大数据毕设选题 - 大数据招聘职业数据分析可视化系统(python 爬虫)
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 Flask框架
- 4 数据爬虫
- 5 最后
0 前言
Hi,大家好,这里是丹成学长的毕设系列文章!
对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
基于大数据的招聘职业爬取与分析可视化
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
1 课题背景
基于Python网络爬虫、Flask Web框架实现的职业能力大数据可视化服务平台
2 实现效果
首页
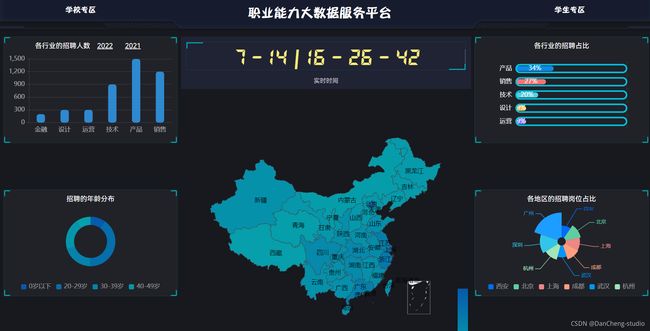
学生专区首页
点击导航栏的学生专区,进入学生专区首页。首页以表格+文字的形式展示数据。但是可能因为屏幕尺寸的原因出现错位。导航栏有查看职业信息与职业分析与推荐两个部分,后者需要登录。

职业信息界面
职业信息界面以卡片的方式展示了各种职业的信息。点击上面右边的文字可以进行筛选,点击左边的城市、分类、薪资可以进入相应的可视化界面。


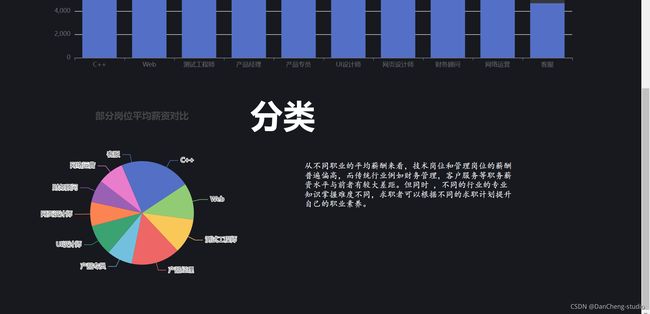
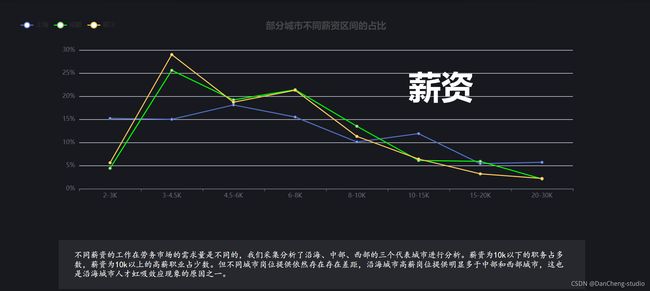
职业分析界面
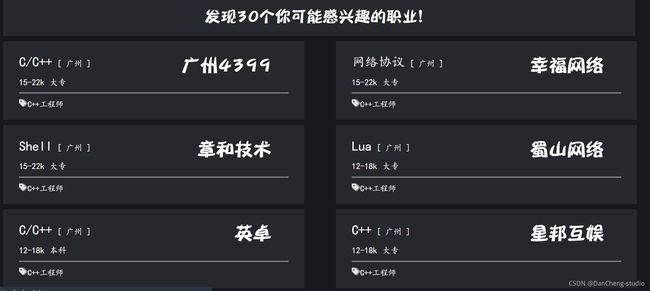
进行职业分析前需要先登录和注册,填写表单即可。

职业分析界面,填写表单即可。需要注意不能留空,不然会打回来重填。填写完提交即可,生成推荐职业。

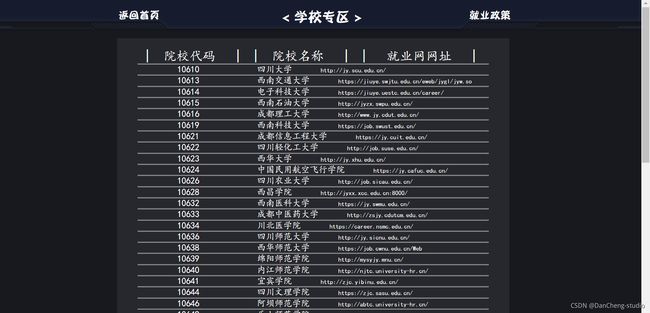
学校专区
学校专区的界面就比较简单了,首页展示各学校的就业网网址,就业政策展示教育部的就业政策:

3 Flask框架
简介
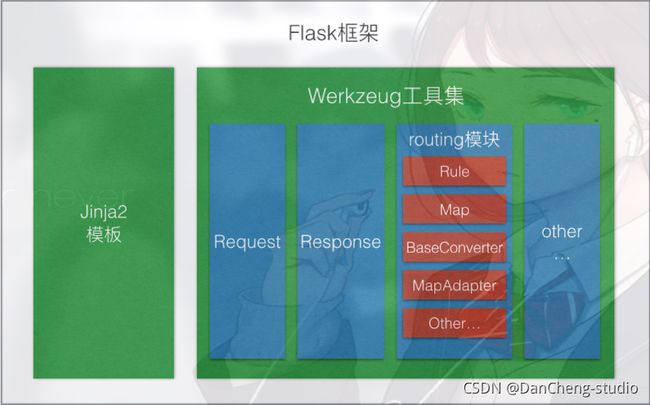
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
本项目在Flask开发后端时,前端请求会遇到跨域的问题,解决该问题有修改数据类型为jsonp,采用GET方法,或者在Flask端加上响应头等方式,在此使用安装Flask-CORS库的方式解决跨域问题。此外需要安装请求库axios。
Flask框架图
相关代码:
from flask import Flask, render_template,request, Response, make_response,redirect
from functions import login,job_info,job_analyse,school,policy,register
from functions.config import SQLManager
# 实例化并命名为app实例
app = Flask(__name__,
static_folder='static', # 配置静态文件的文件夹
template_folder='templates')
# 一些简单界面的路由
@app.route('/')
def index_view():
return render_template('index.html')
@app.route('/info')
def info_view():
return render_template('info.html')
@app.route('/echarts')
def echarts():
return render_template('echarts.html')
@app.route('/student')
def student_view():
cook=request.cookies.get('username')
if cook is None:
cook=''
return render_template('student.html',user=cook)
@app.route('/student/job_info/city')
def city_view():
cook=request.cookies.get('username')
if cook is None:
cook=''
return render_template('city.html',user=cook)
@app.route('/student/job_info/salary')
def salary_view():
cook=request.cookies.get('username')
if cook is None:
cook=''
return render_template('salary.html',user=cook)
@app.route('/student/job_info/category')
def category_view():
cook=request.cookies.get('username')
if cook is None:
cook=''
return render_template('category.html',user=cook)
@app.route('/student/job_info/class/' )
def cate_view(cate):
a=SQLManager()
i=a.get_one('select id from class where class_name="{}"'.format(cate))['id']
return redirect('/student/job_info?category={}'.format(i))
# 引入蓝图对象
app.register_blueprint(login.login)
app.register_blueprint(job_info.job_info)
app.register_blueprint(job_analyse.job_analyse)
app.register_blueprint(school.school)
app.register_blueprint(policy.policy)
app.register_blueprint(register.register)
# 调用run方法,设定端口号,启动服务
if __name__ == "__main__":
app.run(port=2022, host="0.0.0.0", debug=True)
4 数据爬虫
简介
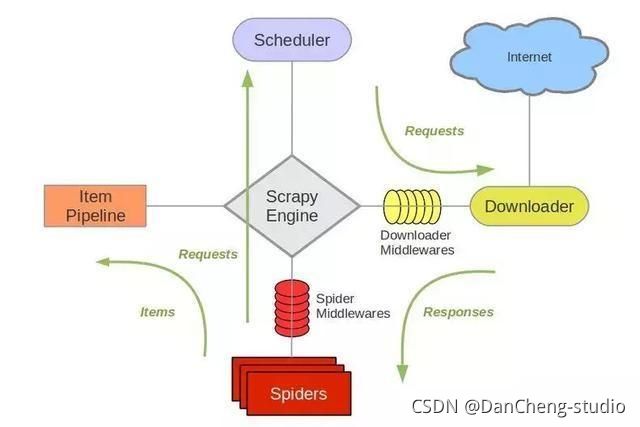
Scrapy是基于Twisted的爬虫框架,它可以从各种数据源中抓取数据。其架构清晰,模块之间的耦合度低,扩展性极强,爬取效率高,可以灵活完成各种需求。能够方便地用来处理绝大多数反爬网站,是目前Python中应用最广泛的爬虫框架。Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。各个组件的作用如下:
-
调度器(Scheduler):说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
-
下载器(Downloader):是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
-
爬虫(Spider):是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
-
实体管道(Item Pipeline):用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
-
Scrapy引擎(Scrapy Engine):Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
官网架构图
相关代码:
# -*- coding: utf-8 -*-
import scrapy
import random
import time
from foodwake.items import FoodwakespiderItem
class FoodwakeSpider(scrapy.Spider):
name = 'foodwake'
allowed_domains = ['www.foodwake.com']
start_urls = ['http://www.foodwake.com/category/food-class/0']
# //:匹配任意位置的节点 @:匹配属性
def parse(self, response):
for box in response.xpath('//div[@class="row margin-b2"]//a'):
new_url = box.xpath('.//@href').extract()[0]
yield scrapy.http.Request(new_url, callback=self.parse_item)
def parse_item(self, response):
for box in response.xpath('//div[@class="row margin-b2"]//a'):
new_url = box.xpath('.//@href').extract()[0]
yield scrapy.http.Request(new_url, meta={"url": new_url}, callback=self.parse_item_info)
def parse_item_info(self, response):
item = FoodwakespiderItem()
name = response.xpath('//h1[@class="color-yellow"]/text()').extract()[0].strip()
# food_nickname = ""
# try:
# nicknames = response.xpath('//h2[@class="h3 text-light"]/text()').extract()[0].strip()
# food_nickname = nicknames.split(':')[1]
# except:
# food_nickname = "无"
# url = response.meta["url"]
infoList = []
for box in response.xpath('//table[@class="table table-hover"]//tr'):
tds = box.xpath('.//td')
if len(tds) == 3:
info = {}
td_name = tds.xpath('.//text()').extract()[0]
td_unit = tds.xpath('.//text()').extract()[1]
td_value = ""
try:
td_value = td_unit + tds.xpath('.//text()').extract()[2]
info[td_name] = td_value
except:
info[td_name] = td_unit
infoList.append(info)
item['name'] = name
item['info'] = str(infoList)
# item['url'] = url
# item['nickname'] = food_nickname
yield item
print("······休眠 1 至 5 秒······")
time.sleep(random.randint(1, 5))