openpyxl,xlrd两种模块方式,较为详细的方法操作Excel文件。
目录
-
-
- 第一个模块 openpyxl 操作excel
-
-
-
- 创建一个Excel文件
- 打开文件的两种方式
- 创建sheet
- 选择sheet
- 查看文件中所有的sheet名, 以列表的形式展示
- 遍历所有表
- 对单元格进行设置值
- 使用append添加多个值
- 获取最大行或列数
- 访问单元格,以下方法都可以取单元格的值
- 指定范围取值,按行循环取值(行->行)
- 指定范围取值,按列循环取值(列->列)
- 按某一列或几列取值
- 表头和数据形成字典,进行DataFrame转换
- 访问所有单元格内容
- 删除表
- 最后修改完后别忘了保存
-
-
- 表格说明
- 第二个模块 xlrd 操作excel
-
-
-
- 打开文件
- 查看sheet页的个数
- 获取sheet页的名称
- 选择sheet页
- 统计行列数
- 获取单元格内容
- 附上代码
-
-
- 表格说明
-
想要控制Excel,我们首先要知道的Excel文件的三个对象,具体都是干嘛的。
workbook: 工作簿,一个Excel文件可以包含多个sheet。
sheet:工作表,一个workbook可以有多个,如“sheet1”,“sheet2”等名称。
cell: 单元格,存储数据对象
第一个模块 openpyxl 操作excel
导入模块:import openpyxl
创建一个Excel文件
wb = openpyxl.Workbook()
wb.save("test.xlsx") # 已存在同名称的就覆盖,没有就创建
wb.close()
打开文件的两种方式
wb1 = openpyxl.open("test.xlsx") # 打开文件方法一,没有文件就报错
wb2 = openpyxl.load_workbook("test.xlsx") # 打开文件方法二,没有文件就报错
# 允许存在多个句柄
# 激活 worksheet /调用正在运行的表,默认为第一个sheet
# 不写这一行也可以,不过后面要选择sheet页
ws = wb1.active
创建sheet
ws1 = wb1.create_sheet("sheet_name") # 默认插入在最后的位置
ws2 = wb1.create_sheet("sheet_name1",0) # 插入到第一个位置
选择sheet
ws3 = wb1.get_sheet_by_name("sheet_name")
ws4 = wb1["sheet_name"]
查看文件中所有的sheet名, 以列表的形式展示
print(wb1.sheetnames)
print(wb1.get_sheet_names())
遍历所有表
for sheet_name in wb1:
print(sheet_name.title)
对单元格进行设置值
# 数据可以直接分配到单元格中(可以输入公式),A2代表Excal的第1列的第2行
ws["A2"] = 1
# 指定行和列,设置值,行和列必须从1开始,否则就报错
ws.cell(1, 1, "test")
使用append添加多个值
ws.append([1, 2, 3]) # 代表第一列第一行是1,第二列第一行是2,第三列第一行是3
for i in [[1, 2, 3], [4, 52, 6]]: # 列表中每个小列表代表一行,该代码一共添加2行3列
ws.append(i)
# 可以指定单元格位置添加,格式需为字典,例如
# 设置写入数据的行数(设置写入第3行),必须从0开始
ws._current_row = 2
ws.append({"B": 3, "C": 4, "F": 6})
import datetime
ws["C1"] = datetime.datetime.now() # 可以赋值时间字符串
获取最大行或列数
print(ws.max_row) # 获取行数
print(ws.max_column) # 获取列数
访问单元格,以下方法都可以取单元格的值
# 获取某一单元格的值,行和列必须从1开始,否则就报错
print(ws.cell(1, 1).value)
# 指定英文位置取值
print(ws["C1"].value)
# ws["A1":"A10"] = ((xx,),(xx,),(xx,)),因为有两层元组,所以取值时需要用到两个for循环
for row in ws["A1":"A10"]: # / ws["A1:A10"] ---->>两种切割方式都可以
for r in row:
print(type(r)) # 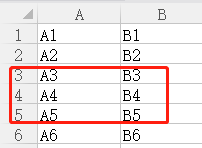
指定范围取值,按行循环取值(行->行)
# ((xx,),(xx,),(xx,))因为有两层元组,所以取值时需要用到两个for循环
# iter_rows 按行取值,该行对应的范围列的值取完后才继续下一行
for row in ws.iter_rows(min_row=3, max_row=5, min_col=1, max_col=2): # /
# 取从第3行--->到第5行, 从第1列-->到第2列,这范围的值
for r in row:
print(r.value)
输出结果:
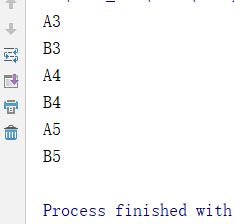
指定范围取值,按列循环取值(列->列)
# iter_cols 按列取值,该列对应的范围行的值取完后才继续下一列
for row in ws.iter_cols(min_row=3, max_row=5, min_col=1, max_col=2):
# 取从第3行--->到第5行, 从第1列-->到第2列,这范围的值
for r in row:
print(r.value)
输出结果:
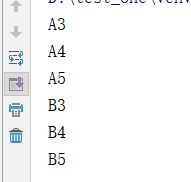
按某一列或几列取值
for i in ws3["A"][0:]: # 取A这一列的所有值
print(i)
print(i.value)
print([col.value for col in ws3["A"][0:]]) # 列表生成式打印
# 取某几列的所有值
for col in ws3["C:F"]:
for c in col:
print(c.value)
表头和数据形成字典,进行DataFrame转换
import pandas as pd
result = {}
for data_cell in ws["A:F"]: # 指定列字母
# {'title': [1,2,3,4,5], ......}
result[data_cell[0].value] = [data.value for data in data_cell[1:]]
pd.DataFrame(result)
访问所有单元格内容
# ws3.columns:按照列遍历 / ws3.rows :按照行遍历
for row in ws.columns:
for r in row:
print(r.value)
删除表
del wb1["Sheet"]
最后修改完后别忘了保存
wb1.save("test.xlsx")
附上完整代码
# 方式一
import openpyxl
# 创建一个Excal文件
wb = openpyxl.Workbook()
wb.save("test.xlsx") # 已存在同名称的就覆盖
wb.close()
wb1 = openpyxl.open("test.xlsx") # 打开文件方法一,没有文件就报错
wb2 = openpyxl.load_workbook("test.xlsx") # 打开文件方法二,没有文件就报错
# 允许存在多个句柄
# 激活 worksheet /调用正在运行的表,默认为第一个
# 不写这一行也可以,不过后面要选择sheet页
ws = wb1.active
# 创建sheet
ws1 = wb1.create_sheet("sheet_name") # 默认插入在最后的位置
ws2 = wb1.create_sheet("sheet_name1", 0) # 插入到第一个位置
# 选择sheet
ws3 = wb1.get_sheet_by_name("sheet_name")
ws4 = wb1["sheet_name"]
# 查看文件中所有的sheet名, 以列表的形式展示
print(wb1.sheetnames)
print(wb1.get_sheet_names())
# 遍历所有表
for sheet_name in wb1:
print(sheet_name.title)
# 对单元格进行设置值
ws["A2"] = 1 # 数据可以直接分配到单元格中(可以输入公式)
ws.cell(1, 1, "test") # 指定行和列,设置值
# 使用append添加值
ws.append([1, 2, 3]) # 代表第一列第一行是1,第二列第一行是2,第三列第一行是3
for i in [[1, 2, 3], [4, 52, 6]]: # 每个列表代表一行,依次向右单元格填充值
ws.append(i)
import datetime
ws["C1"] = datetime.datetime.now()
print(ws.max_row) # 获取行数
print(ws.max_column) # 获取列数
# 访问单元格,以下方法都可以取单元格的值
print(ws.cell(1, 1).value) # 获取某一单元格的值,行和列必须从1开始,否则就报错
print(ws["C1"].value)
for row in ws["A1":"A10"]: # / ws["A1:A10"] ---->>两种切割方式都可以
for r in row:
print(type(r)) # 表格说明
| 方法 | 说明 |
|---|---|
| wb = openpyxl.Workbook() | Workbook的类对象 |
| wb.save(filename) | 保存Excal文件,存在就覆盖,不存在就创建 |
| wb.close() | 关闭Workbook |
| wb1 = openpyxl.open(filemane) | 打开文件方式一,获取文件句柄 |
| openpyxl.load_workbook(filename) | 打开文件方式二,获取文件句柄 |
| wb1.create_sheet(title, index) | 创建sheet,title=文件名,index=创建的sheet位置 |
| ws = wb1.active | 选择激活的sheet表,默认为第一个sheet |
| ws3 = wb1.get_sheet_by_name(name) | 选择sheet方式一,name=sheet名称 |
| ws3 = wb1[“name”] | 选择sheet方式二,name=sheet名称 |
| wb1.sheetnames | 查看文件中所有的sheet名, 以列表的形式展示 |
| wb1.get_sheet_names() | 查看文件中所有的sheet名, 以列表的形式展示 |
| ws3[“A2”] = value / ws.cell(row, column, value) | 对指定位置的单元格进行添加值 |
| ws3.append(iterable) | 对单元格添加值(list, range or generator, or dict) |
| ws3.max_row | 获取最大行数 |
| ws3.max_column | 获取最大列数 |
| ws3.cell(row, column).value | 根据行和列获取单元格的值 |
| ws3[“A2”].value | 根据位置获取单元格的值 |
| ws3[“A1”:“A10”] | 根据切片来获取指定范围的单元格值(需用两个for循环) |
| ws3.iter_rows(min_row, max_row, min_col, max_col) | 指定行迭代范围,没有指定索引(从1开始),则范围从A1开始 |
| ws3.iter_cols(min_row, max_row, min_col, max_col) | 指定列迭代范围,没有指定索引(从1开始),则范围从A1开始 |
| ws3.columns | 按照列遍历(所有列) |
| ws3.rows | 按照行遍历(所有行) |
| del wb1[name] | 删除sheet页 |
当然该模块的功能远不仅于此,还有合并、拆分表,对齐,字体、行高、列宽等等,想要细了解的可以去再学习哈,这些足以应付日常以及部分测试所需。
openpyxl链接地址:
— https://openpyxl.readthedocs.io/en/stable/#usage-examples
— https://openpyxl.readthedocs.io/en/stable/tutorial.html
第二个模块 xlrd 操作excel
模块导入:import xlrd
注意:版本不能太高,最好使用1.2.0的版本
打开文件
workbook=xlrd.open_workbook(r"D:/user.xlsx")
查看sheet页的个数
print(workbook.nsheets)
获取sheet页的名称
# sheet_names 获取sheet页的名称,结果为列表
sheet1=workbook.sheet_names()
print(sheet1) # -->> ['test_one', 'test_two']
选择sheet页
# sheet1 = workbook.sheets()[index] # 根据sheet列表的索引取值
# 取第一个sheet页类的对象
sheet1 = workbook.sheets()[0]
print(sheet1.name) # 根据对象获取sheet的名称,下面的也可以
# 返回对应索引的sheet对象,索引范围为range(work_book.nsheets)。
print(workbook.sheet_by_index(1))
# 返回对应sheet名称的sheet对象。
print(workbook.sheet_by_name("sheet_name"))
统计行列数
print(sheet1.nrows) # 统计总共有多少行
print(sheet1.ncols) # 统计总共有多少列
# 循环行数,列数也一样
for i in range(sheet1.nrows):
print(i)
获取单元格内容
# 查看某一行的具体内容,必须跟(),并且括号里面要有值,因为内容是多个,value要加s
# 括号中的数字代表第几行或者第几列,默认从0开始
print(sheet1.row_values(0)) # -->> 输出为列表,读取第一行的数据
# 查看某一列的具体内容,必须跟(),并且括号里面要有值
print(sheet1.col_values(0)) # -->> 输出为列表,读取第一列的数据
# 取出第一行第一列的数据,以下三种都可以取出
1、print(sheet1.cell(0,0).value) # -->> 因为取出的是具体数值,所以value不加s
2、print(sheet1.row(0)[0].value)
# -->> row(0)代表的是第一行的数据,是个列表,row(0)[1]代表的是第一行第一个的数据
3、print(sheet1.cell_value(0, 0))
附上代码
# 方式二
import xlrd
# 打开一个excel文件
workbook = xlrd.open_workbook("cases1.xlsx")
# # sheet_names 获取所有sheet页的名称,返回结果为列表形式
sheet1 = workbook.sheet_names()
print(sheet1) # -->> ['test_one', 'test_two']
# 返回sheet的个数
print(workbook.nsheets)
# 返回对应索引的sheet对象,索引范围为range(work_book.nsheets)。
print(workbook.sheet_by_index(1))
# 返回对应sheet名称的sheet对象。
print(workbook.sheet_by_name("bonus"))
sheet1 = workbook.sheets()[0]
print(sheet1) # -->> 取第一个sheet页类的实例化
print(sheet1.name) # 获取sheet的名称
# 统计总共有多少行
print(sheet1.nrows)
# 循环行数,列数也一样
for i in range(sheet1.nrows):
print(i)
# 统计总共有多少列
print(sheet1.ncols)
# 查看某一行的具体内容,必须跟(),并且括号里面要有值,因为内容是多个,value要加s
# 括号中的数字代表第几行或者第几列,默认从0开始
print(sheet1.row_values(0)) # -->> 输出为列表,读取第一行的数据
# 查看某一列的具体内容,必须跟(),并且括号里面要有值
print(sheet1.col_values(0)) # -->> 输出为列表,读取第一列的数据
# 取出第一行第一列的数据,以下三种都可以取出
print(sheet1.cell(0, 0).value) # -->> 因为取出的是具体数值,所以value不加s
print(sheet1.row(0)[0].value)
# -->> row(0)代表的是第一行的数据,是个列表,row(0)[1]代表的是第一行第一个的数据
print(sheet1.cell_value(0, 0))
表格说明
| 方法 | 说明 |
|---|---|
| xlrd.open_workbook(file_path) | 打开指定路径的excel文件,返回excel处理对象,但无法打开不存在的文件。 |
| workbook.sheet_names() | 获取所有sheet页的名称,返回结果为列表形式 。 |
| workbook.nsheets | 返回sheet页的个数。 |
| workbook.sheet_by_index(index) | 返回对应索引的sheet对象,索引范围为range(work_book.nsheets)。 |
| workbook.sheet_by_name(“sheet_name”) | 返回对应sheet名称的sheet对象。 |
| sheet1=workbook.sheets()[0] | 取第一个sheet页类的实例化。 |
| sheet1.name | sheet的名称。 |
| sheet1.nrows | 统计该sheet页总共有多少行。 |
| sheet1.ncols | 统计该sheet页总共有多少列。 |
| sheet1.row_values(0) | 读取第一行的数据,括号中的数字代表第一行,默认从0开始, 输出内容为列表形式。 |
| sheet1.col_values(0) | 读取第一列的数据,括号中的数字代表第列行,默认从0开始, 输出内容为列表形式。 |
| sheet.cell(rowx, colx) | 返回对应单元格的cell对象。 |
| sheet1.cell(0,0).value | 取出第一行第一列的数据(方法一)。 |
| sheet1.cell_value(0, 0) | 取出第一行第一列的数据(方法二)。 |
| sheet1.row(0)[0].value | 取出第一行第一列的数据(方法三)。 |
| sheet1.row(rowx) | 返回对应行的cell对象组成的列表。 |
| sheet1.col(colx) | 返回对应列的cell对象组成的列表。 |