【2023全网最全最火】Selenium WebDriver教程(建议收藏)

在本教程中,我将向您介绍 Selenium Webdriver,它是当今市场上使用最广泛的自动化测试框架。它是开源的,可与所有著名的编程语言(如Java、Python、C#、Ruby、Perl等)一起使用,以实现浏览器活动的自动化。通过本文,我将告诉您开始使用 Selenium WebDriver 测试 Web 应用程序所需了解的所有信息。
以下是本教程的主题:
- 什么是 Selenium Webdriver?
- Selenium 容易学吗?
- Selenium 软件有什么作用?
- Selenium 的基本知识是什么?
- Selenium RC 的缺点和 WebDriver 的诞生
- 什么是浏览器元素?
- 定位网页上的浏览器元素
- 浏览器元素上的操作
什么是 Selenium WebDriver?
Selenium WebDriver 是一个基于 Web 的自动化测试框架,可以测试在各种Web浏览器和各种操作系统上启动的网页。实际上,您还可以自由使用各种编程语言(例如Java、Perl、Python、Ruby、C#、PHP 和 JavaScript)编写测试脚本。请注意,Mozilla Firefox 是 Selenium WebDriver 的默认浏览器。
但是很多时候,刚入门的测试人员会想到这个疑问:
Selenium 好学吗?
要用外行的话回答这个问题,我会说:”是的,是!”。Selenium 真的很容易学习和掌握,因为您只需要对任意一种常见的编程语言(例如 Java、C#、Python、Perl、Ruby、PHP)有基本的了解。预先掌握这些编程语言中的任何一种的都可有助于编写测试用例。但是,如果您没有,那就不要担心了。Selenium IDE 是一个可以有效使用的基于 GUI 的工具。
Selenium 软件有什么作用?
以下是 Selenium 软件最吸引人的一些用途:
- 自动化测试:在大型项目中,自动化测试会派上用场,在大型项目中,如果不是 Selenium,测试人员将必须手动测试每个创建的功能。使用 Selenium,所有手动任务都可以自动化,从而减轻了测试人员的负担和压力。
- 跨浏览器兼容性:Selenium 支持多种浏览器,例如:Chrome、Mozilla Firefox、Internet Explorer、Safari 和 Opera。
- 提高测试覆盖率:通过自动化的测试,可以减少总体测试时间,从而为测试人员腾出时间来同时在不同的测试场景下执行更多测试。
- 减少测试执行时间:由于 Selenium 支持并行测试执行,因此可以大大减少并行测试执行时间。
- 多操作系统支持:Selenium WebDriver 提供跨 Windows、Linux、UNIX、Mac 等多种操作系统的支持。使用 Selenium WebDriver,您可以在 Windows 操作系统上创建测试用例并在 Mac 操作系统上执行。
Selenium 的基本知识是什么?
WebDriver 是 Selenium v2.0 的一部分。Selenium v1 仅由 IDE,RC 和 Grid 组成。但是 Selenium 项目的主要突破是开发 WebDriver 并将其作为 Selenium v2 的替代产品引入。但是,随着 Selenium v3 的发布,不推荐使用 RC,而将其迁移到旧版软件包中。 您仍然可以下载并使用 RC,但不要期望对其提供任何支持。
简而言之,WebDriver相对于 RC 的优势是:
- 支持更多的编程语言、操作系统和 Web 浏览器
- 克服 Selenium 1 的局限性,例如文件上传、下载、弹出窗口和对话障碍
- 与 RC 相比,命令更简单,API 更好
- 支持批量测试,跨浏览器测试和数据驱动的测试
但是,与 RC 相比,缺点是无法生成测试报告。RC 生成详细的报告。
下图描述了 WebDriver 的工作方式:
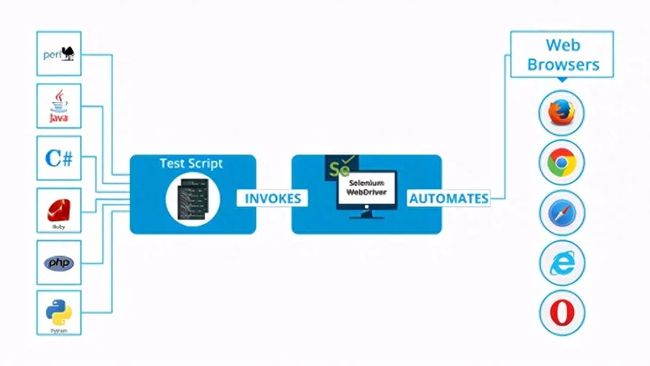
但是您是否想知道为什么需要 Selenium Webdriver?接下来,我将讨论 Selenium RC 的局限性,因为这是最终开发 WebDriver 的原因。
Selenium RC 的缺点和 WebDriver 的诞生
当我说 Selenium RC 推出时立即引起轰动时,您可能会感到惊讶。那是因为它克服了同源策略问题,而在使用 Selenium Core 测试 Web 应用程序时这是一个主要问题。但是您知道什么是同源政策问题吗?
同源策略是用于强制实施 Web 应用程序安全模型的规则。根据同源策略,当且仅当被测试的 JavaScript 和网页都来自同一域时,Web 浏览器才会允许 JavaScript 代码访问网页上的元素。Selenium Core 是基于 JavaScript 的测试工具,由于无法测试每个网页的原因而受到限制。
但是,当 Selenium RC 出现时,它使测试人员摆脱了同源政策问题。但是,RC 如何做到这一点? RC 通过使用另一个称为 Selenium RC 服务器的组件来做到这一点。 因此,RC 是由两个组件组合而成的工具:Selenium RC 服务器和 Selenium RC 客户端。
Selenium RC 服务器是一个 HTTP 代理服务器,旨在“欺骗”浏览器,使其相信 Selenium Core 和被测试的 Web 应用程序来自同一域。因此,不能阻止 JavaScript 代码访问和测试任何网站。
尽管 Selenium RC 受到了很大的欢迎,但它也有自己的问题。主要的是执行测试所花费的时间。由于 Selenium RC 服务器是浏览器与您的 Selenium 命令之间通信的中间人,因此执行测试非常耗时。除了时间因素之外,RC 的架构也有些复杂。
这种架构涉及首先将 Selenium Core 注入 Web 浏览器。然后,Selenium Core 将接收来自 RC 服务器的指令并将其转换为 JavaScript 命令。此 JavaScript 代码负责访问和测试 Web 元素。下面这张图有助于您将了解 RC 的工作原理。

为了克服这些问题,开发了 Selenium WebDriver。WebDriver更快,因为它直接与浏览器交互,并且不需要外部代理服务器。由于从操作系统级别控制浏览器,因此架构也更简单。下图将帮助您了解 WebDriver 的工作方式。
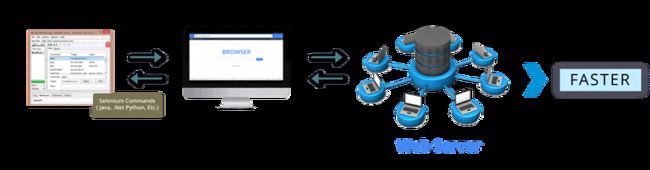
WebDriver 的另一个好处是它支持在 HTML Unit 驱动程序(无头驱动程序)上进行测试。当我们说无头驱动程序时,它是指浏览器没有 GUI 的事实。另一方面,RC 不支持 HTML Unit 驱动程序。这些是 WebDriver 比 RC 得分高的原因。
在学习 Selenium 的概念之前,您应该对 Java 或任何其他面向对象的编程语言有基本的了解。Selenium 支持的语言包括 C#、Java、Perl、PHP、Python 和 Ruby。当前,Selenium Webdriver 在 Java 和 C# 中最受欢迎。
现在,让我们继续,下一部分学习“浏览器元素”,我将告诉您这些元素是什么以及如何在这些 Web 元素上进行测试。
什么是浏览器元素?
元素是网页上存在的不同组件。我们在浏览时注意到的最常见元素是:
- 文本框
- CTA 按钮
- 图像
- 超链接
- 单选按钮 / 复选框
- 文字区 / 错误信息
- 下拉框 / 列表框 / 组合框
- Web表格 / HTML表格
- 框架
测试这些元素本质上意味着我们必须检查它们是否工作正常,并按照我们希望的方式进行响应。例如,如果我们正在测试文本框,您将对它进行什么测试?
- 我们是否能够将文本或数字发送到文本框
- 我们可以检索已传递到文本框等的文本吗?
如果我们正在测试图像,则可能需要:
- 下载图片
- 上传图片
- 点击图片链接
- 检索图像标题等。
类似地,可以对前面提到的每个元素执行操作。但是只有将元素放置在网页上之后,我们才能执行操作并开始对其进行测试,对吗? 因此,下一个主题,我将介绍元素定位器技术。
定位网页上存在的浏览器元素
网页上的每个元素都具有属性。元素可以具有多个属性,并且这些属性中的大多数对于不同的元素而言都是唯一的。例如,考虑具有两个元素的页面:图像和文本框。 这两个元素都有一个“名称”属性和一个“ ID”属性。这些属性值对于每个元素都必须是唯一的。 换句话说,两个元素不能具有相同的属性值。元素的“类名”可以具有相同的值。
在本例中,图像和文本框既不能具有相同的“ ID”值,也不能具有相同的“名称”值。但是,页面上的一组元素可能有一些共同的属性。稍后,我将告诉您这些属性是哪些,但是在此之前,让我列出我们可以用来定位元素的 8 个属性。 这些属性是 ID、名称、类名、标签名、链接文本、部分链接文本、CSS 和 XPath。
由于元素是使用这些属性定位的,因此我们将其称为“定位器”。定位器有:
- By.id
语法: driver.findElement(By.id(“xxx”));
- By.name
语法: driver.findElement(By.name(“xxx”));
- By.className
语法: driver.findElement(By.className(“xxx”));
- By.tagName
语法: driver.findElement(By.tagName(“xxx”));
- By.linkText
语法: driver.findElement(By.linkText(“xxx”));
- By.partialLinkText
语法: driver.findElement(By.partialLinkText(“xxx”));
- By.css
语法: driver.findElement(By.css(“xxx”));
- By.xpath
语法: driver.findElement(By.xpath(“xxx”));
通过查看上面的语法,您可能已经意识到定位器是在内部调用的。因此,在进行进一步操作之前,您需要学习可用于对元素执行操作的所有其他方法、浏览器命令和功能。
浏览器元素上的操作
从现在开始,您将获得很多乐趣,因为理论更少、代码更多。因此,请做好准备,打开Eclipse IDE,并安装必需的 Selenium 软件包。
要开始测试网页,我们需要首先打开浏览器,然后通过提供正确的 URL 导航到该网页?看看下面的代码,我在上面复制了同样的代码。Firefox 浏览器将首先启动,然后将导航到 Facebook 的登录页面。
package seleniumWebDriver;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
public class WebDriverClass
{
public static void main(String[] args)
{
System.setProperty("webdriver.gecko.driver", "files/geckodriver.exe");
WebDriver driver = new FirefoxDriver();
driver.get("https://www.facebook.com/");
driver.getTitle();
driver.quit();
}
}import
org.openqa.selenium.WebDriver; 是一个库包,其中包含启动加载有特定驱动程序的浏览器所需的类。
import
org.openqa.selenium.firefox.FirefoxDriver; 是一个库包,其中包含 FirefoxDriver 类,该类是启动 FirefoxDriver 作为 WebDriver 类启动的浏览器所需的。
System.setProperty(“webdriver.gecko.driver”, “files/geckodriver.exe”); – 该命令通知运行时引擎指定路径中存在 Gecko 驱动程序。在 Firefox 35 之后,我们需要下载 Gecko 驱动程序以使用 WebDriver。如果要在 Chrome 上进行测试,则必须下载ChromeDriver(这是一个.exe文件),并在此代码行中指定其路径。对于其他浏览器,我们也必须这样做。
WebDriver driver = new FirefoxDriver(); – 此命令用于启动新的 Firefox 驱动程序对象。
driver.get(“https://www.edureka.co/”); – 这个方法用于打开指定的URL。
driver.getTitle(); – 此命令获取浏览器中当前打开的选项卡的标题。
driver.quit(); – 此命令关闭浏览器驱动程序。
但是,如果您想导航到其他 URL 然后进行测试该怎么办?在这种情况下,您可以使用下面的代码片段所示的 navigation.to() 命令。然后,如果您想返回上一页,则可以通过使用navigation.back()命令来完成。 同样,要刷新当前页面,可以使用navigation.refresh() 命令。
driver.navigate().to(“https://www.edureka.co/testing-with-selenium-webdriver”);
driver.navigate().refresh();
driver.navigate().back();如果您想最大化浏览器窗口的大小,则可以使用下面的代码片段来实现。
driver.manage().window().maximize();如果要为浏览器窗口设置自定义尺寸,则可以设置自己的尺寸,如下面的代码片段所示。
Dimension d = new Dimension(420,600);
driver.manage().window().setSize(d);现在您已经了解了大多数基本知识,我们进入下一个主题。让我们尝试在网页上找到一个元素,然后执行所有可能的操作。
我很确定,你们所有人都有 Facebook 帐户。因此,让我向您展示如何绕过代码本身的凭据登录 Facebook。
登录页面中有两个文本字段,一个用于电子邮件 / 电话,另一个用于密码。我们必须找到这两个元素,将凭据传递给这些元素,然后找到第三个元素:需要单击的“登录”按钮。
请看下面的截图。这是 Facebook 登录页面的屏幕截图。
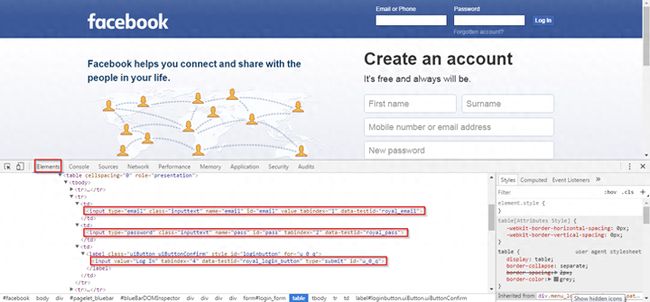
如果您检查(Ctlr + Shift + i)此页面,则将在浏览器中看到相同的窗口。然后,在“元素”下,将显示页面上存在的所有元素及其属性的列表。上面的屏幕快照中突出显示了三个部分。第一个突出显示的元素是电子邮件文本字段,第二个是密码文本字段,第三个是“登录”按钮。
如果您还记得,我在前面提到过可以使用元素定位器技术来定位这些元素。 让我们用它来定位这些元素并发送字段值。
这是查找元素的语法:driver.findElement(By.id(“xxx”));
为了发送它的值,我们可以使用方法 sendKeys(“credentials“);
要单击按钮,我们必须使用 click();
那么,让我们开始寻找元素并对其进行操作。其代码在下面的代码片段中。
driver.findElement(By.name("email")).sendKeys("[email protected]");
driver.findElement(By.name("pass")).sendKeys("xxxxxx");
driver.findElement(By.id("u_0_q")).click();在第 1 行中,我们通过其唯一的“名称”属性来标识 Email 元素,并将其发送给 EmailID。
在第 2 行中,我们通过其唯一的“名称”属性来标识 Password 元素,并将其发送给密码。
在第 3 行中,我们通过其唯一 ID 找到“登录”按钮元素,然后单击该按钮。
仅添加这些代码行可能还不够。那是因为页面的动态,它可能不会立即响应,并且在页面加载时,WebDriver 将终止并引发超时异常错误。此问题可能很快就不会在 Facebook 页面上发生,但很可能会在其他任何电子商务网站和其他动态网站上发生。
为了克服这个问题,我们需要使用一种先进的技术。我们需要请求我们的 WebDriver 在页面被访问并且页面完全加载之后等待,我们需要找到元素然后执行操作。
如果你想让你的 WebDriver 等待,直到所有元素加载到网页中,然后关闭浏览器,那么我们可以使用 driver.wait() 方法或 Threads.sleep() 方法来实现。但是,如果您正在编写更高级的代码,那么您应该使用隐式等待或显式等待。但是对于我们的情况,下面的命令就足够了。
driver.wait(5000);
// or use this:-
Thread.sleep(5000);但是,在使用等待条件时,请记住导入该库:
import java.util.concurrent.TimeUnit;
我们这样做是因为,等待类及其相关方法将出现在此库中。
下面是我所解释代码的完整代码片段。
package seleniumWebDriver;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.concurrent.TimeUnit;
public class WebDriverClass
{
public static void main(String[] args)
{
System.setProperty("webdriver.gecko.driver", "files/geckodriver.exe");
WebDriver driver = new FirefoxDriver();
driver.get("https://www.facebook.com/");
driver.manage().window().maximize();
driver.getTitle();
driver.navigate().to(“https://www.edureka.co/testing-with-selenium-webdriver”);
driver.navigate().back();
driver.navigate().refresh();
driver.wait(5000);
// or use
// Thread.sleep(5000);
driver.findElement(By.name("email")).sendKeys("[email protected]");
driver.findElement(By.name("pass")).sendKeys("xxxxxx");
driver.findElement(By.id("u_0_q")).click();
driver.quit();
}
}当您用实际的电子邮件和密码替换凭据并执行此代码时,Facebook 将在新窗口中打开,输入您的凭据并登录到您的帐户。
瞧! 您已成功登录,这意味着您的完整代码已完全执行。
我使用了 ID 和 Name 属性来定位元素。实际上,您可以使用任何其他定位器来查找元素。XPath 是最有用和最重要的定位器技术。但是,只要您甚至可以找到其中一个属性并将其用于定位元素,就可以了。
今天的分享就到此结束了,大家还有什么不懂的可以评论区下留言哈,如果我的文章对你有所帮助的话,可以点赞三联支持一下