YOLOv5、YOLOv8改进:空间金字塔池化 SPPF改为 SimSPPF / ASPP / RFB / SPPCSPC / SPPFCSPC
目录
1.SPP
2.sppf yolov5作者基于spp提出
3.YOLOv5/YOLOv8改进之结合ASPP
3.1空洞卷积(Atrous Convolution)
3.2空洞空间卷积池化金字塔
2.配置yolo.py文件
3.配置yolov5/yolov8_ASPP.yaml文件
4.1SimSPPF
5.RFB模块(Receptive Field Block)
6.SPPCSPC
7.SPPFCSPC
1.SPP
空间金字塔池化(Spatial Pyramid Pooling,SPP)是一种用于解决输入尺寸不同的图像在深度学习中常见的问题的技术。它通过将不同尺寸的感受野划分成不同的层级,并对每个层级内的特征进行池化操作,从而能够对任意大小的输入图像进行固定长度的特征表示。
SPP最初由He et al.在2014年的论文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》中提出,并被成功应用于目标检测和图像分类任务中。
SPP的主要步骤:
-
输入特征图:给定一张输入图像,首先经过卷积神经网络(如CNN)提取特征,得到一个特征图。
-
划分网格:SPP将特征图分成多个不同尺寸的网格,每个网格对应一个特定大小的感受野。这些感受野可以是不同比例和不同大小的矩形或正方形。
-
池化操作:对于每个网格,应用池化操作(如最大池化)来提取该网格内的特征。不同尺寸的感受野会产生不同大小的区域特征。
-
特征拼接:将所有池化后的特征按照顺序拼接在一起,形成一个固定长度的特征向量。
主要解决两个问题
1.有效避免了R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题。
2.解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
- 问题1具体解释:
在含有全连接层的分类网络中,严格要求输入分辨率和全连接层的特征维度相匹配。所以就会对图像进行裁剪和变形操作,也就出现了问题1。如下图展示的就是通过spp模块将任意分辨率的featherMap转换为设计好的和全连接层相同维度的特征向量。
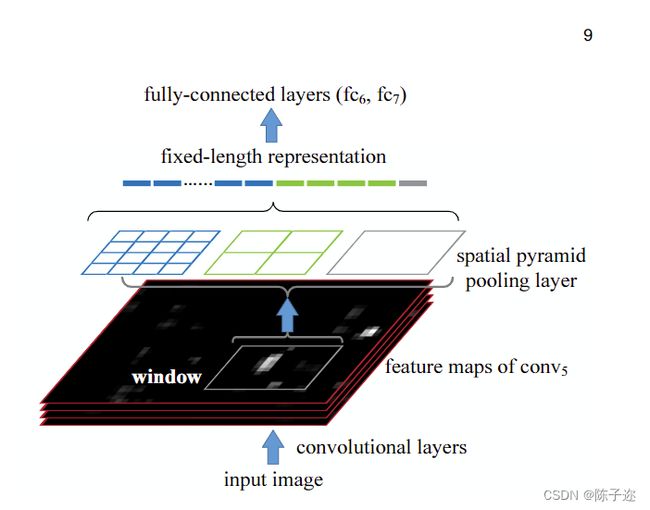 具体做法是,在conv5层得到的特征图是256层,每层都做一次spatial pyramid pooling。先把每个特征图分割成多个不同尺寸的网格,比如网格分别为44、22、11,然后每个网格做max pooling,这样256层特征图就形成了16256,4256,1256维特征,他们连起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。
具体做法是,在conv5层得到的特征图是256层,每层都做一次spatial pyramid pooling。先把每个特征图分割成多个不同尺寸的网格,比如网格分别为44、22、11,然后每个网格做max pooling,这样256层特征图就形成了16256,4256,1256维特征,他们连起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。
- 问题2具体解释:
R-CNN是先对输入图像进行2k个候选框选择后,把候选框内的图像wrap到227*277后,再放到cnn里边进行提取,这2k个候选框很多地方都是重叠的,会带来大量重复的计算,因此SPP就先对输入图像进行特征提取之后,在提取后的feature map上在选取候选框,然后使用spatial pyramid pooling,对对应候选框的feature map区域提到到fixed-length representation。
对卷积层可视化发现:输入图片的某个位置的特征反应在特征图上也是在相同位置。基于这一事实,对某个ROI区域的特征提取只需要在特征图上的相应位置提取就可以了。
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
2.sppf yolov5作者基于spp提出
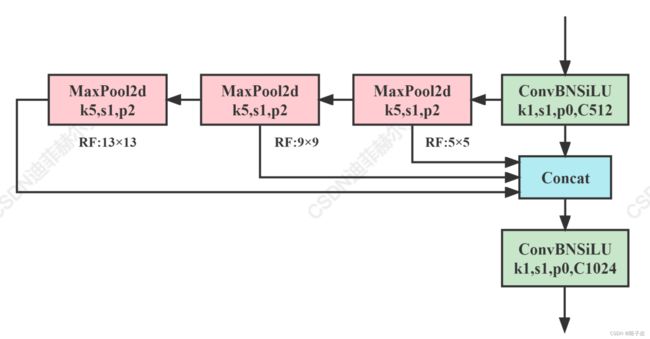
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
3.YOLOv5/YOLOv8改进之结合ASPP
3.1空洞卷积(Atrous Convolution)
空洞卷积和普通的卷积操作不同的地方在于卷积核中按照一定的规律插入了一些(rate-1)为零的值,使得感受野增加,而无需通过减小图像大小来增加感受野。
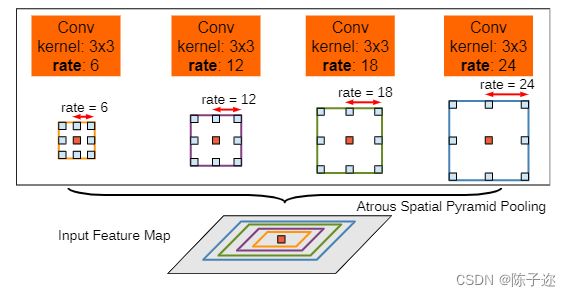
3.2空洞空间卷积池化金字塔
空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)对所给定的输入以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文。
1.配置common.py文件
#ASPP——————————————————————————————————————————————————————————————
class ASPP(nn.Module):
def __init__(self, in_channel=512, depth=256):
super(ASPP,self).__init__()
self.mean = nn.AdaptiveAvgPool2d((1, 1)) #(1,1)means ouput_dim
self.conv = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block1 = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18)
self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x):
size = x.shape[2:]
image_features = self.mean(x)
image_features = self.conv(image_features)
image_features = F.upsample(image_features, size=size, mode='bilinear')
atrous_block1 = self.atrous_block1(x)
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
net = self.conv_1x1_output(torch.cat([image_features, atrous_block1, atrous_block6,
atrous_block12, atrous_block18], dim=1))
return net2.配置yolo.py文件

3.配置yolov5/yolov8_ASPP.yaml文件
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, ASPP, [1024]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]4.1SimSPPF
美团yolov6提出的

class SimConv(nn.Module):
'''Normal Conv with ReLU activation'''
def __init__(self, in_channels, out_channels, kernel_size, stride, groups=1, bias=False):
super().__init__()
padding = kernel_size // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class SimSPPF(nn.Module):
'''Simplified SPPF with ReLU activation'''
def __init__(self, in_channels, out_channels, kernel_size=5):
super().__init__()
c_ = in_channels // 2 # hidden channels
self.cv1 = SimConv(in_channels, c_, 1, 1)
self.cv2 = SimConv(c_ * 4, out_channels, 1, 1)
self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
和上面ASPP的改法一致,就不展开写了
5.RFB模块(Receptive Field Block)
是一种用于目标检测任务的网络模块,最初由Yan et al.在2018年的论文《Rethinking Feature Discrimination and Polymerization for Large-scale Recognition》中提出。RFB模块旨在增强特征的判别能力和重叠感受野,以提高目标检测的性能。
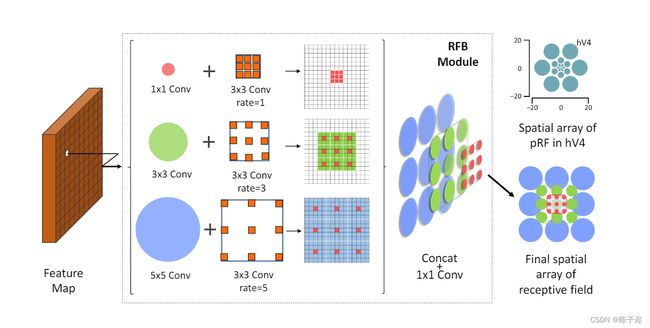
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True):
super(BasicConv, self).__init__()
self.out_channels = out_planes
if bn:
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True)
self.relu = nn.ReLU(inplace=True) if relu else None
else:
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=True)
self.bn = None
self.relu = nn.ReLU(inplace=True) if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class BasicRFB(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, scale=0.1, map_reduce=8, vision=1, groups=1):
super(BasicRFB, self).__init__()
self.scale = scale
self.out_channels = out_planes
inter_planes = in_planes // map_reduce
self.branch0 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, 2 * inter_planes, kernel_size=(3, 3), stride=stride, padding=(1, 1), groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision, dilation=vision, relu=False, groups=groups)
)
self.branch1 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, 2 * inter_planes, kernel_size=(3, 3), stride=stride, padding=(1, 1), groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision + 2, dilation=vision + 2, relu=False, groups=groups)
)
self.branch2 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, (inter_planes // 2) * 3, kernel_size=3, stride=1, padding=1, groups=groups),
BasicConv((inter_planes // 2) * 3, 2 * inter_planes, kernel_size=3, stride=stride, padding=1, groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision + 4, dilation=vision + 4, relu=False, groups=groups)
)
self.ConvLinear = BasicConv(6 * inter_planes, out_planes, kernel_size=1, stride=1, relu=False)
self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
out = self.ConvLinear(out)
short = self.shortcut(x)
out = out * self.scale + short
out = self.relu(out)
return out
6.SPPCSPC
该模块出自yolov7,表现由于sppf但是参数量和计算量较大
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
#分组SPPCSPC 分组后参数量和计算量与原本差距不大,不知道效果怎么样
class SPPCSPC_group(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC_group, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1, g=4)
self.cv2 = Conv(c1, c_, 1, 1, g=4)
self.cv3 = Conv(c_, c_, 3, 1, g=4)
self.cv4 = Conv(c_, c_, 1, 1, g=4)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1, g=4)
self.cv6 = Conv(c_, c_, 3, 1, g=4)
self.cv7 = Conv(2 * c_, c2, 1, 1, g=4)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
7.SPPFCSPC
结合了SPPCSPC和SPPF优点的新模块
class SPPFCSPC(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=5):
super(SPPFCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
x2 = self.m(x1)
x3 = self.m(x2)
y1 = self.cv6(self.cv5(torch.cat((x1,x2,x3, self.m(x3)),1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
SPPCSPC和SPPFCSPC的模块结构图

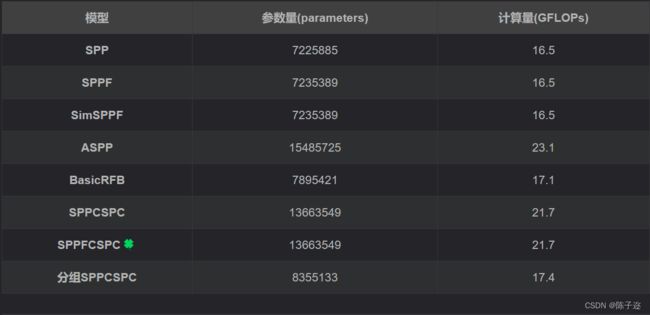
参数量对比