vue3项目使用pdf.js插件实现:搜索高亮、修改pdf.js显示的页码、向pdf.js传值、控制搜索、处理接口文件流
文章目录
-
- 一、pdf.js介绍
- 二、实现pdf预览的两种方式
-
- 1、使用viewer.html
- 2、将PDF文件渲染成Canvas
- 三、viewer.js的使用形势下的一些方法及技巧
-
- 1、实现外部操作跳转到具体的某一页
-
- 法1)、修改viewer.js源码,添加一个可供页面跳转的参数page
- 法2)、修改pdf.js里面的页码
- 2、获取pdf.js里面的页码
- 3、根据pdf.js内置的postMessage函数、findBar函数实现外部文本的搜索
- 4、在pdfjs-3.7.107-dist版本中,给pdf.js传参的处理
- 5、在pdfjs-3.7.107-dist版本中,修改convertToRegExpString方法,更换匹配方法(可匹配到带有空格的文档)
- 6、如果后端返回的是流的形式,就用此方法转一下
- 7、 下载
- 四、原理
- 五、pdf.js历史版本的下载
-
- pdfjs-1.9.426下载地址
- pdfjs-3.7.107下载地址
- 下载方式
一、pdf.js介绍
官网地址:http://mozilla.github.io/pdf.js/
中文文档地址:https://gitcode.gitcode.host/docs-cn/pdf.js-docs-cn/print.html
PDF.js是基于HTML5技术构建的,用于展示可移植文档格式的文件(PDF),它可以在现代浏览器中使用且无需安装任何第三方插件。
pdf.js主要包含两个库文件
pdf.js:负责API解析
pdf.worker.js:负责核心解析
二、实现pdf预览的两种方式
1、使用viewer.html
viewer.html主要分为三层:outerContainer层、printContainer层(该层目前为空)、xl-chrome-ext-bar层、fileInput域。
-
从官网下载pdf.js包
下载地址:https://mozilla.github.io/pdf.js/getting_started/#download -
引入pdf.js包
可将pdf.js包 放到服务器上 如:http://xxxx:8080/static/pdfjs
也可将pdf.js包直接解压在public文件夹下
pdf.js包的目录结构
│ ├── pdf.js - 显示层
│ ├── pdf.js.map - 显示层source map
│ ├── pdf.worker.js - 核心层
│ └── pdf.worker.js.map - 核心层source map
├── web/
│ ├── cmaps/ - character maps (required by core)
│ ├── compressed.tracemonkey-pldi-09.pdf - PDF文件,用于测试目的
│ ├── debugger.js - 用于debug
│ ├── images/ - 图标
│ ├── locale/ - 本地化文件
│ ├── viewer.css - 样式
│ ├── viewer.html - 用于展示的html文件
│ ├── viewer.js - 展示层
│ └── viewer.js.map - 展示层source map
└── LICENSE
- 使用iframe标签显示pdf
1)若pdf.js包及pdf文件都在服务器上部署
<iframe :src="url" width="100%" height="100%" frameborder="0"></iframe>
pdfServerUrl = 'http://xxxx:8080/static/pdfjs/web/viewer.html'
pdfInfoUrl = 'http://xxxx:8080/XXX/getClausePdf?Code=1234'
url = `${pdfServerUrl}?file=${encodeURIComponent(pdfInfoUrl)}` // 调取接口返回文件流
2)若pdf.js包及pdf文件都在本地
<iframe :src="`/PDF.js/web/viewer.html?file=${pdf}` width="100%" height="100%" frameborder="0"></iframe>
<script>
import pdf from '/images/file/11.pdf'
</script>
注:
此方法可以实现pdf的预览、全文搜索、搜索内容高亮展示、文本复制的功能
2、将PDF文件渲染成Canvas
安装
pnpm i pdfjs-dist // "pdfjs-dist": "^3.5.141"
在vue页面
<template>
<div id="pdf-container">
<canvas v-for="page in state.pdfPages" :key="page" :id="`pdfCanvas${page}`" style="border-bottom:1px solid #d4d2d2" />
</div>
</template>
import * as PDF from 'pdfjs-dist'
const pdfjsWorker = import('pdfjs-dist/build/pdf.worker.entry')
PDF.GlobalWorkerOptions.workerSrc = pdfjsWorker
import pdf from '/images/file/11.pdf'
const state = reactive<any>({
pdfPath: pdf, // 本地PDF文件路径放在/public中
pdfPages: '', // 页数
pdfWidth: '', // 宽度
pdfSrc: '', // 地址
pdfScale: 1.0, // 放大倍数
})
let pdfDoc: any = null
onMounted(() => {
loadFile(state.pdfPath)
})
function loadFile(url: string) {
PDF.getDocument(url).promise.then((p: any) => {
pdfDoc = p
const { numPages } = p
state.pdfPages = numPages
nextTick(() => {
renderPage(1) // 从第一页开始渲染
})
})
}
function renderPage(num: number) {
pdfDoc.getPage(num).then((page: any) => {
const canvas: any = document.getElementById(`pdfCanvas${num}`)
const ctx = canvas.getContext('2d')
const dpr = window.devicePixelRatio || 1
const bsr
= ctx.webkitBackingStorePixelRatio
|| ctx.mozBackingStorePixelRatio
|| ctx.msBackingStorePixelRatio
|| ctx.oBackingStorePixelRatio
|| ctx.backingStorePixelRatio
|| 1
const ratio = dpr / bsr
const viewport = page.getViewport({ scale: state.pdfScale })
canvas.width = viewport.width * ratio
canvas.height = viewport.height * ratio
canvas.style.width = '100%'
canvas.style.height = '100%'
state.pdfWidth = `${viewport.width}px`
ctx.setTransform(ratio, 0, 0, ratio, 0, 0)
// 将 PDF 页面渲染到 canvas 上下文中
const renderContext = {
canvasContext: ctx,
viewport,
}
page.render(renderContext)
if (state.pdfPages > num)
renderPage(num + 1)
})
}
注:
此代码只能实现pdf预览功能,如果要文本复制,要使用Text-Layers渲染
使用到的函数解读
getDocument():用于异步获取PDf文档,发送多个Ajax请求以块的形式下载文档。它返回一个Promise,该Promise的成功回调传递一个对象,该对象包含PDF文档的信息,该回调中的代码将在完成PDf文档获取时执行。
getPage():用于获取PDF文档中的各个页面。
getViewport():针对提供的展示比例,返回PDf文档的页面尺寸。
render():渲染PDF。
如果要文本复制,需要将page.render(renderContext)修改为以下代码:
// 要引入组件
import * as pdfjsViewer from 'pdfjs-dist/web/pdf_viewer.js'
import 'pdfjs-dist/web/pdf_viewer.css'
page.render(renderContext).then(() => {
return page.getTextContent();
}).then((textContent) => {
// 创建文本图层div
const textLayerDiv = document.createElement('div');
textLayerDiv.setAttribute('class', 'textLayer');
// 将文本图层div添加至每页pdf的div中
pageDiv.appendChild(textLayerDiv);
// 创建新的TextLayerBuilder实例
var textLayer = new TextLayerBuilder({
textLayerDiv: textLayerDiv,
pageIndex: page.pageIndex,
viewport: viewport
});
textLayer.setTextContent(textContent);
textLayer.render();
});
重点函数解读:
page.render():该函数返回一个当PDF页面成功渲染到界面上时解析的promise,我们可以使用成功回调来渲染文本图层。
page.getTextContent():该函数的成功回调会返回PDF页面上的文本片段。
TextLayerBuilder:该类的实例有两个重要的方法。setTextContent()用于设置page.getTextContent()函数返回的文本片段;render()用于渲染文本图层。
三、viewer.js的使用形势下的一些方法及技巧
1、实现外部操作跳转到具体的某一页
法1)、修改viewer.js源码,添加一个可供页面跳转的参数page
<iframe :src="`/PDF.js/web/viewer.html?file=${pdf}&page=${pageNum}`` width="100%" height="100%" frameborder="0"></iframe>
<script>
import pdf from '/images/file/11.pdf'
const pageNum = 1
</script>
缺点:每次跳转的时候pdf会重新加载一遍,然后跳到对应的位置
法2)、修改pdf.js里面的页码
const pdfFrame = document.getElementById('myIframe').contentWindow
pdfFrame.PDFViewerApplication.page = 10 // 传入需要让跳转的值
根据pdf.js内置函数,可直接修改当前页面,没有太大的跳动,解决了上面方法的缺点
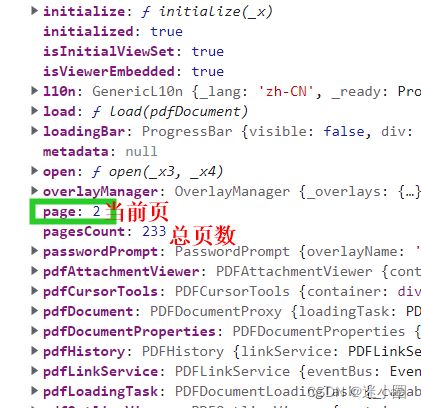
2、获取pdf.js里面的页码
pdf.js内置的page属性把动态的当前页码导出
onMounted(() => {
interval.value = setInterval(checkPdf, 300)
})
const checkPdf = () => {
const pdfFrame = document.getElementById('myIframe').contentWindow
currentPage.value = pdfFrame.PDFViewerApplication.page
}
注:
3、根据pdf.js内置的postMessage函数、findBar函数实现外部文本的搜索
<a-button @click="getTextHighLight">
点击获取文本位置
</a-button>
const getTextHighLight= () => {
const iframe = document.getElementById('myIframe')
iframe.contentWindow.postMessage('经依法审查查明:', '*')
iframe.contentWindow.addEventListener('message', (e) => {
iframe.contentWindow.PDFViewerApplication.findBar.findField.value = e.data
iframe.contentWindow.PDFViewerApplication.findBar.highlightAll.checked = true iframe.contentWindow.PDFViewerApplication.findBar.dispatchEvent('highlightallchange')
}, false)
iframe.contentWindow.PDFViewerApplication.pagesCount)
}
4、在pdfjs-3.7.107-dist版本中,给pdf.js传参的处理
①在全局同样的位置添加三个参数:pageRangeStart, pageRangeEnd, this.isPageRange,在class PDFFindController中增加
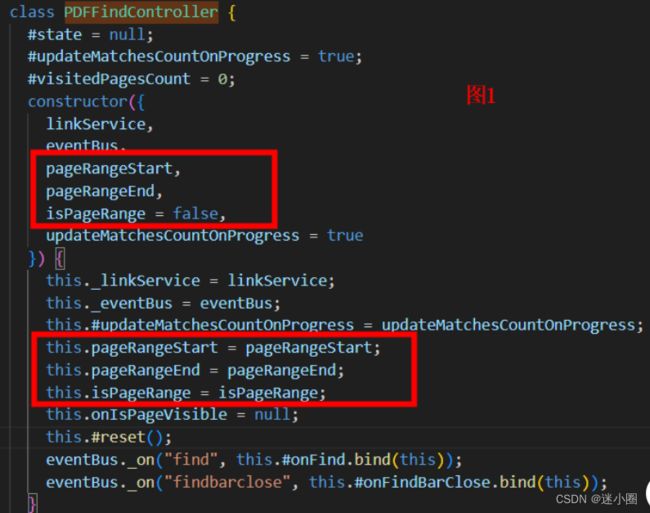
在其它地方要获取到pageRangeStart, pageRangeEnd的值
②、在setInitialView是从外部iframe中获取参数
var c_url=window.location.href;
if(c_url.indexOf("&")&&c_url.indexOf("=")){
var c_urlArray={}
var c_val=c_url.split('?')[1];
var c_valArray=c_val.split('&');
for(let i=0;i<c_valArray.length;i++){
let c_key=c_valArray[i].split('=')[0];
let c_value=c_valArray[i].split('=')[1];
c_urlArray[c_key]=c_value;
}
if(c_urlArray['pageRangeStart']){
this.pageRangeStart = Number(c_urlArray['pageRangeStart'])
PDFViewerApplication.findController.pageRangeStart = this.pageRangeStart
}
if(c_urlArray['pageRangeEnd']){
this.pageRangeEnd = Number(c_urlArray['pageRangeEnd'])
PDFViewerApplication.findController.pageRangeEnd = this.pageRangeEnd
}
if(this.pageRangeStart!==0 && this.pageRangeEnd!==0){
PDFViewerApplication.findController.isPageRange = true
}
}
关于页码索引的几个值
_offset:{
matchIdx: null
pageIdx: 29
wrapped: false
}
_resumePageIdx: null ,基本都是null
_selected: {
matchIdx: -1
pageIdx: -1
}
_pageMatches : 页面所有匹配搜索的内容,是个数组
this._linkService:{
page: 50
pagesCount: 66
rotation: 0
}
_linkService 的page控制页码显示 影响 _offset
【currentPage.value = pdfFrame.PDFViewerApplication.page】
5、在pdfjs-3.7.107-dist版本中,修改convertToRegExpString方法,更换匹配方法(可匹配到带有空格的文档)
原码
#convertToRegExpString(query, hasDiacritics) {
const {
matchDiacritics
} = this.#state;
let isUnicode = false;
query = query.replaceAll(SPECIAL_CHARS_REG_EXP, (match, p1, p2, p3, p4, p5) => {
if (p1) {
return `[ ]*\\${p1}[ ]*`;
}
if (p2) {
return `[ ]*${p2}[ ]*`;
}
if (p3) {
return "[ ]+";
}
if (matchDiacritics) {
return p4 || p5;
}
if (p4) {
return DIACRITICS_EXCEPTION.has(p4.charCodeAt(0)) ? p4 : "";
}
if (hasDiacritics) {
isUnicode = true;
return `${p5}\\p{M}*`;
}
return p5;
});
const trailingSpaces = "[ ]*";
if (query.endsWith(trailingSpaces)) {
query = query.slice(0, query.length - trailingSpaces.length);
}
if (matchDiacritics) {
if (hasDiacritics) {
DIACRITICS_EXCEPTION_STR ||= String.fromCharCode(...DIACRITICS_EXCEPTION);
isUnicode = true;
query = `${query}(?=[${DIACRITICS_EXCEPTION_STR}]|[^\\p{M}]|$)`;
}
}
return [isUnicode, query];
}
修改后:
#convertToRegExpStringWL(query, hasDiacritics) {
const {
matchDiacritics
} = this.#state;
let isUnicode = false;
// const SPECIAL_CHARS_REG_EXP = /([.*+?^${}()|[\]\\])|(\p{P})|(\s+)|(\p{M})|(\p{L})/gu;
const SPECIAL_CHARS_REG_EXP_wl = /([.*+?^${}()|[\]\\])|(\p{P})|(\s+)|(\p{M})|(\p{L})/gu;
// 匹配文本中的特殊字符、标点符号、空格、语言符号和字母的。
// [.*+?^${}()|[\]\\]匹配特殊字符 其中,.表示匹配任意字符,*表示匹配前面的字符0次或多次,+表示匹配前面的字符1次或多次,?表示匹配前面的字符0次或1次,^表示匹配字符串的开头,$表示匹配字符串的结尾,{和}表示匹配前面的字符指定的次数,()表示分组,|表示或,[和]表示字符集,\表示转义字符。
//其中,\p{P}表示标点符号,\s表示空格,\p{M}表示语言符号,\p{L}表示字母。
query = query.replaceAll(SPECIAL_CHARS_REG_EXP_wl,(match, p1, p2, p3, p4, p5)=>{
// return `${match}\\s*`
if (p1) {
return `[ ]*\\${p1}[ ]*`;
}
if (p2) {
return `[ ]*${p2}[ ]*`;
}
if (p3) {
return "[ ]+";
}
if (matchDiacritics) {
return p4 || p5;
}
if (p4) {
return DIACRITICS_EXCEPTION.has(p4.charCodeAt(0)) ? p4 : "";
}
if (hasDiacritics) {
isUnicode = true;
return `${p5}\\p{M}*`;
}
return `${match}\\s*`;
})
const trailingSpaces = "[ ]*";
if (query.endsWith(trailingSpaces)) {
query = query.slice(0, query.length - trailingSpaces.length);
}
if (matchDiacritics) {
if (hasDiacritics) {
DIACRITICS_EXCEPTION_STR ||= String.fromCharCode(...DIACRITICS_EXCEPTION);
isUnicode = true;
query = `${query}(?=[${DIACRITICS_EXCEPTION_STR}]|[^\\p{M}]|$)`;
}
}
return [isUnicode, query];
}
6、如果后端返回的是流的形式,就用此方法转一下
<iframe id="myIframe" width="100%" height="100%" :src="`${serverUrl}?file=${pdfUrl}`" frameborder="0" />
pdfFile('44.pdf').then((res) => {
pdfUrl.value = getObjectURL(res)
})
/**
* 流转成url
*/
getObjectURL(file) {
let url = null
if (window.createObjectURL !== undefined) { // basic
url = window.createObjectURL(file)
} else if (window.webkitURL !== undefined) { // webkit or chrome
try {
url = window.webkitURL.createObjectURL(file)
} catch (error) {
console.log(error)
}
} else if (window.URL !== undefined) { // mozilla(firefox)
try {
url = window.URL.createObjectURL(file)
} catch (error) {
console.log(error)
}
}
return url
},
此方法可以将接口返回的流的形式转成,可用的本地的pdf文件的链接地址
7、 下载
fileDownload() {
if (this.src) {
var tempLink = document.createElement('a')
tempLink.style.display = 'none'
tempLink.href = this.PDF // 解析好的地址
tempLink.setAttribute('download', this.fileName)
if (typeof tempLink.download === 'undefined') {
tempLink.setAttribute('target', '_blank')
}
document.body.appendChild(tempLink)
tempLink.click()
document.body.removeChild(tempLink)
window.URL.revokeObjectURL(this.PDF)
} else {
this.$message.error('请选择需要导出的算法')
}
},
四、原理
首先底图是一个Canvas,内容和PDF一样(通过下面介绍的 page.render 方法可以得到),底图之上是一个textLayer,这一层就是通过 page.getTextContent() 得到了字体的位置和样式,再覆盖在 Canvas 上。
//Add this piece of code to webViewerInitialized function in viewer.js
if ('search' in params) {
searchPDF(params['search']);
}
//New function in viewer.js
function searchPDF(td_text) {
PDFViewerApplication.findBar.open();
PDFViewerApplication.findBar.findField.value = td_text;
PDFViewerApplication.findBar.caseSensitive.checked = true;
PDFViewerApplication.findBar.highlightAll.checked = true;
PDFViewerApplication.findBar.findNextButton.click();
PDFViewerApplication.findBar.close();
}
#extractText()方法:
这个方法的功能为将pdf文件的所有文本提取出来,按页保存在PDFFindController._pageContents[]中;这个方法提取出来的文本会用于之后的查找。
#nextMatch()方法
_nextMatch() {
const previous = this._state.findPrevious; // findPrevious是点击寻找区的按钮发布的事件的参数,只有点击左右箭头时才有这个参数,分别是true和false
const currentPageIndex = this._linkService.page - 1; // 当前查找所在页码-1
const numPages = this._linkService.pagesCount; // pdf页数
this._highlightMatches = true;
if (this._dirtyMatch) { // this._dirtyMatch应该是不区分大小写查找 这下面设置的都是this._reset()方法中定义的变量
this._dirtyMatch = false;
this._selected.pageIdx = this._selected.matchIdx = -1; // this._selected并无实际含义
this._offset.pageIdx = currentPageIndex; // this._offset并无实际含义
this._offset.matchIdx = null;
this._offset.wrapped = false;
this._resumePageIdx = null;
this._pageMatches.length = 0;
this._pageMatchesLength.length = 0;
this._matchesCountTotal = 0;
this._updateAllPages(); // 发布名为updatetextlayermatches的事件,与_onUpdateTextLayerMatches绑定,其调用 _updateMatches()函数,位于11521行
for (let i = 0; i < numPages; i++) { // _pendingFindMatches这个变量只在这个循环内被调用,别处没有调用
if (this._pendingFindMatches[i] === true) {
continue;
}
this._pendingFindMatches[i] = true;
this._extractTextPromises[i].then(pageIdx => { // 相当于将padeIdx传入箭头右边花括号内的函数中 _extractTextPromises内的元素都是Promise类实例
delete this._pendingFindMatches[pageIdx]; // 这里传入的参数pageIdx为_extractTextPromises[i]异步操作的结果
this._calculateMatch(pageIdx);
});
}
}
注:整理了实际开发过程中遇到并解决的问题
五、pdf.js历史版本的下载
我使用的pdf.js版本:pdfjs-3.7.107-dist
2.5.207是主流版本,因为该版本对IE的兼容性很好,不少文章都提到过该版本下能完美兼容IE
pdfjs es5版本 (pdfjs-2.5.207-es5-dist)【请看准一定要包括es5版本的哦,按照上述使用方法,即可完美兼容各大浏览器】
2.4.456 版本开始就不支持旧版本的浏览器了,只支持谷歌76+ 和苹果浏览器13+,还是要好好看文档
当前项目pdf的版本是 “pdfjs-dist”: “2.13.216”
另外两个项目的pdf版本 “pdfjs-dist”: “2.0.943”
只有"pdfjs-dist": "2.13.216"这个版本会挂了,凉凉, “pdfjs-dist”: "2.0.943"这个版本是2018年10月份发布的,这个版本没有问题,
pdfjs-1.9.426下载地址
百度网盘提取:https://pan.baidu.com/s/1SRdUUF6osHVAqLUhtjediQ?pwd=w361
w361
pdfjs-3.7.107下载地址
https://pan.baidu.com/s/1pSWh04jGJJ63eMnJD-BjSQ?pwd=w361
w361
下载方式
https://github.com/mozilla/pdf.js/releases/tag/v2.5.207
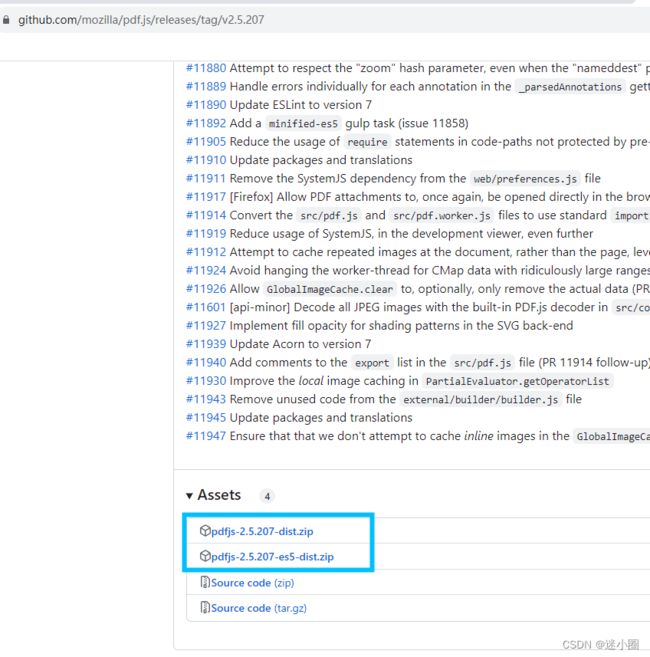
1.9、2.4、2.5、2.5-es是黑边-------都可以
版本
2.6.347版本打不开
2.6.347-es版本是白边

2.11.338的legacy-----是白边,两个浏览器都可以,但是检察院专用浏览器pdf文件乱码
2.12.313的legacy-----是白边,两个浏览器都可以,但是检察院专用浏览器pdf文件乱码
2.13.216的legacy-----两个浏览器都打不开
2.14.305的legacy-----两个浏览器都打不开2.16的legacy-----两个浏览器都打不开
3.7.107的legacy-----两个浏览器都打不开
打不开是这个样子

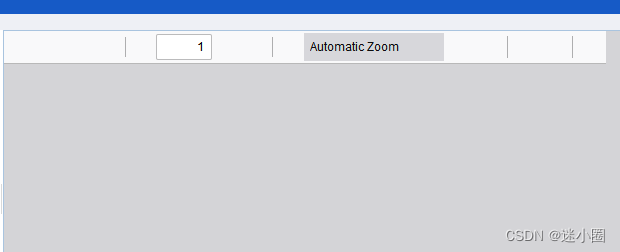
2.8.335版本----打不开pdf,兼容性
2.8.335的legacy版本-----pdf乱码
2.7.570-es版本—pdf有些文件的显示会乱码