑∞γkRt+k+1
2.1.4价值函数(value function)
价值函数(value function):它描述了当前某一状态或某一行为的长期价值,分为状态价值函数(state value function)和动作价值函数(action value function)。
两类价值函数的区别:当前状态的价值就是状态价值函数,当前做了什么动作的价值就是动作价值函数。
因此,一个马尔科夫奖励过程中某一状态价值函数 V ( s ) V(s) V(s)为从该状态开始的马尔可夫链收获的期望:
V ( s ) = E π [ G t ∣ S t = s ] V ( s ) = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s ] V ( s ) = E π [ R t + 1 + γ ( R t + 2 + γ R t + 3 + . . . ) ∣ S t = s ] V ( s ) = E π [ R t + 1 + γ G t + 1 ∣ S t = s ] V ( s ) = E π [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s ] ( 贝尔曼方程 ) \begin{align*} V(s)&=E_{\pi } [G_{t}|S_{t} =s ] \\ V(s)&=E_{\pi } [R_{t+1} +\gamma R_{t+2}+\gamma^{2} R_{t+3}+...|S_{t} =s ]\\ V(s)&=E_{\pi } [R_{t+1} +\gamma (R_{t+2}+\gamma R_{t+3}+...)|S_{t} =s ]\\ V(s)&=E_{\pi } [R_{t+1} +\gamma G_{t+1}|S_{t} =s ]\\ V(s)&=E_{\pi } [R_{t+1} +\gamma V_{\pi }(S_{t+1} ) |S_{t} =s ](贝尔曼方程) \end{align*} V(s)V(s)V(s)V(s)V(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γRt+2+γ2Rt+3+...∣St=s]=Eπ[Rt+1+γ(Rt+2+γRt+3+...)∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=Eπ[Rt+1+γVπ(St+1)∣St=s](贝尔曼方程)
其中 π \pi π指的是在当前状态下采取动作、到下一个状态的概率分布,也就是策略。
上式中最后一步即为贝尔曼方程,即:
V ( s ) = E π [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s ] V(s)=E_{\pi } [R_{t+1} +\gamma V_{\pi }(S_{t+1} ) |S_{t} =s ] V(s)=Eπ[Rt+1+γVπ(St+1)∣St=s]
贝尔曼方程的作用?
当前状态的价值可以由下一步状态的价值来表示,从而迭代求取状态价值函数。
根据Bellman方程求解状态价值函数的过程总体如下:给定一个简单的转移概率图,由于当前状态 S S S到所有可能的下一个状态 S ′ S^{'} S′的转移概率 P P P都不同,因此对他们相应的下一个状态的价值函数加权求平均,可以得到最后的 V ( s ) V(s) V(s):
V s = R S + γ ∑ S ′ ∈ S P S S ′ V S ′ V_{s}= R_{S}+\gamma {\textstyle \sum_{S^{'} \in S}} P_{SS^{'} }V_{S^{'} } Vs=RS+γ∑S′∈SPSS′VS′
状态价值函数的物理意义:我当前在这个状态,未来可能获得多少收益。比如踢足球,梅西在足球场的不同位置拿球,位置的坐标就是状态,而不同位置相应的进球的概率也会不一样,所以相应的价值函数也不会不同。
2.1.5Bellman方程的矩阵形式
Bellman方程的矩阵形式:
V = R + γ P V \mathbf{V} =\mathbf{R} +\gamma \mathbf{PV} V=R+γPV
即:
[ v ( 1 ) ⋮ v ( n ) ] = [ R ( 1 ) ⋮ R ( n ) ] + γ [ P 11 … P 1 n ⋮ ⋱ ⋮ P n 1 … P n n ] [ v ( 1 ) ⋮ v ( n ) ] \begin{bmatrix} v(1)\\ \vdots \\ v(n) \end{bmatrix}=\begin{bmatrix} R(1)\\ \vdots \\ R(n) \end{bmatrix}+\gamma \begin{bmatrix} P_{11} & \dots & P_{1n}\\ \vdots & \ddots & \vdots\\ P_{n1} &\dots &P_{nn} \end{bmatrix}\begin{bmatrix} v(1)\\ \vdots \\ v(n) \end{bmatrix} v(1)⋮v(n) = R(1)⋮R(n) +γ P11⋮Pn1…⋱…P1n⋮Pnn v(1)⋮v(n)
此时,如果是一个model-based的方法,状态转移概率矩阵 P P P就是已知的,可以直接有如下推导:
V = R + γ P V ( 1 − γ P ) V = R V = ( 1 − γ P ) − 1 R \begin{align*} &\mathbf{V} =\mathbf{R} +\gamma \mathbf{PV} \\ &(1-\gamma \mathbf{P})\mathbf{V} =\mathbf{R}\\ &\mathbf{V}=(1-\gamma \mathbf{P})^{-1}\mathbf{R} \end{align*} V=R+γPV(1−γP)V=RV=(1−γP)−1R
实际应用中,很难有机会能直接用这个公式求解,因为 P \mathbf{P} P通常可能的维度 n n n是非常高的,或非常稀疏的矩阵。对于 n n n个状态,计算时间复杂度为 O ( n 3 ) O(n^{3}) O(n3)。当n比较小时,可直接计算;当n较大时,需采用迭代方法来求解,如:动态规划、蒙特卡洛评估、时序差分学习。
2.1.6马尔科夫决策过程(Markov decision process)
马尔科夫决策过程(Markov decision process):马尔科夫决策过程由元组 ( S , A , P , R , γ ) (S,A,P,R,\gamma) (S,A,P,R,γ)描述,其中:
S 为有限状态的集 A 为有限动作的集 P 为状态转移概率 R 为回报函数: R s = E [ R t + 1 ∣ S t = s ] γ 为折扣因子: γ ∈ [ 0 , 1 ] S为有限状态的集\\ A为有限动作的集\\ P为状态转移概率\\ R为回报函数:R_{s} = E[R_{t+1}|S_{t}=s] \\ \gamma为折扣因子:\gamma \in [0,1] S为有限状态的集A为有限动作的集P为状态转移概率R为回报函数:Rs=E[Rt+1∣St=s]γ为折扣因子:γ∈[0,1]
MDP ( S , A , P , R , γ ) (S,A,P,R,\gamma) (S,A,P,R,γ)和MRP ( S , P , R , γ ) (S,P,R,\gamma) (S,P,R,γ)的区别?
MRP仅显式的给出的是状态间的转移过程、隐含了实际执行了什么动作。
MDP的状态转移概率包含确切的动作,同一个状态下可以通过不同的具体动作、获得不同的具体奖励进入到下一个状态,即:
P S S ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] P_{SS^{'} }^{a} =P[S_{t+1}=s^{'} |S_{t}=s,A_{t=a}] PSS′a=P[St+1=s′∣St=s,At=a]
2.2策略
一个智能体(agent)可以由以下部分中一个或多个组成:
策略(Policy):智能体做出决策的部分。
价值函数(Value Function):评价状态或动作好坏的函数。
模型(Model):智能体对环境的建模。
策略 π \pi π是决定个体行为的机制,通常表达为从当前状态到可能的动作的条件概率,第一种为随机性策略,同一个状态下有多种可能动作,即:
π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi (a|s)=P(A_{t} =a|S_{t}=s ) π(a∣s)=P(At=a∣St=s)
第二种为确定性策略,同一个状态下确定地做出一个具体的动作,即:
a = π ( s ) a=\pi (s) a=π(s)
一个策略完整表示了一个个体的行为方式,也就是说定义了个体在各个状态下的各种可能的行为方式及其概率的大小。强化学习输出的一般就是策略,这个策略让智能体去打篮球、踢足球、玩星际争霸、下围棋,本质上都是不断地观测状态、做出行为。策略仅和当前状态有关,与历史信息无关;同时,某一确定的策略是静态的,与时间无关;但是,智能体可以随着时间更新策略。
2.3价值函数
相比马尔科夫奖励过程(MRP)仅考虑状态,我们在马尔科夫决策过程(MRD)要考虑具体动作。
2.3.1重新定义状态价值函数和动作价值函数
状态价值函数 V π ( s ) V_{\pi}(s) Vπ(s):从状态 s s s出发,遵循策略 π \pi π,从而能得到的期望累计奖励,即:
V π ( s ) = E π [ G t ∣ S t = s ] V π ( s ) = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s ] V π ( s ) = E π [ R t + 1 + γ ( R t + 2 + γ R t + 3 + . . . ) ∣ S t = s ] V π ( s ) = E π [ R t + 1 + γ G t + 1 ∣ S t = s ] V π ( s ) = E π [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s ] ( 贝尔曼方程 ) \begin{align*} V_{\pi } (s)&=E_{\pi } [G_{t}|S_{t} =s ] \\ V_{\pi } (s)&=E_{\pi } [R_{t+1} +\gamma R_{t+2}+\gamma^{2} R_{t+3}+...|S_{t} =s ]\\ V_{\pi } (s)&=E_{\pi } [R_{t+1} +\gamma (R_{t+2}+\gamma R_{t+3}+...)|S_{t} =s ]\\ V_{\pi } (s)&=E_{\pi } [R_{t+1} +\gamma G_{t+1}|S_{t} =s ]\\ V_{\pi } (s)&=E_{\pi } [R_{t+1} +\gamma V_{\pi }(S_{t+1} ) |S_{t} =s ](贝尔曼方程) \end{align*} Vπ(s)Vπ(s)Vπ(s)Vπ(s)Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γRt+2+γ2Rt+3+...∣St=s]=Eπ[Rt+1+γ(Rt+2+γRt+3+...)∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=Eπ[Rt+1+γVπ(St+1)∣St=s](贝尔曼方程)
动作价值函数 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a):从状态 s s s出发,采取动作 a a a,然后遵循策略 π \pi π,从而能得到的期望累计奖励,即:
Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] Q π ( s , a ) = E π [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s , A t = a ] Q π ( s , a ) = E π [ R t + 1 + γ Q π ( S t + 1 , a ′ ) ∣ S t = s , A t = a ] ( 贝尔曼方程 ) \begin{align*} Q_{\pi } (s,a)&=E_{\pi } [G_{t}|S_{t} =s ,A_{t} =a] \\ Q_{\pi } (s,a)&=E_{\pi } [R_{t+1} +\gamma V_{\pi }(S_{t+1} ) |S_{t} =s,A_{t} =a ]\\ Q_{\pi } (s,a)&=E_{\pi } [R_{t+1} +\gamma Q_{\pi }(S_{t+1},a^{'} ) |S_{t} =s,A_{t} =a ](贝尔曼方程) \end{align*} Qπ(s,a)Qπ(s,a)Qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+1+γVπ(St+1)∣St=s,At=a]=Eπ[Rt+1+γQπ(St+1,a′)∣St=s,At=a](贝尔曼方程)
2.3.2状态价值函数和动作价值函数之间的关系
a.状态价值函数由动作价值函数表示
状态 s s s的价值可以表示为:在状态 s s s下,遵循 π \pi π策略,采取所有可能动作的价值,按所有动作发生概率的乘积求和,即:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) v_{\pi }(s)= {\textstyle \sum_{a\in A}} \pi (a|s) q_{\pi } (s,a) vπ(s)=∑a∈Aπ(a∣s)qπ(s,a)
b.动作价值函数由状态价值函数表示
状态 s s s下,采取一个动作的价值,可以由两部分表示:一是离开这个状态的状态价值;二是所有进入新的状态的状态价值与其转移概率乘积的和,即:
q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) q_{\pi } (s,a)=R_{s}^{a} +\gamma {\textstyle \sum_{s^{'}\in S }} P_{ss^{'} }^{a} v_{\pi} (s^{'} ) qπ(s,a)=Rsa+γ∑s′∈SPss′avπ(s′)
c.策略 π \pi π与状态转移概率 p p p相结合的Bellman方程
联立以上两方程,互相交换表示项,可以得到以下两个方程:
{ v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) ) q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) \left\{\begin{align*} &v_{\pi }(s)= {\textstyle \sum_{a\in A}} \pi (a|s)(R_{s}^{a} +\gamma {\textstyle \sum_{s^{'}\in S }} P_{ss^{'} }^{a} v_{\pi} (s^{'} )) \\ &q_{\pi } (s,a)=R_{s}^{a} +\gamma {\textstyle \sum_{s^{'}\in S }} P_{ss^{'} }^{a}{\textstyle \sum_{a^{'} \in A}} \pi (a^{'}|s^{'}) q_{\pi } (s^{'},a^{'}) \end{align*}\right. {vπ(s)=∑a∈Aπ(a∣s)(Rsa+γ∑s′∈SPss′avπ(s′))qπ(s,a)=Rsa+γ∑s′∈SPss′a∑a′∈Aπ(a′∣s′)qπ(s′,a′)
由此,我们得到了策略 π \pi π与状态转移概率 p p p相结合的两种Bellman方程,并且均可以递归求解。
2.3.3最优价值函数
假设我们能够知道转移概率是多少,在给定奖励函数下,我们可以在有限多个状态的穷举中,找到最优策略 π ∗ \pi_{*} π∗,从而最大化累计奖励,由此,产生两个新的概念:最优状态价值函数 v ∗ ( s ) v_{*}(s) v∗(s)、最优动作价值函数 q ∗ ( s , a ) q_{*}(s,a) q∗(s,a)。
最优状态价值函数 v ∗ ( s ) v_{*}(s) v∗(s):从所有策略产生的状态价值函数中,选取使状态s价值最大的函数,即:
v ∗ ( s ) = max π v π ( s ) v_{*}(s)=\max _{\pi } v_{\pi } (s) v∗(s)=πmaxvπ(s)
最优动作价值函数 q ∗ ( s , a ) q_{*}(s,a) q∗(s,a):从所有策略产生的动作价值函数中,选取状态动作对 < s , a >
q ∗ ( s , a ) = max π q π ( s , a ) q_{*}(s,a)=\max _{\pi } q_{\pi } (s,a) q∗(s,a)=πmaxqπ(s,a)
最优价值函数明确了MDP的最优可能表现,当知道了最优价值函数,也就知道了每个状态的最优价值,这时便认为这个MDP获得了解决。
最优策略 π ∗ \pi_{*} π∗:当对于任何状态 s s s,遵循策略 π ′ \pi^{'} π′的价值,不小于遵循策略 π \pi π下的价值,则策略 π ′ \pi^{'} π′优于策略 π \pi π,即:
∀ s , v π ′ ( s ) ≥ v π ( s ) ⟹ π ′ ≥ π \forall s,v_{\pi ^{'}}(s)\ge v_{\pi}(s)\Longrightarrow \pi ^{'}\ge \pi ∀s,vπ′(s)≥vπ(s)⟹π′≥π
MDP三定律:对于任何MDP,下面三点恒成立
a.存在一个最优策略,比任何其他策略更好或至少相等;
b.所有的最优策略有相同的最优状态价值函数;
c.所有的最优策略具有相同的最优动作价值函数。
由了上述定义,就可以通过最大化最优动作价值函数来找到最优策略:
π ∗ ( a ∣ s ) = { 1 , i f a = arg max a ∈ A q ∗ ( s , a ) 0 , o t h e r w i s e \pi _{*} (a|s)=\left\{\begin{align*} &1,if\space a=\mathop{\arg\max}\limits_{a\in A}q_{*}(s,a) \\ &0,otherwise \end{align*}\right. π∗(a∣s)=⎩ ⎨ ⎧1,if a=a∈Aargmaxq∗(s,a)0,otherwise
也就是说,对于任何MDP问题,总存在一个确定性的最优策略;同时如果知道最优动作价值函数,则表明找到了最优策略。
2.4模型(Model)
模型(Model)指对智能体所处环境的建模,体现了智能体是如何思考环境运行机制的,模型至少要解决如下两个问题。
问题一:状态转移概率 P s s ′ a P_{ss^{'}}^{a} Pss′a,即在状态 s s s下采取动作 a a a,转移到下一状态 s ′ s^{'} s′的概率:
P s s ′ a = E [ S t + 1 ∣ S t = s , A t = a ] P_{ss^{'} }^{a} =E[S_{t+1}|S_{t}=s,A_{t}=a] Pss′a=E[St+1∣St=s,At=a]
问题二:即时奖励 R s a R_{s}^{a} Rsa,即在状态 s s s下采取动作 a a a,所立即能得到的期望奖励:
R s a = E [ R t + 1 ∣ S t = s , A t = a ] R_{s }^{a} =E[R_{t+1}|S_{t}=s,A_{t}=a] Rsa=E[Rt+1∣St=s,At=a]
3.动态规划
动态规划(Dynamic Programming,DP)是一种用于解决具有如下两个特性问题的通用算法:
a.优化问题可以分解为子问题
b.子问题出现多次并可以被缓存和复用。
马尔可夫决策过程符合这两个特性,因为贝尔曼方程给定了迭代过程的分解,而价值函数保存并复用了解决方案。
动态规划应用于马尔可夫决策过程的规划问题而不是学习问题,我们必须对环境是完全已知的,才能做动态规划,也就是要知道状态转移概率和对应的奖励。
使用动态规划完成预测问题和控制问题的求解,是解决马尔可夫决策过程预测问题和控制问题的非常有效的方式。
使用DP方法推导MDP过程:
a.预测问题:输入MDP为 < S , A , P , R , γ >
b.控制问题:输入MDP为 < S , A , P , R , γ >
3.1策略迭代方法(Policy Iteration)
策略迭代方法分为两个过程:策略评估和策略提升。
策略评估:在当前的策略 π \pi π中更新各状态的价值函数 v ( s ) v(s) v(s),如果达到最大迭代次数 K K K或者价值函数收敛便停止,即:
V k + 1 ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a v k ( s ′ ) ) V_{k+1}(s)= {\textstyle \sum_{a\in A}} \pi (a|s)(R_{s}^{a} +\gamma {\textstyle \sum_{s^{'}\in S }} P_{ss^{'} }^{a} v_{k} (s^{'} )) Vk+1(s)=∑a∈Aπ(a∣s)(Rsa+γ∑s′∈SPss′avk(s′))
策略提升:基于当前价值函数得到最优策略,也就是贪心策略。
π k + 1 = arg max a ∈ A Q π ( s , a ) \pi_{k+1} =\mathop{\arg\max}\limits_{a\in A}Q_{\pi }(s,a) πk+1=a∈AargmaxQπ(s,a)
一次完整的策略迭代过程:K次策略评估+1次策略提升。
策略迭代本质上是一个典型的动态规划方法,但是如果策略空间很大,那么策略评估就会很耗时;如果策略评估迟迟难以收敛,那么策略提升的效果也会非常有限。
3.2价值迭代算法(Value Iteration)
每次价值迭代都找到让当前价值函数最大的更新方式,并且用这种方式更新价值函数,直到价值函数不再变化,即:
V ∗ ( s ) ⟵ max a ∈ A ( R s a + γ ∑ s ′ ∈ S P s s ′ a v k ( s ′ ) ) V^{*}(s)\longleftarrow \max _{a\in A }(R_{s}^{a} +\gamma {\textstyle \sum_{s^{'}\in S }} P_{ss^{'} }^{a} v_{k} (s^{'} )) V∗(s)⟵a∈Amax(Rsa+γ∑s′∈SPss′avk(s′))
价值迭代与策略迭代的区别,就是在值迭代过程中,算法不会给出明确的策略,迭代过程期间得到的价值函数,不对应任何策略。
策略迭代与价值迭代的区别与联系:
a.策略迭代是累计平均的计算方式,价值迭代是单步最好的方式。
b.价值迭代速度更快,尤其是在策略空间较大的时候。
c.策略迭代更接近于样本的真实分布
然而,能够知晓状态转移概率、也就是model-based的问题还是比较少的,在很多实际问题中,我们往往无法得到环境的全貌,状态转移概率也就无从得知,也就是model-free的问题更加普遍。
4.蒙特卡罗算法
4.1算法概念
4.1.1基本思想
许多情况下我们不清楚MDP的真实状态转移概率或即时奖励,而蒙特卡洛(Monte Carlo,简称MC)方法的一个最基本思想是:对各个状态进行一轮轮的重复访问,当访问的回合数足够多的时候,我们最终可以得到趋近于真实的价值评估结果。
从理论角度,这一方法的思想起源于大数定律、中心极限定理,即:通常情况下某个状态的价值等于在多个回合中以该状态算得到的所有奖励的平均,样本数量越大,结果越接近奖励期望:
V ( s ) = 1 N ∑ i = 1 n [ r 1 i + r 2 i + … ] V(s)=\frac{1}{N} \sum_{i=1}^{n} [r_{1}^{i}+r_{2}^{i}+\dots ] V(s)=N1i=1∑n[r1i+r2i+…]
4.1.2First-visit和Every-visit
对于不知道状态转移概率的情况下,蒙特卡洛方法通过不断试错的方式,生成大量的马尔科夫链来估计状态价值,估计的方法主要由两种:First-visit和Every-visit。
First-visit:计算状态 s s s处的值函数时,只利用每个回合中第一次访问到状态 s s s时返回的值,也就是说,通过多次MDP,获得了多个future reward,把这些加起来求评价,得到 V ( s ) V(s) V(s).
Every-visit:在计算状态 s s s处的值函数时,利用所有MDP中访问到的每一次状态 s s s时的奖励返回值求平均,得到 V ( S ) V(S) V(S)。
First-visit方法相比Every-visit的好处是方差较小。
4.1.3蒙特卡洛流程
每进入一个MDP,由于一个序列的平均值可以迭代进行计算,因此对于回合里的每一个状态 s t s_{t} st,都有一个累积折扣奖励 G t G_{t} Gt,每碰到一次
s t s_{t} st,我们可以使用下面的式子计算状态的平均价值 V ( s ) V(s) V(s):
N ( s t ) ⟵ N ( s t ) + 1 V ( s t ) ⟵ V ( s t ) + 1 N ( s t ) ( G t − V ( s t ) ) \begin{align*} &N(s_{t})\longleftarrow N(s_{t})+1 \\ &V(s_{t})\longleftarrow V(s_{t})+\frac{1}{N(s_{t})}(G_{t}-V(s_{t})) \\ \end{align*} N(st)⟵N(st)+1V(st)⟵V(st)+N(st)1(Gt−V(st))
上述第一个公式,First-visit时每轮过程只统计一次,Every-visit就讲次数累加。
上述第二个公式用来进行价值函数的更新。
4.1.4蒙特卡洛的优缺点
优点:
a.方法的误差与问题的维数无关,例如状态空间的大小不会影响该方法的性能。
b.对于具有统计性质问题可以直接进行解决。
c.对于连续性的问题不必进行离散化处理。
缺点:
a.对于确定性问题需要转化成随机性问题,因为如果策略是确定性的,那将难以得到多样化的马尔科夫链。
b.误差是概率误差,取决于大数定律。
c.通常需要较多的计算步数N。
4.2探索与利用
在强化学习里面,探索和利用是两个很核心的问题。
探索:探索即我们去探索环境,通过尝试不同的动作来得到最佳的策略(带来最大奖励的策略),通过试错来理解采取的动作到底可不可以带来好的奖励。
利用:即我们不去尝试新的动作,而是采取已知的可以带来很大奖励的动作,直接采取已知的可以带来很好奖励的动作。
探索利用策略有很多种,以下总结几种最常用的策略。
4.2.1 ϵ \epsilon ϵ-greedy
以某一个小概率 ϵ \epsilon ϵ去选择一个随机的动作作为探索,而其余的大部分概率去选择能够给我最大价值的那个动作作为利用,公式表达为:
ϵ − g r e e d y { R a n d o m A c t i o n , i f p < ϵ arg max a Q ( s , a ) , i f ϵ < p < 1 \epsilon -greedy\left\{\begin{align*} &Random\space Action,if \space p<\epsilon \\ &\arg\max _{a} Q(s,a),if \space \epsilon
具体来说,每次行动前,生成随机数 P ∈ ( 0 , 1 ) P \in (0,1) P∈(0,1),若随机数 P > ϵ P>\epsilon P>ϵ,则采用贪心算法选择最大化Q值的动作;若 P < ϵ P<\epsilon P<ϵ则随机采取动作空间中的某一动作。
优点:计算容易,不需要复杂的计算公式,能保证充分探索所有状态。
缺点:需要大量探索,数据利用率低,因为虽然智能体绝大多数时间都选取的是Q值最大的动作,但此时的最优动作不代表最优策略,依然需要非常长时间的探索,甚至想要获得一个最优策略需要无限多的时间(取决于状态的数量以及 ϵ \epsilon ϵ大小)。
4.2.2Boltzmann strategy
Q值越大的动作有更大的概率被选择,而若两个动作具有接近的Q值,则二者都应有几率被选择。换句话说,Boltzmann策略不再选取Q值最大的动作,而是根据Q值输出动作的概率分布,根据分布从中随机选取一动作,即:
π ( a ∣ s ) = e k Q ( s , a ) ∑ a ′ e k Q ( s , a ′ ) \pi(a|s)=\frac{e^{kQ(s,a)}}{\sum_{a^{'} }e^{kQ(s,a^{'} )} } π(a∣s)=∑a′ekQ(s,a′)ekQ(s,a)
其中,k作为一个常数,负责对Q的量纲进行调整,修整概率分布的形状,实现对探索/利用的鼓励。
4.2.3 高斯策略(Gaussian strategy)
对于确定性策略的动作 μ θ \mu _{\theta } μθ,添加高斯噪声 ϵ \epsilon ϵ来达到增强探索的目的,即:
π θ = μ θ + ϵ , ϵ ∼ N ( 0 , σ 2 ) \pi_{\theta } = \mu _{\theta }+\epsilon ,\epsilon \sim N(0,\sigma ^{2} ) πθ=μθ+ϵ,ϵ∼N(0,σ2)
随着强化学习训练的推进,可以将噪声设置得越来越小,以达到对探索与利用的平衡。
4.3多臂赌博机问题(单步强化学习-蒙特卡洛)
4.3.1基本概念
问题简介:一个赌徒,要去摇老虎机,走进赌场一看,一排老虎机,外表一模一样,但是每个老虎机吐钱的概率可不一样,他不知道每个老虎机吐钱的概率分布是什么,那么每次该选择哪个老虎机可以做到最大化收益呢?这就是经典的多臂赌博机问题 (Multi-armed bandit problem, K- or N-armed bandit problem, MAB)。此时状态和动作均为各个赌博机的“摇把”情况,奖励就是是否最终成功吐钱。
k k k臂赌博机问题因为通常只有单步,且不严格区分状态、动作,因此也被认为是马尔可夫决策过程的特殊简化形式。
在 k k k臂赌博机问题中, k k k个动作的每一个在被选择时都有一个期望或者平均收益,称之为这个动作的“价值”。令 t t t时刻选择的动作为 A t A_{t} At,对应的收益为 R t R_{t} Rt,任一动作a对应的价值为 q ∗ ( a ) q_{*}(a) q∗(a),即给定动作 a a a时收益的期望:
q ∗ ( a ) = E [ R t ∣ A t = a ] q_{*}(a)=E[R_{t} |A_{t} =a] q∗(a)=E[Rt∣At=a]
如果持续对动作的价值进行估计,那么在任一时刻都会至少有一个动作的估计价值是最高的,将这些对应最高估计价值的动作成为贪心的动作。
当从这些动作中选择时,称此为“利用”当前所知道的关于动作的价值的知识。
如果不是如此,而是选择非贪心的动作,称此为“探索”,因为这可以让你改善对非贪心动作的价值的估计。
利用”对于最大化当前这一时刻的期望收益是正确的做法,但是“探索”从长远来看可能会带来总体收益的最大化。到底选择“利用”还是“探索”一种复杂的方式依赖于我们得到的函数估计、不确定性和剩余时刻的精确数值。
4.3.2十臂赌博机之 ϵ \epsilon ϵ-greedy
以10臂赌博机为例,赌场工作人员在你玩之前都会对老虎机做一番调校,此时动作的收益分布如下图所示,横轴是不同老虎机的动作,纵轴是该老虎机的收益概率分布,例如3号赢的概率比6号要大。

使用 ϵ \epsilon ϵ-greedy算法,分布令 ϵ \epsilon ϵ为0(贪心策略),0.01,0.1时,平均收益如下:
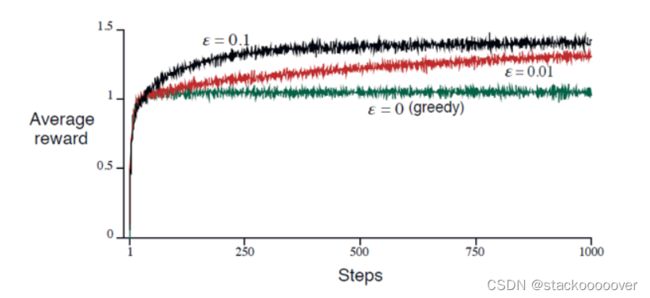
最优动作占比随训练步数的变化情况:

ϵ \epsilon ϵ-greedy在进行尝试时是盲目地选择,因为它不大会选择接近贪心或者不确定性特别大的动作。
4.3.3十臂赌博机之UCB
在非贪心动作中,最好是根据它们的潜力来选择可能事实上是最优的动作,这要考虑它们的估计有多接近最大值,以及这些估计的不确定性。因此,另一种基于置信度上界(Upper Confidence Bound,UCB)思想也非常流行,它选择动作依据如下:
A t ≐ arg max a [ Q t ( a ) + c ln t N t ( a ) ] A_{t} \doteq \arg \max_{a}[Q_{t}(a) +c\sqrt{\frac{\ln t}{N_{t} (a)} } ] At≐argamax[Qt(a)+cNt(a)lnt]
其中, N t ( a ) N_{t} (a) Nt(a)表示在t时刻之前动作a被选择的次数, c > 0 c>0 c>0用于控制探索的程度。平方根项是对a动作值估计的不确定性或方差的度量,最大值的大小是动作a的可能真实值得上限,参数c决定了置信水平。也就是说,如果当前的动作具有很大的价值,那么我们很容易选择这个动作;如果当前的动作被选了很多次,那么我们下一次就倾向于不选择这个动作;抛开该动作被选择的频率,如果时间越来越久,那样我们可以考虑重新选择这个动作。
UCB和 ϵ \epsilon ϵ-greedy比较,可以看到UCB的效率要高点:

4.3.3十臂赌博机之梯度赌博机法
针对每个动作 a a a,考虑学习一个数值化的偏好函数 H t ( a ) H_{t}(a) Ht(a),评价动作的好坏。偏好函数越大,动作就越频繁地被选择,但偏好函数的概念并不是从“回报”的意义上提出的。基于随机梯度上升的思想,在每个步骤中,在选择动作 A t A_{t} At并获得收益 R t R_{t} Rt之后,偏好函数都会按如下方式更新:
H t + 1 ( A t ) ≐ H t ( A t ) + α ( R t − R ˉ t ) ( 1 − π t ( A t ) ) H t + 1 ( a ) ≐ H t ( a ) + α ( R t − R ˉ t ) π t ( a ) , f o r a l l a ≠ A H_{t+1}(A_{t}) \doteq H_{t}(A_{t})+\alpha (R_{t}-\bar{R }_{t} )(1-\pi_{t}(A_{t}))\\ H_{t+1}(a) \doteq H_{t}(a)+\alpha (R_{t}-\bar{R }_{t} )\pi_{t}(a),for\space all\space a\ne A Ht+1(At)≐Ht(At)+α(Rt−Rˉt)(1−πt(At))Ht+1(a)≐Ht(a)+α(Rt−Rˉt)πt(a),for all a=A
其中, α \alpha α表示步长, R ˉ t \bar{R }_{t} Rˉt示时刻 t t t内所有回报的平均值,作为比较回报的一个基准项,如果回报高于它,那么在未来选择动作 A t A_{t} At的概率就会增加,反之概率就会降低,未选择的动作被选择的概率会上升。
上述公式的物理意义是,我们看当前收益和选择了这个动作之后的历史平均收益的差,如果当前收益大于这个平均的收益,说明我当前这个动作是个“好动作”,应该鼓励选取,反之则是一个“坏动作”,应该降低选取概率。
π t ( a ) \pi_{t}(a) πt(a)表示动作 a a a在 t t t时刻被选择的概率,所有偏好函数的初始值都相同(可为0)。
4.3.4算法比较
a. ϵ \epsilon ϵ-greedy方法在一段时间内进行随机的动作选择;
b.UCB 方法虽然采用确定的动作选择,但可以通过每个时刻对具有较少样本的动作进行优先选择来实现探索;
c.梯度赌博机算法则不估计动作价值,而是利用偏好函数,使用softmax分布来以一种分级的、概率式的方式选择更优的动作;
d.简单地将收益的初值进行乐观的设置,可以让贪心方法也能进行显式探索。
5.时序差分算法
5.1算法概念
前面在model-free的动态规划问题中讲到了蒙特卡洛方法,然而蒙特卡洛方法需要等到整个回合结束、获取具体收益 G t G_{t} Gt后才能更新,并且需要大量的回合才能得到较为准确的结果。而时序差分(Temporal-Difference,TD)算法,不使用完整回合,就可以实现单步或几步的更新。这类方法也是现在深度强化学习算法的主要基础。
以单步更新的TD(0)算法为例,此时总奖励 G t G_{t} Gt不再引入整个回合的未来折扣奖励,而是变为:
G t = R t + 1 + γ V ( S t + 1 ) G_{t} =R_{t+1} +\gamma V(S_{t+1} ) Gt=Rt+1+γV(St+1)
由于时序差分算法中不需要完整的回合,因此没有了 1 N ( s t ) \frac{1}{N(s_{t} )} N(st)1,使用系数 α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1](即“学习率”)来代替;原有的MC error G t − V ( s t ) G_{t}-V(s_{t}) Gt−V(st)替换为TD error R t + 1 + γ V ( S t + 1 ) − V ( s t ) R_{t+1} +\gamma V(S_{t+1})-V(s_{t}) Rt+1+γV(St+1)−V(st)
V ( s t ) ⟵ V ( s t ) + 1 N ( s t ) ( G t − V ( s t ) ) V ( s t ) ⟵ V ( s t ) + α ( R t + 1 + γ V ( S t + 1 ) − V ( s t ) ) V(s_{t})\longleftarrow V(s_{t})+\frac{1}{N(s_{t})}(G_{t}-V(s_{t})) \\ V(s_{t})\longleftarrow V(s_{t})+\alpha(R_{t+1} +\gamma V(S_{t+1} )-V(s_{t})) V(st)⟵V(st)+N(st)1(Gt−V(st))V(st)⟵V(st)+α(Rt+1+γV(St+1)−V(st))
TD算法并不是只能考虑下一步,当 n n n的取值不同时, G t G_{t} Gt的取值会不同:
n = 1 , G t 1 = R t + 1 + γ V ( S t + 1 ) T D 方法 n = 2 , G t 2 = R t + 1 + γ R t + 2 + γ 2 a V ( S t + 2 ) T D 方法 ⋯ n = ∞ , G t ∞ = R t + 1 + γ R t + 2 + ⋯ + γ T − 1 R T M C 方法 \begin{align*} &n=1,G_{t}^{1} =R_{t+1} +\gamma V(S_{t+1} ) TD方法\\ &n=2,G_{t}^{2} =R_{t+1} +\gamma R_{t+2}+\gamma ^{2}aV(S_{t+2} ) TD方法\\ &\cdots \\ &n=\infty ,G_{t}^{\infty} =R_{t+1} +\gamma R_{t+2}+\dots +\gamma ^{T-1} R^{T} MC方法 \end{align*} n=1,Gt1=Rt+1+γV(St+1)TD方法n=2,Gt2=Rt+1+γRt+2+γ2aV(St+2)TD方法⋯n=∞,Gt∞=Rt+1+γRt+2+⋯+γT−1RTMC方法
根据上式,n步的TD-learning可以表示为:
V ( s t ) ⟵ V ( s t ) + α ( G t n − V ( s t ) ) V(s_{t})\longleftarrow V(s_{t})+\alpha(G_{t}^{n} -V(s_{t})) V(st)⟵V(st)+α(Gtn−V(st))
那么n为多少时,效果最好?答案是需要超参数调参。引入 λ \lambda λ来综合所有的步数,即:
G t λ = ( 1 − λ ) ∑ n = 1 ∞ λ n − 1 G n t G_{t}^{\lambda } =(1-\lambda )\sum_{n=1}^{\infty} \lambda ^{n-1} G_{n}^{t} Gtλ=(1−λ)n=1∑∞λn−1Gnt
由此,我们得到了TD( λ \lambda λ)算法:
V ( s t ) ⟵ V ( s t ) + α ( G t λ − V ( s t ) ) V(s_{t})\longleftarrow V(s_{t})+\alpha(G_{t}^{\lambda} -V(s_{t})) V(st)⟵V(st)+α(Gtλ−V(st))
5.2MC,TD,DP算法比较
MC和TD:
a.MC方法是回合更新,打完一局游戏一更新;而TD方法可以做到单步更新,每踢一脚球、每射击一下都能进行更新。
b.MC方法一定需要完整的回合之后才能更新,而TD方法不需要完整回合。
c.MC方法是高方差、零误差的,因为我们有大数定律、穷举法的方法,但对过程中的各种状态的多样性非常敏感,因此高方差;而TD方法是低方差、有误差的。
d.MC方法没有体现出马尔科夫性质,因为马尔科夫性讲的是我当前状态只和前一个状态有关,而MC方法需要知道所有状态;相应地,TD方法体现出了马尔科夫性质。
e.MC方法对初值不敏感,因为可以通过不断地模拟整个回合,来最终修正到真值;但是TD方法对初值就敏感了,因为如果初始状态不合适,每一步TD的误差都会不断累积,而好的初始状态就会减少学习需要的步数。
MC更新更像是深度优先搜索,DP更新更像是广度优先搜索,搜索空间更大,但这里的广度是需要对当前状态到下一步所有状态有一个显式的状态转移模型来保证的,而MC、TD算法都是model-free的。
从另一个角度,在更新方式方面,以穷尽搜索作为baseline,三种算法也有如下差异:
TD方法:更新某一动作转移到的状态价值函数。
DP方法:更新所有可能转移到的状态价值函数(增加更新广度)。
MC方法:更新整个回合的所有状态价值函数(增加更新深度)。
6.Q-learning算法
6.1算法简介
Q-learning是一种无模型即model-free RL的形式,它也可以被视为异步DP的方法。它通过体验行动的后果,使智能体能够在马尔可夫域中学习以最优方式行动,而无需构建域的映射。学习的过程类似于TD方法:智能体在特定状态下尝试行动,并根据其收到的即时奖励或处罚以及对其所处状态的值的估计来评估其后果。通过反复尝试所有状态的所有行动,它可以通过长期折扣奖励来判断总体上最好的行为。
6.2算法流程
使用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy算法的Q-learning,在选取动作时,使用如下公式:
ϵ − g r e e d y { R a n d o m A c t i o n , i f p < ϵ arg max a Q ( s , a ) , i f ϵ < p < 1 \epsilon -greedy\left\{\begin{align*} &Random\space Action,if \space p<\epsilon \\ &\arg\max _{a} Q(s,a),if \space \epsilon
在更新Q值矩阵时,使用如下公式:
Q ( S , A ) ← Q ( S , A ) + [ R ( s , a ) + γ max a Q ( S ′ , A ) − Q ( S , A ) ] Q(S,A)\leftarrow Q(S,A)+[R(s,a)+\gamma \max _{a}Q(S^{'} ,A)-Q(S,A)] Q(S,A)←Q(S,A)+[R(s,a)+γamaxQ(S′,A)−Q(S,A)]

由上述可知,Q-learning可以把策略的选择变成了比不同状态值大小的问题。
虽然我们会探索很多个回合、会开启多次不同的马尔科夫链,但是我们始终维持着一个Q表。虽然Q-learning算法的更新方式更类似TD方法,但它也隐含了一点MC方法的启发,因为它同样需要模。拟众多回合才能维持对价值的准确估计。
6.3影响Q学习的因素
Q ( S , A ) ← Q ( S , A ) + [ R ( s , a ) + γ max a Q ( S ′ , A ) − Q ( S , A ) ] Q(S,A)\leftarrow Q(S,A)+[R(s,a)+\gamma \max _{a}Q(S^{'} ,A)-Q(S,A)] Q(S,A)←Q(S,A)+[R(s,a)+γamaxQ(S′,A)−Q(S,A)]
学习率(或步长):由上述公式可知, [ R ( s , a ) + γ max a Q ( S ′ , A ) − Q ( S , A ) ] [R(s,a)+\gamma \max _{a}Q(S^{'} ,A)-Q(S,A)] [R(s,a)+γmaxaQ(S′,A)−Q(S,A)]可以理解为新的知识。因此, α \alpha α确定了新获取的信息在多大程度上覆盖旧信息。此时一个合理的学习率可以更好地平衡新旧知识的权重。类似其它梯度下降的案例,学习率是q-learning算法的重要超参,且学习率不一定越大越好,过大的学习率可能会让我们最终偏离最优的策略。当问题是随机的时,算法在某些技术条件下收敛于需要将其减小到零的学习速率,甚至需要动态的自适应学习率机制。
折扣因子:折扣因子 λ \lambda λ决定了未来奖励的重要性。
初始条件 Q 0 Q_{0} Q0:Q-learning是迭代算法,因此它隐含地假定在第一次更新发生之前的初始条件;高初始值,也称为**“乐观初始条件”或“乐观估计”,可以鼓励探索**。当然过高的估计在整个学习过程中也是有问题的。
6.4算法变种——SARSA算法
同样基于TD方法的还有SARSA算法,与Q-learning算法的区别在于Q函数的更新方式。
6.4.1流程

从第8行可以看到SARSA并没有选择Q值最大的动作来更新Q函数,仍然使用 ϵ \epsilon ϵ-greedy策略来选择动作进行更新。Q-learning是off-policy,SARSA是on-policy。
6.4.2SARSA( λ \lambda λ)
SARSA是一种单步更新法,也称为SARSA(0)方法,只更新获取到奖励前所经历的最后一步,那么能不能结合蒙特卡洛方法的思想,更新获取奖励前所经的回合中的每一步呢,即回合更新?这就需要我们定义一个变量 λ \lambda λ,用来表示对回合中每步动作的重视程度,即SARSA( λ \lambda λ)算法,流程如下。相比SARSA(0)算法,SARSA( λ \lambda λ)增加了路径矩阵 E ( S , A ) E(S,A) E(S,A)。路径矩阵 E ( S , A ) E(S,A) E(S,A)用来保存回合中所经历的每一步,每访问一次其数值 + 1 +1 +1,并且矩阵数值会根据 λ \lambda λ不断进行衰减,保证了离奖励越近的步骤越重要:

第10行可以看到SARSA是对路径上的所有状态进行更新,若是未访问状态,其 E ( S , A ) = 0 E(S,A)=0 E(S,A)=0,对应 Q Q Q值不会被更新。并且,从第12行可以看到 E ( S , A ) E(S,A) E(S,A)会根据 λ \lambda λ衰减,保证了离奖励越近的time step越重要。 λ \lambda λ的选取具有以下物理意义:
λ = 0 \lambda=0 λ=0,更新只关注获取奖励前的一步
λ ∈ ( 0 , 1 ) \lambda \in(0,1) λ∈(0,1),更新对获取奖励前的每一步动作关注度依次递减
λ = 1 \lambda=1 λ=1,更新对获取奖励前的每一步动作关注度相等
6.4.3Q-learning与SARSA的比较
a.SARSA是on-policy算法,行动策略为 λ \lambda λ-greedy,评估策略为
λ \lambda λ-greedy。SARSA的学习方式比较保守稳健,每一个回合的每个动作都会执行 λ \lambda λ-greedy探索,但会导致学习过程变长。
b.Q-learning是off-policy算法,行动策略为 λ \lambda λ-greedy,评估策略为贪心策略。不同于SARSA,Q-learning倾向于利用经验的积累,每次采用Q值最大的动作去学习最优策略,但缺点也在在这一点上。因为我始终使用的是最大的Q进行更新,在反复迭代后,我会对各个状态的价值存在较高估计,因此学习过程存在风险。
这种反复更新Q表的方式叫做自举(bootstrapping)方式。
7.策略梯度(Policy Gradient)算法
7.1 算法简介
上述讲解的均为基于值(value-based)的方法,在处理一些问题中,Q表有明显的局限性,比如没有显式地表达策略,难以处理高维度乃至无穷尽的状态/动作空间。有没有什么方法可以不迭代更新Q表,而是直接迭代更新策略本身?由此我们介绍策略梯度(Policy Gradient)算法,它也是深度强化学习算法的另一个重要鼻祖。
基于值(value-based)的方法:通过近似值函数 V π ∗ ( s ) , Q π ∗ ( s ) V_{\pi }^{*} (s),Q_{\pi }^{*} (s) Vπ∗(s),Qπ∗(s),从而间接得到最优策略 π ∗ ( s ) \pi^{*} (s) π∗(s)。
基于策略(policy-based)的方法:直接参数化策略 π θ ( a ∣ s ) = P ( a ∣ s , θ ) \pi_{\theta }(a|s) =P(a|s,\theta ) πθ(a∣s)=P(a∣s,θ)。这里的 θ \theta θ指参数,例如在深度强化学习中,用神经网络来表征这个策略,此时 θ \theta θ也可以代指神经网络的权值 w w w(weights),即:在不断的学习过程中,我最终可以学好神经网络的所有参数。因此,如何更新策略,也就是如何更新 θ \theta θ的问题。
7.2 算法推导
目标函数:
J ( θ ) = ∑ τ p θ ( τ ) f ( τ ) J(\theta )= \sum_{\tau }p_{\theta } (\tau )f(\tau ) J(θ)=τ∑pθ(τ)f(τ)
其中:
θ \theta θ表示当前策略 π \pi π的参数
τ \tau τ表示轨迹或一条马尔科夫链
p θ ( τ ) p_{\theta } (\tau ) pθ(τ)表示由策略 π θ \pi_{\theta } πθ产生轨迹的概率分布
f ( τ ) f(\tau ) f(τ)表示轨迹的评价函数
根据马尔可夫性质,一个轨迹 τ \tau τ出现的概率 p θ ( τ ) p_{\theta } (\tau ) pθ(τ),可以拆分表示为每一步选取动作的概率、状态转移概率相累乘的形式:
p θ ( τ ) = p θ ( s 0 , a 0 , s 1 , a 1 , … , s T ) = p ( s 0 ) π θ ( a 0 ∣ s 0 ) p ( s 1 ∣ a 0 , s 0 ) π θ ( a 1 ∣ s 1 ) p ( s 2 ∣ a 1 , s 1 ) … π θ ( a T − 1 ∣ s T − 1 ) p ( s T ∣ a T − 1 , s T − 1 ) = p ( s 0 ) ∏ t = 0 T − 1 π θ ( a t ∣ s t ) p ( s t + 1 ∣ a t , s t ) \begin{align*} p_{\theta } (\tau ) = &p_{\theta }(s_{0},a_{0},s_{1},a_{1},\dots ,s_{T})\\ =&p(s_{0}) \pi _{\theta }(a_{0}|s_{0})p(s_{1}|a_{0},s_{0})\pi _{\theta }(a_{1}|s_{1})p(s_{2}|a_{1},s_{1})\\ &\dots \pi _{\theta }(a_{T-1}|s_{T-1})p(s_{T}|a_{T-1},s_{T-1})\\ =&p(s_{0})\prod_{t=0}^{T-1} \pi _{\theta }(a_{t}|s_{t})p(s_{t+1}|a_{t},s_{t}) \end{align*} pθ(τ)===pθ(s0,a0,s1,a1,…,sT)p(s0)πθ(a0∣s0)p(s1∣a0,s0)πθ(a1∣s1)p(s2∣a1,s1)…πθ(aT−1∣sT−1)p(sT∣aT−1,sT−1)p(s0)t=0∏T−1πθ(at∣st)p(st+1∣at,st)
Policy Gradient算法的优化目标是最大化策略 π θ \pi_{\theta} πθ产生轨迹的奖励,以Reinforce算法为例,将轨迹评价函数定义为折扣奖励 G G G,即:
f ( τ ) = G ( τ ) = ∑ t = 0 T − 1 γ t R t f(\tau )=G(\tau )=\sum_{t=0}^{T-1} \gamma ^{t} R_{t} f(τ)=G(τ)=t=0∑T−1γtRt
则其目标函数为:
J ( θ ) = ∑ τ p θ ( τ ) G ( τ ) J(\theta )= \sum_{\tau }p_{\theta } (\tau )G(\tau ) J(θ)=τ∑pθ(τ)G(τ)
使用梯度计算推导策略最优的 θ \theta θ:
▽ θ J ( θ ) = ▽ θ ( ∑ τ p θ ( τ ) G ( τ ) ) = ∑ τ ▽ θ p θ ( τ ) G ( τ ) = ∑ τ p θ ( τ ) 1 p θ ( τ ) ▽ θ p θ ( τ ) G ( τ ) = ∑ τ p θ ( τ ) ▽ θ log ( p θ ( τ ) ) G ( τ ) = ∑ τ p θ ( τ ) ▽ θ log ( p ( s 0 ) ∏ t = 0 T − 1 π θ ( a t ∣ s t ) p ( s t + 1 ∣ a t , s t ) ) G ( τ ) = ∑ τ p θ ( τ ) ▽ θ ( log p ( s 0 ) + ∑ t = 0 T − 1 log π θ ( a t ∣ s t ) + ∑ t = 0 T − 1 log p ( s t + 1 ∣ a t , s t ) ) G ( τ ) = ∑ τ p θ ( τ ) ▽ θ ( ∑ t = 0 T − 1 log π θ ( a t ∣ s t ) ) G ( τ ) = E τ [ ▽ θ ( ∑ t = 0 T − 1 log π θ ( a t ∣ s t ) ) G ( τ ) ] = E τ [ ∑ t = 0 T − 1 ▽ θ log π θ ( a t ∣ s t ) G ( τ ) ] \begin{align*} \triangledown _{\theta } J(\theta )=&\triangledown _{\theta }(\sum_{\tau }p_{\theta } (\tau )G(\tau ))\\ =&\sum_{\tau }\triangledown _{\theta }p_{\theta } (\tau )G(\tau )\\ =&\sum_{\tau }p_{\theta }(\tau )\frac{1}{p_{\theta }(\tau )} \triangledown _{\theta }p_{\theta } (\tau )G(\tau )\\ =&\sum_{\tau }p_{\theta }(\tau )\triangledown _{\theta }\log (p_{\theta } (\tau ))G(\tau )\\ =&\sum_{\tau }p_{\theta }(\tau )\triangledown _{\theta }\log (p(s_{0})\prod_{t=0}^{T-1} \pi _{\theta }(a_{t}|s_{t})p(s_{t+1}|a_{t},s_{t}))G(\tau )\\ =&\sum_{\tau }p_{\theta }(\tau )\triangledown _{\theta }(\log p(s_{0})+\sum _{t=0}^{T-1}\log \pi _{\theta }(a_{t}|s_{t})+ \sum _{t=0}^{T-1}\log p(s_{t+1}|a_{t},s_{t}))G(\tau )\\ =&\sum_{\tau }p_{\theta }(\tau )\triangledown _{\theta }(\sum _{t=0}^{T-1} \log\pi _{\theta }(a_{t}|s_{t}))G(\tau )\\ =&E_{\tau }[\triangledown _{\theta }(\sum _{t=0}^{T-1}\log \pi _{\theta }(a_{t}|s_{t}))G(\tau )]\\ =&E_{\tau }[\sum _{t=0}^{T-1}\triangledown _{\theta }\log \pi _{\theta }(a_{t}|s_{t})G(\tau )]\\ \end{align*} ▽θJ(θ)=========▽θ(τ∑pθ(τ)G(τ))τ∑▽θpθ(τ)G(τ)τ∑pθ(τ)pθ(τ)1▽θpθ(τ)G(τ)τ∑pθ(τ)▽θlog(pθ(τ))G(τ)τ∑pθ(τ)▽θlog(p(s0)t=0∏T−1πθ(at∣st)p(st+1∣at,st))G(τ)τ∑pθ(τ)▽θ(logp(s0)+t=0∑T−1logπθ(at∣st)+t=0∑T−1logp(st+1∣at,st))G(τ)τ∑pθ(τ)▽θ(t=0∑T−1logπθ(at∣st))G(τ)Eτ[▽θ(t=0∑T−1logπθ(at∣st))G(τ)]Eτ[t=0∑T−1▽θlogπθ(at∣st)G(τ)]
7.3算法流程

8.Actor-Critic算法
Policy Gradients需要回合更新,是一种更接近MC的方法,降低了学习效率;而Q-learning不需要回合更新,但无法处理高维的状态/动作空间。可不可以将二者结合?因此,学术界提出了Actor-Critic算法,用两套参数进行近似:Actor参数对策略函数近似,输出动作分布;Critic参数对价值函数近似,评价Actor的动作。在深度强化学习中,Actor、Critic通常由不同的神经网络表示。
8.1算法分析
策略梯度的更新目标:
▽ θ J ( θ ) = E τ [ ∑ t = 0 T − 1 ▽ θ log π θ ( a t ∣ s t ) G ( τ ) ] \triangledown _{\theta } J(\theta )=E_{\tau }[\sum _{t=0}^{T-1}\triangledown _{\theta }\log \pi _{\theta }(a_{t}|s_{t})G(\tau )] ▽θJ(θ)=Eτ[t=0∑T−1▽θlogπθ(at∣st)G(τ)]
使用真实的Q函数 Q π θ Q^{\pi\theta} Qπθ代替 G ( τ ) G(\tau) G(τ),使用蒙特卡洛采样估计策略梯度,省略下标 t t t后,得到一个简化的策略梯度估计:
▽ θ J ( θ ) = E t [ ▽ θ log π θ ( a ∣ s ) Q π θ ( s , a ) ] \triangledown _{\theta } J(\theta )=E_{t}[\triangledown _{\theta }\log \pi _{\theta }(a|s)Q^{\pi\theta}(s,a)] ▽θJ(θ)=Et[▽θlogπθ(a∣s)Qπθ(s,a)]
要结合Policy Gradient和Q-learning,就要先估计 Q π θ Q^{\pi\theta} Qπθ,可以使用 Q w Q_{w} Qw估计 Q π θ Q^{\pi\theta} Qπθ,即:
Q w ≈ Q π θ → ▽ θ J ( θ ) ≈ E t [ ▽ θ log π θ ( a ∣ s ) Q w ( s , a ) ] Q_{w}\approx Q^{\pi\theta}\rightarrow \triangledown _{\theta } J(\theta )\approx E_{t}[\triangledown _{\theta }\log \pi _{\theta }(a|s)Q_{w}(s,a)] Qw≈Qπθ→▽θJ(θ)≈Et[▽θlogπθ(a∣s)Qw(s,a)]
当同时满足以下两个条件时,等号成立:
条件1:参数 w w w是 Q π θ Q^{\pi\theta} Qπθ(s,a)和 Q w Q_{w} Qw的均方误差的极小值点,即:
w ∗ = arg min w E π θ [ ( Q π θ ( s , a ) − Q w ( s , a ) ) 2 ] w^{*}=\arg \min _{w}E_{\pi\theta }[(Q^{\pi\theta}(s,a)-Q_{w}(s,a))^{2} ] w∗=argwminEπθ[(Qπθ(s,a)−Qw(s,a))2]
二是值估计和策略估计是兼容(compatible)的,即:
▽ w Q w = ▽ θ log π θ \triangledown _{w} Q_{w} =\triangledown _{\theta } \log \pi _{\theta } ▽wQw=▽θlogπθ
满足以上两个条件,则:
▽ θ J ( θ ) = E t [ ▽ θ log π θ ( a ∣ s ) Q w ( s , a ) ] \triangledown _{\theta } J(\theta )= E_{t}[\triangledown _{\theta }\log \pi _{\theta }(a|s)Q_{w}(s,a)] ▽θJ(θ)=Et[▽θlogπθ(a∣s)Qw(s,a)]
8.2条件证明
如果满足条件1:
w ∗ = arg min w E π θ [ ( Q π θ ( s , a ) − Q w ( s , a ) ) 2 ] w^{*}=\arg \min _{w}E_{\pi\theta }[(Q^{\pi\theta}(s,a)-Q_{w}(s,a))^{2} ] w∗=argwminEπθ[(Qπθ(s,a)−Qw(s,a))2]
则:
▽ w E π θ [ ( Q π θ ( s , a ) − Q w ( s , a ) ) 2 ] = 0 ⟹ ▽ w E π θ [ Q π θ ( s , a ) 2 − 2 Q π θ ( s , a ) Q w ( s , a ) + Q w ( s , a ) 2 ] = 0 ⟹ E π θ [ − 2 Q π θ ( s , a ) ▽ w Q w ( s , a ) + 2 ▽ w Q w ( s , a ) ] = 0 ⟹ E π θ [ ( Q π θ ( s , a ) − Q w ( s , a ) ) ▽ w Q w ( s , a ) + ] = 0 \begin{align*} &\triangledown_{w}E_{\pi\theta }[(Q^{\pi\theta}(s,a)-Q_{w}(s,a))^{2} ] = 0\\ \Longrightarrow &\triangledown_{w}E_{\pi\theta }[Q^{\pi\theta}(s,a)^{2}-2Q^{\pi\theta}(s,a)Q_{w}(s,a)+Q_{w}(s,a)^{2} ] = 0\\ \Longrightarrow &E_{\pi\theta }[-2Q^{\pi\theta}(s,a)\triangledown_{w}Q_{w}(s,a)+2\triangledown_{w}Q_{w}(s,a) ] = 0\\ \Longrightarrow &E_{\pi\theta }[(Q^{\pi\theta}(s,a)-Q_{w}(s,a))\triangledown_{w}Q_{w}(s,a)+ ] = 0 \end{align*} ⟹⟹⟹▽wEπθ[(Qπθ(s,a)−Qw(s,a))2]=0▽wEπθ[Qπθ(s,a)2−2Qπθ(s,a)Qw(s,a)+Qw(s,a)2]=0Eπθ[−2Qπθ(s,a)▽wQw(s,a)+2▽wQw(s,a)]=0Eπθ[(Qπθ(s,a)−Qw(s,a))▽wQw(s,a)+]=0
如果满足条件2:
▽ w Q w = ▽ θ log π θ \triangledown _{w} Q_{w} =\triangledown _{\theta } \log \pi _{\theta } ▽wQw=▽θlogπθ
根据条件一的推论,则:
E π θ [ ( Q π θ ( s , a ) − Q w ( s , a ) ) ▽ θ log π θ ] = 0 E_{\pi\theta }[(Q^{\pi\theta}(s,a)-Q_{w}(s,a))\triangledown _{\theta } \log \pi _{\theta }] = 0 Eπθ[(Qπθ(s,a)−Qw(s,a))▽θlogπθ]=0
因此:
▽ θ J ( θ ) = E t [ ▽ θ log π θ ( a ∣ s ) Q π θ ( s , a ) ] = E t [ ▽ θ log π θ ( a ∣ s ) Q w ( s , a ) ] \begin{align*} \triangledown _{\theta } J(\theta )=&E_{t}[\triangledown _{\theta }\log \pi _{\theta }(a|s)Q^{\pi\theta}(s,a)]\\ =&E_{t}[\triangledown _{\theta }\log \pi _{\theta }(a|s)Q_{w}(s,a)]\\ \end{align*} ▽θJ(θ)==Et[▽θlogπθ(a∣s)Qπθ(s,a)]Et[▽θlogπθ(a∣s)Qw(s,a)]
需要注意的是,在实际计算中,几乎无法得到真实Q值的准确值估计 Q w Q_{w} Qw。此外,条件2仅当策略函数是指数函数时满足(而现实问题几乎不用指数函数表示策略函数)。尽管两个条件在实际计算中几乎无法满足,但这并不影响Actor-Critic算法在实际问题中发挥的巨大作用,特别是在如今的深度强化学习方法中。
8.3算法流程
以linear critic下的QAC算法为例,介绍Actor-Critic算法的流程。
设actor、critic的参数分别 θ , w \theta,w θ,w
使用线性的神经网络来表征critic参数,即:
Q w ( s , a ) = w T ϕ ( s , a ) Q_{w} (s,a)=w^{T} \phi (s,a) Qw(s,a)=wTϕ(s,a)
其中 ϕ ( s , a ) \phi (s,a) ϕ(s,a)为线性critic的输入,可以视为状态与动作的简单连接。

Actor-Critic算法的优点:
a.可以处理大规模状态/动作空间问题
b.基于TD error进行单步更新,加快了学习速度
缺点:
a.对于深度强化学习来说,Actor-Critic相当于具有两s个网络,更加难以收敛,能否收敛主要取决于critic网络的价值判断是否准确
b.每次参数更新前后都存在相关性,导致神经网络只能片面地看待问题,甚至导致神经网络学不到东西。
8.4A2C
在Actor-critic中,Actor应该朝着Q值增加的方向更新:
J ( θ ) = − log π θ ( s , a ) Q w ( s , a ) J(\theta )=-\log \pi _{\theta }(s,a) Q_{w}(s,a) J(θ)=−logπθ(s,a)Qw(s,a)
为了能够减少Critic网络的估计方差(variance),我们引入advantage,表示一个动作的预期回报比baseline高出多少,数学表达式为:
A t ( s , a ) = Q w ( s , a ) − b a s e l i n e = Q w ( s , a ) − V ( s ) \begin{align*} A_{t}(s,a) & = Q_{w}(s,a)-baseline\\ &=Q_{w}(s,a)-V(s) \end{align*} At(s,a)=Qw(s,a)−baseline=Qw(s,a)−V(s)
其中, V ( s ) V(s) V(s)为平均动作预期回报,通常作为baseline。
如果 A t ( s , a ) > 0 A_{t}(s,a) >0 At(s,a)>0,则动作 a a a的采样概率增加,反之则概率降低。
然而在深度强化学习中, Q Q Q和 A A A可能意味着引入两个参数或两个网络,因此做出调整,去掉 Q Q Q网络,保留 V V V网络,从而得到大名鼎鼎的Advantage Actor-critic(A2C)算法:
在Critic网络部分,A2C使用TD-Error估计 V ϕ ( s ) V_{\phi}(s) Vϕ(s),则:
δ t = r ( s , a ) + γ V ϕ ( s t + 1 ) − V ϕ ( s t ) \delta_{t} =r(s,a)+\gamma V_{\phi } (s_{t+1} )-V_{\phi } (s_{t} ) δt=r(s,a)+γVϕ(st+1)−Vϕ(st)
在Actor网络部分,A2C使用Advantage function更新 π θ \pi_{\theta} πθ:
J θ = − log π θ ( s , a ) δ θ = − π θ ( s , a ) A t ( s , a ) J_{\theta }=-\log \pi _{\theta }(s,a)\delta _{\theta }=-\pi _{\theta }(s,a)A_{t}(s,a) Jθ=−logπθ(s,a)δθ=−πθ(s,a)At(s,a)