Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning(论文笔记)
文章目录
- 问题
- DL训练的Goodput
-
- 建模统计效益
- 建模系统吞吐量
-
- 建模 T g r a d T_{grad} Tgrad
- 建模 T s y n c T_{sync} Tsync
- 结合 T g r a d T_{grad} Tgrad和 T s y n c T_{sync} Tsync
- 考虑梯度累积
- Pollux设计
-
- PolluxAgent:任务级别的优化
- PolluxSched:集群优化
-
- p的取值
- 避免干扰
问题
如何分配资源,调整批量大小和学习率,对于深度学习集群的调度来说十分重要。
如果分配了过多的GPU,就会导致较长的队列等待时间和低效的资源使用。如果分配了太少的GPU,就会导致较长的运行时间,以及资源未被利用。而且在共享集群中,最优的选择是动态的。
除此之外,训练的批量大小能够影响系统的吞吐量,更大的批量意味着更多计算资源的更高的利用率,吞吐量也就更大。但是,较大的批量会导致统计效益的降低(统计效益:每个训练样本促进的训练进展)。
考虑到这些情况,这篇论文提出了Pullux,一个混合的资源调度器,可以为共享集群中的DL任务自适应地分配资源,调整批量大小和学习率。目标是最大化任务的吞吐量。
DL训练的Goodput
首先给出系统吞吐量的定义:即单位时间训练的样本数。
然后给出goodput的定义:一个DL训练任务在迭代t的goodput是它的系统吞吐量和统计效益的乘积。
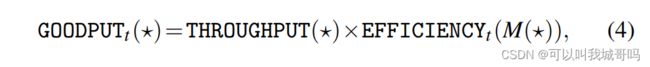
*代表能够影响吞吐量和批量大小的配置参数,M是所有GPU加和的总批量大小。
在这篇文章中,作者关注三个配置参数,即* = (a, m, s)。
- a,大小为N的分配向量,其中 a n a_n an是在节点n上分配的GPU的数量
- m,每个GPU的批量大小
- s,梯度累积步数
总批量大小被定义如下:
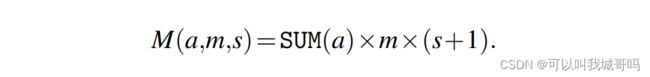
在Pullux中,用户提交作业时指定初始批量大小 M 0 M_0 M0和学习率(LR) η 0 \eta_0 η0。任务初始被指定在一个GPU上运行, m = M = M 0 m=M=M_0 m=M=M0, s = 0 s = 0 s=0, η = η 0 \eta = \eta_0 η=η0。当任务运行时,Pollux分析任务的执行来学习和改进吞吐量和效益的预测模型。使用这些预测模型,Pollux根据集群资源的可用性和性能,为每个任务周期性地调整 ( a , m , s ) (a,m,s) (a,m,s)。
Pollux只考虑不小于初始值的批量大小,在这种情况下, E F F I C I E N C Y t ( M ) EFFICIENCY_t(M) EFFICIENCYt(M)是一个相对于 E F F I C I E N C Y t ( M 0 ) EFFICIENCY_t(M_0) EFFICIENCYt(M0)的0到1之间的小数。
建模统计效益
作者将 E F F I C I E N C Y t ( M ) EFFICIENCY_t(M) EFFICIENCYt(M)建模为相对于初始批量大小 M 0 M_0 M0,使用批量大小M的每个训练样本促进的训练进展。首先文章定义了一个pre-conditioned gradient noise scale(PGNS),用 φ t \varphi_t φt表示:
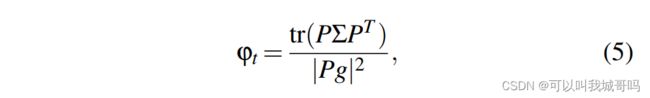
g是真实的梯度,P是适应性SGD算法的pre-conditioning矩阵, ∑ \sum ∑是每个样例随机梯度的协方差矩阵。作者将EFFICIENCY定义如下:
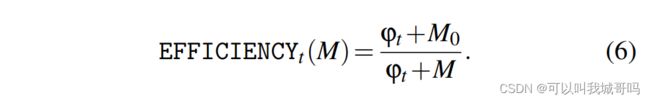
令 E F F I C I E N C Y t ( M ) = E EFFICIENCY_t(M)=E EFFICIENCYt(M)=E,则有如下性质:
- 0 < E ≤ 1 0 < E \leq 1 0<E≤1
- 使用批量大小为M进行训练需要处理1/E倍的训练样本,才能保证和批量大小为 M 0 M_0 M0的训练取得同样的进展
建模系统吞吐量
作者预测每个训练迭代花费的时间,然后计算吞吐量如下:
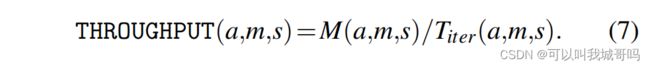
建模 T g r a d T_{grad} Tgrad
首先从计算局部梯度的时间, T g r a d T_{grad} Tgrad开始。运行时间和每个GPU的批量大小呈线性关系:
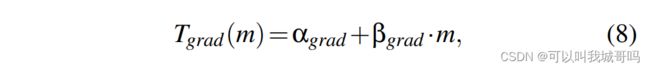
其中 α g r a d \alpha_{grad} αgrad和 β g r a d \beta_{grad} βgrad都是可拟合的参数。
建模 T s y n c T_{sync} Tsync
然后建模梯度同步时间, T s y n c T_{sync} Tsync。计算公式如下:
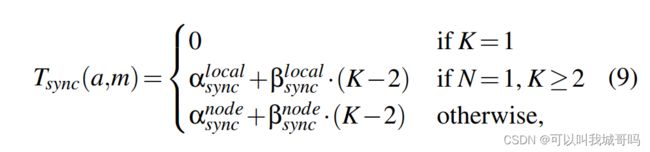
其中K是分配的所有GPU的数量,N是分配到的机器节点的数量。当N=1时,所有的GPU都在同一个机器上,梯度的同步会快很多。当N>1时,不同机器之间的通信要慢很多。
结合 T g r a d T_{grad} Tgrad和 T s y n c T_{sync} Tsync
之后结合上面两者,计算 T i t e r T_{iter} Titer,因为梯度的计算和通信可以流水线实现,因此会有重叠,所以使用以下公式来计算:
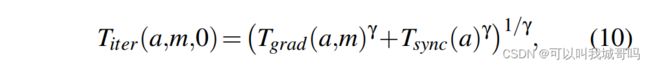
γ ≥ 1 \gamma \geq 1 γ≥1时可学习的参数,当 γ = 1 \gamma = 1 γ=1时, T i t e r = T g r a d + T s y n c T_{iter} = T_{grad} + T_{sync} Titer=Tgrad+Tsync。当 γ → ∞ \gamma \rightarrow \infin γ→∞时, T i t e r = m a x ( T g r a d , T s y n c ) T_{iter} = max(T_{grad}, T_{sync}) Titer=max(Tgrad,Tsync)。
考虑梯度累积
增大批量大小能够减少用于梯度同步的时间,但是GPU显存限制了批量的大小。有一种方法可以继续增大批量大小,即梯度累积。经历s次梯度的前向反向传播后,再聚合每个GPU的梯度,然后在第s+1次传播时同步梯度。此时的 T i t e r T_{iter} Titer如下:

Pollux设计
Pollux在两个不同的粒度上调整DL作业的执行。首先,在作业级别的粒度上,Pollux动态地调整批量大小和学习率,以最好地利用分配的资源。第二,在集群范围的粒度上,Pollux动态地(重新)分配资源,由共享集群的所有作业的goodput和集群级目标(包括公平性和作业完成时间)驱动。
Pollux的设计包括两个部分,PolluxAgent和PolluxSched。架构图如下:

首先,一个PolluxAgent与每个作业一起运行。它拟合该作业的EFFICIENCY和THROUGHPUT函数,并调整其批量大小和学习率,以有效利用其当前分配的资源。PolluxAgent定期向PolluxSched报告其作业的goodput函数。
其次,PolluxSched定期优化集群中所有作业的资源分配,考虑到每个作业的当前goodput函数和集群范围内的资源竞争。PolluxSched做出的调度决定还考虑了与资源重新分配相关的开销、多个作业之间的网络干扰导致的速度减慢以及资源的公平性。
PolluxAgent:任务级别的优化
PolluxAgent测量每次迭代所花费的时间,即 T i t e r T_{iter} Titer,并记录在其生命周期内遇到的所有资源分配a、每个GPU批次大小m和梯度积累步数s的组合的元组(a,m,s, T i t e r T_{iter} Titer)。PolluxAgent定期使用收集到的数据拟合吞吐量函数。PolluxAgent定期向PolluxSched汇报吞吐量拟合函数的参数和PGNS。
作者将所有的 α \alpha α和 β \beta β参数都设为非负,将 γ \gamma γ设为[1, 10]。
给定分配的资源,PolluxAgent调整批量大小和梯度累积步数以最大化goodput:
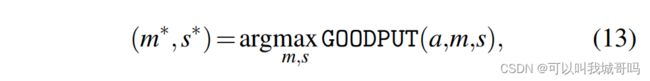
PolluxSched:集群优化
PolluxSched定期为集群中的每个作业分配(和重新分配)资源。为了确定一套有效的集群范围内的资源分配,它最大化了一个拟合函数,该函数被定义为每个任务加速比的幂平均:
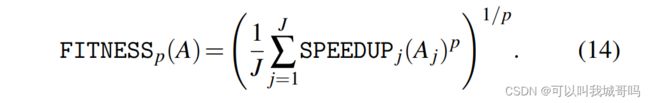
A是一个分配矩阵, A j A_j Aj表示任务j分配的GPU的数量,加速比定义如下:
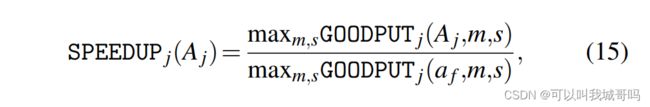
a f a_f af是为每个任务平均分配的资源,即每个任务占据1/J的集群资源。
根据函数拟合,PolluxSched可以得到一个goodput预测模型。据此,通过一个搜索程序,PolluxSched可以预测goodput(即给定分配资源,最大化goodput)来最大化FITNESS,最后将输出的分配应用到集群。
p的取值
p为1时,PolluxSched给能达到较高加速比的任务分配更多的GPU。当 p → − ∞ p\rightarrow -\infin p→−∞时,它趋向于导致所有任务的加速比相同。作者发现将p取为-1可以达到最多的goodput提升和合理的公平性。
避免干扰
当多个分布式DL任务分享一个节点时,他们同步梯度时的网络使用会彼此干扰,降低训练速度。Xiao et al.提到了网络资源的竞争会导致至多50%的DL训练速度降低。
PolluxSched通过确保至多一个分布式任务被分配到每个节点上,缓解了此问题。