HIVE笔记
HIVE
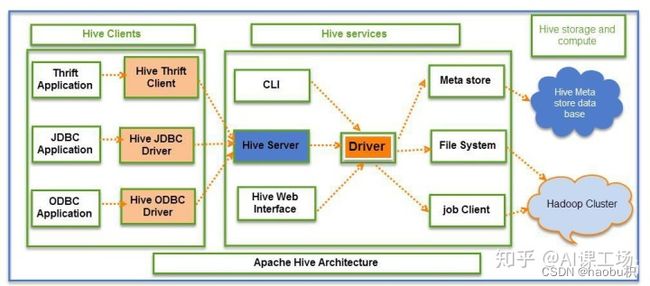
HIVE工作流程
Hive架构设计包括三个部分
Hive Clients
Hive客户端,它为不同类型的应用程序提供不同的驱动,使得Hive可以通过类似Java、Python等语言连接,同时也提供了JDBC和ODBC驱动。
Hive Services
Hive服务端,客户端必须通过服务端与Hive交互,主要包括:
- 用户接口组件(CLI,HiveServer,HWI),它们分别以命令行、与web的形式连接Hive。
- Driver组件,该组件包含编译器、优化器和执行引擎,它的作用是将hiveSQL语句进行解析、编译优化、生成执行计划,然后调用底层MR计算框架。
- Metastore组件,元数据服务组件。Hive数据分为两个部分,一部分真实数据保存在HDFS中,另一部分是真实数据的元数据,一般保存在MySQL中,元数据保存了真实数据的很多信息,是对真实数据的描述。
Hive Storage and Computing
包括元数据存储数据库和Hadoop集群。Hive元数据存储在RDBMS(关系型数据库)中,Hive数据存储在HDFS中,查询由MR完成。
部署模式
- 嵌入式模式: Metastore 和数据库( Derby )两个进程嵌入到 Driver 中,当 Driver 启动时会同时运行这两个进程,一般用于测试.
- 本地模式: Driver 和 Metastore 运行在本地,而数据库(比如 MYSQL )启动在个共享节点上。
- 远程模式: Metastore 运行在单独一个节点上,被其他所有服务共享。
工作流程
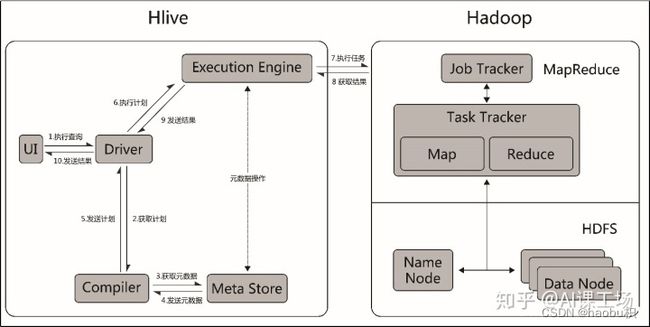
- 执行查询。Hive接口,如命令行或Web UI发送查询Driver驱动程序(任何数据库驱动程序,如JDBC)来执行
- 获取计划。在Driver的帮助下查询编译器,分析查询,检查语法和查询的要求
- 获取元数据。编译器发送元数据请求到Metastore(任何数据库)
- Metastore发送元数据,响应编译器
- 编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。
- Driver发送执行计划到执行引擎
- 在内部,执行作业的是一个MapReduce工作。执行引擎发送作业给JobTracker,TaskTracker分配作业到Namenode。在Datanode执行Mapreduce工作。在执行时,执行引擎可以通过MetaStore执行元数据操作。(虚线部分)
- 执行引擎收到来自数据节点的结果
- 执行引擎发送这些结果给驱动程序。
- 驱动程序将结果发送给HIve接口。
HIVE转SQL语句
hive.fetch.task.conversion参数
<property>
<name>hive.fetch.task.conversionname>
<value>morevalue>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
description>
property>
- 当设置为none时,所有任务转化为MR任务;
- 当设置为minimal时,全局查找SELECT *、在分区列上的FILTER(where…)、LIMIT才使用Fetch,其他为MR任务;
- 当设置为more时,不限定列,简单的查找SELECT、FILTER、LIMIT都使用Fetch,其他为MR任务。
默认情况下,使用参数more,本文也介绍参数为more时的SQL转化。
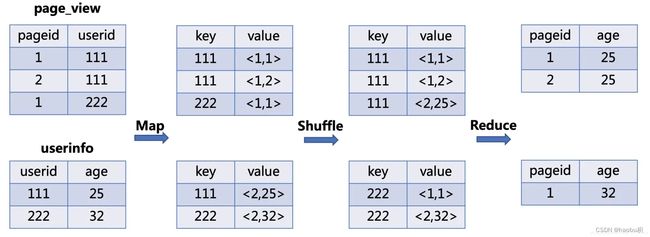
JOIN
Map:生成键值对,以JOIN ON条件中的列作为Key,以JOIN之后所关心的列作为Value,在Value中还会包含表的 Tag 信息,用于标明此Value对应于哪个表
Shuffle:根据Key的值进行 Hash,按照Hash值将键值对发送至不同的Reducer中
Reduce:Reducer通过 Tag 来识别不同的表中的数据,根据Key值进行Join操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-67JUqCLf-1681778635753)(数仓面经.
在Hive命令行工具中运行上述代码,结果如下,注意到reducer为0,原因是示例的表很小,Hive默认将其优化为mapjoin任务。
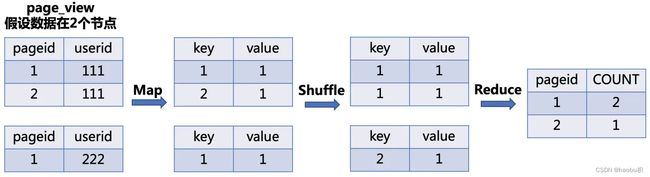
GROUP BY
Map:生成键值对,以GROUP BY条件中的列作为Key,以聚集函数的结果作为Value
Shuffle:根据Key的值进行 Hash,按照Hash值将键值对发送至不同的Reducer中
Reduce:根据SELECT子句的列以及聚集函数进行Reduce
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z1rf0HYE-1681778635753)(数仓面经.assets/v2-0bdcb155db717e2dcb50d9cbc1691493_1440w.webp)]
DISTINCT
相当于没有聚集函数的GROUP BY,操作相同,只是键值对中的value可为空。
SELECT DISTINCT pageid FROM page_view;
Join对应的MR
- Hive有两种Join的方式,一种是Common Join,一种是Map Join。
- **Common Join:**是在Reduce阶段完成Join操作的,它的流程如下:
- Map阶段:读取源表的数据,以Join on条件中的列作为key,以Join之后所关心的列作为value。同时在value中还会包含表的Tag信息,用于标明此value对应哪个表。
- Shuffle阶段:根据key的值进行hash,并将key/value按照hash值推送至不同的Reduce中,这样确保两个表中相同的key位于同一个Reduce中。
- Reduce阶段:根据key的值完成Join操作,期间通过Tag来识别不同表中的数据。根据不同的Join类型(如Inner Join, Left Outer Join等),将key值相等的数据中,来自不同Tag的value值进行配对或过滤。
- **Map Join:**是在Map阶段完成Join操作的,它适用于一个很小的表和一个大表进行Join的场景。它的流程如下:
- Local Task:扫描小表的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中,供Map Task使用。
- Map Task:扫描大表的数据,在Map阶段,根据大表的每一条记录去和DistributeCache中小表对应的HashTable关联,并直接输出结果。由于没有Reduce阶段,所以有多少个Map Task,就有多少个结果文件。
2一张小表Join一张大表 在MR上怎么JOIN
- Map Join需要将小表加载到内存中,所以要注意小表的大小,不要超过参数hive.mapjoin.smalltable.filesize的值,默认是25M。
- Map Join可以通过两种方式使用,一种是手动使用/*+ MAPJOIN (table) */提示来指定哪个表作为小表,另一种是开启参数hive.auto.convert.join=true来让Hive自动判断并转换为Map Join。
3 大表join大表怎么解决
- 使用分桶表(Bucketed Table)来划分大表的数据,使得相同的key分配到同一个桶中,然后在Map端进行join操作,避免Reduce端的shuffle和排序。使用clustered by (column) into n buckets来指定按照哪个列进行分桶。
- 使用随机前缀或者扩容RDD来解决数据倾斜,即在join的key前面加上一个随机数或者将key扩展成多个key,然后在join后再去掉随机数或者合并扩展的key,这样可以打散数据,使得数据更加均匀地分配到不同的Reduce中。
4 hive的四个分组函数的区别
- Sort By: 对每个分区内的数据进行排序,分区间的数据不保证有序。可以指定多个排序字段,也可以指定升序或降序。例如:select * from table sort by col1 asc, col2 desc;
- Order By: 对全局的数据进行排序,只有一个Reducer,效率低。可以指定多个排序字段,也可以指定升序或降序。例如:select * from table order by col1 asc, col2 desc;
- Distribute By: 对数据进行分区,类似于MapReduce中的Partitioner,可以指定分区函数或字段。结合Sort By使用,可以实现分区内有序,分区间无序。例如:select * from table distribute by col1 sort by col2;
- Cluster By: 当Distribute By和Sort By字段相同时,可以使用Cluster By方式。Cluster By除了具有Distribute By的功能外还兼具Sort By的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。例如:select * from table cluster by col1;
5 hive sql指令转换执行的过程
- 词法、语法解析:这个阶段是用一个工具叫Antlr来完成的,它可以根据Hive SQL的语法规则,将指令分解成不同的词汇和符号,并检查是否有语法错误。如果没有错误,它会生成一个抽象语法树(AST),这是一个用节点和边表示指令结构和逻辑的树形图。
- 语义解析:这个阶段是遍历AST,抽象出查询的基本组成单元,叫做查询块(Query Block)。一个查询块就是一个子查询,它包括输入源、计算过程和输出三个部分。查询块可以嵌套和连接,形成复杂的查询逻辑。
- 生成逻辑执行计划:这个阶段是将查询块翻译为执行操作树(Operator Tree),这是一种用不同的操作符表示数据处理流程的树形图。基本的操作符有表扫描、选择、过滤、连接、分组等,每个操作符都有输入和输出,可以串联或并联。操作树可以分为Map端和Reduce端两部分,对应MapReduce任务的两个阶段。
- 优化逻辑执行计划:这个阶段是对操作树进行变换和合并,以减少MapReduce任务的数量和数据传输量。主要有列过滤、行过滤、谓词下推、Join方式选择、分组优化等策略。
- 生成物理执行计划:这个阶段是将操作树翻译为MapReduce任务树,这是一种用不同的MapReduce任务表示数据处理流程的有向无环图(DAG)。每个MapReduce任务包括一个或多个Mapper和一个或多个Reducer,以及相应的输入输出路径。任务之间可以有依赖关系,也可以并行执行。
- 优化物理执行计划:这个阶段是对MapReduce任务树进行变换和调整,以提高执行效率和资源利用率。主要有任务合并、任务拆分、任务重用、任务排序等策略。
6 谓词下推
Hive中的谓词下推是一种优化技术,它可以在不影响查询结果的情况下,尽量将过滤条件提前执行,减少数据的扫描和传输量,提高查询性能。谓词是指返回布尔值的表达式,例如where子句或join条件中的过滤条件。下推是指将谓词从上层操作符移动到下层操作符,例如从join操作符移动到tablescan操作符。Hive中默认开启了谓词下推,也可以通过设置hive.optimize.ppd为true或false来开启或关闭谓词下推。
7 常用窗口函数
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
LAG(col,n):往前第n行数据
LEAD(col,n):往后第n行数据
8 相同的sql在hivesql与sparksql的实现中,为什么spark比hadoop快
- HiveSQL的底层执行引擎是MapReduce,它是基于磁盘的计算模型,需要频繁地进行磁盘IO操作,导致性能较低。HiveSQL更适合于批量处理、离线分析、数据挖掘等场景。
- SparkSQL的底层执行引擎是Spark,它是基于内存的计算模型,可以利用内存缓存数据,减少磁盘IO操作,提高性能。SparkSQL更适合于机器学习、大数据分析、数据科学等场景。
- HiveSQL有元数据管理服务,可以存储表和分区的元数据信息,而SparkSQL没有元数据管理服务,需要自己维护。
- HiveSQL支持用户自定义函数(UDF)和用户自定义聚合函数(UDAF),而SparkSQL不支持UDAF,但支持用户自定义窗口函数(UDWF)。
- HiveSQL支持多种存储格式,例如文本文件、序列化文件、ORC文件等,而SparkSQL主要支持Parquet和ORC两种列式存储格式。
9 hive的内表和外表的区别,hive的元数据存在哪?
Hive是一个基于Hadoop的数据仓库工具,它可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。Hive中的表分为内部表和外部表两种类型。
内部表(Managed Table):内部表也称为托管表,是由Hive自己管理的表,它们的元数据和数据都存储在Hive的Warehouse目录下。当我们删除内部表时,Hive会自动删除元数据和数据。内部表是默认的表类型,如果不指定类型,则创建的就是内部表。
外部表(External Table):外部表也称为非托管表,它们的元数据存储在Hive中,但是数据存储在其他地方。当我们删除外部表时,只会删除元数据,而不会删除数据。外部表可以用来引用已经存在于HDFS或者本地文件系统上的数据。
因此,内部表和外部表的区别在于元数据和数据的存储位置不同。内部表由Hive自己管理,元数据和数据都存储在Hive的Warehouse目录下;而外部表的元数据存储在Hive中,但是数据存储在其他地方。
10 spark UDF与 hive UDF区别
- Spark UDF是Spark SQL提供的一种自定义函数,它可以在Spark SQL的DSL编程和SQL编程中使用,它可以接受0到22个参数,返回一个值,它可以用Python, Java, Scala或R语言实现。
- Hive UDF是Hive提供的一种自定义函数,它只能在Hive SQL中使用,它可以接受任意个参数,返回一个值,它只能用Java语言实现。
- Spark UDF和Hive UDF的兼容性也有所不同,Spark SQL支持集成Hive UDF,但是Hive SQL不支持集成Spark UDF。因此,在Spark SQL中可以使用Hive UDF,但是在Hive SQL中不能使用Spark UDF。
11 hdfs数据导入hive,数据表创建
Hive支持从本地文件系统或者HDFS中导入数据到Hive表中,使用load data命令,语法如下:
- load data [local] inpath ‘filepath’ [overwrite] into table tablename [partition (partcol1=val1, partcol2=val2 …)];
- local表示从本地文件系统导入数据,如果不加则表示从HDFS导入数据。
- overwrite表示覆盖表中已有的数据,如果不加则表示追加数据。
- partition表示指定分区表的分区值,如果不加则表示导入到默认分区
Hive支持创建两种类型的表:内部表(managed table)和外部表(external table)
create [external] table tablename (col_name data_type [comment col_comment], …) [comment table_comment] [partitioned by (col_name data_type [comment col_comment], …)] [row format row_format] [stored as file_format] [location hdfs_path];
external表示创建外部表,如果不加则表示创建内部表。
comment表示添加注释信息,可以对列或者表进行注释。
partitioned by表示创建分区表,指定分区字段的名称和类型。
row format表示指定行的格式,例如分隔符、行终止符等。
stored as表示指定文件的格式,例如textfile、orc、parquet等。
location表示指定表的存储位置,如果不指定则使用默认的位置。
Hive优化
1 Fetch抓取(可避免MapReduce)
Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。
在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
例子
1)把hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序。
hive (default)> set hive.fetch.task.conversion=none;
hive (default)> select * from score;
hive (default)> select s_score from score;
hive (default)> select s_score from score limit 3;
2)把hive.fetch.task.conversion设置成more,然后执行查询语句,如下查询方式都不会执行mapreduce程序。
hive (default)> set hive.fetch.task.conversion=more;
hive (default)> select * from score;
hive (default)> select s_score from score;
hive (default)> select s_score from score limit 3;
2 本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务时消耗可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
1)开启本地模式,并执行查询语句
hive (default)> set hive.exec.mode.local.auto=true;
hive (default)> select * from score cluster by s_id;
18 rows selected (1.568 seconds)
2)关闭本地模式,并执行查询语句
hive (default)> set hive.exec.mode.local.auto=false;
hive (default)> select * from score cluster by s_id;
18 rows selected (11.865 seconds)
分区表
由于hive在查询时会做全表扫描,有些情况下我们只需要查询部分数据,为了避免全表扫描消耗资源和性能,我们可以实现表分区使之扫描部分表。
在hive中分区字段是一个伪字段,并不实际存储数据,但可以作为条件用于查询。表分区就是会在表目录下面针对不同的分区创建一个子目录,如果有二级分区,那么会在一级子目录下面继续创建子目录。
hive中的分区字段是表外字段,mysql中的分区字段是表内字段。
进入目标库中
hive> use test_data;
静态分区
一级分区应用:
建表
hive> create table if not exists partition1(
> id int,
> name string,
> age int
> )
> partitioned by (testdate string)
> row format delimited
> fields terminated by '\t'
> lines terminated by '\n'; #默认就是以\n作为换行符的,所以可以省略不写
创建数据文件
[root@hadoop01 test_data]# pwd
/usr/local/wyh/test_data
[root@hadoop01 test_data]# cat user_partition1.txt
1 user1 1
2 user2 2
3 user3 2
4 user4 1
5 user5 1
6 user6 1
7 user7 2
8 user8 1
9 user9 2
加载数据
由于在建表时定义了分区字段,所以在加载数据时就要指定当前数据文件要加载到哪个分区中。
这里我们先将数据放在testdate='2022-04-28’这个分区下。(分区不存在时,会自动创建该分区)
hive> load data local inpath '/usr/local/wyh/test_data/user_partition1.txt' into table partition1 partition(testdate='2022-04-28');
查看hdfs目录树
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zAljjBcZ-1683688026976)(HIVE.assets/b98352a58a2d40a8afee3612a1dc6f24.png)]
查看数据
查看数据时就会发现最后面多了一列分区字段:
hive> select * from partition1;
OK
1 user1 1 2022-04-28
2 user2 2 2022-04-28
3 user3 2 2022-04-28
4 user4 1 2022-04-28
5 user5 1 2022-04-28
6 user6 1 2022-04-28
7 user7 2 2022-04-28
8 user8 1 2022-04-28
9 user9 2 2022-04-28
加载数据放入第二个分区中。
hive> load data local inpath '/usr/local/wyh/test_data/user_partition1.txt' into table partition1 partition(testdate='2022-04-27');
查看hdfs目录树
此时表目录下面多了一个分区目录:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HtI82sy9-1683688026977)(HIVE.assets/80f5e4bdbd1d4a7eaffffc209c907fd5.png)]
查看数据
hive> select * from partition1;
OK
1 user1 1 2022-04-27
2 user2 2 2022-04-27
3 user3 2 2022-04-27
4 user4 1 2022-04-27
5 user5 1 2022-04-27
6 user6 1 2022-04-27
7 user7 2 2022-04-27
8 user8 1 2022-04-27
9 user9 2 2022-04-27
1 user1 1 2022-04-28
2 user2 2 2022-04-28
3 user3 2 2022-04-28
4 user4 1 2022-04-28
5 user5 1 2022-04-28
6 user6 1 2022-04-28
7 user7 2 2022-04-28
8 user8 1 2022-04-28
9 user9 2 2022-04-28
使用分区字段作为查询条件
hive> select * from partition1 where testdate='2022-04-27';
OK
1 user1 1 2022-04-27
2 user2 2 2022-04-27
3 user3 2 2022-04-27
4 user4 1 2022-04-27
5 user5 1 2022-04-27
6 user6 1 2022-04-27
7 user7 2 2022-04-27
8 user8 1 2022-04-27
9 user9 2 2022-04-27
这样在查询时,就会只扫描当前分区的目录。
二级分区应用:
建表
hive> create table if not exists partition2(
> id int,
> name string,
> age int
> )
> partitioned by (year string,month string)
> row format delimited
> fields terminated by '\t';
加载数据
在二级分区应用中,需要指定两个字段,第一个分区字段会生成一级分区目录,第二个字段会生成一级分区目录下面的二级分区目录。
hive> load data local inpath '/usr/local/wyh/test_data/user_partition2.txt' into table partition2 partition(year='2022',month='03');
查看hdfs目录树
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xs9vogS3-1683688026977)(HIVE.assets/a1ddf9a6849041588261fa40e7b688b5.png)]
查看数据
查询数据时后面会多了两列,分别为分区的两个字段:
hive> select * from partition2;
OK
1 user1 1 2022 03
2 user2 2 2022 03
3 user3 2 2022 03
4 user4 1 2022 03
5 user5 1 2022 03
6 user6 1 2022 03
7 user7 2 2022 03
8 user8 1 2022 03
9 user9 2 2022 03
加载第二个分区的数据
hive> load data local inpath '/usr/local/wyh/test_data/user_partition2.txt' into table partition2 partition(year='2022',month='02');
查看数据
hive> select * from partition2;
OK
1 user1 1 2022 02
2 user2 2 2022 02
3 user3 2 2022 02
4 user4 1 2022 02
5 user5 1 2022 02
6 user6 1 2022 02
7 user7 2 2022 02
8 user8 1 2022 02
9 user9 2 2022 02
1 user1 1 2022 03
2 user2 2 2022 03
3 user3 2 2022 03
4 user4 1 2022 03
5 user5 1 2022 03
6 user6 1 2022 03
7 user7 2 2022 03
8 user8 1 2022 03
9 user9 2 2022 03
加载第三个分区的数据
hive> load data local inpath '/usr/local/wyh/test_data/user_partition2.txt' into table partition2 partition(year='2021',month='04');
查看数据
hive> select * from partition2;
OK
1 user1 1 2021 04
2 user2 2 2021 04
3 user3 2 2021 04
4 user4 1 2021 04
5 user5 1 2021 04
6 user6 1 2021 04
7 user7 2 2021 04
8 user8 1 2021 04
9 user9 2 2021 04
1 user1 1 2022 02
2 user2 2 2022 02
3 user3 2 2022 02
4 user4 1 2022 02
5 user5 1 2022 02
6 user6 1 2022 02
7 user7 2 2022 02
8 user8 1 2022 02
9 user9 2 2022 02
1 user1 1 2022 03
2 user2 2 2022 03
3 user3 2 2022 03
4 user4 1 2022 03
5 user5 1 2022 03
6 user6 1 2022 03
7 user7 2 2022 03
8 user8 1 2022 03
9 user9 2 2022 03
查看表分区
hive> show partitions partition2;
OK
year=2021/month=04
year=2022/month=02
year=2022/month=03
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gth9GMzS-1683688026978)(HIVE.assets/7d9935e2bf0d4a228bdb7539526dc404.png)]
以上两个案例都是通过load数据文件进行加载数据的,属于静态分区。
动态分区
创建动态分区表
hive> create table dynamic_partition1(
> id int,
> name string,
> gender string,
> age int,
> academy string
> )
> partitioned by (test_date string)
> row format delimited fields terminated by ','
> ;
创建临时表
实现动态分区时,需要通过创建临时表来完成,先创建一个与上表结构相同的临时表,且将分区字段加入表结构中,然后将数据先加载至临时表,再将临时表数据导入目标表。
hive> create table tmp_dynamic_partition1(
> id int,
> name string,
> gender string,
> age int,
> academy string,
> test_date string
> )
> row format delimited fields terminated by ','
> ;
#注意这里没有分区字段,原表中的分区字段在临时表中要放在实际表的字段中。
创建数据文件
[root@hadoop01 test_data]# pwd
/usr/local/wyh/test_data
[root@hadoop01 test_data]# cat dynamic_student.txt
1801,Tom,male,20,CS,2018-8-23
1802,Lily,female,18,MA,2019-7-14
1803,Bob,male,19,IS,2017-8-29
1804,Alice,female,21,MA,2017-9-16
1805,Sam,male,19,IS,2018-8-23
将数据加载至临时表
hive> load data local inpath '/usr/local/wyh/test_data/dynamic_student.txt' into table tmp_dynamic_partition1;
查看数据
hive> select * from tmp_dynamic_partition1;
OK
1801 Tom male 20 CS 2018-8-23
1802 Lily female 18 MA 2019-7-14
1803 Bob male 19 IS 2017-8-29
1804 Alice female 21 MA 2017-9-16
1805 Sam male 19 IS 2018-8-23
将动态分区模式参数改为非严格模式
hive> set hive.exec.dynamic.partition.mode=nonstrict;
否则在动态分区导入数据时,会要求分区字段至少要有一个时静态值。
动态加载数据
将临时表中的数据动态加载至我们实际要用的目标表中。
hive> insert into dynamic_partition1 partition(test_date) select id,name,gender,age,academy,test_date from tmp_dynamic_partition1;
查询数据
hive> select * from dynamic_partition1;
OK
1803 Bob male 19 IS 2017-8-29
1804 Alice female 21 MA 2017-9-16
1801 Tom male 20 CS 2018-8-23
1805 Sam male 19 IS 2018-8-23
1802 Lily female 18 MA 2019-7-14
查看表分区
hive> show partitions dynamic_partition1;
OK
test_date=2017-8-29
test_date=2017-9-16
test_date=2018-8-23
test_date=2019-7-14
2018-8-23这个分区会存放两条数据。
混合分区:
混合分区与静态分区的步骤大致一致,也是需要创建临时表的,只不过在将临时表的数据加载至目标表时,分区字段有的是写死的,有的是根据字段值动态分区的。
创建目标表
hive> create table mixed_partition(
> id int,
> name string
> )
> partitioned by (year string,month string,day string)
> row format delimited fields terminated by ','
> ;
创建临时表
hive> create table tmp_mixed_partition(
> id int,
> name string,
> year string,
> month string,
> day string
> )
> row format delimited fields terminated by ','
> ;
#将目标表中的三个分区字段全部写在表的实际字段中
创建数据文件
[root@hadoop01 test_data]# pwd
/usr/local/wyh/test_data
[root@hadoop01 test_data]# cat mixed_partition.txt
1,Mike,2022,03,13
2,Peak,2022,04,21
3,Tina,2022,04,17
4,Keith,2022,03,13
将数据文件加载至临时表中
hive> load data local inpath '/usr/local/wyh/test_data/mixed_partition.txt' into table tmp_mixed_partition;
将临时表数据导入目标表中
hive> insert into mixed_partition partition (year='2022',month,day) select id,name,month,day from tmp_mixed_partition;
#这里的混合分区指的就是,year字段是我们手动指定的,属于静态分区,month和day是根据实际值进行动态分区的,所以这里就是混合分区。
#注意这里在从临时表中查询时select的字段里不包含year字段,因为我们已经在分区字段中写死了值,所以不需要查year字段。
查询数据
hive> select * from mixed_partition;
OK
1 Mike 2022 03 13
4 Keith 2022 03 13
3 Tina 2022 04 17
2 Peak 2022 04 21
查看表分区
hive> show partitions mixed_partition;
OK
year=2022/month=03/day=13
year=2022/month=04/day=17
year=2022/month=04/day=21
分桶表
分桶是将数据集分解成更容易管理的若干部分的一个技术,是比表或分区更为细粒度的数据范围划分。针对某一列进行桶的组织,对列值哈希,然后除以桶的个数求余,决定将该条记录存放到哪个桶中。
常用于:
- 获得更高的查询处理效率
- 抽样调查
分桶表与分区表区别
对于一张表或者分区,Hive还可以进一步组织成桶,也就是更为细粒度的数据范围划分。
- 分桶对数据的处理比分区更加细粒度化;
- 分桶和分区两者不干扰,可以把分区表进一步分桶;
- 分区针对的是数据的存储路径;分桶针对的是数据文件。
创建一个分桶表
我们创建一个简单的分桶表,只有两个字段(id,name),并且按照id进行分6个桶,sql如下:
create table test_buck(id int, name string)
clustered by(id)
into 6 buckets
row format delimited fields terminated by '\t';
使用desc formatted test_buck;查看test_buck表结构,数据较多,这里截取重要数据如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T6Ix2ubB-1683688026978)(HIVE.assets/20200330184514932.jpg)]
准备数据
准备一些编号和字符串并按照 "\t"分隔开,把这些数据放入/tools/目录下的test_buck.txt文件内,数据格式如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-60CJKnA1-1683688026979)(HIVE.assets/20200330184755729.jpg)]
向分桶表导入数据
错误导入示范(引出分桶的本质)
数据准备好之后,我们就可以向分桶表里导入数据里。这里我首先使用如下常规命令导入:
load data local inpath '/tools/test_buck.txt' into table test_buck;
报错
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0tzuAkqD-1683688026980)(HIVE.assets/2020033018485423.jpg)]
简单翻译一下,报错信息是这样说的:请把数据导入到一个中间表,并使用insert … select语句导入到分桶表里。如果你非要直接导入分桶表里,需要把hive.strict.checks.bucketing设置为false(关闭严格模式),然后你写sql就没有检查了。。。。。
哈哈,到这里,我们知道了分桶表应该怎么导入数据了,但是为啥直接导入就不行呢?下面让我们硬着头皮改为false,然后导入数据试一下。
然后我们打开50070查看hdfs上数据如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ETXgFk5m-1683688026980)(HIVE.assets/20200330185517339.jpg)]
只有一个桶
原因:桶的概念就是MapReduce的分区的概念,两者是完全一样的。也就是说物理上每个桶就是目录里的一个文件,一个作业产生的桶(输出文件)数量和reduce任务个数相同
所以这里我们导入一个文件,由于分区数等于文件数,只有一个分区,所以上面的操作并没有分桶。
正确导入示范
把hive严格模式打开,并把桶表清空:
set hive.strict.checks.bucketing = true;
truncate table test_buck;
下面我们使用之前严格模式下建议我们使用的分桶表导入数据方式,使用中间表来进行数据导入:
设置强制分桶为true,并设置reduce数量为分桶的数量个数。
set hive.enforce.bucketing = true;
创建一个临时表,并导入数据。
create table temp_buck(id int, name string)
row format delimited fields terminated by '\t';
load data local inpath '/tools/test_buck.txt' into table temp_buck;
使用insert select来间接把数据导入到分桶表。
insert into table test_buck select id, name from temp_buck;
在50070上查看分桶表的数据,已经分为了6个,桶表数据插入成功!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xF5LCzJw-1683688026980)(HIVE.assets/20200330185902518.jpg)]
查询分桶表里的数据。
select * from test_buck;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CkXXBsOF-1683688026981)(HIVE.assets/2020033019000254.jpg)]
通过观察规则和桶数的对应关系,我们可以得出如下分桶规则:
Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
分桶抽样
抽样语句语法解析:
tablesample(bucket x out of y)
必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
例如,table总共分了6份,当y=2时,抽取(6/2=)3个bucket的数据,当y=8时,抽取(6/8=)3/4个bucket的数据。
x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y。
例如,table总bucket数为6,tablesample(bucket 1 out of 2),表示总共抽取(6/2=)3个bucket的数据,抽取第1(x)个和第3(x+y)个和第5(x+y)个bucket的数据。
注意:x的值必须小于等于y的值
举例:
select * from test_buck tablesample(bucket 1 out of 3 on id);
结果如下图,可以发现,上面这条sql查出了第1个和第4个桶的数据:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v65xkqod-1683688026982)(HIVE.assets/2020033019013776.jpg)]
总结
分桶表的优点
- 查询效率更快,因为分桶为表加上了额外结构,链接相同列划分了桶的表,可以使用map-side join更加高效;
- 由于分桶规则保证了数据在不同桶的随机性,因此平时进行抽样调查时取样更加方便。
常用建表语句及含义
create table buck_table_name (id int,name string)
clustered by (id) sorted by (id asc) into 4 buckets
row format delimited fields terminated by '\t';
注意:CLUSTERED BY来指定划分桶所用列和划分桶的个数。
分桶规则:HIVE对key的hash值除bucket个数取余数,保证数据均匀随机分布在所有bucket里。
SORTED BY对桶中的一个或多个列另外排序
导入数据
先把数据导入中间表,然后使用insert select语句进行间接导入到分桶表,比如咱们实战的例子:
insert into table test_buck select id, name from temp_buck;
分桶表的实质及与分区表的区别
hive的桶其实就是MapReduce的分区的概念,两者完全相同。在物理上每个桶就是目录里的一个文件,一个作业产生的桶(输出文件)数量和reduce任务个数相同。
而分区代表了数据的仓库,也就是文件夹目录。每个文件夹下面可以放不同的数据文件。通过文件夹可以查询里面存放的文件。但文件夹本身和数据的内容毫无关系。
桶则是按照数据内容的某个值进行分桶,把一个大文件散列称为一个个小文件。这些小文件可以单独排序。如果另外一个表也按照同样的规则分成了一个个小文件。两个表join的时候,就不必要扫描整个表,只需要匹配相同分桶的数据即可,效率当然大大提升。
同样的道理,在对数据抽样的时候,也不需要扫描整个文件。只需要对每个分区按照相同规则抽取一部分数据即可。
3 分区表和分桶表
分区表和分桶表是hive中的两种优化方式。分区表是将表按照某个字段进行分区,可以加快查询速度,提高效率。例如,按照日期分区,可以快速查询某一天的数据。分桶表是将表按照某个字段进行分桶,可以提高查询效率,减少数据扫描量。例如,按照id进行分桶,可以快速查询某个id的数据。
对于分区表,我们可以使用以下方式进行优化:
- 选择合适的字段进行分区。例如,按照日期进行分区,可以快速查询某一天的数据。
- 控制每个分区的大小。如果一个分区太大,查询速度会变慢。如果一个分区太小,则会浪费存储空间。
- 使用动态分区插入数据。动态分区插入数据可以避免手动创建分区,提高效率。
对于分桶表,我们可以使用以下方式进行优化:
- 选择合适的字段进行分桶。例如,按照id进行分桶,可以快速查询某个id的数据。
- 控制每个桶的大小。如果一个桶太大,查询速度会变慢。如果一个桶太小,则会浪费存储空间。
- 使用动态分桶插入数据。动态分桶插入数据可以避免手动创建桶,提高效率。
以上是hive中优化分区表和分桶表的一些方法和技巧。
4 join优化
4.1 小表Join大表
-
将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用Group让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。
-
多个表关联时,最好分拆成小段,避免大sql(无法控制中间Job)
-
大表Join大表。空KEY过滤。有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。例如key对应的字段为空。
对比如下:
不过滤
INSERT OVERWRITE TABLE jointable SELECT a.* FROM nullidtable a JOIN ori b ON a.id = b.id; 结果: No rows affected (152.135 seconds)过滤
INSERT OVERWRITE TABLE jointable SELECT a.* FROM (SELECT * FROM nullidtable WHERE id IS NOT NULL ) a JOIN ori b ON a.id = b.id; 结果: No rows affected (141.585 seconds)
4.2 mapjoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
开启MapJoin参数设置:
(1)设置自动选择Mapjoin
set hive.auto.convert.join = true; 默认为true
(2)大表小表的阈值设置(默认25M以下认为是小表):
set hive.mapjoin.smalltable.filesize=25123456;
5 group by
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。
并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
开启Map端聚合参数设置
(1)是否在Map端进行聚合,默认为True
set hive.map.aggr = true;
(2)在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
(3)有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true;
当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
6 map数
1 通常情况下,作业会通过input的目录产生一个或者多个map任务。
主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小(目前为128M,可在hive中通过set dfs.block.size;命令查看到,该参数不能自定义修改);
2 举例:
a) 假设input目录下有1个文件a,大小为780M,那么hadoop会将该文件a分隔成7个块(6个128m的块和1个12m的块),从而产生7个map数。
b) 假设input目录下有3个文件a,b,c大小分别为10m,20m,150m,那么hadoop会分隔成4个块(10m,20m,128m,22m),从而产生4个map数。即,如果文件大于块大小(128m),那么会拆分,如果小于块大小,则把该文件当成一个块。
3 是不是map数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
4 是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
针对上面的问题3和4,我们需要采取两种方式来解决:即减少map数和增加map数;
5 如何增加map数
如果表a只有一个文件,大小为120M,但包含几千万的记录,如果用1个map去完成这个任务,肯定是比较耗时的,这种情况下,我们要考虑将这一个文件合理的拆分成多个,这样就可以用多个map任务去完成。
set mapreduce.job.reduces =10;
create table a_1 as
select * from a
distribute by rand(123);
这样会将a表的记录,随机的分散到包含10个文件的a_1表中,再用a_1代替上面sql中的a表,则会用10个map任务去完成。
7 reduce数
调整reduce个数方法一
(1)每个Reduce处理的数据量默认是256MB
hive.exec.reducers.bytes.per.reducer=256123456
(2)每个任务最大的reduce数,默认为1009
hive.exec.reducers.max=1009
调整reduce个数方法二
在hadoop的mapred-default.xml文件中修改
设置每个job的Reduce个数
set mapreduce.job.reduces = 15;
reduce个数并不是越多越好
1)过多的启动和初始化reduce也会消耗时间和资源;
2)另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
在设置reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的reduce数;使单个reduce任务处理数据量大小要合适;
8 jvm重用
JVM重用是Hadoop调优参数的内容,其对Hive的性能具有非常大的影响,特别是对于很难避免小文件的场景或task特别多的场景,这类场景大多数执行时间都很短。
JVM重用可以使得JVM实例在同一个job中重新使用N次。N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间,具体多少需要根据具体业务场景测试得出。
<property>
<name>mapreduce.job.jvm.numtasksname>
<value>10value>
<description>How many tasks to run per jvm. If set to -1, there is
no limit.
description>
property>
我们也可以在hive当中通过
set mapred.job.reuse.jvm.num.tasks=10;
这个设置来设置我们的jvm重用
缺点:
Hive启用JVM重用的缺点有:
可能会导致内存泄漏
可能会导致性能问题
可能会导致安全问题,因为JVM重用时,JVM中的所有对象都不会被清除,这可能会导致安全问题。
可能会导致应用程序崩溃
可能会导致内存溢出问题,
可能会导致线程安全问题,因为多个线程可以同时访问同一个JVM实例。
9 数据压缩
压缩可以节约磁盘的空间,基于文本的压缩率可达40%+; 压缩可以增加吞吐量和性能量(减小载入内存的数据量),但是在压缩和解压过程中会增加CPU的开销。所以针对IO密集型的jobs(非计算密集型)可以使用压缩的方式提高性能。 几种压缩算法:
| 压缩方式 | 压缩后大小 | 压缩速度 | 是否可以分割 |
|---|---|---|---|
| GZIP | 中 | 中 | 否 |
| BZIP2 | 小 | 慢 | 是 |
| LZO | 大 | 块 | 是 |
| Snappy | 大 | 快 | 是 |
存储格式
列式存储:列式存储是指使用列式数据库(column-oriented database)来存储数据的方式。列式数据库是一种非关系型数据库,它将数据按照列而不是行来组织和存储。每一列包含了同一个属性或字段的所有值,每一行则表示了一个实体或记录的所有属性或字段。列式数据库通常采用分布式架构,将数据分散到多个节点上,从而实现数据的并行处理和分析。
TextFile
Hive数据表的默认格式,存储方式:行存储。 可以使用Gzip压缩算法,但压缩后的文件不支持split 在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
Sequence Files
Hadoop中有些原生压缩文件的缺点之一就是不支持分割。支持分割的文件可以并行 的有多个mapper程序处理大数据文件,大多数文件不支持可分割是因为这些文件只能从头开始读。Sequence File是可分割的文件格式,支持Hadoop的block级压缩。 Hadoop API提供的一种二进制文件,以key-value的形式序列化到文件中。存储方式:行存储。 sequencefile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,RECORD是默认选项,通常BLOCK会带来较RECORD更好的压缩性能。 优势是文件和hadoop api中的MapFile是相互兼容的。
RCFile
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低 其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取 数据追加:RCFile不支持任意方式的数据写操作,仅提供一种追加接口,这是因为底层的 HDFS当前仅仅支持数据追加写文件尾部。 行组大小:行组变大有助于提高数据压缩的效率,但是可能会损害数据的读取性能,因为这样增加了 Lazy 解压性能的消耗。而且行组变大会占用更多的内存,这会影响并发执行的其他MR作业。
ORCFile
ORC是一种基于Hive开发的开源列式存储格式,它将数据按照条带(stripe)为单位进行划分和存储。每一个条带包含了若干条记录的所有属性或字段,并且可以对每个属性或字段进行不同的编码和压缩。ORC还提供了轻量级索引(light-weight index)来加速查询过滤。
Parquet
Parquet是一种基于Thrift开发的开源列式存储格式,它将数据按照块(block)为单位进行划分和存储。每一个块包含了若干条记录的所有属性或字段,并且可以对每个属性或字段进行不同的编码和压缩。Parquet还支持复杂的嵌套数据结构,如数组、列表、映射等。
自定义格式
可以自定义文件格式,用户可通过实现InputFormat和OutputFormat来自定义输入输出格式。
结论,一般选择orcfile/parquet + snappy 的方式
create table tablename (
xxx,string
xxx, bigint
)
ROW FORMAT DELTMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties("orc.compress" = "SNAPPY")
10 并行执行
当一个sql中有多个job时候,且这多个job之间没有依赖,则可以让顺序执行变为并行执行(一般为用到union all )
// 开启任务并行执行
set hive.exec.parallel=true;
// 同一个sql允许并行任务的最大线程数
set hive.exec.parallel.thread.number=8;
11 合并小文件
小文件的产生有三个地方,map输入,map输出,reduce输出,小文件过多也会影响hive的分析效率:
设置map输入的小文件合并
set mapred.max.split.size=256000000;
//一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
设置map输出和reduce输出进行合并的相关参数:
//设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
//设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
//设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=16000000
数据倾斜
解决方案
Hive数据倾斜是指在整个MapReduce计算框架中,由于数据分布不均匀,导致某些节点的负载过重,从而导致整个作业的运行时间变长。解决这个问题的方法有很多,以下是一些常见的方法:
-
开启负载均衡 如果发生数据倾斜,我们首先需要调整参数,进行负载均衡处理,这样 MapReduce 进程则会生成两个额外的 MR Job,这两个任务的主要操作如下: 第一步:MR Job 1:将原始数据按照 key 进行分组,生成多个小文件。 第二步:MR Job 2:将多个小文件合并成一个大文件。
-
使用随机数 在进行数据倾斜处理时,可以使用随机数来打散原始数据中的 key 值。这样可以使得每个 key 值被打散到不同的 reduce task 中去,从而达到负载均衡的目的。
-
使用自定义分区 自定义分区是一种常见的解决数据倾斜问题的方法。通过自定义分区,我们可以将原始数据中相同 key 的数据分配到不同的 reduce task 中去。这样可以避免某些 reduce task 负载过重的问题。
-
使用 Combiner Combiner 是 MapReduce 中一个非常重要的概念。它可以在 Map 端对输出结果进行合并操作,从而减少网络传输量和 I/O 操作次数。在处理大量数据时,使用 Combiner 可以有效地减少 MapReduce 作业的运行时间。
-
使用 BloomFilter BloomFilter 是一种高效的数据结构,它可以用来判断某个元素是否存在于一个集合中。在进行数据倾斜处理时,我们可以使用 BloomFilter 来判断某个 key 是否存在于原始数据中。如果不存在,则可以直接跳过该 key 的处理过程。
数据倾斜在 MapReduce 计算框架中经常发生。通俗理解,该现象指的是在整个计算过程中,大量相同的key被分配到了同一个任务上,造成“一个人累死、其他人闲死”的状况,这违背了分布式计算的初衷,使得整体的执行效率十分低下。
表现:任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
原因:某个reduce的数据输入量远远大于其他reduce数据的输入量
- key分布不均匀
- 业务数据本身的特性
- 建表时考虑不周
- 某些SQL语句本身就有数据倾斜
什么情况会出现数据倾斜
日常工作中数据倾斜主要发生在Reduce阶段,而很少发生在 Map阶段,其原因是Map端的数据倾斜一般是由于 HDFS 数据存储不均匀造成的(一般存储都是均匀分块存储,每个文件大小基本固定),而Reduce阶段的数据倾斜几乎都是因为数据研发工程师没有考虑到某种key值数据量偏多的情况而导致的。
Reduce阶段最容易出现数据倾斜的两个场景分别是Join和Count Distinct。有些博客和文档将Group By也纳入其中,但是我们认为如果不使用Distinct,仅仅对分组数据进行Sum和Count操作,并不会出现数据倾斜
解决方案
1 优先开启负载均衡
-- map端的Combiner,默认为ture
set hive.map.aggr=true;
-- 开启负载均衡
set hive.groupby.skewindata=true (默认为false)
如果发生数据倾斜,我们首先需要调整参数,进行负载均衡处理,这样 MapReduce 进程则会生成两个额外的 MR Job,这两个任务的主要操作如下:
第一步:MR Job 中Map 输出的结果集合首先会随机分配到 Reduce 中,然后每个 Reduce 做局部聚合操作并输出结果,这样处理的原因是相同的Group By Key有可能被分发到不同的 Reduce Job中,从而达到负载均衡的目的。第二步:MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成聚合操作。
2 表join连接时引发的数据倾斜
两表进行join时,如果表连接的key存在倾斜,那么在 Shuffle 阶段必然会引起数据倾斜。
原因:
因为在Shuffle阶段,Spark会将相同的key分配到同一个reduce task中进行处理,如果某个key的数据量过大,那么就会导致该reduce task的处理时间过长,从而影响整个任务的执行效率。
Spark会将相同的key分配到同一个reduce task中进行处理,这是因为在MapReduce中,shuffle阶段是将map输出的结果按照key进行排序,然后将相同的key分配到同一个reduce task中进行处理,这样可以减少网络传输的数据量,提高处理效率。
2.1 小表join大表,某个key过大
通常做法是将倾斜的数据存到分布式缓存中,分发到各个Map任务所在节点。在Map阶段完成join操作,即MapJoin,这避免了 Shuffle,从而避免了数据倾斜。
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率。
在Hive 0.11版本之前,如果想在Map阶段完成join操作,必须使用MAPJOIN来标记显示地启动该优化操作,由于其需要将小表加载进内存所以要注意小表的大小。
-- 常规join
SELECT
pis.id_ id,
service_name serviceName,
service_code serviceCode,
bd.code_text serviceType,
FROM
prd_price_increment_service pis
left join prd_price_increment_product pip on pis.id_ = pip.increment_service_id
-- Hive 0.11版本之前开启mapjoin
-- 将小表prd_price_increment_service,别名为pis的表放到map端的内存中
-- 如果想将多个表放到Map端内存中,只需在mapjoin()中写多个表名称即可,用逗号分隔,如将a表和c表放到Map端内存中,则 /* +mapjoin(a,c) */ 。
SELECT
/*+ mapjoin(pis)*/
pis.id_ id,
service_name serviceName,
service_code serviceCode,
bd.code_text serviceType,
FROM
prd_price_increment_service pis
left join prd_price_increment_product pip on pis.id_ = pip.increment_service_id
在Hive 0.11版本及之后,Hive默认启动该优化,也就是不在需要显示的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin,可以通过以下两个属性来设置该优化的触发时机:
-- 自动开启MAPJOIN优化,默认值为true,
set hive.auto.convert.join=true;
-- 通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中,默认值为2500000(25M),
set hive.mapjoin.smalltable.filesize=2500000;
SELECT
pis.id_ id,
service_name serviceName,
service_code serviceCode,
bd.code_text serviceType,
FROM
prd_price_increment_service pis
left join prd_price_increment_product pip on pis.id_ = pip.increment_service_id
-- 特殊说明
使用默认启动该优化的方式如果出现莫名其妙的BUG(比如MAPJOIN并不起作用),就将以下两个属性置为fase手动使用MAPJOIN标记来启动该优化:
-- 关闭自动MAPJOIN转换操作
set hive.auto.convert.join=false;
-- 不忽略MAPJOIN标记
set hive.ignore.mapjoin.hint=false;
SELECT
/*+ mapjoin(pis)*/
pis.id_ id,
service_name serviceName,
service_code serviceCode,
bd.code_text serviceType,
FROM
prd_price_increment_service pis
left join prd_price_increment_product pip on pis.id_ = pip.increment_service_id
特说说明:将表放到Map端内存时,如果节点的内存很大,但还是出现内存溢出的情况,我们可以通过这个参数 mapreduce.map.memory.mb 调节Map端内存的大小。
2.2 表中作为关联条件的字段值为0或空值的较多
解决方式:给空值添加随机key值,将其分发到不同的reduce中处理。由于null值关联不上,所以对结果无影响。
-- 方案一、给空值添加随机key值,将其分发到不同的reduce中处理。由于null值关联不上,所以对结果无影响。
SELECT *
FROM log a left join users b
on case when a.user_id is null then concat('hive',rand()) else a.user_id end = b.user_id;
-- 方案二:去重空值
SELECT a.*,b.name
FROM
(SELECT * FROM users WHERE LENGTH(user_id) > 1 OR user_id IS NOT NULL ) a
JOIN
(SELECT * FROM log WHERE LENGTH(user_id) > 1 OR user_id IS NOT NULL) B
ON a.user_id; = b.user_id;
2.3 表中作为关联条件的字段重复值过多
SELECT a.*,b.name
FROM
(SELECT * FROM users WHERE LENGTH(user_id) > 1 OR user_id IS NOT NULL ) a
JOIN
(SELECT * FROM (SELECT *,row_number() over(partition by user_id order by create_time desc) rk FROM log WHERE LENGTH(user_id) > 1 OR user_id IS NOT NULL) temp where rk = 1) B
ON a.user_id; = b.user_id;
-- 排个序只取第一个
3 空值引发的数据倾斜
实际业务中有些大量的null值或者一些无意义的数据参与到计算作业中,表中有大量的null值,如果表之间进行join操作,就会有shuffle产生,这样所有的null值都会被分配到一个reduce中,必然产生数据倾斜。
之前有小伙伴问,如果A、B两表join操作,假如A表中需要join的字段为null,但是B表中需要join的字段不为null,这两个字段根本就join不上啊,为什么还会放到一个reduce中呢?
这里我们需要明确一个概念,数据放到同一个reduce中的原因不是因为字段能不能join上,而是因为shuffle阶段的hash操作,只要key的hash结果是一样的,它们就会被拉到同一个reduce中。
-- 解决方案
-- 场景:如日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和 用户表中的user_id 关联,会碰到数据倾斜的问题。
-- 方案一:可以直接不让null值参与join操作,即不让null值有shuffle阶段,所以user_id为空的不参与关联
SELECT * FROM log a JOIN users b ON a.user_id IS NOT NULL AND a.user_id = b.user_id UNION ALL SELECT * FROM log a WHERE a.user_id IS NULL;
-- 方案二:因为null值参与shuffle时的hash结果是一样的,那么我们可以给null值随机赋值,这样它们的hash结果就不一样,就会进到不同的reduce中:
SELECT * FROM log a LEFT JOIN users b ON CASE WHEN a.user_id IS NULL THEN concat('hive_', rand()) ELSE a.user_id END = b.user_id;
特殊说明:针对上述方案进行分析,方案二比方案一效率更好,不但io少了,而且作业数也少了。方案一中对log读取可两次,jobs是2。方案二job数是1。本优化适合对无效id (比如 -99, ’’, null等) 产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上,解决数据倾斜问题。
4 不同数据类型关联产生数据倾斜
对于两个表join,表a中需要join的字段key为int,表b中key字段既有string类型也有int类型。当按照key进行两个表的join操作时,默认的Hash操作会按int型的id来进行分配,这样所有的string类型都被分配成同一个id,结果就是所有的string类型的字段进入到一个reduce中,引发数据倾斜。
-- 如果key字段既有string类型也有int类型,默认的hash就都会按int类型来分配,那我们直接把int类型都转为string就好了,这样key字段都为string,hash时就按照string类型分配了:
方案一:把数字类型转换成字符串类型
SELECT * FROM users a LEFT JOIN logs b ON a.usr_id = CAST(b.user_id AS string);
方案二:建表时按照规范建设,统一词根,同一词根数据类型一致
5 count distinct 大量相同特殊值
由于SQL中的Distinct操作本身会有一个全局排序的过程,一般情况下,不建议采用Count Distinct方式进行去重计数,除非表的数量比较小。当SQL中不存在分组字段时,Count Distinct操作仅生成一个Reduce 任务,该任务会对全部数据进行去重统计;当SQL中存在分组字段时,可能某些 Reduce 任务需要去重统计的数量非常大。在这种情况下,我们可以通过以下方式替换。
-- 可能会造成数据倾斜的sql
select a,count(distinct b) from t group by a;
-- 先去重、然后分组统计
select a,sum(1) from (select a, b from t group by a,b) group by a;
-- 总结: 如果分组统计的数据存在多个distinct结果,可以先将值为空的数据占位处理,分sql统计数据,然后将两组结果union all进行汇总结算。
6 数据膨胀引发的数据倾斜
在多维聚合计算时,如果进行分组聚合的字段过多,且数据量很大,Map端的聚合不能很好地起到数据压缩的情况下,会导致Map端产出的数据急速膨胀,这种情况容易导致作业内存溢出的异常。如果log表含有数据倾斜key,会加剧Shuffle过程的数据倾斜。
-- 造成倾斜或内存溢出的情况
-- sql01
select a,b,c,count(1)from log group by a,b,c with rollup;
-- sql02
select a,b,c,count(1)from log grouping sets a,b,c;
-- 解决方案
-- 可以拆分上面的sql,将with rollup拆分成如下几个sql
select a,b,c,sum(1) from (
SELECT a, b, c, COUNT(1) FROM log GROUP BY a, b, c
union all
SELECT a, b, NULL, COUNT(1) FROM log GROUP BY a, b
union all
SELECT a, NULL, NULL, COUNT(1) FROM log GROUP BY a
union all
SELECT NULL, NULL, NULL, COUNT(1) FROM log
) temp;
-- 结论:但是上面这种方式不太好,因为现在是对3个字段进行分组聚合,那如果是5个或者10个字段呢,那么需要拆解的SQL语句会更多。
-- 在Hive中可以通过参数 hive.new.job.grouping.set.cardinality 配置的方式自动控制作业的拆解,该参数默认值是30。
-- 该参数主要针对grouping sets/rollups/cubes这类多维聚合的操作生效,如果最后拆解的键组合大于该值,会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值。
set hive.new.job.grouping.set.cardinality=10;
select a,b,c,count(1)from log group by a,b,c with rollup;