golang学习笔记
编译运行
文章目录
- 编译运行
- 前言
- 一、golang的优势?
- 二、编译运行
- 三、代码规范
- 四、语言特性
-
-
- ·指针
- ·结构体
- ·命名相关问题
- ·方法
- ·函数
-
- 定义
- 基本特性
- 高级特性
- ·defer语句
- ·错误与异常
- ·结构体嵌套
- ·接口
- ·golang接口相关的特性
- ·类型断言
- ·反射
- ·并发
-
- 五、基础语法
-
-
- ·声明变量
- ·控制台打印
- ·声明结构体对象
- ·结构体初始化
- ·流程控制
-
- 六、 集合
-
- 数组
- 切片
-
- 切片表达式
- 判断切片是否为空
- 切片的拷贝
- 切片中删除一个元素
- 切片添加元素
- 切片的扩容机制
- map
-
- 创建和初始化
- 获取map中元素
- 向map中添加元素
- 遍历map
- 删除元素
- 小例题:英文单词词频统计
- 七、常用标准库中的一些经典用法(不断更新)
- 遇到的问题
前言
初学golang的学习笔记,可能会有大量浅显的理解甚至谬误,仅作记录。
一、golang的优势?
- 高性能-协程
golang 源码级别支持协程,实现简单。协程使用,当底层遇到阻塞会自动切换,也就是逻辑层通过同步方式实现异步,充分利用了系统资源,同时避免了异步状态机的反人类异步回调,实现方式更为直观简单。 - 生态
有谷歌做背书,生态丰富,可以轻松 go get 获得各种高质量轮子。这样用户可以专注于业务逻辑,避免重复造轮子。 - 部署
部署简单,源码编译成执行文件后,可以直接运行,减少了对其它插件依赖。不像其它语言,执行文件依赖各种插件,各种库,研发机器运行正常,放到生产环境上,死活跑不起来,需要各种安装和版本匹配。 - 跨平台
很多语言都支持跨平台,把这个优点单独拿出来,貌似没有什么值得称道的,但是如果结合以上优点来看,它的综合能力就非常强了。 - 代码极简
个人认为 golang 是 C++ 和 python 的结合体,它是一门全新的语言,入门和使用相对简单,是性能和代码极简之间的一种平衡。
引用自:简单说说 golang 的主要优点
二、编译运行
//windows下编译成可执行文件:
go run xxx.go ---直接执行go代码
go build xxx.go [-o xxx] --- 编译go代码生成可执行文件[指定可执行文件名]
//Windows下编译linux下可执行文件:
SET CGO_ENABLED=0 // 禁用CGO
SET GOOS=linux // 目标平台是linux
SET GOARCH=amd64 // 目标处理器架构是amd64
//Mac 下编译 Linux 和 Windows平台 64位 可执行程序:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build
//Linux 下编译 Mac 和 Windows 平台64位可执行程序:
CGO_ENABLED=0 GOOS=darwin GOARCH=amd64 go build
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build
//Windows下编译Mac平台64位可执行程序:
SET CGO_ENABLED=0
SET GOOS=darwin
SET GOARCH=amd64
//在进行上述设置之后,即可通过go build xxx.go指令生成目标平台上的可执行文件。
三、代码规范
package main //Todo 包相关知识点
//import “xxx” //引入的模块
import (
console "fmt" //当需要引入多个模块时可以使用圆括号
)
//如果要编译一个go工程,必须有一个.go文件
//并且其中含有func main(){}作为整个程序的入口
func main() {
fmt.Println("hello world")
}
四、语言特性
·指针
go中所有方法的参数都是传值,对于*type的指针,本质上会在方法调用时创建一个新的形参指针并且把实参指针记录的地址赋给形参。
·结构体
go中没有class的概念,但是可以通过结构体+方法来实现类的效果。
首先结构体是一组数据的集合,不包含方法,定义形式如下:
type XXX struct{
fieldName1 int
fieldName2 string
fieldName3,fieldName4,fieldName5 float32
}
·命名相关问题
1、golang的命名需要使用驼峰命名法,且不能出现下划线,单独的下划线作为变量名表示这是一个不会被使用到的匿名变量,这在调用多返回值的函数或方法时很常用。
2、golang中根据首字母的大小写来确定可以访问的权限。无论是方法名、常量名、变量名还是结构体的名称,如果首字母大写,则可以被其他的包访问;如果首字母小写,则只能在本包中使用。
3、如果结构体属性名首字母小写则在数据解析(如json解析,或将结构体作为请求或访问参数)时无法解析。
·方法
golang中的方法需要有一个接收者,即类似于属于某一个类的成员方法,
func (receiverName ReceiverType) funcName (param1 type1, param2 type2) (retType1, retType2){
doSomething...
}
接收者可以是一个结构体对象,也可以是结构体对象指针,区别在于:
- 如果接收者为结构体对象,那么在该类对象调用这个方法的时候会复制一份当前对象,再执行这个方法,于是方法内部对this做出的修改不会作用到原对象中。
- 如果接收者是结构体指针,那么该方法被调用时,就是直接在该对象的数据上进行操作。
何时选择对象指针作为方法的接收者:
- 需要修改接收者中的值
- 接收者是拷贝代价比较大的大对象
可以通过给基础数据类型添加别名,然后给新的类型名添加方法(感觉没什么用)
·函数
定义
func fooName (param1 type1, params ...type2) (type1, type2){
//func fooName (param1 type1, params ...type2) (val1 type1, val2 type2){
dosomething()
return val1,val2
//return
}
基本特性
-
其中返回值可以在定义类型时声明变量名字,在函数体中直接使用返回变量,这样就不需要再显示地return val1,val2,直接return就可以了。
-
当函数没有返回值时,可以不用声明返回值列表。
-
golang支持多返回值,在调用的时候,n值返回的函数可以当作另一个函数的n个参数如
fmt.Println(add(swap(a,b)))。 -
可变参数
func foo(x ... int){ //x将以一个切片的形式传入函数中 }
高级特性
- 函数类型变量
//定义了calculation的方法类型
type calculation func(int, int) int
//所有以两个int作为参数、一个int作为返回值的方法都属于calculation类型
func add( a int, b int) int {return a+b}
func sub(a int, b int) int {return a-b}
func main() {
//add和sub都能赋值给一个calculation类型的函数变量
var method1 calculation = add
fmt.Printf("%T\n",method1) //main.calculation
method2 := sub
fmt.Printf("%T\n",method2) //func(int, int) int
}
- 函数作为参数
类似于C++中的函数指针,可以把函数1当作参数传入另一个函数2,使得函数2中能够动态地执行不同内容。
func add( a int, b int) int {return a+b}
func doCalculate(a int,b int,option func (int,int)int) {
fmt.Println(option(a,b))
}
//函数作为参数
doCalculate(100,200,add) //output: 300
- 函数作为返回值
//func getOption(s string) (func (int,int)int, error) {
func getOption(s string) (calculation, error) {
switch s {
case "+":
return add, nil
case "-":
return sub, nil
default:
err := errors.New("无法识别的操作符")
return nil, err
}
}
//函数作为返回值
plus,_ := getOption("+")
fmt.Printf("%T",plus)
- 匿名函数
//匿名函数
anonymousMethod := func (x int,y int) int {
if x>y {
return x
} else {
return y
}
}
fmt.Println(anonymousMethod(999,888)) //output:999
- 自执行匿名函数
//自执行匿名函数
i := func(start int, end int) int {
if start > end {
return 0
}
result := 0
for i := start; i <= end; i++ {
result += i
}
return result
}(1, 100) //注意到 这里在订一晚匿名函数之后 立马跟上实参 表示立即执行
fmt.Println(i) //output:5050
- 闭包
闭包指的是一个函数和与其相关的引用环境组合而成的实体。简单来说,闭包=函数+引用环境
这里的引用环境我个人理解为那些未经过传参而直接在函数内部使用的外部变量,举例如下://内部维护一个累加值,返回一个函数,该函数每次被调用就会增加这个累加值的大小 func getAnAction() func (int) int{ baseValue :=100 return func (a int) int{ baseValue+=a return baseValue } } action := getAnAction() //在action这个函数的生命周期内,返回他的getAnAction中的局部变量baseValue是会持续存在的 fmt.Println("action1:",action(1)) //action1: 101 fmt.Println("action1:",action(2)) //action1: 103 fmt.Println("action1:",action(3)) //action1: 106 //action2是getAnAction返回的另一个方法,其中引用的baseValue跟action引用的是相互独立、互不影响的 action2 := getAnAction() fmt.Println("action2:",action2(100)) //action2: 200 fmt.Println("action1:",action(4)) //action1: 110
·defer语句
将defer后引导的子句压入栈中,在函数最终return之前执行。
注意到,当一个被derfer引导的子句被压入栈中时,语句中的**参数值就已经确定下来**,与出栈并被执行时的参数实时值无关。
```go
func f3() {
x:=1
defer fmt.Println(x)
x++
return
}
f3() //output: 1
```
特殊的,有必要说明,golang中的return不是原子性的,实际上分为两步:
1. 确定需要return的变量,并且对其赋值,这里又有两种情况:
· 无名返回值---`return n` 则此时会创建一个新的变量m,并把n的值赋给m,最终在RET指令中返回m的值。
· 有名返回值x---`return x` / `return 常量`/`return` ,这三种情况不会创建新的变量m,而会在RET指令中直接返回x的值。
这两种差异会导致以下情况:
```go
func f1() int {
x := 5
defer func() {
x++
}()
return x
}
func f2() (x int) {
defer func() {
x++
}()
return 5
}
fmt.Println(f1()) //5
fmt.Println(f2()) //6
```
原因在于f1中是无名返回值,在return x的时候已经把5赋值给了隐含的返回变量m,defer中对x做修改,不会影响m的值,即依然返回5。
f2中是有名返回值,return 5等价于执行x=5,而defer中会执行x++,最终返回的依然是x,即返回6。
2. 执行RET指令。
这一步之前、第一步之后,还会执行defer栈中的指令,最后执行RET指令,整个return过程才结束。
·错误与异常
在java程序中,业务层的功能接口通常是对可能出现运行时异常的地方进行显示地try{...}catch(Exception e){...},功能接口返回一个Response响应体,将功能接口的返回值or错误异常信息传递给controller层,而golang中的方法支持多返回值,于是可以省去response的封装,通过额外返回一个error对象,来返回错误异常信息。
golang中提供一个接口error,可以引入“errors”包,通过errors.New(str string)来快速构造一个error接口的实现类对象作为返回值。
```go
type error interface {
Error() string
}
func panic2() error{
fmt.Println("This is panic2 --- I am returning an error")
return errors.New("This is an Error")
}
func panic1(){
if err := panic2();err!=nil{
fmt.Println(err) //output:This is an Error
}
}
```
除此之外,对于那些业务逻辑以外的“运行时异常”,golang也有一套类似于try/catch的机制,即panic/recover。
``panic(v interface{})``是golang一个内置方法,可以简单理解为java中的throw关键字,他会中断当前携程的执行。
以下为golang官方文档对panic、recover的解释:
For this purpose, there is a built-in function panic that in
effect creates a run-time error that will stop the program (but see
the next section). The function takes a single argument of
arbitrary type—often a string—to be printed as the program dies. It’s
also a way to indicate that something impossible has happened, such as
exiting an infinite loop.
内置函数panic实际上会创建一个运行时的error,并且会停止当前程序的运行(但是可以通过recover方法恢复程序的运行,见下文叙述)。pani函数仅仅需要一个抽象类型的参数,通常是一个字符串,在程序结束运行时会被打印出来。这也是用来表示一些不可能(不应该)发生的事发生了,例如出现了一个无限的循环。
When panic is called, including implicitly for run-time errors such as
indexing a slice out of bounds or failing a type assertion, it
immediately stops execution of the current function and begins
unwinding the stack of the goroutine, running any deferred functions
along the way. If that unwinding reaches the top of the goroutine’s
stack, the program dies. However, it is possible to use the built-in
function recover to regain control of the goroutine and resume normal
execution. A call to recover stops the unwinding and returns the
argument passed to panic. Because the only code that runs while
unwinding is inside deferred functions, recover is only useful inside
deferred functions.
当panic被主动调用,或者是对切片、数组越界访问而隐式地触发panic时,会立即停止执行当前的函数,并且开始本携程栈的解旋(unwinding似乎是c++的异常处理机制中的一个名词,不是很了解),在此过程中,会后进先出地执行本段代码触发panic之前的所有defer修饰的内容。当解旋过程到达了携程栈的顶端,那么这个携程的生命周期就结束了。然而,可以用内置的recover函数来重新获得对当前携程的控制权,并且可以继续正常地执行写在recover后的程序代码。对recover的调用会停止解旋过程,并且会返回导致解旋的panic被调用时传入的那个参数(就是刚刚说通常是字符串的那个)。因为在解旋过程中唯一会执行的代码就只有defer修饰的函数(或者一个语句中)中,所以revover只有在defer修饰的片段中才会生效。
但需要注意的是,何时使用error机制,何时使用panic/recover也有讲究,查阅资料得知通常在以下场景使用panic/recover:
在这个启示下,我们给出异常处理的作用域(场景):
- 空指针引用
- 下标越界
- 除数为0
- 不应该出现的分支,比如default
- 输入不应该引起函数错误
引用自>>Golang错误和异常处理的正确姿势
使用示例:
//不使用recover:
func panic1(){
fmt.Println("Before panic2, do something to prepare.")
//defer func(){
// err := recover()
// fmt.Println(err)
//}()
panic2()
fmt.Println("After panic2, do the rest of the work.")
}
func panic2(){
fmt.Println("This is panic2 --- I am throwing an exception")
panic("some fatal errors happened, call panic from panic2()!!!")
fmt.Println("This is panic2 , do something after panic. [This should not happen]")
}
//in main
panic1()
//output:
Before panic2, do something to prepare.
This is panic2 --- I am throwing an exception
panic: some fatal errors happened, call panic from panic2()!!!
goroutine 1 [running]:
main.panic2()
F:/golang_projects/test01/1208/method.go:88 +0xa5
main.panic1()
F:/golang_projects/test01/1208/method.go:80 +0x8a
main.main()
F:/golang_projects/test01/1208/method.go:154 +0x871
Process finished with exit code 2
//使用recover:
func panic1(){
fmt.Println("Before panic2, do something to prepare.")
defer func(){
if err := recover();err!=nil{
fmt.Println(err)
fmt.Println("After panic2, do the rest of the work.")
}
}()
panic2()
//recover之后并不会继续执行panic2后的代码,只会执行err!=nil{}中的内容
//fmt.Println("After panic2, do the rest of the work.")
}
//in main
//output:
Before panic2, do something to prepare.
This is panic2 --- I am throwing an exception
some fatal errors happened, call panic from panic2()!!!
Process finished with exit code 0
·结构体嵌套
-
字段如果没有变量名而仅有一个类型名,称其为匿名字段,那么可以直接通过obj.typeName访问这个字段,但是同一类型的匿名字段只允许出现一个。
-
对于嵌套的匿名结构体,可以直接访问其字段。而当有多个匿名嵌套结构体,并且这些结构体存在重复字段时,不能直接访问。
package main
import "fmt"
//地址结构体
type Address struct {
Location string
Distance int
}
//个人信息结构体
type Info struct {
Address //嵌套了一个匿名的Address的结构体 以实现【继承】的效果
Name string
Age int
}
func main() {
info := Info{
Address{
Location: "天马学生公寓",
Distance: 12,
},
"程序猿杨老师",
21,
}
//可以认为Info是Address的子类
//于是可以直接由Info的实例访问Address中的字段
fmt.Println(info.Location,info.Distance)
}
·接口
golang中接口本质是——规定一个包含多个方法的集合,如果一个【结构体】实现了接口中的全部方法,那么这个【结构体】就自动实现了这个接口,不需要显式地声明这个结构体与接口的关系,具体的作用就是体现在代码中的多态上,即可以用接口类型变量指代接口实现类的具体对象。
注意到,这里指的【结构体】也可以是一个结构体的指针,当这种情况下,就只能用该接口去指代该结构体指针的对象,如下图:

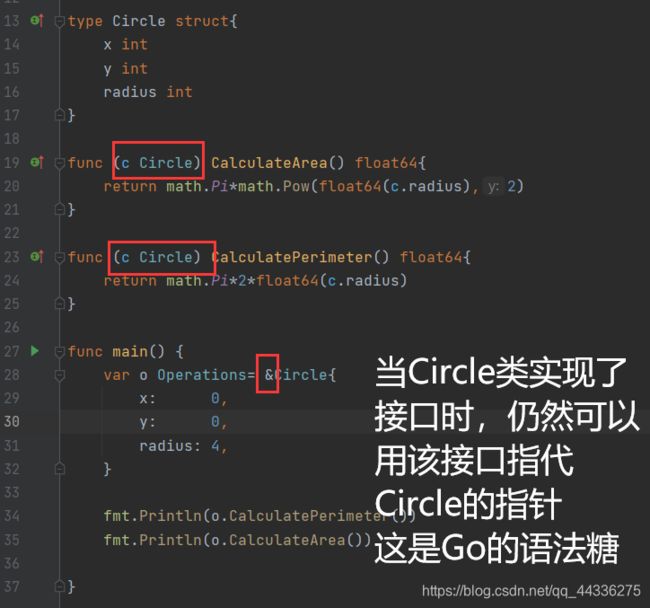
·golang接口相关的特性
- 结构体可以实现多个接口
- 结构体实现接口可以直接以该结构体作为方法接收者去实现,也可以通过嵌套实现了接口中部分方法的匿名结构体来凑出接口中的全部方法,如图:
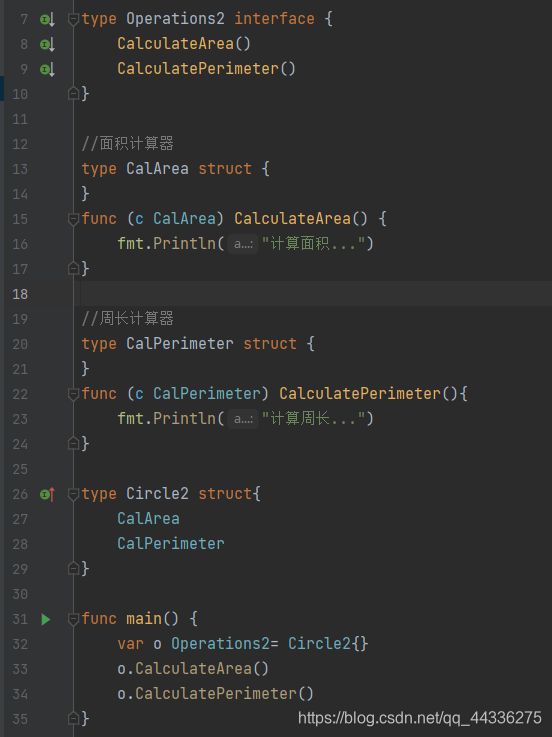
- 接口内部可以嵌套接口,将多个接口的方法合并到该接口中
- 注意到,当两个接口中含有相同的方法(这里指的是方法名、参数、返回值完全一致)
此时由一个结构体去实现这两个接口中的所有方法,会默认把这两个相同的方法视为一个,可以编译通过。
即:结构体实现一个方法,它可以是两个不同接口中的同一个方法,当然因为golang方法不支持重载的特点,两个接口中的该方法的方法名、参数、返回值一定是一样的。
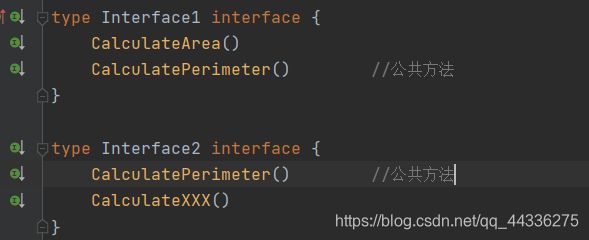
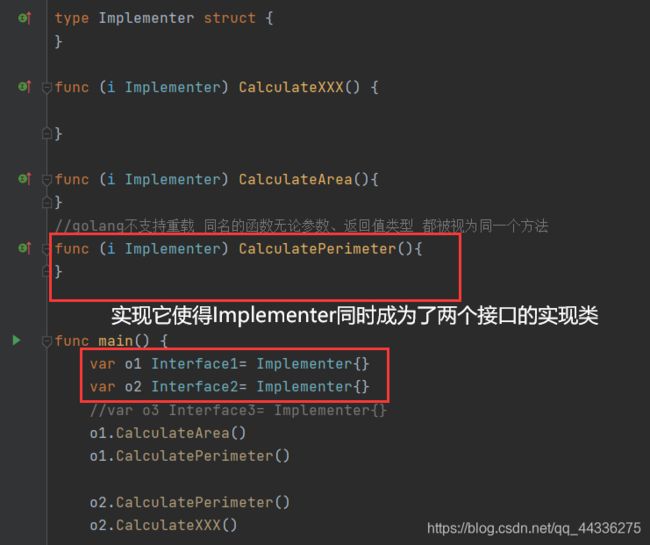
- 如果这两个接口中两个方法仅仅是方法名相同,而参数或返回值不同,编译器会识别出这是重复声明的一个方法(duplicated declared),无法编译通过。
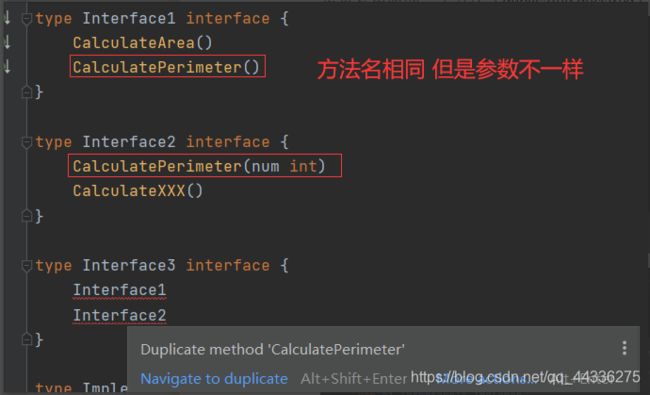
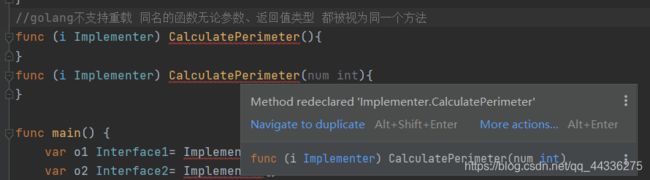
这个问题出现的本质是,golang不支持方法重载,即方法名本身就是这一个方法的全部标识,与参数、返回值无关。
这是为了顺应golang设计时【简单】【语义明确】的原则。重载这个特性不是必须的,只是在极少数场景下能够使得代码更加优雅,但会因此带来语义上的模糊以及更多不必要的麻烦。

- 其实如果真的硬要方法重载,可以通过可变参数的方式实现 func foo(args … interface{})
这里就要引入golang中的空接口 interface{}
因为空接口中没有任何方法,于是按照golang的接口实现逻辑可以认为,所有结构体或者说所有类型都实现了空接口,这就好比java中的Object类,所有的对象都是Object的实例。
package main
import "fmt"
/**
空引用:interface{} 类比于java中的Object类
*/
type SomeClass struct{
Name string
}
func main() {
//声明一个空接口的引用
//var obj interface{}
它可以用来指代任何类型的对象
//obj = SomeClass{}
//obj = 1
//obj = "abc"
//obj = true
//println(obj)
multipleParamFunction(1,"abc",true,SomeClass{"GeorgeYang"})
// 空接口作为map值
var studentInfo = make(map[string]interface{})
studentInfo["name"] = "SomeBody"
studentInfo["age"] = 18
studentInfo["married"] = false
fmt.Println(studentInfo)
}
func multipleParamFunction(args... interface{}) {
//对参数的类型、数量进行定制化判断 以达到这个函数重载的效果
for i:=0;i< len(args);i++{
fmt.Println(args[i])
}
}
如果采用这种方式实现函数重载,需要自行对参数数量、类型进行判断,也很麻烦
一种优雅的写法就是直接通过函数名去唯一标识该方法,例如
loginByPhone(phoneNum string)
loginByAccount(account string, password string)
·类型断言
golang类型断言的使用
·反射
·并发
五、基础语法
·声明变量
//声明一个type类型的变量,可以对其进行初始化赋值
var name type [= initial_value]
//声明多个变量 用新行分隔
var( name1 type
name2 type
)
//当声明多个相同类型变量时,2可以化简为
var name1,name2,name3 type
·控制台打印
fmt.Println(val1,val2,...) //打印的结果默认会按照一个空格分隔
fmt.Printf(“xxx占位符1xxx占位符2xxx”,value1,value2...)
一些常用的占位符和打印方式
十进制数%d
(%0nd为指定长度为n,不足左部补零,超过则按实际长度打印)
打印结构体对象的值%v {xxx 18}
打印结构体对象的字段以及对应的值%+v
Printf("%+v", people) {name:xxx age:18}
打印值的Go语法表示%#v
Printf("%#v", person) — main.Human{name:xxx age:18}
·声明结构体对象
//声明一个type1类型的变量(或者理解成一个引用)
1. var xxx type1
//必要时可以传入相等于结构体内字段数量的构造参数
3. var xxx = type1{}
//创建一块内存区域用于存储一个type1类型的对象,返回该对象的地址,
//其中ptr的类型应该是*type1,即type1类型的指针,
//是go语言支持直接通过ptr.xxx的方式访问该地址对应对象的属性。
4. var ptr = new(type1)
//与3类似,创建一个type1对象,并把其地址赋给ptr,go语言提供了语法糖,
//自动将ptr.field 转换成 (*ptr).field,即把地址还原成对象引用,
//再进行对象的属性访问。
5. var ptr = &type1{}
·结构体初始化
1、使用 键:值 进行初始化:
var obj = type1{ //声明结构体
field1: “value1”,
field2: “value2”, //注意到 这里最后还有个逗号
}
var ptr = & type1{ //声明结构体指针
field1: “value1”,
field2: “value2”, //注意到 这里最后还有个逗号
}
2、使用值进行初始化:
不写键,直接写值,但是要把结构体中所有字段都初始化
var obj = type1{ //声明结构体
“value1”,
“value2”, //注意到 这里最后还有个逗号
}
·流程控制
- if else
golang中对一些表达式的格式有严格的要求,就比如if的条件后接的左花括号一定要跟if在同一行,这样有助于golang的代码风格统一,增强在大工程中的代码可读性。
if 表达式1 {
分支1
} else if 表达式2 {
分支2
} else{
分支3
}
可以在if后面初始化一些变量,用分号分隔后再写第一个判断条件
if score := 65; score >= 90 {
fmt.Println("A")
} else if score > 75 {
fmt.Println("B")
} else {
fmt.Println("C")
}
- for
for 初始语句;条件表达式;结束语句{
循环体语句
}
//for循环的初始语句和结束语句都可以省略
//就像其它语言中的while(true){...}
i := 0
for i < 10 {
fmt.Println(i)
i++
}
for循环可以通过break、goto、return、panic语句强制退出循环。
- for range
Go语言中可以使用for range遍历数组、切片、字符串、map 及通道(channel)。 通过for range遍历的返回值有以下规律:
数组、切片、字符串返回索引和值。
map返回键和值。
通道(channel)只返回通道内的值。
for index, value := range someArrayOrSlice{
...
}
for key, value := range someMap{
...
}
for i := range someChannel { // 通道关闭后会退出for range循环
...
}
- switch
Go语言规定每个switch只能有一个default分支。
switch finger {
case 1:
fmt.Println("大拇指")
case 2:
fmt.Println("食指")
case 3:
fmt.Println("中指")
case 4:
fmt.Println("无名指")
case 5:
fmt.Println("小拇指")
default:
fmt.Println("无效的输入!")
}
一个分支可以有多个值,多个case值中间使用英文逗号分隔。
switch n := 7; n {
case 1, 3, 5, 7, 9:
fmt.Println("奇数")
case 2, 4, 6, 8:
fmt.Println("偶数")
default:
fmt.Println(n)
}
分支还可以使用表达式,这时候switch语句后面不需要再跟判断变量。
age := 30
switch {
case age < 25:
fmt.Println("好好学习吧")
case age > 25 && age < 35:
fmt.Println("好好工作吧")
case age > 60:
fmt.Println("好好享受吧")
default:
fmt.Println("活着真好")
}
golang中的一个case匹配并执行完毕后,默认有一个break,不会继续走之后的分支,但是fallthrough会无条件执行下一个分支,并不会判断条件是否为true。
s := "a"
switch {
case s == "a":
fmt.Println("a")
fallthrough
case s == "b":
fmt.Println("b")
default:
fmt.Println("...")
}
输出结果:
a
b
当所有的分支都没有进入时,就会执行default分支。
- goto
和C++中的flag用法一样。
func gotoDemo2() {
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
// 设置退出标签
goto breakTag
}
fmt.Printf("%v-%v\n", i, j)
}
}
return
// 标签
breakTag:
fmt.Println("结束for循环")
}
六、 集合
数组
大小固定、声明时确定的长度,是该数组类型的一部分。
注意,go中不允许使用非常量来声明数组的大小,即不可以在运行时通过变量开辟一个不确定大小的数组,所以推荐使用切片slice。

切片
切片的底层原理: slice本质是对一个数组的封装,内部会维护这个数组的地址、容量(即数组的大小)、当前容纳元素数量。
可以通过go内置的len()、cap()函数获取一个数组或者切片的大小和容量。

切片表达式
-
简单切片表达式:slice/arrayName[low:high] 包左不包右,左右均可省略,省略的地方取到边界,例如a[:] 等同于 a[0:len(a)]
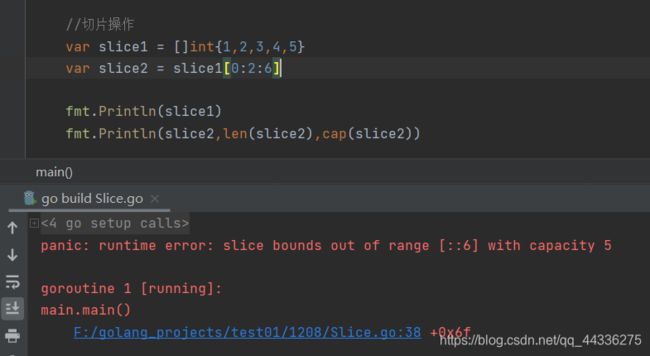
注意,对于一个slice,再进行切片,则右边界最大为cap(oldSlice)而不是len(oldSlice)。 -
完整切片表达式:slice/arrayName[low:high:max] low和high与简单切片表达式用法一致,max-low等于返回切片的容量。
注意:high、max的数值不能大于cap(oldSlice),否则将panic。
判断切片是否为空
if( len(slice) == 0)
而不是 if( slice == nil)
因为非空指针对应的切片也有可能内容为空。
切片的拷贝
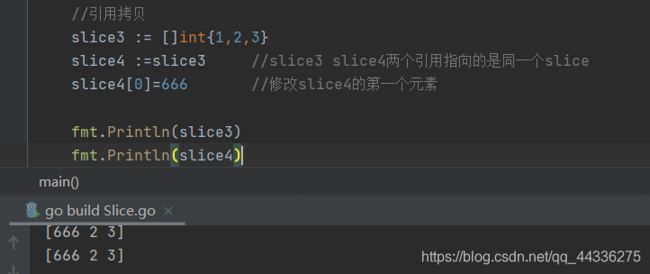
- 引用拷贝
本质上多个引用指向的slice是相同的,故底层维护的数组、len、cap是共享变化的。
- 内容拷贝
copy(destSlice, srcSlice []T)
刚刚有提到,可以通过
destSlice := copy(srcSlice[0:0:0],srcSlice…)
快速地拷贝一个切片,这样省去了对destSlice的初始化。

copy函数容量不足时,不会进行自动扩容,而只会把目标切片容量占满。

copy函数的destinySlice如果没有初始化过,即为nil,此时复制会失败。
切片中删除一个元素
go中没有专门提供delete方法,但是可以通过append来实现:
slice := append(slice[:deleteIndex],slice[deleteIndex+1:]…)
切片添加元素
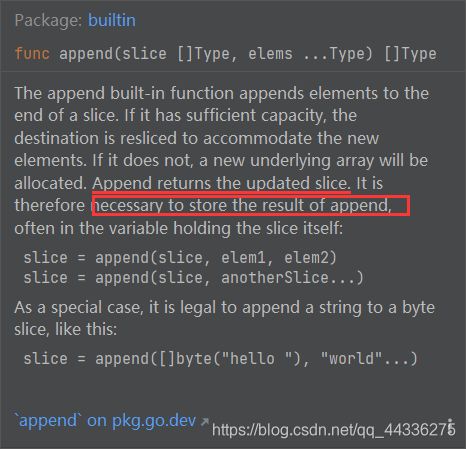
func append(slice []Type, elems ...Type) []Type
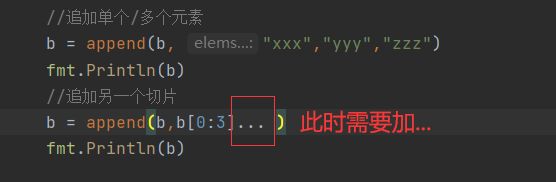
注意到,之前提到copy函数的destinySlice如果没有初始化过,即为nil,此时复制会失败,
但是在append中则可以直接使用,因为append的机制会在当destiny为nil或者容量不足时自动开辟空间或者扩容。
切片的扩容机制
查看源码,可以知道知道golang切片的扩容原理:
如果当前切片容量小于目标大小,则进行扩容;
当前容量小于1024,则直接翻倍;
如果当前容量大于1024,则按照1/4倍大小扩大,直到出现有符号整数加法溢出;
如果出现溢出,那么将新容量设置为目标大小。
newcap := old.cap
doublecap := newcap + newcap if cap > doublecap {
newcap = cap} else {
if old.len < 1024 { //切片当前长度小于1024 那就翻倍
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
//切片大于1024,那么按之前的1/4进行扩容并且每次检查有符号整数的溢出
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
//如果发生了溢出,那就直接扩容为新的大小
newcap = cap
}
}}
切片的底层实现原理,其实就是维护一个数组的地址以及该切片当前的大小以及容量。而切片的引用指向的地址,其实就是这个底层数组的首地址。于是切片扩容时,由于需要重新开辟空间用来分配一个更大的数组,所以底层数组首地址肯定会变化,进而切片引用指向的地址也会发生变化,这正是append被要求将返回值重新赋给切片引用的原因。

map
散列实现,key-value型容器。
创建和初始化
//声明并初始化一个map
studentMap := map[int]string{
10101:"张三",
10102:"李四",
10103:"王五",
}
//用make创建一个map
teacherMap := make(map[int]string,10)
teacherMap[1001]="刘老师" //mapName[key] = value 进行k-v的插入/覆盖
teacherMap[1002]="杨老师"
获取map中元素
//获取map中一个key对应的value以及这个key是否存在
val,exist :=teacherMap[1002]
向map中添加元素
//mapName[key] = value 进行k-v的插入/覆盖
teacherMap[1001]="热心的小陈老师"
注意,不可以使用nil作为key或者value,这一点跟java中的HashTable类似(我把nil理解为java中的null)。

遍历map
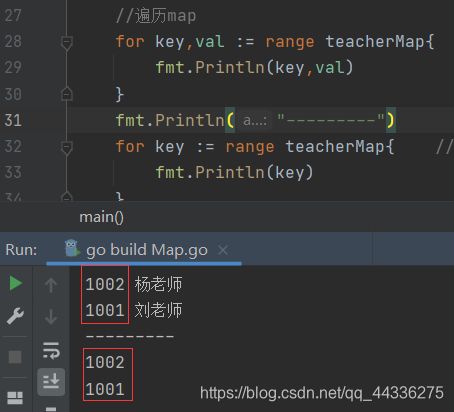
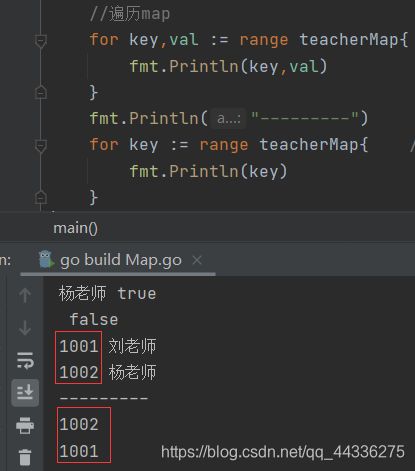
//遍历map
for key,val := range teacherMap{ //在for range中可以获取每次迭代的key和val 也可以省略val只获取key
fmt.Println(key,val)
}
fmt.Println("---------")
for key := range teacherMap{ //在for range中可以获取每次迭代的key和val 也可以省略val只获取key
fmt.Println(key)
}
注意:
map的遍历是无序的,并不会保证每次遍历的元素的顺序。
删除元素
delete(mapName,key)
小例题:英文单词词频统计
//统计一个字符串中单词的数量
prase :="how do you do"
//首先按照空格进行分割
wordSlice := strings.Fields(prase)
wordSlice2 := strings.Split(prase," ")
fmt.Println(wordSlice2)
//创建map
wordMap := make(map[string]int,100)
for _,val :=range wordSlice{
if _,exist:=(wordMap[val]); exist {
wordMap[val] +=1
}else{
wordMap[val] = 1
}
}
fmt.Println(wordMap)
七、常用标准库中的一些经典用法(不断更新)
- strings对象中的几个常用方法:
str:="XabcdXefgXhijkXXX"
//按照指定的sep分割,两个sep之间的空字符串也会被返回
fmt.Println(strings.Split(str,"X"))
//按照sep分割,但是返回的结果中不会剔除这个sep子串,
//例如,在Split(“xabcx”,x)中返回 {"","abc",""}
//在SplitAfter(“xabcx”,x)中返回 {"x","abcx",""}
fmt.Println(strings.SplitAfter(str,"X"))
//在SplitAfter的基础上,限制返回slice的长度,即整体分割成n段,
//如果已经划分出了前n-1段,那么字符串后续的内容直接当作最后一段,
//如果n大于SplitAfter结果的子串数量,那此时SplitAfterN与SplitAfter无异
fmt.Println(strings.SplitAfterN(str,"X",5))
//字符串切片拼成字符串并加入分隔符
strings.Join(slice1,"---任意分隔符---")
- 字符串转换
字符串与整数之间的转换:
string转成int:
int, err := strconv.Atoi(string)
string转成int64:
int64, err := strconv.ParseInt(string, 10, 64)
int转成string:
string := strconv.Itoa(int)
int64转成string:
string := strconv.FormatInt(int64,10)
- 对数组/切片排序
//对整形数组/切片排序
sort.Ints(a []int)
//对字符串数组/切片排序
sort.Strings(a []string)
- 随机数
//产生一个[0,n)的随机整数
random.Intn(n int)
遇到的问题
- 如果想实现类似【泛型】的效果,封装一个能够返回任意指定类型对象的query方法要怎么做呢?
- 如果一个函数需要返回一个结构体类型例如User,当需要返回“null”时,在golang中一般是如何写的呢?
- 包的循环引用问题,实际工程中的分包结构是怎么样的?

不断学习中,后续慢慢填坑吧:)