scikit-learn机器学习算法封装
K近邻算法
K-最近邻(KNN)是一种有监督的机器学习算法,可用于解决分类和回归问题。它基于一个非常简单的想法,数据点的值由它周围的数据点决定。考虑的数据点数量由k值确定。因此,k值是算法的核心。

我们现在已经知道。 这个大量输入的学习资料, 其实更加专业的一个叫法是训练的数据集数据集。那么对于我们的监督学习来说,训练的数据集不仅包括这些数据相应的特征也就是X_train, 还要包括数据所对应的标签, 或者说是最终的这个类别结果通常我们叫它y_train, 那么我们将x_train和y_train送入机器学习算法训练模型的这个过程,通常在英文上管这个过程叫做fit, 我们可以翻译成拟合,也就是说我们的算法要得到一个模型,这个模型要能够拟合我们的训练数据集,输入的样例送到模型之后,这个模型获得输出结果的这个过程通常英文叫做predict,也就是预测。
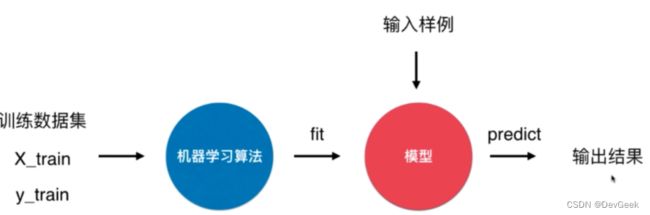
更加专业的认识,可能有一些同学再去想我们的KNN算法,就会有这样的一个疑问了,对于我们的KNN算法,我们并没有得到什么模型啊,事实上确实如此, 这可能也是KNN算法的一个非常重要的特性, 近乎可以说KNN算法是机器学习中唯一一个不需要训练过程的算法, 换句话说, 这个输入样例直接可以送给这个训练数据集, 在这个训练数据集上直接找到离输入样例最近的K个点, 然后投票选出来投票数最高的那一个标签就是结果了,
- k近邻算法是非常特殊的,可以被认为是没有模型的算法
- 为了和其他算法统一,可以认为训练数据集就是模型本身
事实上在scikitlearn机器学习库库的设计上就是使用这样的一个设计方式,这是为了可以方便的和其他算法统一,这样每一个算法都会有fit这个过程。
对于KNN来说, 机器学习算法其实就是将X_train和y_train这个数据集拷贝过来,形成了我们的模型, 而训练集本身就是模型, 而相对复杂的其实是在这个预测的过程,在预测过程中,我们将输入样例交给模型,并采用以下步骤:
- 寻找K个最近的元素。
- 统计它们的投票结果。
- 最终得出输出的预测结果。
虽然在预测过程中涉及到一些复杂的步骤,但不管怎么样,这种方式为KNN算法找到了适应的模型。
对于KNN算法的训练过程或拟合过程,在scikit-learn框架下,与其他机器学习算法的训练过程是统一的,首先进行fit操作以获得模型,然后进行相应的predict操作。但对于KNN算法来说,fit过程非常简单,稍后我们将深入研究并从底层实现自己的KNN模型。
一、拟合 欠拟合 过拟合
1.拟合:
根据训练样本中学习出适用于所有潜在样本的“普遍规律”,这样在遇到新样本时做出正确的判别,即具有很好的泛化能力。
2.欠拟合
是指对训练样本的一般性质没有学好,即无法更好的判别测试样本, 甚至在训练集上的表现就很差。
3.过拟合
当学习器把训练样本学习的很“优秀”,即在训练集上表现优秀,近似完美的预测或者区分出了所有的数据,但是在新的测试样本集却无法正确预测或者区分,缺乏泛化能力。
K值的重要性
选择最优k值是建立一个合理、精确的knn模型的必要条件。
如果k值太低,则模型会变得过于具体,不能很好地泛化。它对噪音也很敏感。该模型在训练组上实现了很高的精度,但对于新的、以前看不到的数据点,该模型的预测能力较差。因此,我们很可能最终得到一个过拟合的模型。
如果k选择得太大,模型就会变得过于泛化,无法准确预测训练和测试集中的数据点。这种情况被称为欠拟合。
泛化能力
泛化能力(Generalization Ability)是指机器学习模型对于未在训练集中见过的新数据的适应能力或泛化能力。具体来说,它衡量了模型在面对新样本时能否产生准确的预测或正确的分类。泛化能力是评估一个机器学习模型优劣的重要指标之一。
泛化能力的概念可以用以下方式来理解:
-
训练集和测试集:在机器学习中,通常将数据集分为两部分:训练集(Training Set)和测试集(Test Set)。模型在训练集上学习模式和规律,然后在测试集上进行性能评估。
-
泛化到新数据:泛化能力指的是模型在测试集上表现良好,同时也能够对未在训练集中出现过的新数据做出准确的预测或分类。这意味着模型不仅仅能够背诵训练数据,还能够理解数据背后的真实规律。
-
避免过拟合和欠拟合:泛化能力的好坏与过拟合(Overfitting)和欠拟合(Underfitting)密切相关。过拟合指模型在训练集上表现很好,但在测试集或新数据上表现差。欠拟合指模型未能很好地拟合训练数据,因此在训练集和测试集上都表现不佳。泛化能力良好的模型能够在训练集和测试集之间取得平衡,避免过拟合和欠拟合问题。
-
交叉验证:为了评估模型的泛化能力,通常会使用交叉验证等技术,将数据集进一步划分为多个子集,以进行模型评估和参数调整,以确保模型在不同数据集上都能够泛化良好。
总的来说,泛化能力是机器学习模型成功应用于实际问题的关键因素之一。一个具有良好泛化能力的模型能够在新数据上产生可靠的结果,而不仅仅是在训练数据上表现良好。因此,在开发和评估机器学习模型时,泛化能力是一个重要的考虑因素。
使用scikit-learn中的KNN
对于sklearn中所有的机器学习算法算法都是以面向对象的形式进行包装的,所以首先我们要做的事情是创建一个实例
可能遇到的bug
注意在我们调用预测方法的时候可能会出现一个bug, 这里可能会出现一个bug, 如果sklearn kmean 算法predict时候出现 ‘NoneType‘ object has no attribute ‘split‘ sklearn, 我们只需要在命令行输入
pip install threadpoolctl==3.1.0然后重新启动jupyter notebook就解决了
我们整理一下用scikitlearn模块使用kNN算法的这个过程
- ①:加载scikitlearn模块中相应的机器学习的算法
- ②:然后创建算法所对应的实例, 如果这个算法在构造的过程中需要一些参数,相应的我们也要传入这些参数
- ③:进行fit我们的训练数据集
- ④:进行预测
我们有完全的自由来创建自己的机器学习算法,只要我们遵守scikit-learn的标准,这个算法就可以轻松地集成到scikit-learn的其他方法中。
面向函数封装KNN算法
"kNN_function\kNN.py"
# coding:utf-8
# """KNN算法的实现过程"""
import numpy as np
from math import sqrt
from collections import Counter
def KNN_classify(k, X_train, y_train, x):
"""
:param k: 选取的距离最近的K个样本
:param X_train、y_train:样本训练数据集
:param x:将要预测的特征向量
:return: 判断结果
"""
# 判断数据是否合法
assert 1 <= k <= X_train.shape[0], "K must valid"
# 我们需要确保X_train中样本的数量和y_train中Label的数量是相等的
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
# 并且我们需要确保将要预测的样本的特征数量和我们所使用的X_train训练数据集中的特征数量是相同的
assert X_train.shape[1] == x.shape[0], \
"the feather number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in X_train]
# 得到排序后的数组中的元素分别在原数组中对应的索引
nearest = np.argsort(distances)
# 查找这几个距离最近的k个样本在y训练集中所对应的类别
topk_y = [y_train[i] for i in nearest[:k]]
votes = Counter(topk_y) # 对投票结果进行统计
predict = votes.most_common(1)[0][0] # 得到预测结果
if predict == 1:
return "该病人可能为恶性肿瘤"
if predict == 0:
return "该病人可能为良性肿瘤"
面向对象实现KNN算法
"kNN\kNN.py"
# coding:utf-8
"""使用面向对象的方式封装我们的KNN算法"""
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self, k):
"""初始化KNN分类器"""
# 判断数据是否合法
assert 1 <= k, "K must valid"
# 将k的值传给一个成员变量
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""Fit函数由用户传来Xtrain和y_train相应的去获得模型,也就是跟据所谓的训练数据集来训练我们的KNN分类器
"""
# 判断数据是否合法
# 我们需要确保X_train中样本的数量和y_train中Label的数量是相等的
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
# 我们需要确保k的值要在训练数据集的样本数量范围内
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k"
self._X_train = X_train
self._y_train = y_train
# 这里其实可以不用设置返回值, 但我们还是尽量遵循scikit-learn的设置原则来将self对象返回
# 我们完全可以设计一个属于我们自己的机器学习的算法, 只要我们完全遵守scikit的标准的话, 那么这个算法就可以无缝的送给sklearn中的其他的算法中
return self
def predict(self, X_predict):
"""给定待测二维数据集X_predict, 返回表示X_predict的结果向量"""
# 判断用户设置的数据是否合法
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict"
# 特征的个数必须和训练集中的列数特征是一致的
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
# 接下来我们对X_train样本中的每一行进行逐行预测, 并把预测后的结果放到一个向量中
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""
给定单个待预测预测的数据x, 返回x_predict的预测结果值
:param x: predict方法运行所传入的样本数据
:return:
"""
# 判断用户输入的数据集中的样本的特征个数是否和训练集中的样本特征个数一致
assert x.shape[0] == self._X_train.shape[1], \
"the feather number of x must be equal to X_train"
# 求出新输入的样本与训练数据集中每一个样本的距离
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
# 返回排序后的数组中的元素在元素中的位置索引
nearest = np.argsort(distances)
# 进行投票(也就是分别得出最近的k个样本的类别)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
# 统计投票结果
vote = Counter(topK_y)
# 返回预测结果(取出投票结果最大的类别, 也就是最有可能是哪一类)
return vote.most_common(1)[0][0]
def __repr__(self):
return "KNN(k=%d)" % self.k
接下来会将我们实现的模块加载到jupyter中
02-kNN-in-scikit-learn.ipynb
import numpy as np
import matplotlib.pyplot as plt
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
x = np.array([8.093607318, 3.365731514])
# 我们加载我们实现的KNN方法
%run ./Pycharm_project/kNN_function/kNN.py
predict_y = KNN_classify(6, X_train, y_train, x)
predict_y
'该病人可能为恶性肿瘤'
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train, y_train)
KNeighborsClassifier(n_neighbors=6)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KNeighborsClassifier(n_neighbors=6)
x = x.reshape(1, -1) # 因为我们输入的训练数据集是矩阵, 所以我们也要把将要预测的数据转化为二维数组
kNN_classifier.predict(x)
array([1])
X_predict = x.reshape(1, -1)
X_predict
array([[8.09360732, 3.36573151]])
kNN_classifier.predict(X_predict)
array([1])
y_predict = kNN_classifier.predict(X_predict)
y_predict[0]
1
%run ./Pycharm_project/KNN/kNN.py
knn_clf = KNNClassifier(3)
knn_clf.fit(X_train, y_train)
KNN(k=3)
X_predict = x.reshape(1, -1) # 因为我们输入的训练数据集是矩阵, 所以我们也要把将要预测的数据转化为二维数组
y_predict = knn_clf.predict(X_predict)
y_predict
array([1])
y_predict[0]
1
以上就是我们实现KNN算法的过程, 事实上sklearn内部的KNN算法的底层实现, 不像我们实现的这么简单, 而使用了更加复杂的方式, 这是因为KNN本身在预测的过程中是非常好使的。对于KNN的缺点在这一章的最后我还会再向大家总结的。