CHAPTER 6: DESIGN A KEY-VALUE STORE
Understand the problem and establish design scope
Each design achieves a specific balance regarding the tradeoffs of
the read, write, and memory usage. Another tradeoff has to be made was between consistency and availability.
• The size of a key-value pair is small: less than 10 KB.
• Ability to store big data.
• High availability: The system responds quickly, even during failures.
• High scalability: The system can be scaled to support large data set.
• Automatic scaling: The addition/deletion of servers should be automatic based on traffic.
• Tunable consistency.
• Low latency.
Single server key-value store
keeps everything in memory. Even though
memory access is fast, fitting everything in memory may be impossible due to the space constraint.
• Data compression
• Store only frequently used data in memory and the rest on disk
Even with these optimizations, a single server can reach its capacity very quickly. A
distributed key-value store is required to support big data.
Distributed key-value store
CAP (Consistency, Availability, Partition Tolerance)
CAP theorem
CAP theorem states it is impossible for a distributed system to simultaneously provide more than two of these three guarantees: consistency, availability, and partition tolerance.
Consistency: consistency means all clients see the same data at the same time no matter which node they connect to.
Availability: availability means any client which requests data gets a response even if some of the nodes are down.
Partition Tolerance: a partition indicates a communication break between two nodes.
Partition tolerance means the system continues to operate despite network partitions.

CP (consistency and partition tolerance) systems: a CP key-value store supports
consistency and partition tolerance while sacrificing availability.
AP (availability and partition tolerance) systems: an AP key-value store supports
availability and partition tolerance while sacrificing consistency.
CA (consistency and availability) systems: a CA key-value store supports consistency and availability while sacrificing partition tolerance. Since network failure is unavoidable, a distributed system must tolerate network partition. Thus, a CA system cannot exist in realworld applications.
Assume data are replicated on three replica nodes, n1, n2 and n3 as shown in Figure 6-2.
In the ideal world, network partition never occurs. Data written to n1 is automatically
replicated to n2 and n3. Both consistency and availability are achieved.

Real-world distributed systems
In a distributed system, partitions cannot be avoided, and when a partition occurs, we must choose between consistency and availability.
n3 goes down and cannot communicate with n1 and n2. If clients write data to n1 or n2, data cannot be propagated to n3. If data is written to n3 but not propagated to n1 and n2 yet, n1 and n2 would have stale data.

If we choose consistency over availability (CP system), we must block all write operations to n1 and n2 to avoid data inconsistency among these three servers, which makes the system unavailable.
However, if we choose availability over consistency (AP system), the system keeps accepting reads, even though it might return stale data. For writes, n1 and n2 will keep accepting writes, and data will be synced to n3 when the network partition is resolved.
System components
• Data partition
• Data replication
• Consistency
• Inconsistency resolution
• Handling failures
• System architecture diagram
• Write path
• Read path
Data partition
• Distribute data across multiple servers evenly.
• Minimize data movement when nodes are added or removed.

Automatic scaling: servers could be added and removed automatically depending on the load.
Heterogeneity: the number of virtual nodes for a server is proportional to the server capacity.
For example, servers with higher capacity are assigned with more virtual nodes.
Data replication
To achieve high availability and reliability, data must be replicated asynchronously over N servers, where N is a configurable parameter.

With virtual nodes, the first N nodes on the ring may be owned by fewer than N physical servers. To avoid this issue, we only choose unique servers while performing the clockwise walk logic.
Nodes in the same data center often fail at the same time due to power outages, network issues, natural disasters, etc. For better reliability, replicas are placed in distinct data centers, and data centers are connected through high-speed networks.
Consistency
N = The number of replicas
W = A write quorum of size W. For a write operation to be considered as successful, write operation must be acknowledged from W replicas.
R = A read quorum of size R. For a read operation to be considered as successful, read operation must wait for responses from at least R replicas.

W = 1 means that the coordinator must receive at least one acknowledgment before the write operation is considered as successful.
If W = 1 or R = 1, an operation is returned quickly because a coordinator only needs to wait for a response from any of the replicas. If W or R > 1, the system offers better consistency;
however, the query will be slower because the coordinator must wait for the response from the slowest replica.
If W + R > N, strong consistency is guaranteed because there must be at least one
overlapping node that has the latest data to ensure consistency.
If R = 1 and W = N, the system is optimized for a fast read.
If W = 1 and R = N, the system is optimized for fast write.
If W + R > N, strong consistency is guaranteed (Usually N = 3, W = R = 2).
If W + R <= N, strong consistency is not guaranteed.
Consistency models
A
consistency model defines the degree of data consistency, and a wide spectrum of possible
consistency models exist:
• Strong consistency: any read operation returns a value corresponding to the result of the most updated write data item. A client never sees out-of-date data.
• Weak consistency: subsequent read operations may not see the most updated value.
• Eventual consistency: this is a specific form of weak consistency. Given enough time, all updates are propagated, and all replicas are consistent.
Strong consistency is usually achieved by forcing a replica not to accept new reads/writes until every replica has agreed on current write.
Dynamo and Cassandra adopt eventual consistency, which is our recommended consistency model for our key-value store. From concurrent writes, eventual consistency allows inconsistent values to enter the system and force the client to read the values to reconcile.
Inconsistency resolution: versioning
Versioning and vector locks are used to solve inconsistency problems. Versioning means treating each data modification as a new immutable version of data.


These two changes are performed simultaneously.
Now, we have conflicting values, called versions v1 and v2.
we need a versioning system that can detect conflicts and reconcile conflicts.
A vector clock is a common technique to solve this problem.
A vector clock is a [server, version] pair associated with a data item. It can be used to check if one version precedes, succeeds, or in conflict with others.

Even though vector clocks can resolve conflicts, there are two notable downsides. First,vector clocks add complexity to the client because it needs to implement conflict resolution logic.
Second, the [server: version] pairs in the vector clock could grow rapidly. To fix this
problem, we set a threshold for the length, and if it exceeds the limit, the oldest pairs are removed.
This can lead to inefficiencies in reconciliation because the descendant relationship
cannot be determined accurately.
Handling failures
Failure detection
Usually, it requires at least two independent sources of information to mark a
server down.
As shown in Figure 6-10, all-to-all multicasting is a straightforward solution. However, this is inefficient when many servers are in the system.

Gossip protocol works as follows:
• Each node maintains a node membership list, which contains member IDs and heartbeat
counters.
• Each node periodically increments its heartbeat counter.
• Each node periodically sends heartbeats to a set of random nodes, which in turn
propagate to another set of nodes.
• Once nodes receive heartbeats, membership list is updated to the latest info.
• If the heartbeat has not increased for more than predefined periods, the member is
considered as offline.
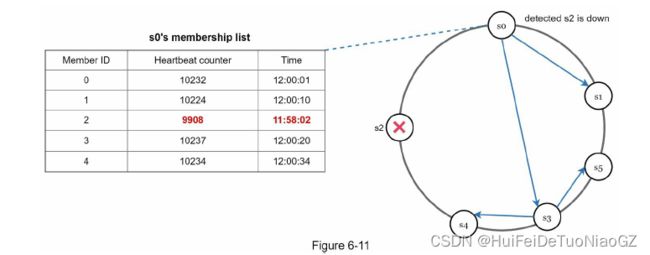
Node s0 sends heartbeats that include s2’s info to a set of random nodes. Once other nodes confirm that s2’s heartbeat counter has not been updated for a long time, node s2 is marked down, and this information is propagated to other nodes.
Handling temporary failures
“sloppy quorum” [4] is used to improve availability
the system chooses the first W healthy servers for writes and first R healthy servers for reads on the hash ring. Offline servers are ignored.
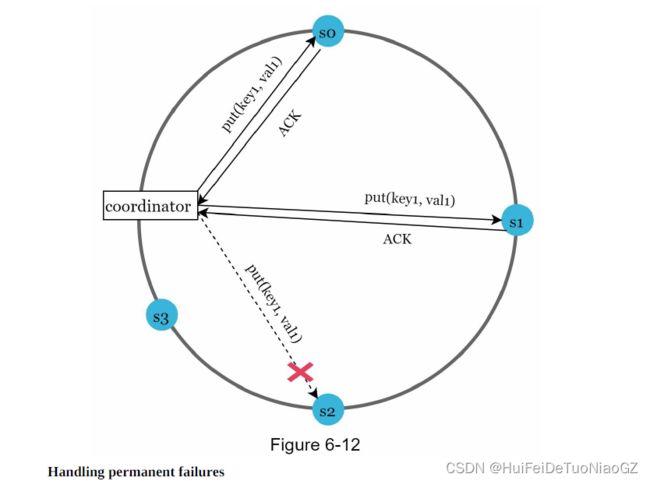
This process is called hinted handoff. Since s2 is unavailable in Figure 6-
12, reads and writes will be handled by s3 temporarily. When s2 comes back online, s3 will hand the data back to s2.
What if a replica is permanently unavailable? To handle such a situation, we implement an anti-entropy protocol to keep replicas in sync. Anti-entropy involves comparing each piece of data on replicas and updating each replica to the newest version. A Merkle tree is used for inconsistency detection and minimizing the amount of data transferred.




System architecture diagram

• Clients communicate with the key-value store through simple APIs: get(key) and put(key,
value).
• A coordinator is a node that acts as a proxy between the client and the key-value store.
• Nodes are distributed on a ring using consistent hashing.
• The system is completely decentralized so adding and moving nodes can be automatic.
• Data is replicated at multiple nodes.
• There is no single point of failure as every node has the same set of responsibilities.

Write path



The bloom filter is used to figure out which SSTables might contain the key.
