docker&kubernets篇(二十三)
kubernet-pod 设计
在Kubernetes中,能够被创建、调度和管理的最小单元是pod,而非单个容器。前面已经说过,一个pod是由若干个Docker容器构成的容器组(pod意为豆荚,里面容纳了多个豆子,很形象)。这里需要强调的是,pod里的容器共享network namespace,并通过volume机制共享一部分存储。
❏ pod是IP等网络资源的分配的基本单位,这个IP及其对应的network namespace是由pod里的容器共享的;
❏ pod内的所有容器也共享volume。当有一个volume被挂载在同属一个pod的多个Docker容器的文件系统上时,该volume可以被这些容器共享。
另外,从Linux namespace的角度看,同属一个pod的容器还共享以下namespace。
❏ IPC namespace,即同一个pod内的应用容器能够使用System V IPC或POSIX消息队列进行通信。❏ UTS namespace,即同一个pod内的应用容器共享主机名。
这是一个怎么样的场景呢?如果运行起来的是一个网站系统,似乎并不需要这些特性,因为没必要读取超过网站内容外的文件,况且如需连接其他容器(比如MySQL),直接采用IP访问不也能实现吗?但试想一下,有一个应用叫“云控制器”,它不是一个简单的网站,而是由3个独立的进程组成的。其中进程A是一个负责响应和处理用户请求的Web服务器;进程B是一个负责转发A产生日志的定时任务;进程C负责监控A和B的PID存活情况并发送定时心跳给监控组件。在传统的部署方法里,该服务的3个进程一定是被部署在同一个机器里面,这个机器也会被命名为“云控制器服务节点”。可是采用容器方案之后呢
pod正是为了解决“如何合理使用容器支撑企业级复杂应用”这个问题而诞生的。这也是Kubernetes明显区别于其他各类容器编排调度工具的显著特性。Kubernetes也是目前唯一一个没有大谈特谈所谓“轻应用”和“十二要素应用”概念的一个Docker容器编排系统,毕竟它的设计理念就是要支持绝大多数应用的原生形态。我们可以看到它的官方示例中有很多演示如何发布诸如HBase、Hazelcast、Cassandra等分布式服务的,我们团队的很多实际经验也是在如何使用Kubernetes和Docker发布Cloud Foundry这样的分布式系统上。从这一点上来讲,Kubernetes的设计确实让大多数竞争者望尘莫及
前面也讲到,当系统运行着数量庞大的pod时,用户或者系统管理员如何有效地定位与组织这些pod就成了一个重要问题。Kubernetes的解决方案是label。每个pod都有一个属性"labels"——一组键/值对,形如:
"labels": { "key1" : "value1", "key2" : "value2"}
通过label,可以在Kubernetes集群管理工具kubectl中方便地实现pod等资源对象的定位和组织,只要传入-l key=value参数即可,例如列举所有匹配标签{“name”:“nginx”}的pod可以这么操作:
$ kubectl get pods -l name=nginx
label的用途并非仅限于此,Kubernetes中的其他对象,如replication controller和service,同样可以通过label对pod进行定位和组织。事实上,在Kubernetes中,label是一种重要的且被广泛应用的组织、分类和选择Kubernetes对象的机制,因此下文将详细介绍Kubernetes label和label selector的工作原理。
-
label和label selector与pod协作labels属性是一组绑定到Kubernetes对象(如pod)上的键/值对,同一个对象labels属性的key必须独一无二。label的数据结构非常简单,就是一个key和value均为string类型的map结构。
在Kubernetes对象创建时,label进行绑定操作,当然,绑定后label也能够任意增删和修改,这些对象根据各自的label被划分子集。Kubernetes设计者引入label的主要目的是面向用户,使之成为用户级的Kubernetes对象标识属性,因为包含Kubernetes对象功能性和特征性描述的label比对象名或UID更加用户友好和有意义,而且使用户能够以一种松耦合的方式实现自身组织结构到系统对象之间的映射,无须客户端存储这些映射关系。但是,label一般不直接作为系统内部唯一标识Kubernetes对象的依据,因为不同于对象名和UID, label并不保证唯一性。
利用一个label的key代表一个资源管理维度(如release、environment等),不同的Kubernetes对象携带一个或一组相同的label,是Kubernetes实现多维度资源管理的精华所在。一个复杂的分布式应用包括若干个层级,简单可以分成前端、后端、中间层等。从应用运行环境角度区分,又分为开发环境、测试环境和生产环境等。有时应用为了升级需要可能同时存在稳定版和升级测试版。在一个多租户的系统中,系统空间又根据不同用户进行划分。不同系统组件的更新周期也存在差异,有些更新频率是周级别,有些则是日级别。因此,根据上述讨论的不同维度,可以为基于容器的服务系统的系统实体–pod贴上不同的标签,方便管理和维护,示例如下。
"release" : "stable", "release" : "canary", ... "environment" : "dev", "environment" : "qa", "environment" : "production", ... "tier" : "frontend", "tier" : "backend", "tier" : "middleware", ... "partition" : "customerA", "partition" : "customerB", ... "track" : "daily", "track" : "weekly", ...以上只是一些示例,用户完全可以根据自身实际情况自由地创建label。labels属性由一组键/值对组成。一个合法的key由两部分组成——前缀(prefix)和名字(name),中间由一个“/”分隔,前缀和“/”是可选的,表示属于哪个域。name字段最多由63个字符组成,接受的字符包括a-z,0-9和“-”,全部小写,开头和结尾只能是小写字母和数字([a-z,0-9]),中间用“-”连接,譬如2n1-ame0作为key值是合法的,但An1-ame0或2n1_ame0是非法的。如果指定了前缀,则前缀必须是一个DNS子域名(即一系列用“.”分隔的DNS标签,总长度不超过253个字符)。如果前缀是缺省的,则认为该label是用户私有的,系统组件如果要使用labels,必须指定一个前缀,譬如前缀kubernetes.io就是Kubernetes核心组件的保留前缀。
一个合法的value最多由63个字符组成,接受的字符包括A-Z, a-z,0-9, “-”,“_”和“.”,但第一个字符必须是[A-Za-z0-9]中的一个。label selector是Kubernetes核心的分组机制,通过label selector,客户端或用户能够识别一组有共同特征或属性的Kubernetes对象。一个label selector可以由多个查询条件组成,这些查询条件用逗号分隔。当一个label selector存在多个查询条件时,这些查询条件需要同时满足,这时逗号就充当“逻辑与”的作用。在实际应用中,label selector经常作为发送给APIServer的RESTful查询请求的条件参数,用于检索一个与label selector匹配的Kubernetes对象列表。Kubernetes API目前支持以下两种类型的label selector查询条件。
- 基于值相等的查询条件
通过等值匹配label的key和value来过滤Kubernetes对象。匹配的Kubernetes对象必须包含所有指定的label(包括key和value),当然这些对象可能还包含其他的label,这并不影响被label selector选中。这种类型的label selector支持3种操作符:=、==和!=,其中前两个操作符从在语法上是等价的且代表“相等”的语意,而最后一个操作符代表“不相等”的语意。请看下面这两个例子。
environment = productiontier ! = frontend
前者选择所有的key值等于environment而且value值等于production的资源对象,后者选择所有的key值等于tier且value值不等于frontend的资源对象。如果想过滤出位于production环境但非前端的资源对象可以使用,操作符
environment=production, tier! =frontend
- 基于子集的查询条件
通过匹配label的key及其对应的value集合来过滤Kubernetes对象。匹配的Kubernetes对象必须包含所有指定的label(比如,所有的key值和每个key对应的至少一个value值)。这种类型的label selector支持3种操作符:in、notin和exists(exists操作符只适用于对key值的比较)。请看下面这3个例子。
environment in (production, qa)
tier notin (frontend, backend)
partition
第一个例子选择所有的key值等于environment且value值等于production或qa的资源对象。
第二个例子选择所有的key值等于tier而且value值不等于frontend且backend的资源对象。
第三个例子选择所有的labels属性中包含key值等于partition的资源对象,不需要检查value值。
可以看出,基于值相等的查询条件是基于子集的查询条件的一个特例,因为key=value等价于key in value,类似地,key! =value等价于key notin (value)。在一个label selector中,基于子集的查询条件可以和基于值相等的查询条件混合使用,例如,partition in (customerA, customerB), environment! =qa。Kubernetes API的LIST(返回一个特定的资源对象列表)和WATCH(检测一个特定的资源对象的数据变化情况)操作可能会用到label selector来过滤出返回的资源对象的某个子集。label selector通过查询参数的方式传入RESTful API请求,以上提到的两种查询条件均支持,如下所示。❏ 基于值相等的查询条件:? labels=key1%3Dvalue1, key2%3Dvalue2❏ 基于子集的查询条件:? labels=key+in+%28value1%2Cvalue2%29%2Ckey2+notin+%28value3
最后要说明的是,根据label的特点,同一个pod(或其他资源对象)可能同时属于多个对象集合(回忆一下venn图集合相交的情况)。这一特性促进了扁平化、多维度的服务组织和部署架构,这对集群的管理(譬如配置和部署等)和应用的自我检查和分析(如日志、监控、预警和分析等)非常有用。如果没有label这种将资源对象划分集合的能力,就需要创建很多隐含联系而且属性重叠的资源集合,而我们知道,单纯的分层嵌套的组织结构不能很好地支持从多个维度对系统资源对象集合进行切割。
- pod的现状和未来走向
由于pod对于Kubernetes来说非常重要,这里有必要说明一下这个模型未来的发展方向,以便读者更好地理解pod设计者的用心。
● 资源共享和通信
目前pod内的容器共享同一个network namespace、IP资源和端口区间,能够通过localhost进行相互间的通信(下文会有实验说明)。在一个扁平化的共享网络空间中,每个pod都拥有一个IP地址,通过该IP地址,pod内的容器就能够与其他宿主机、虚拟机或者容器进行通信(更多关于网络的细节请参见8.5节)。pod内容器的的主机名被设置成pod的名字。pod还可以为pod内的容器指定了一组共享的存储卷(volume),这些存储卷的作用是方便pod内容器之间共享数据以及在容器重启过程中避免数据丢失。而在未来,pod内的容器之间将能够共享CPU和内存[插图],这就意味着,将来pod里的各个容器可以完美地实现一种“超亲密”的关系,就像在虚拟机里部署和启动多个应用的过程一样,最终可以在一个pod中部署和管理多个紧密协作的容器,为这个pod而非每个容器设置一个资源上限(比如2GB内存),然后为某个关键容器设置最少的资源配额(比如60%),让其他辅助类进程共同竞争剩余的资源(40%),这无疑是一个十分有用的特性。
● 集中式管理
目前而言,pod对于Kubernetes来说最有用的价值就是“原子化调度”,即在为一个pod选择目的宿主机时,Kubernetes会考量这个机器是否能够放下整个pod,而避免出现本应该部署在一起的容器因为资源不足无法满足“超亲密”关系的尴尬。而在未来,与Docker提供的原始底层容器接口不同,pod会进一步简化应用部署和管理流程。逐步实现Docker容器的协同定位、命运共担[插图]、协同复制、主机托管、资源共享、协调复制和依赖管理的全自动处理。
- pod的使用场景
前面已经列举过pod如何处理紧密协作的多个进程的方法,这里还可以列举出符合这类关系的很多应用场景,如下所示:❏ 一个内容管理系统,包括文件和数据加载器,本地缓存管理系统的组合;❏ 一个常规应用和它的日志和检查点的备份、压缩、轮换、快照系统等的组合;❏ 一个常规应用和它的数据变化监测器、日志实时收集器、事件发布器等的组合;❏ 一个常规服务和它的网络代理、桥接和适配器等网络辅助组件的组合。
- pod使用实例
使用Kubernetes的客户端工具kubectl来创建pod,该命令行工具支持对Kubernetes对象(pod、replication controller、service)的增、删、改、查操作以及其他对集群的管理操作。创建Kubernetes资源对象的一般方法如下所示。
kubectl create -f obj.json
其中obj.json可以是定义pod、replication controller、service等Kubernetes对象的JSON格式的资源配置文件。先来看一个简单的例子。
{
"kind": "Pod",
"apiVersion": "v1",
"metadata": {
"name": "podtest",
"labels": {
"name": "redis-master"
}
},
"spec": {
"containers": [{
"name": "master1",
"image": "k8stest/redis:test",
"ports": [{
"containerPort": 6379,
"hostPort": 6388
}]
}, {
"name": "master2",
"image": "k8stest/sshd:test",
"ports": [{
"containerPort": 22,
"hostPort": 8888
}]
}]
}
}
以上配置信息描述了一个name为podtest的对象。而该配置信息的kind字段表明该对象是一个pod。apiVersion字段表明客户端使用的服务端API版本是v1。
spec:containers字段描述了pod内的容器的属性,包括:容器名(name)、镜像(image)、端口映射(ports)等。其中ports字段由两个属性值组成:containerPort(容器端口)和hostPort(主机端口), Kubernetes自动实现了用户容器端口到宿主机端口的映射关系。
这里需要详细说明下spec字段。所有的资源对象都会在该字段下告诉系统自己的期望状态,而Kubernetes负责收集该资源对象的当前状态与期望状态进行匹配。
例如,当创建一个pod时,声明该pod容器正常运行所需的计算资源,那么Kubernetes不论发生什么情况都要保证pod内的容器正常运行。如果pod内的容器没有运行(譬如发生程序错误), Kubernetes就会不停地重新创建pod对象,这个过程将一直持续到使用者删除该pod为止。labels字段即该pod的标签,该pod只有一个标签:redis-master。将以上配置内容写入testpod.json文件,并根据该配置文件创建一个包含两个容器的pod。这里需要注意两类端口冲突的问题,第一类是pod内部的端口冲突,即同一个pod内的容器端口不能重复,否则会发生端口冲突;另外一类是宿主机端口冲突,即同一个pod的不同容器的端口可能会映射到宿主机上的同一个端口,这样也会引起端口冲突。这两个问题都需要用户自己定义清楚,否则就会收到“端口被占用”的错误。
- 如何编写一个pod的描述文件
在上面的实践中,我们已经看到了一个基本的pod描述文件的内容,那么如何根据需要编写一个完整、正确的pod资源文件(manifest)呢?除去那些共性的字段(比如ID等元数据),需要重点关注的是pod的期望状态(spec)字段。只要这里各字段的含义解析清楚了,pod资源文件的写法问题也就迎刃而解了。首先是元数据部分,如表所示。(pod manifest字段说明(元数据))
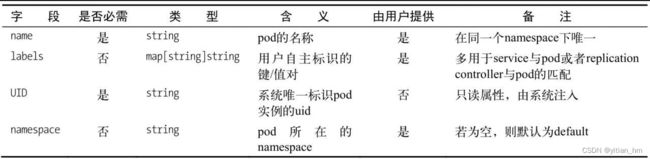
然后定义pod内容器信息及其资源使用的部分,此处用数组表示该字段可以有多个值,比如containers[].name表示containers字段下可以定义多个容器,每个容器对应一个name,

定义容器端口和环境变量的部分

接下来是volume的配置

接下来是重启策略
最后是pod网络使用何种DNS

- pod内的容器网络与通信
前面已经介绍过,pod内的容器是共享network namespace的,那Kubernetes是怎么做到这一点的呢?假设pod内一共有3个容器,那么这个pod对应的Docker容器信息应该如下所示:
$ docker ps
IMAGE COMMAND CREATED STATUS PORTS
k8stest/sshd:test "/usr/sbin/sshd -D" 3 minutes ago Up 3 minutes 0.0.0.0:8888->22/tcp,pause:2.0
k8stest/redis:test "/run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:6388->6379/tcp
gcr.io/google_containers/ "/pause" 3 minutes ago Up 3 minutes
其中上面两个是用户容器,第三个是Kubernetes的网络容器(名称为gcr.io/google_ containers/pause,也称为基础容器),这就是关键了。
只要保证每个pod中都会自动运行一个这样的网络容器,并且pod中的其他容器都借助–net="container"的方式使用它间接定义自身的网络,就实现了这些容器network namespace的共享。因此,无论使用者给pod指定了怎样的端口和IP,这些网络参数都只定义在了这个网络容器上,其他容器通过共享网络容器的network namespace来分享这些配置
除此之外,网络容器不需要做任何工作,可以看到它执行的操作是pause,这是用汇编编写的一段什么都不做的代码,占用资源也可以忽略不计。回到上述例子,可以发现master1容器的6379端口映射在宿主机上的6388端口,将master2容器的22端口映射在宿主机上的8888端口。现在,先通过ssh的方式进入master2容器,然后在master2容器内通过localhost访问master1容器。
$ ssh [email protected] 8888
[email protected]'s password:
Welcome to Ubuntu 12.04 LTS (GNU/Linux 3.13.0-32-generic x86_64)
这样就通过ssh的方式登录了master2容器,接着在master2容器内访问master1容器的6379端口。
$ telnet 127.0.0.16379
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
通过localhost:6379,连接上了master1容器,即同一个pod里的容器通信都是可以直接通过localhost来进行的。