仔仔细细的给您讲,如何建立数据仓库
数据仓库的定位
在整个数据价值生产链路中,数据仓库的主要作用就是中心化分发,将原始数据与数据价值挖掘活动隔离。所有的原始数据都会进入数据仓库,再由数据仓库统一分发给下游的数据使用者。这样的结构实现了原始数据与数据分析工作的解耦,让业务活动可以专注于生产,也让数据价值挖掘可以专注于分析。
且不谈数据仓库对数据做了怎样的处理,光是把数据集中到一起再分发,本身就已经提升了整个数据价值生产链路的运转效率了。反过来说,只要做到了数据的中心化分发,隔离业务与数据生产,就实现了一个最简单的数据仓库,它满足了数据仓库定义中的第一条:集成。
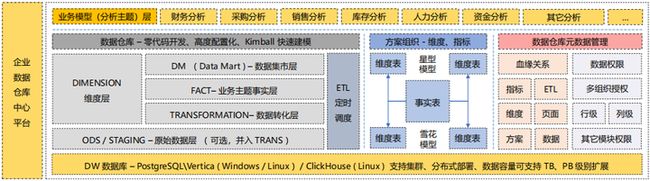
数据平台系统
在最原始的时候,数据生产工作是很简单地直接使用一些数据表来做计算,甚至可能连数据库都没有,就是一些表格而已,分析师可能就是每天手动汇总然后出一些报表来辅助领导做出决策。 如果分析师觉得这样每天重复工作的效率太低,他们就会朝着「自动化」的方向前进,构建起一个个数据系统。
给每日定时定量的任务加上任务调度系统,实现每日工作的自动化;建立数据管道,让原始数据通过管道自动变成数据分析所需要的报表形式;建立质量管控系统,自动处理脏乱数据并监测错误率等指标,确保数据质量。
如果分析师们希望让数据更容易使用,他们就会朝着「易使用」的方向前进,构建起一个个数据产品。所谓的「易使用」,也可以说成是「产品化」。最直接的方法莫过于建立一个数据仓库了。正如上面所说,光是实现数据的中心化分发,隔离业务生产与数据生产,就已经能让数据好用不少。
除了数据仓库之外,为了能让整个团队更好地使用和理解数据,我们也需要进行元数据管理工作。数据产品最后的形态就是各种报表了,汇总了各项重要信息,能够快速了解业务系统的整体现状以便做出下一步决策。 「自动化」和「易使用」两个方向的发展,汇聚在一起就成了数据平台系统。这个系统既依赖于「自动化」的程度来保证稳定高效的运转,也依赖于「产品化」的程度来保证用户能够方便快捷地挖掘数据价值,指导业务决策。
尽管在实际实践中,数据仓库的建设往往都伴随着一定的自动化工作,但这只是为了让数据仓库更为高效。从最本质的角度来说,「让数据更好用」,才是数据仓库建设的核心目标,下面就对这一点来展开说明。
数据使用的痛点
在现实的实践中,往往是先开始发展业务,然后有了数据团队来直接对原始的业务数据做处理分析,辅助业务决策。随着业务规模的增长和复杂度的增加,原始的方法渐渐扛不住了。比如,数据源很多,需要分别提取。业务数据存在一些错乱的情况,取数后还需要做检查和清洗。整体的工作效率受到了很大影响。这时候数据团队就会说,这个数据系统不好用,有许多痛点,需要做出改变。于是大家就想起了数据仓库,希望它能够解决问题。

就让我们来梳理一下,细化之后都有哪些痛点。
P0 基础
在这个层级上的痛点,会极大地影响整个数据价值链条的运转,要么严重降低效率,要么破坏分析的准确性。因此,只要是打算挖掘数据价值,无论是否建立狭义上的数据仓库,都必须要解决这个层级上的痛点。
数据异构:数据存储在不同的数据库或文件系统上,在使用前必须先进行汇总,当表很多很零散的时候,处理起来非常不方便。这个痛点对效率带来的影响,会随着表数量的增长而呈指数上升。如果不管不顾,最后很可能让分析处理工作陷入汇总泥潭。
脏数据:错值、空值、意义不明的业务代码、同一实体多个别名等等,这些都会对分析产生巨大的干扰。正所谓「垃圾进,垃圾出」,为了保证分析结果的正确性,脏数据是必须处理干净。
所有的数据团队,只要在正常输出数据价值,都会解决这些痛点。将数据汇总到统一的数据库中供分析使用,在进行分析前对数据进行清洗,这就已经是数据仓库的雏形了。
P1 进阶
在这个层级上的痛点,主要体现为数据的使用难度大,学习成本高。往往正是因为这个层级的痛点无法通过简单的修补方式解决,需要一套完整系统的方案,数据团队才会想要建立一个传统意义上的数据仓库。
强耦合:同一实体的数据混杂分散在不同的源数据表里,难以直接使用。比如,希望按品牌分析商品的品类占比。但商品的品类和品牌信息都不在商品表中,而是在订单表里。每次使用都需要从订单表中提取相应的数据,极其费事。这种情况在实践中非常常见,原因有很多,比如来自爬虫的数据会受到可爬取接口的限制。

复杂结构:存在多重联结或者树形结构等较复杂的设计,SQL难写,查询效率也不高。树形结构常用于业务生产,对单点读写来说是一种高效的结构,但对于分析场景来说就非常不方便。
实体关系模糊:数据表无法直接体现要分析的业务过程,需要提炼加工。比如希望分析对比不同流量入口的业务表现,但实际存储的数据可能会很零散,第一个大问题就是确定都有哪些流量入口,哪些指标可以体现业务水平。接着的问题就是,怎么把业务表现与流量入口关联起来。像强耦合、复杂结构这样的问题还能通过技术解决。实体关系模糊的问题就需要深入理解业务了。错误的理解可能会导致错误的关联,这一点会极大加重新人的工作负担。
难以上手:数据表繁杂,新人难以理解使用。杂乱无章的数据表带来的一大问题就是交接困难,新人面对一大堆表,尤其是缺乏良好命名的表,根本就一头雾水不知道如何下手。如果再缺失相应的文档,那简直就是灾难。
粒度混乱:同一个数据表里,数据的粒度不同。举例:地理位置信息,可能会把市级数据和省级数据放在同一个表里。粒度混乱会给分析带来非常大的麻烦。对于那些包含业务指标的数据,如果无法确定这个指标的统计口径是按天还是按周,就不知道该如何进行分析。对于像省市信息这样的数据,缺乏统一的数据粒度,也会让使用者在关联这张表时不得不增加一些筛选操作,比如希望获取省一级的信息,就需要过滤掉市一级的信息以免混淆。粒度混乱虽然不复杂,但却是很容易被忽略的一个问题,往往会因为统计口径的不统一造成严重的分析错误。

P2 优化
在这个层级上的痛点,就属于有点痛,但凑合凑合也能用的水准。处理他们的急迫性没那么大,不过要是有时间做了,还是能带来一些回报的。
查询缓慢:查询缓慢可以说是最常见的优化类痛点了。引起缓慢的问题有很多,比如索引或分区设置不合理,SQL没优化好,表结构不适合分析场景,或者存储的数据库本身的大规模查询能力就比较薄弱等等。提升查询效率也是个需要不断迭代优化的工作,它不是那么紧迫但也同样重要。
关联过深:在实体-关系模型中,如果严格遵守3NF范式构建,很容易出现关联过深的问题。也就是想要使用一个实体的数据必须要联结3张以上的表才能触达,而这些中间关联表的数据完全不会用上。这个问题不那么重要,分析师凑合一下也能用,不过肯定还是希望能通过一层关联来获取,更为方便。
P3 拓展
这个层级上的痛点往往是特异化的,它不会影响一般的通用业务,但对于特定需求,是必须解决的。
缺少历史:当前的数据不能代表历史情况,这样的数据无法做出有效分析,只能得到错误结论。为此就需要做一些特殊设计来实现。只是,有时候做分析并不需要所有维度的历史信息,这样的需求是比较特异化的,可以按需开发。
特殊需求:像大宽表、轻聚合表等,它们并不是数据仓库的核心构件,但对于下游使用有很大帮助,比如节约计算资源,方便接入报表工具等等。
免责声明:本公众号所发布的文章为本公众号原创,或者是在网络搜索到的优秀文章进行的编辑整理,文章版权归原作者所有,仅供读者朋友们学习、参考。对于分享的非原创文章,有些因为无法找到真正来源,如果标错来源或者对于文章中所使用的图片、链接等所包含但不限于软件、资料等,如有侵权,请直接联系后台,说明具体的文章,后台会尽快删除。给您带来的不便,深表歉意。