Flink关于算子状态笔记
DataStream API
Map
- 消费一个元素并产出一个元素
- 参数 MapFunction
- 返回DataStream
- 例子:
DataStream dataStream = //...
dataStream.map(new MapFunction() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});
FlatMap
- 消费一个元素并产生零到多个元素
- 参数 FlatMapFunction
- 返回 DataStream
- 例子:
dataStream.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String value, Collector out)
throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});
Filter
- 根据FliterFunction返回的布尔值来判断是否保留元素,true为保留,false则丢弃
- 参数 FilterFunction
- 返回DataStream
- 例子:
dataStream.filter(new FilterFunction() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 0;
}
});
KeyBy
-
根据指定的Key将元素发送到不同的分区,相同的Key会被分到一个分区(这里分区指的就是下游算子多个并行的节点的其中一个)。keyBy()是通过哈希来分区的。
-
只能使用KeyedState(Flink做备份和容错的状态)
-
参数 String,tuple的索引,覆盖了hashCode方法的POJO,不能使数组
-
返回KeyedStream
-
例子:
dataStream.keyBy("someKey") // Key by field "someKey"
dataStream.keyBy(0) // Key by the first element of a Tuple
Flink状态
算子状态
定义
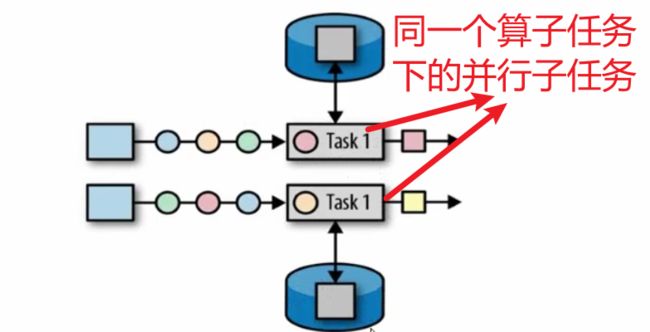
【例,map算子有多个并行任务,每个并行任务只能访问自己的一个算子状态实例】,
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务,与Key无关,不同Key的数据只要分发到同一个并行子任务,就会访问到同一个算子状态。
算子状态一般用在 Source 或 Sink 等与外部系统连接的算子上,或者完全没有 key 定义的场景。比如 Flink 的 Kafka 连接器中,就用到了算子状态。在我们给 Source 算子设置并行度后,Kafka 消费者的每一个并行实例,都会为对应的主题(topic)分区维护一个偏移量, 作为算子状态保存起来。这在保证 Flink 应用“精确一次”(exactly-once)状态一致性时非常有用。
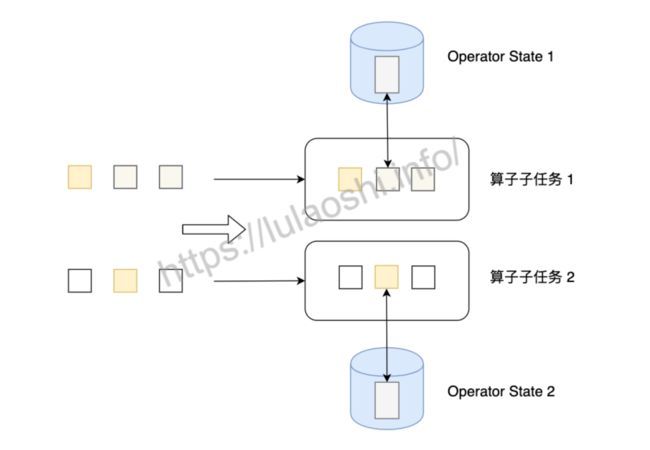
状态类型
列表状态[ListState]
与 Keyed State 中的 ListState 一样,将状态表示为一组数据的列表。
与 Keyed State 中的列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
当算子并行度进行缩放调整时,算子的列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),与之前介绍的 rebanlance 数据传输方式类似,是通过逐一“发牌”的方式将状态项平均分配的。这种方式也叫作“平均分割重组”(even-splitredistribution)。
算子状态中不会存在“键组”(key group)这样的结构,所以为了方便重组分配,就把它直接定义成了“列表”(list)。这也就解释了,为什么算子状态中没有最简单的值状态(ValueState)。
联合列表状态[UnionListState]
与 ListState 类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于,算子并行度进行缩放调整时对于状态的分配方式不同。
UnionListState 的重点就在于“联合”(union)。在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。这样,并行度缩放之后的并行子任务就获取到了联合后完整的“大列表”,可以自行选择要使用的状态项和要丢弃的状态项。这种分配也叫作“联合重组”(union redistribution)。如果列表中状态项数量太多,为资源和效率考虑一般不建议使用联合重组的方式
广播列表状态[BroadcastListState]
键值分区状态
定义
状态类型
总结
| Keyed State | Operator State | |
|---|---|---|
| 适用算子类型 | 只适用于KeyedStream上的算子 |
可以用于所有算子 |
| 状态分配 | 每个Key对应一个状态 | 一个算子子任务对应一个状态 |
| 创建和访问方式 | 重写Rich Function,通过里面的RuntimeContext访问 | 实现CheckpointedFunction等接口 |
| 横向扩展 | 状态随着Key自动在多个算子子任务上迁移 | 有多种状态重新分配的方式 |
| 支持的数据结构 | ValueState、ListState、MapState等 | ListState、BroadcastState等 |
横向扩展问题
状态的横向扩展问题主要是指修改Flink应用的并行度,每个算子的并行实例数或算子子任务数发生了变化,应用需要关停或启动一些算子子任务,某份在原来某个算子子任务上的状态数据需要平滑更新到新的算子子任务上。Flink的Checkpoint可以辅助迁移状态数据。算子的本地状态将数据生成快照(Snapshot),保存到分布式存储(如HDFS)上。横向伸缩后,算子子任务个数变化,子任务重启,相应的状态从分布式存储上重(Restore)。下图展示了一个算子扩容的状态迁移过程。
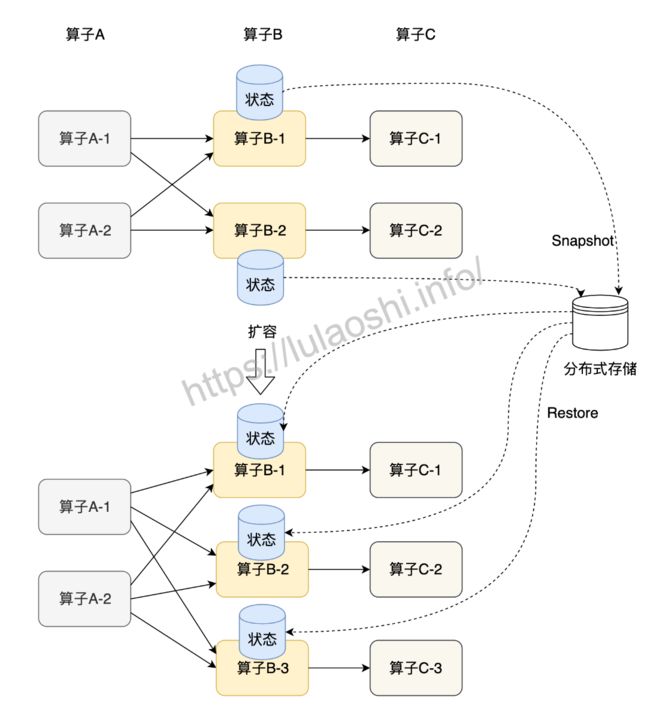
对于Keyed State和Operator State这两种状态,他们的横向伸缩机制不太相同。由于每个Keyed State总是与某个Key相对应,当横向伸缩时,Key总会被自动分配到某个算子子任务上,因此Keyed State会自动在多个并行子任务之间迁移。对于一个非KeyedStream,流入算子子任务的数据可能会随着并行度的改变而改变。如上图所示,假如一个应用的并行度原来为2,那么数据会被分成两份并行地流入两个算子子任务,每个算子子任务有一份自己的状态,当并行度改为3时,数据流被拆成3支,此时状态的存储也相应发生了变化。对于横向伸缩问题,Operator State有两种状态分配方式:一种是均匀分配,另一种是将所有状态合并,再分发给每个实例上。
Flink的核心代码目前使用Java实现的,而Java的很多类型与Scala的类型不太相同,比如List和Map。这里不再详细解释Java和Scala的数据类型的异同,但是开发者在使用Scala调用这些接口,比如状态的接口,需要注意两种语言间的转换。对于List和Map的转换,只需要引用import scala.collection.JavaConversions._,并在必要的地方添加后缀asScala或asJava来进行转换。此外,Scala和Java的空对象使用习惯不太相同,Java一般使用null表示空,Scala一般使用None。
Keyed State的使用方法
七、有状态算子和应用
7.1 使用ListCheckpointed接口来实现操作符的列表状态
操作符状态会在操作符的每一个并行实例中去维护。一个操作符并行实例上的所有事件都可以访问同一个状态。Flink支持三种操作符状态:list state, list union state, broadcast state。
一个函数可以实现ListCheckpointed接口来处理操作符的list state。ListCheckpointed接口无法处理ValueState和ListState,因为这些状态是注册在状态后端的。操作符状态类似于成员变量,和状态后端的交互通过ListCheckpointed接口的回调函数实现。接口提供了两个方法:
// 返回函数状态的快照,返回值为列表
snapshotState(checkpointId: Long, timestamp: Long): java.util.List[T]
// 从列表恢复函数状态
restoreState(java.util.List[T] state): Unit
当Flink触发stateful functon的一次checkpoint时,snapshotState()方法会被调用。方法接收两个参数,checkpointId为唯一的单调递增的检查点Id,timestamp为当master机器开始做检查点操作时的墙上时钟(机器时间)。方法必须返回序列化好的状态对象的列表。
当宕机程序从检查点或者保存点恢复时会调用restoreState()方法。restoreState使用snapshotState保存的列表来恢复。
下面的例子展示了如何实现ListCheckpointed接口。业务场景为:一个对每一个并行实例的超过阈值的温度的计数程序。
class HighTempCounter(val threshold: Double)
extends RichFlatMapFunction[SensorReading, (Int, Long)]
with ListCheckpointed[java.lang.Long] {
// index of the subtask
private lazy val subtaskIdx = getRuntimeContext
.getIndexOfThisSubtask
// local count variable
private var highTempCnt = 0L
override def flatMap(
in: SensorReading,
out: Collector[(Int, Long)]): Unit = {
if (in.temperature > threshold) {
// increment counter if threshold is exceeded
highTempCnt += 1
// emit update with subtask index and counter
out.collect((subtaskIdx, highTempCnt))
}
}
override def restoreState(
state: util.List[java.lang.Long]): Unit = {
highTempCnt = 0
// restore state by adding all longs of the list
for (cnt <- state.asScala) {
highTempCnt += cnt
}
}
override def snapshotState(
chkpntId: Long,
ts: Long): java.util.List[java.lang.Long] = {
// snapshot state as list with a single count
java.util.Collections.singletonList(highTempCnt)
}
}
上面的例子中,每一个并行实例都计数了本实例有多少温度值超过了设定的阈值。例子中使用了操作符状态,并且每一个并行实例都拥有自己的状态变量,这个状态变量将会被检查点操作保存下来,并且可以通过使用ListCheckpointed接口来恢复状态变量。
看了上面的例子,我们可能会有疑问,那就是为什么操作符状态是状态对象的列表。这是因为列表数据结构支持包含操作符状态的函数的并行度改变的操作。为了增加或者减少包含了操作符状态的函数的并行度,操作符状态需要被重新分区到更多或者更少的并行任务实例中去。而这样的操作需要合并或者分割状态对象。而对于每一个有状态的函数,分割和合并状态对象都是很常见的操作,所以这显然不是任何类型的状态都能自动完成的。
通过提供一个状态对象的列表,拥有操作符状态的函数可以使用snapshotState()方法和restoreState()方法来实现以上所说的逻辑。snapshotState()方法将操作符状态分割成多个部分,restoreState()方法从所有的部分中将状态对象收集起来。当函数的操作符状态恢复时,状态变量将被分区到函数的所有不同的并行实例中去,并作为参数传递给restoreState()方法。如果并行任务的数量大于状态对象的数量,那么一些并行任务在开始的时候是没有状态的,所以restoreState()函数的参数为空列表。
再来看一下上面的程序,我们可以看到操作符的每一个并行实例都暴露了一个状态对象的列表。如果我们增加操作符的并行度,那么一些并行任务将会从0开始计数。为了获得更好的状态分区的行为,当HighTempCounter函数扩容时,我们可以按照下面的程序来实现snapshotState()方法,这样就可以把计数值分配到不同的并行计数中去了。
/** Split count into 10 partial counts for improved state distribution. */
override def snapshotState(chkpntId: Long, ts: Long): java.util.List[java.lang.Long] = {
// split count into ten partial counts
val div = highTempCnt / 10
val mod = (highTempCnt % 10).toInt
/**
* 例如 highTempCnt = 109
* div = 109 / 10 = 10
* mod = 109 % 10 = 9
*
* 9 * (10 + 1) + (10-9) * 10 = 109 = highTempCnt
*/
(List.fill(mod)(new java.lang.Long(div + 1)) ++ List.fill(10 - mod)(new java.lang.Long(div))).asJava
}
}
∵ mod = highTemp % 10
highTemp / 10 = div … mod
∴ highTemp = 10 * div + mod
为了实现10等分,我们将数据分为(10 - mod) 份 和 mod 份 两部分
∴ highTemp = (10-mod) * Y + mod * X
联立方程组:
$$
\begin{cases}
\begin{aligned}
highTemp &= 10 * div + mod\
highTemp &= (10-mod) * Y + mod * X\
&=10Y + (Y-X)*mod
\end{aligned}
\end{cases}
故 而 得 : 故而得: 故而得:
\begin{cases}
\begin{aligned}
Y =& div\
Y-X &= 1
\end{aligned}
\end{cases}
$$
即,
highTemp = mod * X + (10-mod) * Y = mod * (div+1) + (10-mod) * div
7.2 使用CheckPointedFunction接口
7.3 使用连接的广播状态
参考文章1
基本概念
两个流,一个传输过来行为数据,另一个存储匹配规则进行筛选(Patterns)。

① 模式流会被广播到3个并行任务的操作算子Operator,Operator tasks 会在其broadcast state中存储刚广播过来的patterns。

② Data Stream:User Actions 中的数据会以轮询的方式轮流发送给每一个 Operator进行消费。

③ After the first three actions are processed, the next event, the logout action of User 1001, is shipped to the task that processes the events of User 1001. When the task receives the actions, it looks up the current pattern from the broadcast state and the previous action of User 1001. Since the pattern matches both actions, the task emits a pattern match event. Finally, the task updates its keyed state by overriding the previous event with the latest action.

④ When a new pattern arrives in the pattern stream, it is broadcasted to all tasks and each task updates its broadcast state by replacing the current pattern with the new one.
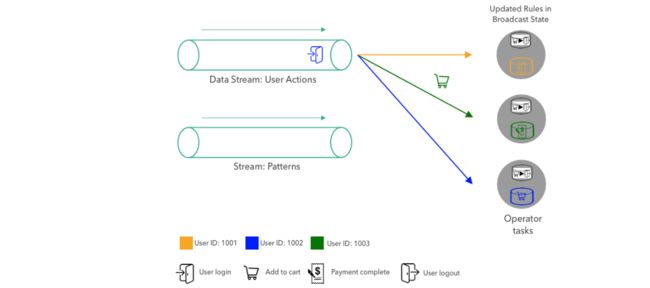
⑤ Once the broadcast state is updated with a new pattern【更新成功好了后】, the matching logic continues as before, i.e., user action events are partitioned by key and evaluated by the responsible task.
实现连接的广播状态
看上面的【参考文章1】
7.4 配置检查点,开启故障恢复
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment;
// set checkpointing interval to 10 seconds (10000 milliseconds)
env.enableCheckpointing(10000L);
将HDFS配置为状态后端
首先在IDEA的pom文件中添加依赖:
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.8.3version>
dependency>
在hdfs-site.xml添加:
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
别忘了重启hdfs文件系统!
然后添加本地文件夹和hdfs文件的映射:
hdfs getconf -confKey fs.default.name
hdfs dfs -put /home/parallels/flink/checkpoint hdfs://localhost:9000/flink
然后在代码中添加:
env.enableCheckpointing(5000)
env.setStateBackend(new FsStateBackend("hdfs://localhost:9000/flink"))
检查一下检查点正确保存了没有:
hdfs dfs -ls hdfs://localhost:9000/flink
7.5 确保有状态应用的可维护性
指定算子唯一标识符
DataStream> alerts = keyedSensorData
.flatMap(new TemperatureAlertFunction(1.1))
.uid("TempAlert");
指定操作符的最大并行度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment;
// set the maximum parallelism for this application
env.setMaxParallelism(512);
DataStream> alerts = keyedSensorData
.flatMap(new TemperatureAlertFunction(1.1))
// set the maximum parallelism for this operator and
// override the application-wide value
.setMaxParallelism(1024);

7.6 有状态应用的性能和鲁棒性
选择一个状态后端
- MemoryStateBackend将状态当作Java的对象(没有序列化操作)存储在TaskManager JVM进程的堆上。
- FsStateBackend将状态存储在本地的文件系统或者远程的文件系统如HDFS。
- RocksDBStateBackend将状态存储在RocksDB中。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment;
String checkpointPath = ???
// configure path for checkpoints on the remote filesystem
// env.setStateBackend(new FsStateBackend("file:///tmp/checkpoints"))
val backend = new RocksDBStateBackend(checkpointPath)
// configure the state backend
env.setStateBackend(backend);
防止状态泄露
class SelfCleaningTemperatureAlertFunction(val threshold: Double)
extends KeyedProcessFunction[String,
SensorReading, (String, Double, Double)] {
// the keyed state handle for the last temperature
private var lastTempState: ValueState[Double] = _
// the keyed state handle for the last registered timer
private var lastTimerState: ValueState[Long] = _
override def open(parameters: Configuration): Unit = {
// register state for last temperature
val lastTempDesc = new ValueStateDescriptor[Double](
"lastTemp", classOf[Double])
lastTempState = getRuntimeContext
.getState[Double](lastTempDescriptor)
// register state for last timer
val lastTimerDesc = new ValueStateDescriptor[Long](
"lastTimer", classOf[Long])
lastTimerState = getRuntimeContext
.getState(timestampDescriptor)
}
override def processElement(
reading: SensorReading,
ctx: KeyedProcessFunction
[String, SensorReading, (String, Double, Double)]#Context,
out: Collector[(String, Double, Double)]): Unit = {
// compute timestamp of new clean up timer
// as record timestamp + one hour
val newTimer = ctx.timestamp() + (3600 * 1000)
// get timestamp of current timer
val curTimer = lastTimerState.value()
// delete previous timer and register new timer
ctx.timerService().deleteEventTimeTimer(curTimer)
ctx.timerService().registerEventTimeTimer(newTimer)
// update timer timestamp state
lastTimerState.update(newTimer)
// fetch the last temperature from state
val lastTemp = lastTempState.value()
// check if we need to emit an alert
val tempDiff = (reading.temperature - lastTemp).abs
if (tempDiff > threshold) {
// temperature increased by more than the threshold
out.collect((reading.id, reading.temperature, tempDiff))
}
// update lastTemp state
this.lastTempState.update(reading.temperature)
}
override def onTimer(
timestamp: Long,
ctx: KeyedProcessFunction[String,
SensorReading, (String, Double, Double)]#OnTimerContext,
out: Collector[(String, Double, Double)]): Unit = {
// clear all state for the key
lastTempState.clear()
lastTimerState.clear()
}
}
八、读写外部系统
8.1 应用的一致性保证
Flink的检查点和恢复机制定期的会保存应用程序状态的一致性检查点。在故障的情况下,应用程序的状态将会从最近一次完成的检查点恢复,并继续处理。尽管如此,可以使用检查点来重置应用程序的状态无法完全达到令人满意的一致性保证。相反,source和sink的连接器需要和Flink的检查点和恢复机制进行集成才能提供有意义的一致性保证。
为了给应用程序提供恰好处理一次语义的状态一致性保证,应用程序的source连接器需要能够将source的读位置重置到之前保存的检查点位置。当处理一次检查点时,source操作符将会把source的读位置持久化,并在恢复的时候从这些读位置开始重新读取。支持读位置的检查点的source连接器一般来说是基于文件的存储系统,如:文件流或者Kafka source(检查点会持久化某个正在消费的topic的读偏移量)。如果一个应用程序从一个无法存储和重置读位置的source连接器摄入数据,那么当任务出现故障的时候,数据就会丢失。也就是说我们只能提供at-most-once)的一致性保证。
Fink的检查点和恢复机制和可以重置读位置的source连接器结合使用,可以保证应用程序不会丢失任何数据。尽管如此,应用程序可能会发出两次计算结果,因为从上一次检查点恢复的应用程序所计算的结果将会被重新发送一次(一些结果已经发送出去了,这时任务故障,然后从上一次检查点恢复,这些结果将被重新计算一次然后发送出去)。所以,可重置读位置的source和Flink的恢复机制不足以提供端到端的恰好处理一次语义,即使应用程序的状态是恰好处理一次一致性级别。
一个志在提供端到端恰好处理一次语义一致性的应用程序需要特殊的sink连接器。sink连接器可以在不同的情况下使用两种技术来达到恰好处理一次一致性语义:幂等性写入和事务性写入。
8.1.1 幂等性写入
**一个幂等操作无论执行多少次都会返回同样的结果。**例如,重复的向hashmap中插入同样的key-value对就是幂等操作,因为头一次插入操作之后所有的插入操作都不会改变这个hashmap,因为hashmap已经包含这个key-value对了。另一方面,append操作就不是幂等操作了,因为多次append同一个元素将会导致列表每次都会添加一个元素。在流处理程序中,幂等写入操作是很有意思的,因为幂等写入操作可以执行多次但不改变结果。所以它们可以在某种程度上缓和Flink检查点机制带来的重播计算结果的效应。
需要注意的是,依赖于幂等性sink来达到exactly-once语义的应用程序,**必须保证在从检查点恢复以后,它将会覆盖之前已经写入的结果。**例如,一个包含有sink操作的应用在sink到一个key-value存储时必须保证它能够确定的计算出将要更新的key值。同时,从Flink程序sink到的key-value存储中读取数据的应用,在Flink从检查点恢复的过程中,可能会看到不想看到的结果。当重播开始时,之前已经发出的计算结果可能会被更早的结果所覆盖(因为在恢复过程中,好似时间倒流重新回到现在)。所以,一个消费Flink程序输出数据的应用,可能会观察到时间回退,例如读到了比之前小的计数。也就是说,当流处理程序处于恢复过程中时,流处理程序的结果将处于不稳定的状态,因为一些结果被覆盖掉,而另一些结果还没有被覆盖。一旦重播完成,也就是说应用程序已经通过了之前出故障的点,结果将会继续保持一致性。
8.1.2 事务性写入
第二种实现端到端的恰好处理一次一致性语义的方法基于事务性写入。其思想是只将最近一次成功保存的检查点之前的计算结果写入到外部系统中去。(中间的结果就不存进去)这样就保证了在任务故障的情况下,端到端恰好处理一次语义。应用将被重置到最近一次的检查点,而在这个检查点之后并没有向外部系统发出任何计算结果。通过只有当检查点保存完成以后再写入数据这种方法,事务性的方法将不会遭受幂等性写入所遭受的重播不一致的问题。尽管如此,事务性写入却带来了延迟,因为只有在检查点完成以后,我们才能看到计算结果。
Flink提供了两种构建模块来实现事务性sink连接器:write-ahead-log(WAL,预写式日志)sink和两阶段提交sink。WAL式sink将会把所有计算结果写入到应用程序的状态中,等接到检查点完成的通知,才会将计算结果发送到sink系统。因为sink操作会把数据都缓存在状态后段,所以WAL可以使用在任何外部sink系统上。尽管如此,WAL还是无法提供刀枪不入的恰好处理一次语义的保证,再加上由于要缓存数据带来的状态后段的状态大小的问题,WAL模型并不十分完美。
与之形成对比的,2PC sink需要sink系统提供事务的支持或者可以模拟出事务特性的模块。对于每一个检查点,sink开始一个事务,然后将所有的接收到的数据都添加到事务中,并将这些数据写入到sink系统,但并没有提交(commit)它们。当事务接收到检查点完成的通知时,事务将被commit,数据将被真正的写入sink系统。这项机制主要依赖于一次sink可以在检查点完成之前开始事务,并在应用程序从一次故障中恢复以后再commit的能力。
2PC协议依赖于Flink的检查点机制。检查点屏障是开始一个新的事务的通知,所有操作符自己的检查点成功的通知是它们可以commit的投票,而作业管理器通知一个检查点成功的消息是commit事务的指令。于WAL sink形成对比的是,2PC sinks依赖于sink系统和sink本身的实现可以实现恰好处理一次语义。更多的,2PC sink不断的将数据写入到sink系统中,而WAL写模型就会有之前所述的问题。
WAL,预写式日志

两阶段提交

不同Source和Sink的一致性保证
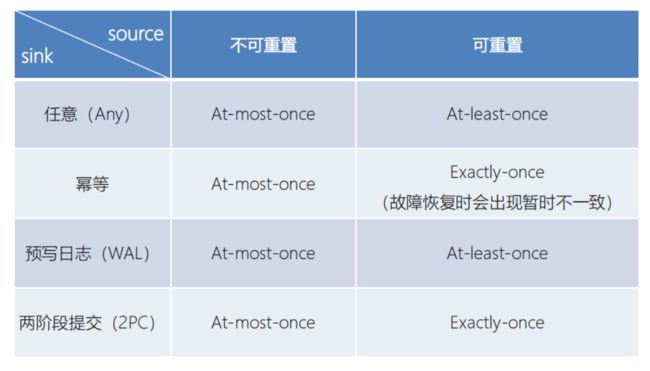
8.2 Flink提供的连接器
Flink提供了读写很多存储系统的连接器。消息队列,日志系统,例如Apache Kafka, Kinesis, RabbitMQ等等这些是常用的数据源。在批处理环境中,数据流很可能是监听一个文件系统,而当新的数据落盘的时候,读取这些新数据。
在sink一端,数据流经常写入到消息队列中,以供接下来的流处理程序消费。数据流也可能写入到文件系统中做持久化,或者交给批处理程序来进行分析。数据流还可能被写入到key-value存储或者关系型数据库中,例如Cassandra,ElasticSearch或者MySQL中,这样数据可供查询,还可以在仪表盘中显示出来。
不幸的是,对于大多数存储系统并没有标准接口,除了针对DBMS的JDBC。相反,每一个存储系统都需要有自己的特定的连接器。所以,Flink需要维护针对不同存储系统(消息队列,日志系统,文件系统,k-v数据库,关系型数据库等等)的连接器实现。
Flink提供了针对Apache Kafka, Kinesis, RabbitMQ, Apache Nifi, 各种文件系统,Cassandra, Elasticsearch, 还有JDBC的连接器。除此之外,Apache Bahir项目还提供了额外的针对例如ActiveMQ, Akka, Flume, Netty, 和Redis等的连接器。
8.2.1 Apache-Kafka-Source 连接器
Kafka的依赖引入如下:
org.apache.flink
flink-connector-kafka_2.12
1.7.1
Kafka source连接器使用如下代码创建:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "test")
val stream: DataStream[String] = env.addSource(
new FlinkKafkaConsumer[String](
"topic",
new SimpleStringSchema(),
properties))
构造器接受三个参数。第一个参数定义了从哪些topic中读取数据,可以是一个topic,也可以是topic列表,还可以是匹配所有想要读取的topic的正则表达式。当从多个topic中读取数据时,Kafka连接器将会处理所有topic的分区,将这些分区的数据放到一条流中去。
第二个参数是一个DeserializationSchema或者KeyedDeserializationSchema。Kafka消息被存储为原始的字节数据,所以需要反序列化成Java或者Scala对象。上例中使用的SimpleStringSchema,是一个内置的DeserializationSchema,它仅仅是简单的将字节数组反序列化成字符串。DeserializationSchema和KeyedDeserializationSchema是公共的接口,所以我们可以自定义反序列化逻辑。
第三个参数是一个Properties对象,设置了用来读写的Kafka客户端的一些属性。
为了抽取事件时间的时间戳然后产生水印(waterMark),我们可以通过调用
FlinkKafkaConsumer.assignTimestampsAndWatermark()
方法为Kafka消费者提供AssignerWithPeriodicWatermark或者AssignerWithPucntuatedWatermark。每一个assigner都将被应用到每个分区,来利用每一个分区的顺序保证特性。source实例将会根据水印的传播协议聚合所有分区的水印。
8.2.2 Apache Kafka Sink连接器
添加依赖:
org.apache.flink
flink-connector-kafka_2.12
1.7.1
下面的例子展示了如何创建一个Kafka sink
val stream: DataStream[String] = ...
val myProducer = new FlinkKafkaProducer[String](
"localhost:9092", // broker list
"topic", // target topic
new SimpleStringSchema) // serialization schema
stream.addSink(myProducer)
8.2.3 Kafka-Sink的at-least-once语义保证
Flink的Kafka sink提供了基于配置的一致性保证。Kafka sink使用下面的条件提供了至少处理一次保证:
- Flink检查点机制开启,所有的数据源都是可重置的。
- 当写入失败时,sink连接器将会抛出异常,使得应用程序挂掉然后重启。这是默认行为。应用程序内部的Kafka客户端还可以配置为重试写入,只要提前声明当写入失败时,重试几次这样的属性(retries property)。
- sink连接器在完成它的检查点之前会等待Kafka发送已经将数据写入的通知。
8.2.4 Kafka-Sink的Exactly-once语义保证
Kafka 0.11版本引入了事务写特性。由于这个新特性,Flink Kafka sink可以为输出结果提供恰好处理一次语义的一致性保证,只要经过合适的配置就行。Flink程序必须开启检查点机制,并从可重置的数据源进行消费。FlinkKafkaProducer还提供了包含Semantic参数的构造器来控制sink提供的一致性保证。可能的取值如下:
- Semantic.NONE,不提供任何一致性保证。数据可能丢失或者被重写多次。
- Semantic.AT_LEAST_ONCE,保证无数据丢失,但可能被处理多次。这个是默认设置。
- Semantic.EXACTLY_ONCE,基于Kafka的事务性写入特性实现,保证每条数据恰好处理一次。
8.2.5 文件系统source连接器
Apache Flink针对文件系统实现了一个可重置的source连接器,将文件看作流来读取数据。如下面的例子所示:
val lineStream: DataStream[String] = env.readFile[String](
new TextInputFormat(null), // The FileInputFormat
"hdfs:///path/to/my/data", // The path to read
FileProcessingMode
.PROCESS_CONTINUOUSLY, // The processing mode
30000L) // The monitoring interval in ms
StreamExecutionEnvironment.readFile()接收如下参数:
- FileInputFormat参数,负责读取文件中的内容。
- 文件路径。如果文件路径指向单个文件,那么将会读取这个文件。如果路径指向一个文件夹,FileInputFormat将会扫描文件夹中所有的文件。
- PROCESS_CONTINUOUSLY将会周期性的扫描文件,以便扫描到文件新的改变。
- 30000L表示多久扫描一次监听的文件。
FileInputFormat是一个特定的InputFormat,用来从文件系统中读取文件。FileInputFormat分两步读取文件。首先扫描文件系统的路径,然后为所有匹配到的文件创建所谓的input splits。一个input split将会定义文件上的一个范围,一般通过读取的开始偏移量和读取长度来定义。在将一个大的文件分割成一堆小的splits以后,这些splits可以分发到不同的读任务,这样就可以并行的读取文件了。FileInputFormat的第二步会接收一个input split,读取被split定义的文件范围,然后返回对应的数据。
DataStream应用中使用的FileInputFormat需要实现CheckpointableInputFormat接口。这个接口定义了方法来做检查点和重置文件片段的当前的读取位置。
在Flink 1.7中,Flink提供了一些类,这些类继承了FileInputFormat,并实现了CheckpointableInputFormat接口。TextInputFormat一行一行的读取文件,而CsvInputFormat使用逗号分隔符来读取文件。
8.2.6 文件系统sink连接器
在将流处理应用配置成exactly-once检查点机制,以及配置成所有源数据都能在故障的情况下可以重置,Flink的StreamingFileSink提供了端到端的恰好处理一次语义保证。下面的例子展示了StreamingFileSink的使用方式。
val input: DataStream[String] = …
val sink: StreamingFileSink[String] = StreamingFileSink
.forRowFormat(
new Path("/base/path"),
new SimpleStringEncoder[String]("UTF-8"))
.build()
input.addSink(sink)
当StreamingFileSink接到一条数据,这条数据将被分配到一个桶(bucket)中。一个桶是我们配置的“/base/path”的子目录。
Flink使用BucketAssigner来分配桶。BucketAssigner是一个公共的接口,为每一条数据返回一个BucketId,BucketId决定了数据被分配到哪个子目录。如果没有指定BucketAssigner,Flink将使用DateTimeBucketAssigner来将每条数据分配到每个一个小时所产生的桶中去,基于数据写入的处理时间(机器时间,墙上时钟)。
StreamingFileSink提供了exactly-once输出的保证。sink通过一个commit协议来达到恰好处理一次语义的保证。这个commit协议会将文件移动到不同的阶段,有以下状态:in progress,pending,finished。这个协议基于Flink的检查点机制。当Flink决定roll a file时,这个文件将被关闭并移动到pending状态,通过重命名文件来实现。当下一个检查点完成时,pending文件将被移动到finished状态,同样是通过重命名来实现。
一旦任务故障,sink任务需要将处于in progress状态的文件重置到上一次检查点的写偏移量。这个可以通过关闭当前in progress的文件,并将文件结尾无效的部分丢弃掉来实现。
8.3 自定义source函数
DataStream API提供了两个接口来实现source连接器:
- SourceFunction和RichSourceFunction可以用来定义非并行的source连接器,source跑在单任务上。
- ParallelSourceFunction和RichParallelSourceFunction可以用来定义跑在并行实例上的source连接器。
除了并行于非并行的区别,这两种接口完全一样。就像process function的rich版本一样,RichSourceFunction和RichParallelSourceFunction的子类可以override open()和close()方法,也可以访问RuntimeContext,RuntimeContext提供了并行任务实例的数量,当前任务实例的索引,以及一些其他信息。
SourceFunction和ParallelSourceFunction定义了两种方法:
- void run(SourceContext ctx)
- cancel()
run()方法用来读取或者接收数据然后将数据摄入到Flink应用中。根据接收数据的系统,数据可能是推送的也可能是拉取的。Flink仅仅在特定的线程调用run()方法一次,通常情况下会是一个无限循环来读取或者接收数据并发送数据。任务可以在某个时间点被显式的取消,或者由于流是有限流,当数据被消费完毕时,任务也会停止。
当应用被取消或者关闭时,cancel()方法会被Flink调用。为了优雅的关闭Flink应用,run()方法需要在cancel()被调用以后,立即终止执行。下面的例子显示了一个简单的源函数的例子:从0数到Long.MaxValue。
class CountSource extends SourceFunction[Long] {
var isRunning: Boolean = true
override def run(ctx: SourceFunction.SourceContext[Long]) = {
var cnt: Long = -1
while (isRunning && cnt < Long.MaxValue) {
cnt += 1
ctx.collect(cnt)
}
}
override def cancel() = isRunning = false
}
可重置的source函数
之前我们讲过,应用程序只有使用可以重播输出数据的数据源时,才能提供令人满意的一致性保证。如果外部系统暴露了获取和重置读偏移量的API,那么source函数就可以重播源数据。这样的例子包括一些能够提供文件流的偏移量的文件系统,或者提供seek方法用来移动到文件的特定位置的文件系统。或者Apache Kafka这种可以为每一个主题的分区提供偏移量并且可以设置分区的读位置的系统。一个反例就是source连接器连接的是socket,socket将会立即丢弃已经发送过的数据。
支持重播输出的源函数需要和Flink的检查点机制集成起来,还需要在检查点被处理时,持久化当前所有的读取位置。当应用从一个保存点(savepoint)恢复或者从故障恢复时,Flink会从最近一次的检查点或者保存点中获取读偏移量。如果程序开始时并不存在状态,那么读偏移量将会被设置到一个默认值。一个可重置的源函数需要实现CheckpointedFunction接口,还需要能够存储读偏移量和相关的元数据,例如文件的路径,分区的ID。这些数据将被保存在list state或者union list state中。
下面的例子将CountSource重写为可重置的数据源。
scala version
class ResettableCountSource
extends SourceFunction[Long] with CheckpointedFunction {
var isRunning: Boolean = true
var cnt: Long = _
var offsetState: ListState[Long] = _
override def run(ctx: SourceFunction.SourceContext[Long]) = {
while (isRunning && cnt < Long.MaxValue) {
// synchronize data emission and checkpoints
ctx.getCheckpointLock.synchronized {
cnt += 1
ctx.collect(cnt)
}
}
}
override def cancel() = isRunning = false
override def snapshotState(
snapshotCtx: FunctionSnapshotContext
): Unit = {
// remove previous cnt
offsetState.clear()
// add current cnt
offsetState.add(cnt)
}
override def initializeState(
initCtx: FunctionInitializationContext): Unit = {
val desc = new ListStateDescriptor[Long](
"offset", classOf[Long])
offsetState = initCtx
.getOperatorStateStore
.getListState(desc)
// initialize cnt variable
val it = offsetState.get()
cnt = if (null == it || !it.iterator().hasNext) {
-1L
} else {
it.iterator().next()
}
}
}
8.4 自定义sink函数
DataStream API中,任何运算符或者函数都可以向外部系统发送数据。DataStream不需要最终流向sink运算符。例如,我们可能实现了一个FlatMapFunction,这个函数将每一个接收到的数据通过HTTP POST请求发送出去,而不使用Collector发送到下一个运算符。DataStream API也提供了SinkFunction接口以及对应的rich版本RichSinkFunction抽象类。SinkFunction接口提供了一个方法:
void invode(IN value, Context ctx)
SinkFunction的Context可以访问当前处理时间,当前水位线,以及数据的时间戳。
下面的例子展示了一个简单的SinkFunction,可以将传感器读数写入到socket中去。需要注意的是,我们需要在启动Flink程序前启动一个监听相关端口的进程。否则将会抛出ConnectException异常。可以运行“nc -l localhost 9191”命令。
val readings: DataStream[SensorReading] = ...
// write the sensor readings to a socket
readings.addSink(new SimpleSocketSink("localhost", 9191))
// set parallelism to 1 because only one thread can write to a socket
.setParallelism(1)
// -----
class SimpleSocketSink(val host: String, val port: Int)
extends RichSinkFunction[SensorReading] {
var socket: Socket = _
var writer: PrintStream = _
override def open(config: Configuration): Unit = {
// open socket and writer
socket = new Socket(InetAddress.getByName(host), port)
writer = new PrintStream(socket.getOutputStream)
}
override def invoke(
value: SensorReading,
ctx: SinkFunction.Context[_]): Unit = {
// write sensor reading to socket
writer.println(value.toString)
writer.flush()
}
override def close(): Unit = {
// close writer and socket
writer.close()
socket.close()
}
}
之前我们讨论过,端到端的一致性保证建立在sink连接器的属性上面。为了达到端到端的恰好处理一次语义的目的,应用程序需要幂等性的sink连接器或者事务性的sink连接器。上面例子中的SinkFunction既不是幂等写入也不是事务性的写入。由于socket具有只能添加(append-only)这样的属性,所以不可能实现幂等性的写入。又因为socket不具备内置的事务支持,所以事务性写入就只能使用Flink的WAL sink特性来实现了。接下来我们将学习如何实现幂等sink连接器和事务sink连接器。
8.4.1 幂等性Sink
对于大多数应用,SinkFunction接口足以实现一个幂等性写入的sink连接器了。需要以下两个条件:
- 结果数据必须具有确定性的key,在这个key上面幂等性更新才能实现。例如一个计算每分钟每个传感器的平均温度值的程序,确定性的key值可以是传感器的ID和每分钟的时间戳。确定性的key值,对于在故障恢复的场景下,能够正确的覆盖结果非常的重要。
- 外部系统支持针对每个key的更新,例如关系型数据库或者key-value存储。
下面的例子展示了如何实现一个针对JDBC数据库的幂等写入sink连接器,这里使用的是Apache Derby数据库。
val readings: DataStream[SensorReading] = ...
// write the sensor readings to a Derby table
readings.addSink(new DerbyUpsertSink)
// -----
class DerbyUpsertSink extends RichSinkFunction[SensorReading] {
var conn: Connection = _
var insertStmt: PreparedStatement = _
var updateStmt: PreparedStatement = _
override def open(parameters: Configuration): Unit = {
// connect to embedded in-memory Derby
conn = DriverManager.getConnection(
"jdbc:derby:memory:flinkExample",
new Properties())
// prepare insert and update statements
insertStmt = conn.prepareStatement(
"INSERT INTO Temperatures (sensor, temp) VALUES (?, ?)")
updateStmt = conn.prepareStatement(
"UPDATE Temperatures SET temp = ? WHERE sensor = ?")
}
override def invoke(SensorReading r, context: Context[_]): Unit = {
// set parameters for update statement and execute it
updateStmt.setDouble(1, r.temperature)
updateStmt.setString(2, r.id)
updateStmt.execute()
// execute insert statement
// if update statement did not update any row
if (updateStmt.getUpdateCount == 0) {
// set parameters for insert statement
insertStmt.setString(1, r.id)
insertStmt.setDouble(2, r.temperature)
// execute insert statement
insertStmt.execute()
}
}
override def close(): Unit = {
insertStmt.close()
updateStmt.close()
conn.close()
}
}
由于Apache Derby并没有提供内置的UPSERT方法,所以这个sink连接器实现了UPSERT写。具体实现方法是首先去尝试更新一行数据,如果这行数据不存在,则插入新的一行数据。
8.4.2 事务性Sink
事务写入sink连接器需要和Flink的检查点机制集成,因为只有在检查点成功完成以后,事务写入sink连接器才会向外部系统commit数据。
为了简化事务性sink的实现,Flink提供了两个模版用来实现自定义sink运算符。这两个模版都实现了CheckpointListener接口。CheckpointListener接口将会从作业管理器接收到检查点完成的通知。
- GenericWriteAheadSink模版会收集检查点之前的所有的数据,并将数据存储到sink任务的运算符状态中。状态保存到了检查点中,并在任务故障的情况下恢复。当任务接收到检查点完成的通知时,任务会将所有的数据写入到外部系统中。
- TwoPhaseCommitSinkFunction模版利用了外部系统的事务特性。对于每一个检查点,任务首先开始一个新的事务,并将接下来所有的数据都写到外部系统的当前事务上下文中去。当任务接收到检查点完成的通知时,sink连接器将会commit这个事务。
GENERICWRITEAHEADSINK
GenericWriteAheadSink使得sink运算符可以很方便的实现。这个运算符和Flink的检查点机制集成使用,目标是将每一条数据恰好一次写入到外部系统中去。需要注意的是,在发生故障的情况下,write-ahead log sink可能会不止一次的发送相同的数据。所以GenericWriteAheadSink无法提供完美无缺的恰好处理一次语义的一致性保证,而是仅能提供at-least-once这样的保证。我们接下来详细的讨论这些场景。
GenericWriteAheadSink的原理是将接收到的所有数据都追加到有检查点分割好的预写式日志中去。每当sink运算符碰到检查点屏障,运算符将会开辟一个新的section,并将接下来的所有数据都追加到新的section中去。WAL(预写式日志)将会保存到运算符状态中。由于log能被恢复,所有不会有数据丢失。
当GenericWriteAheadSink接收到检查点完成的通知时,将会发送对应检查点的WAL中存储的所有数据。当所有数据发送成功,对应的检查点必须在内部提交。
检查点的提交分两步。第一步,sink持久化检查点被提交的信息。第二步,删除WAL中所有的数据。我们不能将commit信息保存在Flink应用程序状态中,因为状态不是持久化的,会在故障恢复时重置状态。相反,GenericWriteAheadSink依赖于可插拔的组件在一个外部持久化存储中存储和查找提交信息。这个组件就是CheckpointCommitter。
继承GenericWriteAheadSink的运算符需要提供三个构造器函数。
- CheckpointCommitter
- TypeSerializer,用来序列化输入数据。
- 一个job ID,传给CheckpointCommitter,当应用重启时可以识别commit信息。
还有,write-ahead运算符需要实现一个单独的方法:
boolean sendValues(Iterable<IN> values, long chkpntId, long timestamp)
当检查点完成时,GenericWriteAheadSink调用sendValues()方法来将数据写入到外部存储系统中。这个方法接收一个检查点对应的所有数据的迭代器,检查点的ID,检查点被处理时的时间戳。当数据写入成功时,方法必须返回true,写入失败返回false。
下面的例子展示了如何实现一个写入到标准输出的write-ahead sink。它使用了FileCheckpointCommitter。
val readings: DataStream[SensorReading] = ...
// write the sensor readings to the standard out via a write-ahead log
readings.transform(
"WriteAheadSink", new SocketWriteAheadSink)
class StdOutWriteAheadSink extends GenericWriteAheadSink[SensorReading](
// CheckpointCommitter that commits
// checkpoints to the local filesystem
new FileCheckpointCommitter(System.getProperty("java.io.tmpdir")),
// Serializer for records
createTypeInformation[SensorReading]
.createSerializer(new ExecutionConfig),
// Random JobID used by the CheckpointCommitter
UUID.randomUUID.toString) {
override def sendValues(
readings: Iterable[SensorReading],
checkpointId: Long,
timestamp: Long): Boolean = {
for (r <- readings.asScala) {
// write record to standard out
println(r)
}
true
}
}
之前我们讲过,GenericWriteAheadSink无法提供完美的exactly-once保证。有两个故障状况会导致数据可能被发送不止一次。
- 当任务执行sendValues()方法时,程序挂掉了。如果外部系统无法原子性的写入所有数据(要么都写入要么都不写),一些数据可能会写入,而另一些数据并没有被写入。由于checkpoint还没有commit,所以在任务恢复的过程中一些数据可能会被再次写入。
- 所有数据都写入成功了,sendValues()方法也返回true了;但在CheckpointCommitter方法被调用之前程序挂了,或者CheckpointCommitter在commit检查点时失败了。那么在恢复的过程中,所有未被提交的检查点将会被重新写入。
TWOPHASECOMMITSINKFUNCTION
Flink提供了TwoPhaseCommitSinkFunction接口来简化sink函数的实现。这个接口保证了端到端的exactly-once语义。2PC sink函数是否提供这样的一致性保证取决于我们的实现细节。我们需要讨论一个问题:“2PC协议是否开销太大?”
通常来讲,为了保证分布式系统的一致性,2PC是一个非常昂贵的方法。尽管如此,在Flink的语境下,2PC协议针对每一个检查点只运行一次。TwoPhaseCommitSinkFunction和WAL sink很相似,不同点在于前者不会将数据收集到state中,而是会写入到外部系统事务的上下文中。
TwoPhaseCommitSinkFunction实现了以下协议。在sink任务发送出第一条数据之前,任务将在外部系统中开始一个事务,所有接下来的数据将被写入这个事务的上下文中。当作业管理器初始化检查点并将检查点屏障插入到流中的时候,2PC协议的投票阶段开始。当运算符接收到检查点屏障,运算符将保存它的状态,当保存完成时,运算符将发送一个acknowledgement信息给作业管理器。当sink任务接收到检查点屏障时,运算符将会持久化它的状态,并准备提交当前的事务,以及acknowledge JobManager中的检查点。发送给作业管理器的acknowledgement信息类似于2PC协议中的commit投票。sink任务还不能提交事务,因为它还没有保证所有的任务都已经完成了它们的检查点操作。sink任务也会为下一个检查点屏障之前的所有数据开始一个新的事务。
当作业管理器成功接收到所有任务实例发出的检查点操作成功的通知时,作业管理器将会把检查点完成的通知发送给所有感兴趣的任务。这里的通知对应于2PC协议的提交命令。当sink任务接收到通知时,它将commit所有处于开启状态的事务。一旦sink任务acknowledge了检查点操作,它必须能够commit对应的事务,即使任务发生故障。如果commit失败,数据将会丢失。
让我们总结一下外部系统需要满足什么样的要求:
- 外部系统必须提供事务支持,或者sink的实现能在外部系统上模拟事务功能。
- 在检查点操作期间,事务必须处于open状态,并接收这段时间数据的持续写入。
- 事务必须等到检查点操作完成的通知到来才可以提交。在恢复周期中,可能需要一段时间等待。如果sink系统关闭了事务(例如超时了),那么未被commit的数据将会丢失。
- sink必须在进程挂掉后能够恢复事务。一些sink系统会提供事务ID,用来commit或者abort一个开始的事务。
- commit一个事务必须是一个幂等性操作。sink系统或者外部系统能够观察到事务已经被提交,或者重复提交并没有副作用。
下面的例子可能会让上面的一些概念好理解一些。
class TransactionalFileSink(val targetPath: String, val tempPath: String)
extends TwoPhaseCommitSinkFunction[(String, Double), String, Void](
createTypeInformation[String].createSerializer(new ExecutionConfig),
createTypeInformation[Void].createSerializer(new ExecutionConfig)) {
var transactionWriter: BufferedWriter = _
// Creates a temporary file for a transaction into
// which the records are written.
override def beginTransaction(): String = {
// path of transaction file
// is built from current time and task index
val timeNow = LocalDateTime.now(ZoneId.of("UTC"))
.format(DateTimeFormatter.ISO_LOCAL_DATE_TIME)
val taskIdx = this.getRuntimeContext.getIndexOfThisSubtask
val transactionFile = s"$timeNow-$taskIdx"
// create transaction file and writer
val tFilePath = Paths.get(s"$tempPath/$transactionFile")
Files.createFile(tFilePath)
this.transactionWriter = Files.newBufferedWriter(tFilePath)
println(s"Creating Transaction File: $tFilePath")
// name of transaction file is returned to
// later identify the transaction
transactionFile
}
/** Write record into the current transaction file. */
override def invoke(
transaction: String,
value: (String, Double),
context: Context[_]): Unit = {
transactionWriter.write(value.toString)
transactionWriter.write('\n')
}
/** Flush and close the current transaction file. */
override def preCommit(transaction: String): Unit = {
transactionWriter.flush()
transactionWriter.close()
}
// Commit a transaction by moving
// the precommitted transaction file
// to the target directory.
override def commit(transaction: String): Unit = {
val tFilePath = Paths.get(s"$tempPath/$transaction")
// check if the file exists to ensure
// that the commit is idempotent
if (Files.exists(tFilePath)) {
val cFilePath = Paths.get(s"$targetPath/$transaction")
Files.move(tFilePath, cFilePath)
}
}
// Aborts a transaction by deleting the transaction file.
override def abort(transaction: String): Unit = {
val tFilePath = Paths.get(s"$tempPath/$transaction")
if (Files.exists(tFilePath)) {
Files.delete(tFilePath)
}
}
}
TwoPhaseCommitSinkFunction[IN, TXN, CONTEXT]包含如下三个范型参数:
- IN表示输入数据的类型。
- TXN定义了一个事务的标识符,可以用来识别和恢复事务。
- CONTEXT定义了自定义的上下文。
TwoPhaseCommitSinkFunction的构造器需要两个TypeSerializer。一个是TXN的类型,另一个是CONTEXT的类型。
最后,TwoPhaseCommitSinkFunction定义了五个需要实现的方法:
-
beginTransaction(): TXN开始一个事务,并返回事务的标识符。
-
invoke(txn: TXN, value: IN, context: Context[_]): Unit将值写入到当前事务中。
-
preCommit(txn: TXN): Unit预提交一个事务。一个预提交的事务不会接收新的写入。
-
commit(txn: TXN): Unit提交一个事务。这个操作必须是幂等的。
-
abort(txn: TXN): Unit终止一个事务。
// to the target directory.
override def commit(transaction: String): Unit = {
val tFilePath = Paths.get(s" t e m p P a t h / tempPath/ tempPath/transaction")
// check if the file exists to ensure
// that the commit is idempotent
if (Files.exists(tFilePath)) {
val cFilePath = Paths.get(s" t a r g e t P a t h / targetPath/ targetPath/transaction")
Files.move(tFilePath, cFilePath)
}
}// Aborts a transaction by deleting the transaction file.
override def abort(transaction: String): Unit = {
val tFilePath = Paths.get(s" t e m p P a t h / tempPath/ tempPath/transaction")
if (Files.exists(tFilePath)) {
Files.delete(tFilePath)
}
}
}
TwoPhaseCommitSinkFunction[IN, TXN, CONTEXT]包含如下三个范型参数:
- IN表示输入数据的类型。
- TXN定义了一个事务的标识符,可以用来识别和恢复事务。
- CONTEXT定义了自定义的上下文。
TwoPhaseCommitSinkFunction的构造器需要两个TypeSerializer。一个是TXN的类型,另一个是CONTEXT的类型。
最后,TwoPhaseCommitSinkFunction定义了五个需要实现的方法:
- beginTransaction(): TXN开始一个事务,并返回事务的标识符。
- invoke(txn: TXN, value: IN, context: Context[_]): Unit将值写入到当前事务中。
- preCommit(txn: TXN): Unit预提交一个事务。一个预提交的事务不会接收新的写入。
- commit(txn: TXN): Unit提交一个事务。这个操作必须是幂等的。
- abort(txn: TXN): Unit终止一个事务。