大数据从入门到精通(超详细版)之 Hive的配置与基本语法
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
大数据从入门到精通文章体系!!!!!!!!!!!!!!
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!
文章目录
- 前言
- 知识回顾
- 交互式命令与非交互式命令
-
- 交互式命令
- 非交互式命令之传入sql语句
- 非交互式命令之传入sql文件
- Hive的参数配置方式
-
- 配置文件的方式
- 交互式命令行的方式
- 交互式界面的方式
- 配置的优先级
- Hive的常见配置
-
- 命令行的展示界面配置
- Hive运行日志配置
- Hive的JVM内存堆进行配置
- **关闭** Hadoop 虚拟内存检查
- Hive的基本语法
-
- DDL(库相关)
-
- 创建数据库
- 查看数据库
- 修改数据库
- 删除数据库
- DDL(表相关)
-
- 创建表(普通语法)
- CTAS建表
- Create Table Like建表
- 重要知识补充

知识回顾
Hive 是一个基于 Hadoop 的数据仓库基础架构,它提供了类似于 SQL 的查询语言用于分析和处理大规模的结构化数据。Hive 的设计目标是使非技术人员能够轻松地使用 SQL 进行数据分析,而无需编写复杂的 MapReduce 代码。
以下是 Hive 的一些主要特点和功能:
- 数据仓库架构:Hive 使用数据仓库架构来管理和处理大规模数据集。它支持常见的关系型数据库概念,如表、列、分区和分桶,以及丰富的数据类型。
- SQL-like 查询语言:Hive 提供了一个类似于 SQL 的查询语言,称为 HiveQL(HQL)。用户可以使用类似于传统数据库的 SQL 语法进行数据查询、过滤、聚合等操作。
- 可扩展性:Hive 建立在 Hadoop 分布式计算框架之上,能够有效地处理大规模的数据集。它能够利用 Hadoop 的并行计算能力,实现高度可扩展的数据处理。
- 高容错性:Hadoop 提供了容错机制,因此 Hive 能够处理大规模数据时发生故障或节点失效的情况。它具备自动故障恢复和数据冗余的特性。
- 数据存储和压缩:Hive 支持多种数据存储格式,包括文本文件、序列文件、Avro、Parquet 等。此外,它还支持数据压缩,可以减少存储空间和提高查询性能。
- 扩展性和可定制性:Hive 提供了丰富的内置函数和扩展接口,允许用户编写自定义的函数、转换器和优化器,以满足特定的数据处理需求。
Hive 被广泛用于大规模数据处理、数据仓库、ETL(Extract、Transform、Load)等场景。它可以与其他 Hadoop 生态系统工具(如 HBase、Spark)和常见的可视化工具(如 Tableau、Superset)集成,提供更全面的数据分析解决方案。
以上就是之前文章的一个简单回顾。
在当前文章当中 , 主要介绍了Hive的一些参数配置, 日志配置以及JVM和其他优化 , 后续又介绍了Hive的操作语句和表的操作语句.
下面开始正文 :
文章目录
- 前言
- 知识回顾
- 交互式命令与非交互式命令
-
- 交互式命令
- 非交互式命令之传入sql语句
- 非交互式命令之传入sql文件
- Hive的参数配置方式
-
- 配置文件的方式
- 交互式命令行的方式
- 交互式界面的方式
- 配置的优先级
- Hive的常见配置
-
- 命令行的展示界面配置
- Hive运行日志配置
- Hive的JVM内存堆进行配置
- **关闭** Hadoop 虚拟内存检查
- Hive的基本语法
-
- DDL(库相关)
-
- 创建数据库
- 查看数据库
- 修改数据库
- 删除数据库
- DDL(表相关)
-
- 创建表(普通语法)
- CTAS建表
- Create Table Like建表
- 重要知识补充
交互式命令与非交互式命令
交互式命令
由bin/hive命令行进入的hive shell一条指令一条指令的操作的方式就是交互式操作方式
bin/hive
这种方式比较适用于实时操作 , 交互性较强
非交互式命令之传入sql语句
由bin/hive命令加上参数的方式操作hive , 就是非交互式命令
bin/hive -e "select * from student"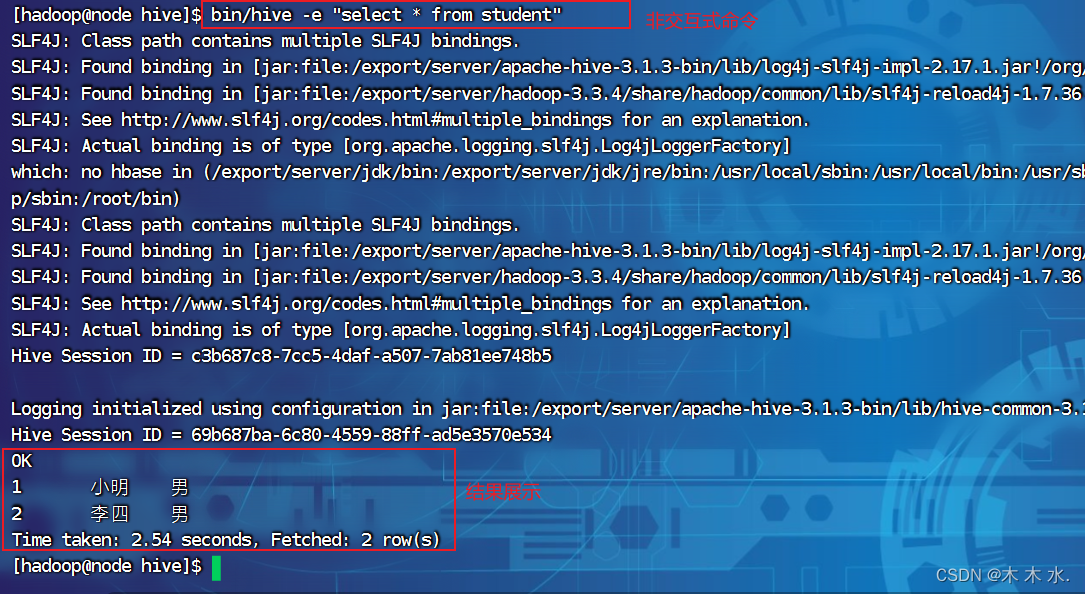

这种方式是不进入hive shell的操作界面, 就可以直接进行操作的方式, 适用于离线数仓的场景
非交互式命令之传入sql文件
mkdir test
vim test.sql
insert into student valeus(3,'王五','男');
bin/hive -f test.sql
这种方式就是直接从文件中加载sql命令 , 可以达到与sql语句一样的效果
Hive的参数配置方式
配置文件的方式
在配置文件当中 , hive-default.xml文件会被源码忽略掉, 而采用hive-site.xml这个配置文件进行默认配置
交互式命令行的方式
bin/hive -hiveconf mapreduce.job.reduces=10
以上参数配置是为了调整mapreduce的个数使用的, 这种配置只能本次使用, 下一次退出客户端时就不会生效
交互式界面的方式
#设置mapreduce的值
set mapreduce.job.reduces=10;
#查看mapreduce的值
set mapreduce.job.reduces;
配置的优先级
配置文件 < 命令行参数 < 界面参数声明
Hive的常见配置
命令行的展示界面配置
此处小题一嘴 : Hive的命令行操作界面可能在后续版本移除 , 只保留beeline的方式操作Hive , 但是大家仍然要抓紧学习, 知道的东西多一点不一定是坏事.
为了展示直观, 我们通常需要显示hive的当前选择的数据库和查询表中的字段名
这是没有对其进行配置的界面, 页面的展示数据过少
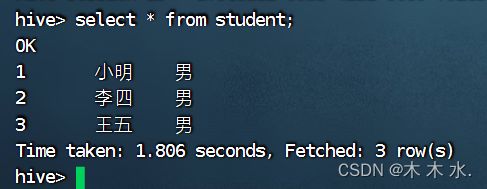
下面更改其配置 :
vim hive-site.xml
然后在文件当中插入以下的配置
<property>
<name>hive.cli.print.headername>
<value>truevalue>
<description>展示字段名description>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
<description>展示当前的数据库名description>
property>
再次连接客户端 , 即可看见配置的效果 , 已经可以展示库名和字段名了

Hive运行日志配置
Hive的日志文件在hive-exec-log4j2.properties.template文件当中 , 需要先将其改名为hive-exec-log4j2.properties
mv hive-exec-log4j2.properties.template hive-exec-log4j2.properties
#文件当中关于日志文件路径的配置
# list of propertiessh
property.hive.log.level = INFO
property.hive.root.logger = FA
property.hive.query.id = hadoop
#这就是默认存放的路径,默认在/tmp/[启动hive的用户] 需要的话在此修改其配置
property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}
#默认的文件名
property.hive.log.file = ${sys:hive.query.id}.logsh
我们可以验证一下日志文件的位置
#当前我的hive就是以hadoop用户启动的
cd /tmp/hadoop
ll -l

可以看到日志文件就在其配置文件夹当中的位置中存储, 如果需要修改的话, 可以对property.hive.log.dir此文件进行修改
Hive的JVM内存堆进行配置
Hive 使用 JVM 来执行查询和处理大规模数据,因此 JVM 内存堆对于 Hive 的性能和稳定性非常重要。
Hive 的 JVM 内存堆可以通过以下两个参数进行配置:
-
hive.heapsize:该参数用于指定 JVM 内存堆的总大小。它定义了 Hive 在执行查询时可以使用的最大内存量。
默认申请的 JVM 堆内存大小为 256M,JVM 堆内存申请的太小 , 导致后期开启本地模式 ,执行复杂的SQL时经常会报错 :
java.lang.OutOfMemoryError: Java heap space,因此最好提前调整一下 HADOOP_HEAPSIZE 这个参数 。刚刚有提到本地模式 , 下面我会详细讲解一下Hive的本地模式.
跳转到Hive的本地模式介绍
#修改hive-env.sh的内容 export HADOOP_HEAPSIZE=2048 -
hive.server2.heapsize:该参数用于指定 Hive Server2 进程的 JVM 内存堆大小。Hive Server2 是 Hive 的服务器组件,用于提供远程查询服务。默认情况下,该参数的值为 1024MB。
通常情况下,可以根据系统的资源和负载情况来调整这两个参数的值。如果系统中有多个用户同时执行查询,并且有较大的数据集需要处理,那么增加 JVM 内存堆的大小可能是一个好的选择,以提高查询的性能和并发处理能力。但是,如果内存资源有限或者系统负载较高,增加内存堆的大小可能会导致内存压力或竞争,影响系统的稳定性和性能。
关闭 Hadoop 虚拟内存检查
**Hadoop 通过虚拟内存检查来控制和监控任务的资源使用情况,以防止任务由于过度使用内存而导致系统崩溃或执行时间过长。**虚拟内存检查主要包括以下几个方面:
- MapReduce 任务的虚拟内存限制:Hadoop 允许为每个任务设置虚拟内存限制。该限制指定了任务可以使用的最大虚拟内存量。一旦任务超过这个限制,Hadoop 将终止任务并标记为失败。
- MapReduce 任务的物理内存检查:除了虚拟内存外,Hadoop 还会检查任务使用的实际物理内存。如果任务使用的物理内存超出了预定义的阈值,则任务可能被终止。
- 虚拟内存与物理内存的比例检查:Hadoop 还提供了一个配置选项,允许您设置虚拟内存与物理内存之间的比例限制。默认情况下,虚拟内存可以是物理内存的倍数。如果某个任务的虚拟内存超过该比例限制,Hadoop 可能会终止该任务。
这些虚拟内存检查措施有助于避免 Hadoop 集群中的任务过度使用内存而导致资源耗尽或系统不稳定。通过适当地配置虚拟内存限制和比例限制,可以平衡任务执行的资源需求和集群的整体性能。
注意 , 虚拟内存检查仅仅是一种资源管理和保护机制,并不一定意味着任务使用虚拟内存就一定是错误的。**在某些情况下,可能需要根据具体的应用场景和需求来调整虚拟内存限制,以达到最佳的性能和资源利用率。
本操作主要关闭Yarn的虚拟内存检查 , 对Yarn不熟悉的同学可以看下之前对Yarn的的文章 , 以及接下来对Yarn的知识补充
Yarn的使用,安装与部署
点击跳转到Yarn的虚拟内存
实际上我们就是控制Yarn当中Container的资源 , Yarn会默认轮询每个Container是否超过了资源限制, 如果超过了就会kill掉 , 如果我们关闭掉虚拟内存的检查 , 那么默认就会直接检查我们的物理内存
首先关闭Hadoop
stop-hadoop.sh
再到yarn-site.xml文件当中 , 添加以下配置
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
再使用scp分发yarn-site.xml, 重启yarn即可
Hive的基本语法
接下来为了方便操作, 我们使用上一篇文章当中介绍的Beneline方式使用DataGrip客户端进行操作
DDL(库相关)
创建数据库
先进行数据库的操作
语法 :
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT '注释'] #可选 , 设置注释
[LOCATION hdfs_path] #可选 , 设置新建的数据库在hdfs当中的存储路径
[WITH DBPROPERTIES] #可选 ,
若不指定路径LOCATION,其默认路径为${hive.metastore.warehouse.dir}/database_name.db
create database studyHard;
此时没有指定路径, 那么默认在hdfs当中的存储路径应该为 : /user/hive/warehouse , 我们打开Hdfs的Web界面可以进行验证

现在我们测试指定创建存储路径的创建方式
create database studyHard1 location '/studyHard1';
按照sql语句, studyHard1库应该存在于根目录下的/studyHard1当中

这下来是带初始键值对的创建库的方式sql
create database studyHard2 with dbproperties ('date'='2023-09-02');
这个dbproperties需要查看特定的查看数据库的方式才能查看 , 我们下面来详细的介绍
查看数据库
语法:
SHOW DATABASES [LIKE '通配符表达式']
like通配符表达式有两种 : * 表示任意个任意字符 , | 表示或的关系
下面我们来测试这两种方式 :
show databases like 'stu*';
这句是sql是查看所有以stu开头的库名称

下面我们来测序查看数据库的详细信息
这是语法, 使用DESCRIBE关键字即可
DESCRIBE DATABASE [EXTENDED] db_name
我们先查看刚刚创建的studyHard库
DESC DATABASE studyHard
以下图片就是查看结果, 可以看到可以战术名称 , 注释, hdfs的存储位置 , 创建的用户 , 用户的类型 等等
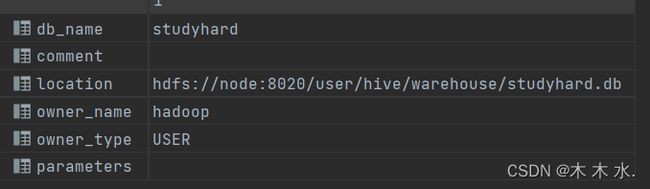
还记得刚刚创建表的时候带有了dbproperties吗 , 想要查询它就需要EXTENDED扩展选项
DESCRIBE DATABASE EXTENDED studyHard2
可以看到, 我们刚刚指定的dbproperties的值已经能够查询出来了.

修改数据库
用户可以使用 alter database 命令修改数据库的某些信息 , 其中能修改的信息包括 dbproperties , location , owner user .
注意, 这里的修改数据库的location , 不会修改当前已有的表路径信息 , 而是修改后续创建表的默认的父目录.
语法 :
--修改dbproperties
ALTER DATABASE database_name SET DBPROPERTIES (property_name=property_value, ...) ;
--修改location
ALTER DATABASE database_name SET LOCATION hdfs_path ;
--修改owner user
ALTER DATABASE database_name SET LOCATION OWNER USER user_name ;
这个语法比较简单, 这里对DBPROPERTIES进行测试
ALTER DATABASE studyHard2 SET DBPROPERTIES ('Alter date'='2023-09-02','date'='YYYY-mm-dd');
这段sql语句会覆盖修改原有的date , 同时也会新增新的Alter date;

删除数据库
删除数据库是生产环境当中需要谨慎使用的命令 , 慎用!!!
语法 :
DROP DATABASE [IF EXITSTS] database_name [RESTRICT | CASCADE];
RESTRICT 严格模式 , 若数据库不为空, 则会删除失败 , 默认就是该模式 , 算是一个保护性的涉及
CASCADE 级联模式 , 若数据库不为空 , 则会将库中的表一并删除
这里就不对其进行演示了, 这种删除库的操作一定要慎重!!!
DDL(表相关)
创建表(普通语法)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS]
[db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]hive
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
可以看到可以选择的关键字其实挺多的 , 我们这里逐步介绍每个关键字的作用
-
TEMPORARY临时表 :该表只在当前会话可见,会话结束,表会被删除。
-
EXTERNAL外部表 :外部表,与之相对应的是内部表(管理表)。管理表意味着 Hive 会完全接管该表,包括元数据和 HDFS 中的数据。而外部表则意味着 Hive 只接管元数据,而不完全接管 HDFS中的数据。
内部表和外部表的区别注意体现在删除表的时候 :
当删除内部表时 : 元数据和HDFS当中的数据会被一并删除
但删除外部表时 : 元数据的数据才会被删除 , HDFS当中的数据一定不会被删除
-
data_type数据类型 :Hive 中的字段类型可分为基本数据类型和复杂数据类型
基本数据类型 :
Hive 说明 定义格式 tinyint 1byte有符号整数 smallint 2byte有符号整数 int 4byte有符号整数 bigint 8byte有符号整数 boolean 布尔类型,true或者false float 单精度浮点数 double 双精度浮点数 decimal 十进制精准数字类型 decimal(16,2) varchar 字符序列,需指定最大长度,最大长度的范围是[1,65535] varchar(32) string 字符串,无需指定最大长度 timestamp 时间类型 binary 二进制数据 复杂数据类型
类型 说明 定义 取值 array 数组是一组相同类型的值的集合 array arr[0] map map是一组相同类型的键-值对集合 map map[‘key’] struct 结构体由多个属性组成,每个属性都有自己的属性名和数据类型 struct struct.id Hive的基本数据类型可以做类型转换 , 转换的方式包括隐式转换和显示转换 . 可以通过知识补充查看隐式转换和显示转换的具体介绍.
跳转到Hive的隐式转换与显示转换
-
ROW FORMAT
SERDE就是Hive的序列化与反序列化过程 , 英文名为 : “Serializer and Deserializer”
在知识补充里面有对它的介绍 : 点击跳转到 : Hive的序列化与反序列化
指定 SERDE,SERDE 是 Serializer and Deserializer 的简写。Hive 使用 SERDE 序列化和反序列化每行数据。语法说明如下:
**语法一:**DELIMITED 关键字表示对文件中的每个字段按照特定分割符进行分割,其会使用默认的 SERDE 对每行数据进行序列化和反序列化。
ROW FORAMT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char]注:
fields terminated by :列分隔符
collection items terminated by : map、struct 和 array 中每个元素之间的分隔符
map keys terminated by :map 中的 key 与 value 的分隔符
lines terminated by :行分隔符
**语法二:**SERDE 关键字可用于指定其他内置的 SERDE 或者用户自定义的 SERDE。例如 JSON
SERDE,可用于处理 JSON 字符串。
ROW FORMAT SERDE serde_name [WITH SERDEPROPERTIES] (property_name=property_value,property_name=property_value, ...)] -
PARTITIONED BY
创建分区表 , 这个分区概念以后会重点介绍
-
CLUSTERED BY … SORTED BY…INTO … BUCKETS
创建分桶表, 这个分桶概念也会在后续详细介绍
-
STORED AS
指定文件格式,就是这张表所对应的HDFS的文件格式 ,常用的文件格式有,textfile(默认值),sequence file,orc file、parquet file等等。
-
LOCATION
指定表所对应的HDFS路径,若不指定路径,其默认值为
${hive.metastore.warehouse.dir}/db_name.db/table_name , 其实就是默认存储在库的路径下
CTAS建表
CTAS 就是 Create Table As Select
该语法允许用户利用select查询语句返回的结果,直接建表,表的结构和查询语句的结构保持一致,且保证包含select查询语句放回的内容。
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
Create Table Like建表
该语法允许用户复刻一张已经存在的表结构,与上述的CTAS语法不同,该语法创建出来的表中不包含数据。
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[LIKE exist_table_name]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
以上就是本文的的全部内容了 , 主要介绍了Hive的一些参数配置以及JVM和其他优化 , 后续有介绍了Hive的操作语句和表的操作语句.
在接下来的文章中我将会介绍Hive的详细表操作案例和详细的数据操作案例, 敬请期待吧~
重要知识补充
Hive的本地模式是一种执行模式,适用于小数据集的查询。在本地模式下,Hive的查询将在单个节点上执行,而不需要分布到大型的Hadoop集群中。这使得查询更加快速,因为数据和计算都在同一台机器上进行。
本地模式的配置方法是设置Hive的配置参数hive.exec.mode.local.auto为true,这将使Hive自动选择在本地模式执行查询。然而,这种模式只能运行一个reducer,因此对于处理大型数据集可能会非常慢。
注意,本地模式的限制在于它可能无法处理多个用户的并发操作,因为每个操作都可能在不同的JVM中运行,导致数据不一致的情况。因此,在处理多个用户操作同一张表时,需要特别注意。
以下图片是对分布式计算引擎的直观概括 :


Yarn的虚拟内存主要通过设置container的内存大小来实现。每个container被分配一定量的虚拟内存,这使得Yarn可以更好地管理内存资源,避免内存消耗过多或者过少的问题。
在启动Yarn时,可以通过调整一些配置参数来调节虚拟内存率或者应用运行时调节内存大小。比如,可以在Yarn的配置文件(yarn-site.xml)中设置yarn.nodemanager.vmem-pmem-ratio参数来调节虚拟内存与物理内存的比例。
此外,Yarn的虚拟内存管理也体现在它如何处理不同类型的应用任务上。例如,对于Map Task和Reduce Task,Yarn会根据预设的虚拟内存比例,为它们分配不同的虚拟内存量。如果应用的虚拟内存需求超过了预设的数值,Yarn会报错并拒绝执行任务。
为了解决这种错误情况,可以在启动Yarn时调整虚拟内存率或者在应用运行时调节内存大小。另外,也可以考虑优化应用的内存使用,例如通过减少不必要的内存占用或者优化数据结构等方式。
隐式转换和显示转换的转换规则其实和Java中的转换极其相似
隐式转换 :
- 任何整数类型都可以隐式地转换为一个范围更广的类型,如tinyint可以转换成int,int可以转换成bigint。
- 所有整数类型、float和string类型都可以隐式地转换成double。
- tinyint、smallint、int都可以转换为float。
- boolean类型不可以转换为任何其它的类型。
显示转换 :
可以借助cast函数完成显示的类型转换
a.语法
cast(expr as )
b.案例
hive (default)> select '1' + 2, cast('1' as int) + 2;
Hive支持多种数据存储的格式,序列化/反序列化只是其中的一种格式。在Hive中,序列化是对象转化为字节序列的过程,而反序列化则是将字节序列恢复为对象的过程。
序列化的主要作用有两个:一是实现对象的持久化,即将对象转换为字节序列并保存到文件;二是实现对象数据的传输,即在网络上发送对象数据。
反序列化的主要作用则是在Hive加载数据到表中时,将
在Hive中创建表时,可以通过自定义的SerDe或使用Hive内置的SerDe类型来指定数据的序列化和反序列化方式。
HDFS与Hive之间的转换过程
成double。
3. tinyint、smallint、int都可以转换为float。
4. boolean类型不可以转换为任何其它的类型。
显示转换 :
可以借助cast函数完成显示的类型转换
a.语法
cast(expr as )
b.案例
hive (default)> select '1' + 2, cast('1' as int) + 2;
Hive支持多种数据存储的格式,序列化/反序列化只是其中的一种格式。在Hive中,序列化是对象转化为字节序列的过程,而反序列化则是将字节序列恢复为对象的过程。
序列化的主要作用有两个:一是实现对象的持久化,即将对象转换为字节序列并保存到文件;二是实现对象数据的传输,即在网络上发送对象数据。
反序列化的主要作用则是在Hive加载数据到表中时,将
在Hive中创建表时,可以通过自定义的SerDe或使用Hive内置的SerDe类型来指定数据的序列化和反序列化方式。
HDFS与Hive之间的转换过程
