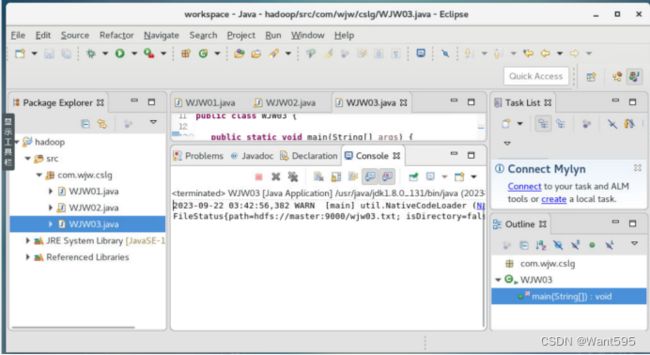
【大数据开发技术】实验05-HDFS目录与文件的创建删除与查询操作
文章目录
- 一、实验目标
- 二、实验要求
- 三、实验内容
- 四、实验步骤
一、实验目标
- 熟练掌握hadoop操作指令及HDFS命令行接口
- 掌握HDFS目录与文件的创建方法和文件写入到HDFS文件的方法
- 掌握HDFS目录与文件的删除方法
- 掌握查询文件状态信息和目录下所有文件的元数据信息的方法
二、实验要求
- 给出主要实验步骤成功的效果截图。
- 要求分别在本地和集群测试,给出测试效果截图
- 对本次实验工作进行全面的总结。
- 完成实验内容后,实验报告文件名加上学号姓名。
三、实验内容
-
创建目录,并将一个本地文件写入到该目录中,实现效果参考下图:
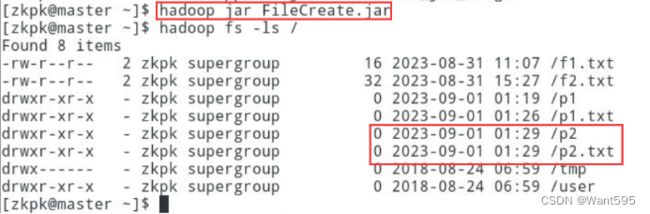
-
删除文件与目录,实现效果参考下图:
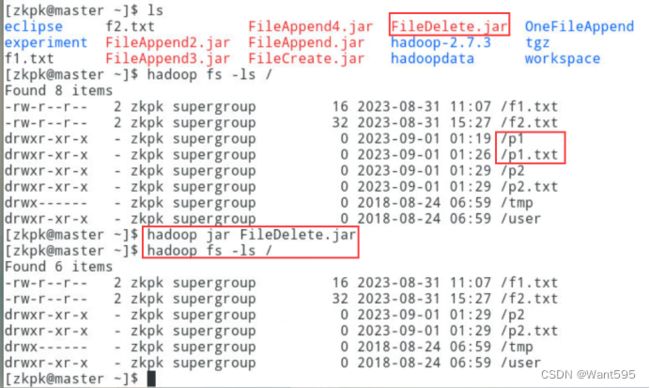
-
查询文件状态信息和目录下所有文件的元数据信息,实现效果参考下图:

四、实验步骤
- 创建目录,并将一个本地文件写入到该目录中
程序设计
package com.wjw.cslg;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class WJW01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
FileSystem fs = null;
args = new String[2];
args[0] = "hdfs://master:9000/wjw02.txt";
args[1] = "hdfs://master:9000/wjw02";
try{
for(int i=0; i<args.length; i++){
fs = FileSystem.get(URI.create(args[i]), conf);
fs.mkdirs(new Path(args[i]));
}
}catch (IOException e){
e.printStackTrace();
}
}
}
程序分析
本程序是一个Java程序,使用了Hadoop的API,主要功能是在HDFS上创建指定路径的目录。
首先,程序利用Configuration类创建一个配置对象conf,用于指定Hadoop的配置信息。然后利用FileSystem类创建一个文件系统对象fs,用于与HDFS交互。args数组表示用户在命令行中传入的参数,其中args[0]表示要创建的路径,args[1]表示要创建的目录名。
接下来,程序进入for循环语句,遍历args数组中的所有路径。在循环体中,程序调用FileSystem的get()方法获取一个文件系统对象,该方法的参数是一个URI对象和一个配置对象conf。URI对象表示HDFS上的路径,可以通过URI.create()方法创建。创建好文件系统对象后,程序调用mkdirs()方法创建指定的目录。
最后,程序捕获可能的IOException异常,并打印出错误信息。
总体来说,本程序比较简单,主要是熟悉Hadoop API的使用和理解创建HDFS目录的基本原理。
运行结果

- 删除文件与目录
程序设计
package com.wjw.cslg;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class WJW02 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
FileSystem fs = null;
args = new String[2];
args[0] = "hdfs://master:9000/wjw02.txt";
args[1] = "hdfs://master:9000/wjw02";
try{
for(int i=0; i<args.length; i++){
fs = FileSystem.get(URI.create(args[i]), conf);
fs.delete(new Path(args[i]));
}
}catch (IOException e){
e.printStackTrace();
}
}
}
程序分析
本程序是一个Java程序,使用了Hadoop的API,主要功能是在HDFS上删除指定路径的文件或目录。
首先,程序利用Configuration类创建一个配置对象conf,用于指定Hadoop的配置信息。然后利用FileSystem类创建一个文件系统对象fs,用于与HDFS交互。args数组表示用户在命令行中传入的参数,其中args[0]表示要删除的路径,args[1]表示要删除的目录名。
接下来,程序进入for循环语句,遍历args数组中的所有路径。在循环体中,程序调用FileSystem的get()方法获取一个文件系统对象,该方法的参数是一个URI对象和一个配置对象conf。URI对象表示HDFS上的路径,可以通过URI.create()方法创建。创建好文件系统对象后,程序调用delete()方法删除指定的文件或目录。
最后,程序捕获可能的IOException异常,并打印出错误信息。
总体来说,本程序也比较简单,主要是熟悉Hadoop API的使用和理解删除HDFS文件或目录的基本原理。需要注意的是,删除文件或目录时,需要确保目标存在并且没有被其他程序或用户锁定,否则会删除失败。
运行结果
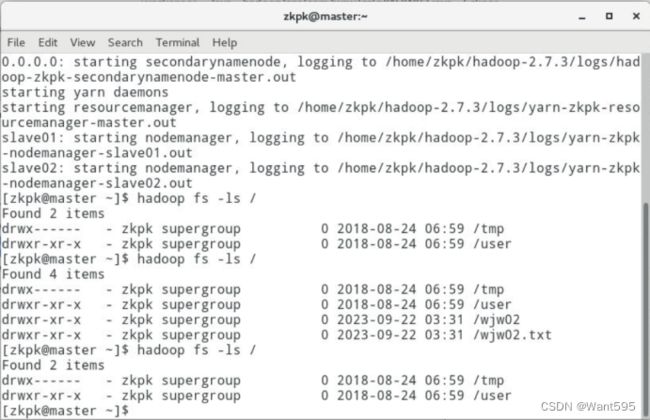
- 查询文件状态信息和目录下所有文件的元数据信息
程序设计
package com.wjw.cslg;
import java.io.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.*;
import org.apache.hadoop.conf.*;
import java.net.*;
public class WJW03 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
args=new String[1];
args[0]="hdfs://master:9000/wjw01.txt";
conf.set("fs.DefailtFS","hdfs://master:9000/");
FileSystem fs=null;
try{
fs=FileSystem.get(URI.create(args[0]),conf);
FileStatus filestatus[]=fs.listStatus(new Path(args[0]));
for(int i=0;i<filestatus.length;i++){
System.out.println(filestatus[i]);
}
}catch(IOException e){
e.printStackTrace();
}
}
程序分析
本程序是一个Java程序,使用了Hadoop的API,主要功能是在HDFS上获取指定路径下的所有文件或目录。
首先,程序利用Configuration类创建一个配置对象conf,用于指定Hadoop的配置信息。接着,程序使用URI.create()方法创建一个URI对象并将其作为参数传递给FileSystem.get()方法,该方法返回一个FileSystem对象,用于与HDFS交互。args数组表示用户在命令行中传入的参数,其中args[0]表示要获取的路径。
接下来,程序调用FileSystem的listStatus()方法获取指定路径下的所有文件或目录的信息,并将结果存储在一个FileStatus数组中。最后,程序遍历该数组并输出每个文件或目录的信息到控制台。
需要注意的是,程序在创建配置对象conf时,使用了set()方法设置了fs.DefaultFS属性,用于指定Hadoop集群的默认文件系统地址,即"fs.defaultFS",而不是"fs.DefailtFS"(注意单词拼写的正确性)。
总体来说,本程序也比较简单,主要用于熟悉Hadoop API的使用和理解获取HDFS路径下文件或目录信息的基本原理。需要注意的是,listStatus()方法只返回指定路径下的直接子文件或目录的信息,而不会递归地返回所有子文件或目录的信息。如果要获取所有子文件或目录的信息,需要使用递归算法来实现。
运行结果