使用FastChat部署Baichuan2
1. 引言
近来,大型语言模型的市场需求呈现出蓬勃发展的态势。然而,仅仅掌握模型的数据准备和训练是不够的,模型的部署方法也变得至关重要。在这篇文章中,我们将以Baichuan2为例,利用FastChat进行模型部署的实战操作。
2. 提前准备
除了按照FastChat的github给出的安装条件:
还需要安装pytorch:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
以及其他依赖项:
pip install transformers
pip install acclerate
pip install sentencepiece
另外,也请下载好Baichuan2的模型到本地来:
3. 使用方式
3.1 框架代码解读
既然我们都上手使用FastChat了,如果仅仅是直接运行,那基本上5分钟就过了。我们目的是要了解整个FastChat的运行机制,大家喜欢看源码的,可以直接去github上看一下。
FastChat的推理架构还是比较规范的,用的是FastAPI这个非常简洁方便的python框架,整体架构是一个Controller-Worker的架构,可扩展性更强,可以将框架、模型和用户接口分离开,可以说是非常优秀的设计。(在没有FastChat之前,我们也是这样想的构建。)
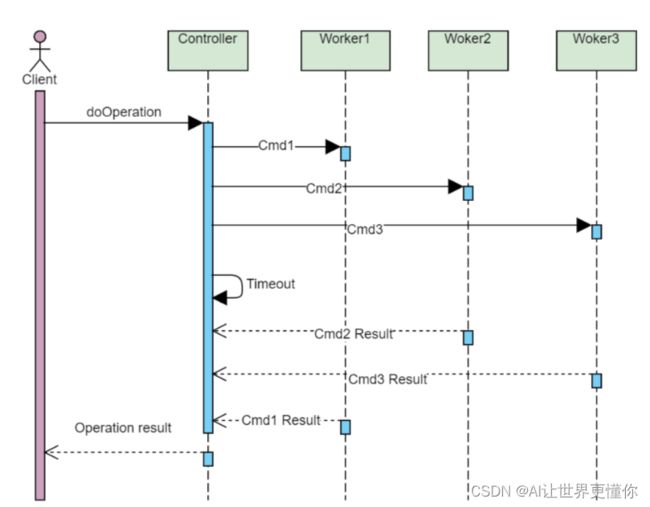
这里借用一个Controller-Worker架构模式图,更容易的展示出整个架构,可以看到在一个程序中,只会有一个Controller用于协调所有worker的工作情况以及与client的交互,因此首先需要将其构建起来,然后就是各个worker的构建,在FastChat中,worker则是模型加载后的实体,它的目的就是将来到的信息进行一个推理,把结果返回给controller。最后粉红色的Client有3种方式可以实现,第一种是最简单的CLI,第二种则是常用的WebGUI, 第三种则是比较高级的API调用。
3.1.1 controller.py解读
整个代码太长,可以看一下源代码。
大致内容如下:
代码中使用了FastAPI框架来搭建Web服务,通过HTTP接口与客户端进行通信。主要的功能模块如下:
DispatchMethod 枚举类定义了两种调度方法:LOTTERY 和 SHORTEST_QUEUE,分别表示抽签法和最短队列法。
WorkerInfo 是一个数据类,用于存储工作节点的相关信息,包括模型名称、速度、队列长度、心跳检测等。
Controller 类是任务调度器的核心类,用于注册和管理工作节点。它包含了注册工作节点、获取工作节点状态、选择工作节点等方法。
heart_beat_controller 函数是一个线程函数,用于定期检测工作节点的心跳信息,并移除超时未发送心跳的节点。
app 是一个 FastAPI 应用实例,定义了各个接口的处理函数。
create_controller 函数用于创建任务调度器的实例,并解析命令行参数。
在 main 部分,通过调用 create_controller 函数创建了一个 Controller 实例,并根据命令行参数选择是否启用 SSL 加密。最后使用 uvicorn 启动了 Web 服务。
3.1.2 model_worker.py解读
整个代码太长,可以看一下源代码。
大致内容如下:
主要功能模块如下:
BaseModelWorker 类是工作节点的基类,定义了一些共用的方法和属性,包括注册到控制器、发送心跳信息等。
ModelWorker 类继承自 BaseModelWorker,是具体的模型工作节点类。它包含了模型加载、生成文本、获取嵌入向量等方法。在初始化时会加载指定的模型,并根据命令行参数进行配置。
heart_beat_worker 函数是一个线程函数,用于定期发送心跳信息给控制器。
app 是一个 FastAPI 应用实例,定义了各个接口的处理函数。
create_background_tasks 函数用于创建后台任务,用于释放工作节点的信号量。
在 main 部分,通过调用 create_model_worker 函数创建了一个 ModelWorker 实例,并解析命令行参数。最后使用 uvicorn 启动了 Web 服务。
3.1.3 两个部分如何配合运行
这两个部分是通过网络通信进行协调工作的。
在代码中,控制器 (controller.py) 和工作节点 (worker.py) 都是通过 HTTP 协议进行通信的。工作节点会向控制器注册自己,并定期发送心跳信息告知控制器自己的状态。控制器可以根据工作节点的状态和负载情况,将任务分配给合适的工作节点。
具体的协调过程如下:
- 工作节点启动后,会调用
register_to_controller方法向控制器注册自己,包括工作节点的名称、心跳检测和当前状态等信息。- 工作节点会定期调用
send_heart_beat方法发送心跳信息给控制器,告知自己的状态。心跳信息中包括工作节点的名称、队列长度等信息。- 控制器会接收到工作节点发送的心跳信息,并根据工作节点的状态和负载情况,决定是否需要重新注册工作节点。
- 控制器可以根据需要向工作节点发送任务请求,包括生成文本任务和获取嵌入向量任务等。
- 工作节点接收到任务请求后,会执行相应的任务,并将结果返回给控制器。
通过这样的协调和通信机制,控制器和工作节点可以相互配合,实现任务的分发和执行。控制器负责调度和管理工作节点,而工作节点负责执行具体的模型任务。
因此,无论是使用那种用户接口,首先都要先启动Controller,然后启动Worker,最后再启动各种Client。
3.2 执行步骤
正如刚才所说的,无论哪一种Client,都需要首先启动controller和worker,遵循下面的指令:
启动controller
python3 -m fastchat.serve.controller
然后我们启动worker:
python3 -m fastchat.serve.model_worker --model-path
3.2.1 使用CLI
CLI全称是command-line interface,意思是命令行交互,一般都是用于测试使用。当你需要做一个简单的演示的时候,可以使用此命令
python3 -m fastchat.serve.cli --model-path
3.2 使用Web GUI
Web GUI作为最方便的接口自然也是不可缺少的:
python3 -m fastchat.serve.gradio_web_server

3.1 使用RESTful API
如果想把它也作为像ChatGPT一样调用的模型,那么只需要起一个RESTful API Server即可:
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
执行完后调用的方式也很简单:
import openai
# to get proper authentication, make sure to use a valid key that's listed in
# the --api-keys flag. if no flag value is provided, the `api_key` will be ignored.
openai.api_key = "EMPTY"
openai.api_base = "http://localhost:8000/v1"
model = "Model name"
prompt = "Once upon a time"
# create a completion
completion = openai.Completion.create(model=model, prompt=prompt, max_tokens=64)
# print the completion
print(prompt + completion.choices[0].text)
# create a chat completion
completion = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": "Hello! What is your name?"}]
)
# print the completion
print(completion.choices[0].message.content)
如果需要更加复杂的描述,可以参见一下openai_api。
4. 小结
本文介绍了使用FastChat部署Baichuan2的步骤和使用方式。通过FastChat的Controller-Worker架构和不同的客户端接口,我们可以高效地部署和使用Baichuan2模型。
在使用前,我们需要按照FastChat的安装条件进行准备,并安装pytorch和其他必要的依赖项。同时,还需要下载Baichuan2的模型文件到本地。
通过阅读源代码,我们了解了FastChat的运行机制。Controller负责任务调度和与客户端的交互,而Worker则是具体的模型工作节点,负责加载模型并执行各种任务。
在使用过程中,我们可以选择不同的客户端接口。CLI提供了命令行交互的方式,适用于快速测试和演示。Web GUI则提供了友好的图形界面,方便用户进行交互。而RESTful API则使我们可以像调用ChatGPT一样使用模型。
通过本文所介绍的步骤和方式,我们可以轻松地部署和使用Baichuan2模型,为我们的应用程序和项目增添强大的语言生成能力。