Unicode和UTF-8的区别
文章目录
- 一、概念:
- 二、案例:
- 三、前因后果
- 四、结论:
一、概念:
本质上来说:
Unicode 是「字符集」 UTF-8 是「编码规则」
字符集: 为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point);
编码规则: 将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
二、案例:
每一个字符对应一个十六进制数字。
计算机只懂二进制,因此,严格按照unicode的方式(UCS-2),应该这样存储:
I 00000000 01001001
t 00000000 01110100
’ 00000000 00100111
s 00000000 01110011
00000000 00100000(这是空格的二进制)
知 01110111 11100101
乎 01001110 01001110
日 01100101 11100101
报 01100010 10100101
上面 8 个字符串总共占用了18个字节,但是对比中英文的二进制码,可以发现,英文前9位都是0!浪费啊,浪费硬盘,浪费流量。英文出现的频率明显比中文高的!
UTF-8是这样做的:
单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
n个字节的字符(n>1),第一个字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足。
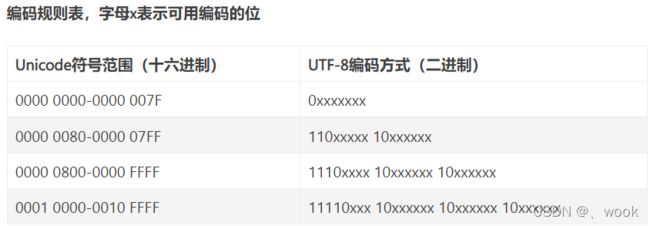
这样就形成了如下的UTF-8标记位:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
… …
于是,”It’s 知乎日报“就变成了:
I 01001001
t 01110100
’ 00100111
s 01110011
00100000(这是空格的二进制)
知 11100111 10011111 10100101
乎 11100100 10111001 10001110
日 11100110 10010111 10100101
报 11100110 10001010 10100101
和上边的方案对比一下,英文短了,每个中文字符却多用了一个字节。但是整个字符串只用了17个字节,比上边的18个短了一点点。
python是支持Unicode的,在使用Unicode时,在字符串前加上u即可。
要看懂从unicode 二进制 变为 utf-8二进制,需要了解如下规则
UTF-8 是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
编码规则:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
例如 utf8中,中文占3个字节,即第一个字节的前3位都设为1,第3 + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
如上规则推算unicode 的 知 【0111】【0111】 【1110】【0101】 转换为 utf8 知的二进制同理
- 1.中文在utf8 是3个字节,所以 第1个字节的前3位为 111,第3+1位为0,得到 1110
- 2.后面还有2个字节,前两位一律为10 。即 1110xxxx 10xxxxxx 10xxxxxx
- 3.将unicode的二进制,补上xxx的部分就得到 1110【0111】 10【0111】【11】 10【10】【0101】
三、前因后果
ASCII码:是用一个字节(8bit, 0-255)中的127个字母表示大小写字母,数字和一些符号.主要用来表示现代英语和西欧语言。
所以处理中文就出现问题了,因为中文处理至少需要两个字节,所以中国制定了GB2312。
所以,各国制定了各国的标准。日本制定了Shift_JIS,韩国制定了Euc-kr。。。那么,乱码就来了。
为了统一,Unicode诞生了。统一码把所有语言都统一到一套编码里。解决了乱码问题,但是存储和传输效率低下的问题又来了。
因为ASCII编码是1个字节,而Unicode编码通常是2个字节。你表示一个英文字母一个字节就够了,但是Unicode却不得不用两个字节来表示(另一个字节补0)。
四、结论:
unicode是静态的,而且是固定长度的,一一对应;unicode-8是一套规则,字长是可变的,即对应的字符结果是可变的。
为了节约,出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间(ASCII码可以看成是UTF-8的一部分,所以大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作)。
说到编码,得先从ASCII编码讲起。ASCII编码是由美国人发明,美国的字符不超过255个,所以ASCII编码使用了8bit 即一个字节来存储字符。由于汉字的数量远超255个,所以中国自己发明了一个GB2312编码来表示汉字,一般的汉字使用2个字节,对于一些生僻的汉字则使用更多的字节来表示,当然,GB2313编码是可以兼容ASCII码的。
然后,日本,韩国等等国家也自己发明了一套编码方法,这时候又出现了一个新的问题。如果一篇文章里面,即有中文,又有日文的话,无论使用中文的编码方法还是使用日文的编码方法都会出现乱码。随后,unicode编码便应运而生。unicode编码对文字的编码进行了统一,当然,unicode只是一种编码规范,它有多个版本,常用的unicode编码使用了16位来存储字符,16位的存储空间足以容纳世界上所有书面字符(对于汉字来说,一共有6万多个,只能包含其中的一些常用汉字,所以unicode编码对于汉字的兼容性并不是特别好)。unicode编码兼容了ASCII码,ASCII码转unicode编码时,保持后8位不变,前8位只需要用0去补全即可。
使用了unicode编码后,又有新的问题出现。因为unicode编码是用两个字节来存储字符,如果一篇文章中,大部分都是英文,使用unicode编码就会造成空间的浪费,对英文部分使用ASCII码只需要一个字节就可以了。这时候,utf-8解决了这个问题。utf-8是一种可变长的字符编码,当存储英文时只使用一个字节,节省了一半的空间,而存储中文字符时,长度还是不变。utf-8虽然压缩了存储空间,但是如果在内存中存储,使用utf-8却由于它的长度不固定,带来了很大的不便,使得在内存处理字符变得复杂。应对这个问题的解决策略是:在内存中存储字符时还是使用unicode编码,因为unicode编码的长度固定,处理起来很方便。而在文件的存储中,则使用utf-8编码,可以压缩内存,节省空间。这里一般有个自动转换的机制,即从文件中读取utf-8编码到内存时,会自动转换为unicode编码,而从内存中将字符保存到文件时,则自动转换为utf-8编码。