多线程爬取pear video
参考教程:
KP:
- 在python中,在函数内部修改全局变量值的方法:在函数内部另外声明global 全局变量名(
global i,这样就可以修改全局变量i的值) - 什么是二次渲染? CSS二次渲染是当浏览器能够正确显示内容,但在渲染图像之前会重新计算样式,并重新绘制元素。这意味着你的页面可能会闪烁并在用户体验上产生短暂的延迟。这种情况通常发生在使用内联样式和在样式表中添加!important声明的时候。在本案例中,就是视频.mp4文件并没有加载,而是在点击视频后才加载出来。
以此视频链接为例
获取视频真正url
-
在没有点击视频播放前,在源码中找不到mp4文件。

点击播放视频后,才可以找到真正的视频文件:
此src文件才是真正的视频文件。
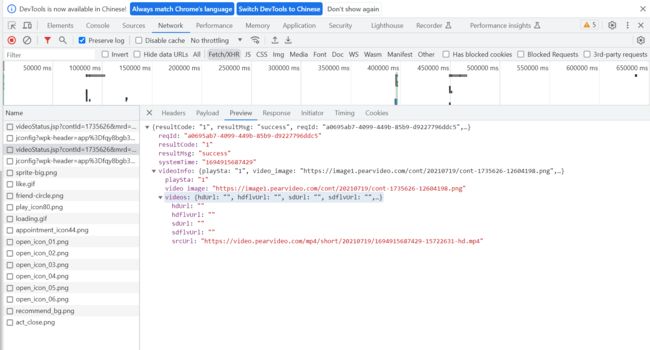
通过抓包工具也可以得到一个srcUrl。但是这个得到的并不是真正能播放的视频链接。
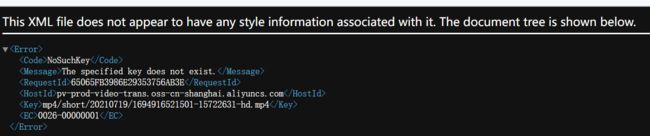
FAKE: https://video.pearvideo.com/mp4/short/20210719/1694916521501-15722631-hd.mp4
REAL: src="https://video.pearvideo.com/mp4/short/20210719/cont-1735626-15722631-hd.mp4">
通过对比这两个链接:发现是将FAKE中的1694916521501换成cont-1735626。
而这个是systemTime
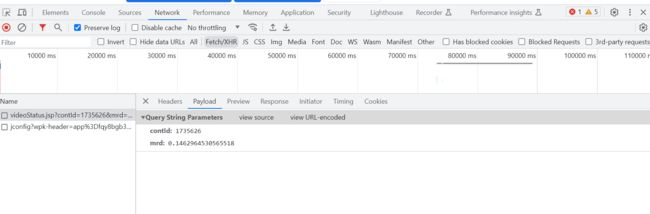
从上面这张图中看出cont-后面的为contid。本视频详情页的链接为https://www.pearvideo.com/video_1735626,所以可以通过此链接得到contid。
再将取到的contid替换system就可以得到真正的视频链接,从而下载。
注意!梨视频加载了防盗链,在获取真正的视频下载链接时,必须在请求的UA伪装中添加Referer防盗链,Referer的值为前一个页面的链接,即视频详情页的链接。如果不添加则无法爬取。
headers_video = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
"Referer": f"https://www.pearvideo.com/video_{contID}"
}
所以大体步骤为:
- 通过梨视频页面得到要下载的视频的详情页信息。
- 从详情页信息中获取FAKE视频链接
- 将FAKE视频链接转为REAL视频链接。
- 使用多线程进行下载。
1.通过梨视频页面得到要下载的视频的详情页信息。
url = 'https://www.pearvideo.com/category_1'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
# with open('./lishipin.html', 'w', encoding='utf-8') as fp:
# fp.write(page_text)
# 获取video_name , video_url
video_list = tree.xpath('//*[@id="listvideoListUl"]//div[@class="vervideo-bd"]/a/@href')
video_name_list = tree.xpath('//div[@class="category-top"]//div[@class="vervideo-title"]/text()') #
video_list = ["https://www.pearvideo.com/" + video for video in video_list]
print(video_list)
print(video_name_list)
2. 从详情页信息中获取FAKE视频链接
# 获取视频的真正下载链接
video_download_url = []
for i in range(len(video_list)):
contID = video_list[i].split('_')[1]
mrd = random.random()
video_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=" + str(mrd) # 实测没有mrd相关信息也可以解析。
headers_video = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
"Referer": f"https://www.pearvideo.com/video_{contID}"
}
video_response = requests.get(video_url, headers=headers_video) # 得到视频详情页的response
print(video_response.text)
# 将文件写入磁盘
fp = open(f'./{contID}.json', 'w', encoding='utf-8')
json.dump(video_response.json(), fp, ensure_ascii=False)
3. 将FAKE视频链接转为REAL视频链接。
这里注意,将video_response转为json格式后,可以直接使用字典的操作获取某键对应的值。
# 将fake的url转为真正的url
systemTime = video_response.json()['systemTime']
srcUrl = video_response.json()['videoInfo']['videos']['srcUrl']
srcUrl = srcUrl.replace(systemTime, f"cont-{contID}")
video_download_url.append(srcUrl)
print(video_download_url)
4. 使用多线程进行下载。
# 使用多线程进行下载
if not os.path.exists('./梨视频'): # 创建视频目录
os.makedirs('./梨视频')
i=0
def download_video(video):
global i # 在函数内修改全局变量:在函数内声明global变量
with open(f'./梨视频/{video_name_list[i]}.mp4', 'wb') as fp:
fp.write(requests.get(video).content)
print(video_name_list[i],"下载成功")
i+=1
# 单线程下载
start_time = time.time()
for video in video_download_url:
download_video(video)
end_time = time.time()
print("单线程下载时间:", end_time - start_time)
# 多线程下载
pool = Pool(len(video_list)) # 获取大小为视频个数的线程池
start_time = time.time()
i=0
pool.map(download_video, video_download_url)
end_time = time.time()
print("多线程下载时间:", end_time - start_time)
完整代码:
import json
import os.path
import random
import time
from multiprocessing.dummy import Pool
import requests
from lxml import etree
url = 'https://www.pearvideo.com/category_1'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
# with open('./lishipin.html', 'w', encoding='utf-8') as fp:
# fp.write(page_text)
# 获取video_name , video_url
video_list = tree.xpath('//*[@id="listvideoListUl"]//div[@class="vervideo-bd"]/a/@href')
video_name_list = tree.xpath('//div[@class="category-top"]//div[@class="vervideo-title"]/text()') #
video_list = ["https://www.pearvideo.com/" + video for video in video_list]
print(video_list)
print(video_name_list)
# 获取视频的真正下载链接
video_download_url = []
for i in range(len(video_list)):
contID = video_list[i].split('_')[1]
mrd = random.random()
video_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=" + str(mrd) # 实测没有mrd相关信息也可以解析。
headers_video = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
"Referer": f"https://www.pearvideo.com/video_{contID}"
}
video_response = requests.get(video_url, headers=headers_video)
print(video_response.text)
# 将文件写入磁盘
fp = open(f'./{contID}.json', 'w', encoding='utf-8')
json.dump(video_response.json(), fp, ensure_ascii=False)
# 将fake的url转为真正的url
systemTime = video_response.json()['systemTime']
srcUrl = video_response.json()['videoInfo']['videos']['srcUrl']
srcUrl = srcUrl.replace(systemTime, f"cont-{contID}")
video_download_url.append(srcUrl)
print(video_download_url)
# 使用多线程进行下载
if not os.path.exists('./梨视频'):
os.makedirs('./梨视频')
i=0
def download_video(video):
global i # 在函数内修改全局变量:在函数内声明global变量
with open(f'./梨视频/{video_name_list[i]}.mp4', 'wb') as fp:
fp.write(requests.get(video).content)
print(video_name_list[i],"下载成功")
i+=1
# 单线程下载
start_time = time.time()
for video in video_download_url:
download_video(video)
end_time = time.time()
print("单线程下载时间:", end_time - start_time)
# 多线程下载
pool = Pool(len(video_list)) # 获取大小为视频个数的线程池
start_time = time.time()
i=0
pool.map(download_video, video_download_url)
end_time = time.time()
print("多线程下载时间:", end_time - start_time)