阿里云服务器部署zookeeper集群+kafka集群
阿里云服务器部署zookeeper集群+kafka集群
阿里云服务器部署zookeeper集群以及kafka集群,连接java 整了好几天没整好,大年二十九晚上的一次灵光乍现,解决了问题。
背景: 想实现一个netty服务端集成到微服务中去,netty服务端主要实现报文数据的接收以及转发,具体是 硬件端发送报文
----> 到netty服务端 ------> kafka中转数据到 flink
,kafka采用集群部署的方式,由zookeeper集群作为协调管理kafka,很常见,也很常用,但是按照网上的部署方式,部署完毕后连接java,死活连接不上
问题解决,想了一下肯定是kafka配置文件的问题
下面进入正题:
zookeeper 的部署,没什么好说的,按照网上的大部分博客就可以,大同小异,当然详细参数的配置还是要到官网上去翻文档官网
我自己的配置贴出来方便大家参考
#由于我的java程序不操作zookeeper,所以都是很基本的配置
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zookeeper
clientPort=2181
dataDir=/opt/module/zookeeper-3.5.7/zkData
#######################cluster##########################
#集群配置zoo.cfg
#这里的server1,server2,server3是阿里云服务器的内网地址
#在/etc/hosts 文件中配置
#xxx.xxx.xxx.xxx server1
#xxx.xxx.xxx.xxx server2
#xxx.xxx.xxx.xxx server3
#在这里就能用server1了
server.2=server1:2888:3888
server.3=server2:2888:3888
server.4=server3:2888:3888
#服务器一共三台,其他两台的zookeeper配置一样
然后是kafka的集群配置
server1 的kafka安装目录/config/server.properties
#这个必须不能重复,这里broker.id=0 那么server2的kafka配置broker.id=1,以此类推 (重点)
broker.id=0
#内网borker相互通信(重点)
listeners=PLAINTEXT://内网ip:9092
#暴露外网borker供java程序使用(重点)
advertised.listeners=PLAINTEXT://公网ip:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/module/kafka_2.11-2.4.1/datas
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#注册到zookeeper集群(重点)
zookeeper.connect=server1:2181,server2:2181,server3:2181
#超时时间
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
auto.create.topics.enable=true
server1 的kafka安装目录/config/producer.properties
#主要配置,其他按需
bootstrap.servers=公网ip1:9092,公网ip2:9092,公网ip3:9092
server1 的kafka安装目录/config/consumer.properties
#主要配置,其他按需
bootstrap.servers=公网ip1:9092,公网ip2:9092,公网ip3:9092
其他服务器,server2,server3的kafka配置基本上和server1一样,除了个别参数
broker.id
listeners
advertised.listeners
log.dirs
这些要配置服务器自己对应的参数,例如公网,私网ip,文件路径,其他参数配置的都一样
集群的ip配置都是以逗号隔开,单机部署的话,就写一个就可以
#集群
bootstrap.servers=公网ip1:9092,公网ip2:9092,公网ip3:9092
#单机
bootstrap.servers=公网ip1:9092
一般这种情况下配置好后zookeeper和kafka
集群正常启动后就可以正常连上java进行开发调试了,但是,可恶的阿里云服务器,相互之间外网通信有安全组规则拦截,需要在阿里云控制台的安全组配置当中加上这几台已经部署了kafka集群的公网ip地址,真是奇葩!!!
所以具体解决问题的方法,是一个安全组规则的配置
 配置完成后,启动集群,验证一下收发消息
配置完成后,启动集群,验证一下收发消息
服务器开启producer,consumer
#producer,配置环境变量后在哪里都可以执行,没配就去kafka安装目录的bin下执行
kafka-console-producer.sh --broker-list 公网ip:9092 --topic first
#consumer
kafka-console-consumer.sh --bootstrap-server 公网ip:9092 --from-beginning --topic first
具体效果
producer

consumer
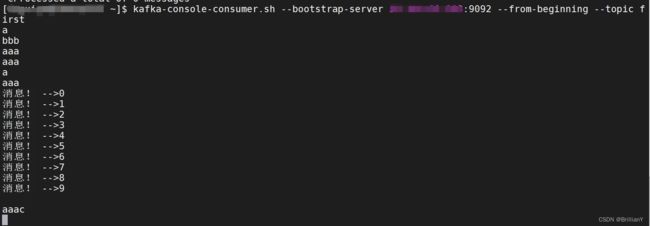 java程序验证,结果可以在上面的consumer里体现出来
java程序验证,结果可以在上面的consumer里体现出来
public class KafkaTest {
public static void main(String[] args) {
Properties props = new Properties();
//集群地址
props.put("bootstrap.servers", "公网ip:9092,公网ip:9092,公网ip:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("first", Integer.toString(i),"消息! -->" + i));
}
producer.close();
}
}
结尾:疫情已经过去,之后的行情也会逐渐好转,我相信努力是会有回报的,共勉。