初识Elasticsearch
简介
Elasticsearch 故名思议,Elastic Search 一个分布式搜索中间件。据说是创始人给妻子开发搜索食谱的应用时,顺手做的中间件。果然,爱情的力量是伟大的,否则也不会有至今广受使用的 Elasticsearch 了。
分布式、高性能、近实时是 Elasticsearch 的特点。它可以对几乎所有类型的数据(基本值类型、地理空间、IP 等)进行搜索,这依赖于针对不同的类型建立合适的索引结构,后面的系列我们将详细分析索引部分,本次我们分析 Elasticsearch 的系统概念与读写流程。
平时我们通常把 Elasticsearch 称为 ES。
集群 Cluster
作为一个分布式系统,肯定是需要由多个 ES 实例节点组成集群的。集群需要被管理,ES 中通过 master 来管理集群。集群为了保障高可用,避免单点故障,master 是经过选举选出来的。ES 中,并不是所有的节点都能作为 master 的候选者。
ES 中,一个实例节点也是可以自成集群的
如下图,是一个 常见的ES 集群架构图:
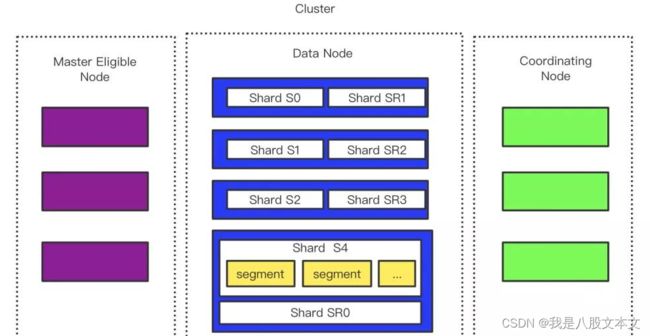
节点 Node
单个 ES 实例,既称为一个节点。ES 中节点可以有以下一个或多个角色:
候选主节点-Master Eligible Node
用来选主,只有候选主节点才有选举权和被选举权,其它节点不参与选主。
选举出的主节点负责创建索引、删除索引、跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点、追踪集群中节点的状态等,稳定的主节点对集群的健康是非常重要的。
通常,为了稳定性,最好使用低配置机器创建独立的候选主节点,且不小于3个。
数据节点-Date Node
负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作,所以数据节点(Data 节点)对机器配置要求比较高,对 CPU、内存和 I/O 的消耗很大。
数据节点是集群中压力很大的节点,最好将数据节点和主节点分开,以免影响主节点稳定性,导致脑裂,造成索引、数据不一致等。
1、使用 SSD ,提升磁盘读写能力
2、除了 JVM heap 本身使用的内存外,预留一定的内存给文件缓存,能加快文件访问,避免每次都要访问磁盘
3、禁用 swap 机制
协调节点-Coordinating Node
一般来说,每个节点都可承担协调节点的角色。通常,哪个节点接收客户端请求,就是本次请求的协调节点。协调节点用来处理客户端请求,进行请求分发,结果合并,并返回给客户端。
协调节点的压力介于主节点和数据节点之间,不需要很高的 io 能力。将协调节点独立,有助于降低数据节点的压力,避免互相影响。
ES 集群除了可以有以上常见节点角色外,还有:Ingest node、Remote-eligible node、Machine learning node、Transform node ,感兴趣的可以取官网了解,本文就不一一介绍了。
分片 Shard
一个 data 节点可包含多个 shard 。一个 shard 就是一个 Lucene 实例,索引由一系列 shard 组成。ES 之所以称作分布式搜索,既是可以将数据分散在多个 shard 上,提供更高的性能。
因为写入时,需要通过路由,确定写在哪一个 shard 上,所以需要在索引创建时,确定好 shard 数,一旦设置后将不可变。
副本分片 Replica Shard
一个主 shard 可以有0个或多个副本 shard。默认每个主 shard 都有一个副本 shard,副本 shard 永远不会和主 shard 在同一节点上。主要作用:
1、故障转移:当主 shard 出现故障时,可以将副本 shard 提升为主 shard。
2、提高性能:get、search 请求可以交给主 shard 或副本 shard 处理。
Lucene
Lucene 是一个全文检索库,ES 基于 lucene 来建立。一个 lucene 索引里有很多个 segemnt,每个 segment 都是一个索引结构。在搜索时,会搜索所有的 segment。segment 内部会构建倒排索引,用来检索。
segment 不可变,所以:
1、当文档删除时:lucene 将文档额外标记为删除
2、当更新时:先删除,再插入(新的 segmeng )
写入
当协调节点收到写请求后,通过 routing 找到对应的主 shard,将写请求转发给主 shard,主 shard 写完之后,将写入并发发送给副本 shard,待副本 shard 写入后,返回给主 shard,当所有副本 shard 写完后,主 shard 返回请求给协调节点。
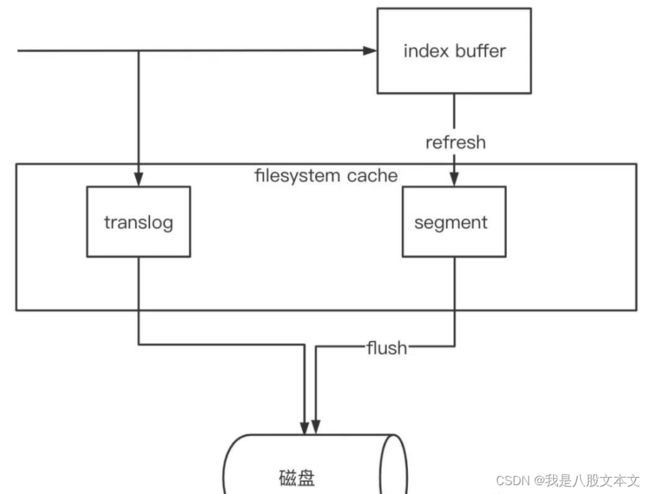
当节点接收到写入请求时,先将数据写入到 index buffer 之中,此时,写入的数据还不能被搜索到,直到数据被 refresh 机制(默认1秒)刷到文件系统缓存,形成不可变的 segment 小索引,此时才能被搜索(近实时搜索)。数据被 refresh 之后,是写入到文件缓存的,并不会立刻持久化到磁盘,而是通过 flush 机制刷到磁盘。
数据写入到 index buffer 中的同时,还会写入到 translog,防止数据丢失。translog 默认5秒会 fsync 到磁盘,所以理论上5秒之内写入的数据,还是有丢失的可能。translog 并不会无限增大,当数据 flush 到磁盘后,translog 就可以进行清理了。
segment flush 时机:
1、5分钟内没有对索引的请求
2、translog 到达一定大小,默认 512m
3、调用 flush api
针对整个集群 flush
curl -XPOST "http://127.0.0.1:9200/_flush/synced"
针对单个索引 flush
curl -XPOST "http://127.0.0.1:9200/demo/_flush/synced"
每秒生成一个 segment 会导致文件数量很多,同时造成搜索响应变慢,所以 ES 内部会不定期自动对 segment 进行合并,老的 segment 将删除并释放资源。当然也可以在 ES 压力不大时,进行手动强制合并。
curl -X POST "http://127.0.0.1:9200/demo/_forcemerge"
搜索
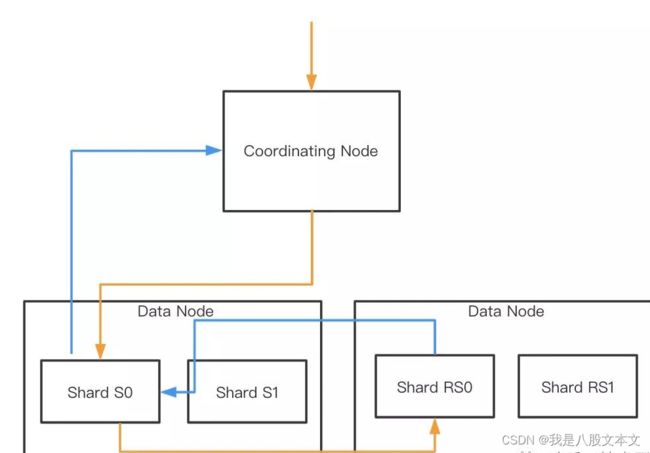
当搜索请求到达第一个节点时,其将作为协调节点,负责处理请求。处理流程如图:

如果是分页搜索:假设客户端请求 from = 50,size = 50;协调节点发送给每个 shard 的请求 from = 0,size = from + size = 100;协调节点收到的数据量为 shard 数 * ( from + size ) ;最后再择出分页数据,fetch 得到要获取的数据返回。
基于以上流程,ES 为了避免深度分页对系统的影响,默认对分页有1万条限制的。那怎么解决呢?
1、修改 index. max_result_window 调大限制,可动态设置
curl -XPUT "http://127.0.0.1:9200/demo/_settings" -H 'Content-Type: application/json' -d'
{
"index.max_result_window": "1000000"
}'
2、Scroll
第一次查询时带上 scroll 参数代表是 scroll 查询,同时设置 scroll 上下文的过期时间:
curl -XGET "http://127.0.0.1:9200/demo/_search?scroll=10s" -H 'Content-Type: application/json' -d'
{
"size": 20,
"query": {
"match_all": {}
}
}'
返回 _scroll_id:
{
"_scroll_id": "i1BOVdVWjJyU...",
... //省略
}
后续查询将上次返回的 _scroll_id 作为参数:
curl -XGETY "http://127.0.0.1:9200/_search/scroll" -H 'Content-Type: application/json' -d'
{
"scroll" : "10s",
"scroll_id" : "i1BOVdVWjJyU..."
}'
scroll 需要在 ES 服务端持续维持一个快照上下文,持有 segment 。此时 segment 合并仍可继续,但却不能删除老的 segment 释放资源。直到过期或者手动清理:
curl -XDELETE "http://127.0.0.1:9200/_search/scroll" -H 'Content-Type: application/json' -d'
{
"scroll_id" : "i1BOVdVWjJyU..."
}'
当遍历大量数据时,可通过 slice scroll 加快速度
3、Search After
curl -XGET "http://127.0.0.1:9200/demo/_search" -H 'Content-Type: application/json' -d'
{
"from": 0,//from 永远从0开始
"size": 10,
"query": {
"match_all": {}
},
"search_after": [ //初次不传,后续使用上次最后元素的排序值作为参数
674688494483205
],
"sort": [
{
"_id": { //稳定排序,建议最后排序字段用 _id
"order": "desc"
}
}
]
}'
需要设置排序字段,并且是稳定排序,通常最后排序字段是 _id。记录上页最后元素的排序值,作为下次的查询条件。相比 scroll 是服务端无状态的,不占用 ES 资源。