PostgreSQL 技术内幕(十)WAL log 模块基本原理
事务日志是数据库的重要组成部分,记录了数据库系统中所有更改和操作的历史信息。 WAL log(Write Ahead Logging)也被称为xlog,是事务日志的一种,也是关系数据库系统中用于保证数据一致性和事务完整性的一系列技术,在数据库恢复、高可用、流复制、逻辑复制等模块中扮演着极其重要的角色。
在这次直播中,我们为大家介绍了WAL log模块的基本原理、构成和特性。以下内容根据直播文字实录整理而成。
WAL log简介
数据库在写入或更新资料时,要确保事务始终保持ACID的特性。当系统发生故障时,数据库通过事务日志回放来保证故障恢复后数据不丢失。

图1:单机WAL log流程示意图
如图1所示,在单机场景下,如果每一次写入或更新都直接去写表文件,单次更新表文件的代价相对高昂,对于硬盘来说随机写的性能也会非常差。此时,可以通过引入缓冲池(Buffer Pool),将数据写入内存中。相比直接写表文件,这种方式的性能更高。
同时,为了保证数据的持久化,需要引入WAL log:在内存更新前,先写入WAL log,再更新内存。在这种情况下,即使出现了断电或故障等情况,也能准确地恢复数据,保证了数据库的ACID。
相比直接去更新表文件,WAL log代价更小,执行路径更短。在PostgreSQL中,WAL log的写入也属于随机写。
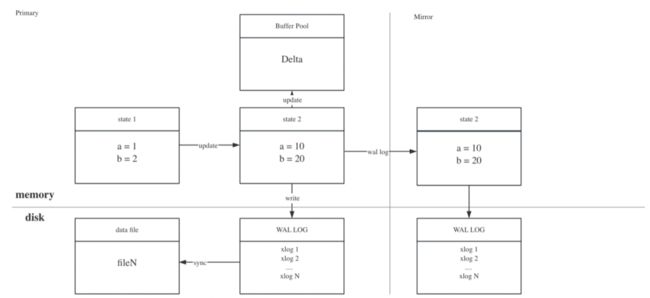
图2:联机WAL log流程示意图
除此之外,WAL log在联机场景下还可以支持主从同步,以及热备份等功能。
以Greenplum为例,如果没有引入WAL log ,主从之间需要约定好一份同步/备份的协议,或者是在从节点执行同样的SQL语句,这样不仅操作复杂,而且很难做到热切换。
在引入WAL log之后,主从节点之间直接同步WAL log,就能够保证数据的一致性。当主节点发生故障时,从节点也能快速地通过相应的WAL log重放,让数据恢复到可使用的状态,整个过程操作更为简便。
WAL log实现方式
不同的数据库对WAL log实现的需求点也有所区别,主要体现在四个方面:
- 首先是格式,一般由meta+data两个部分组成。meta部分记录了关联资源的元信息,data是资源自定的裸数据。meta和data可以分开存储,也可以统一存储。分开存储时,单条WAL log需要先读取完整的meta,再按需求解data;统一存储时,可以一条条解。举个例子,在分开存储时,数据组成往往是meta1+meta2.. metaN+data1+data2...dataN;而在统一存储时,数据组成往往是meta1+data1+meta2+data2...metaN+dataN。
- 其次,在修改数据时有undo log和redo log两种方式。undo log从后往前写,redo log从前往后写。PostgreSQL采用的是redo log。
- 此外,循环校验码信息(CRC)分为完整数据和分段数据两种。分段CRC的优点是当出现错误时,能够快速定位到坏的块数据,且损坏的范围很小,但代价是速度较慢;相比之下,完整数据的CRC读写速度更快,但如果单个meta损坏,则可能导致整个WAL log都损坏,恢复成本较高。
- 最后,是否需要落盘,这主要取决于具体场景,如果只做同步和备份,可以考虑不落盘。
WAL log的组成
在PostgreSQL中,WAL log由头部、块头部、块私有数据块、自定义资源数据块四部分组成。
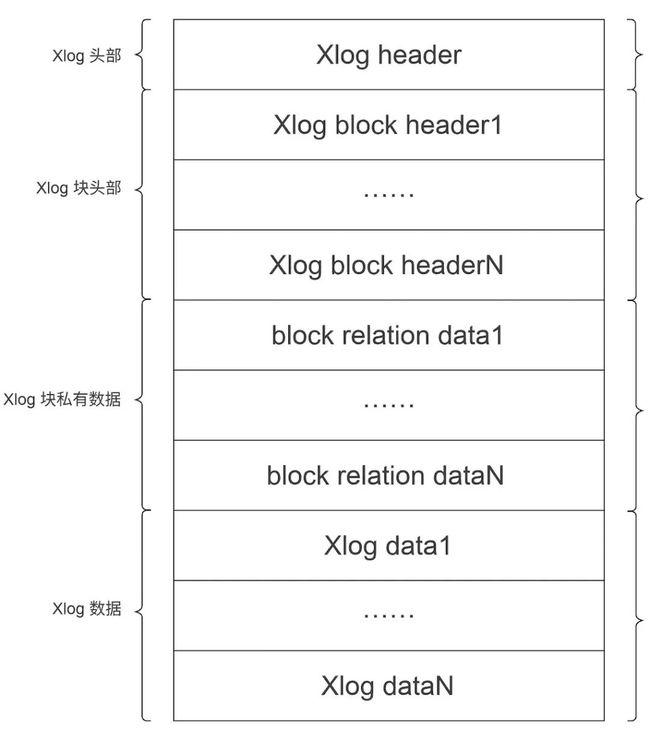
图3:PostgreSQL中WAL log构成图
头部和块头部,相当于上面提到的meta,主要用于数据块的快速定位、数据块的描述以及对数据块CRC操作等。其中,块头部是私有的,需要和page绑定。而块私有数据和WAL log本身数据属于data部分,用于存储具体的数据。
在WAL log本身数据中,初始化资源管理器rmgr(Resource managers definition)是自定义资源的主要载体,也是WAL log数据块内容的生产与消费者。
WAL log checkpoint
WAL log在执行过程中,数据量会不断地累积,当达到一定数量后,会对系统性能产生影响,因此需要定时清理WAL log数据。
清理页缓存和xlog文件需要借助checkpoint(检查点)机制。执行checkpoint 之后,页缓存可以被清空,这样可以保证不会因为页缓存太大而导致性能下降。
checkpoint的主要作用包括脏数据块回写、xlog回收(非archive xlog 且已同步的 xlog)和checkpoint redo。
通常触发checkpoint的时机主要有包括按时定期清理、数据最大长度限制、checkpoint语句、数据库关闭在内的四种场景。当然在其他场景下,也可能会触发checkpoint,这里不再一一列举。
自动checkpoint指的是按照一定的时间间隔执行checkpoint命令,时间间隔在PostgreSQL.conf文件中可以配置,默认是5分钟。
WAL log recovery与replay
如图4所示,在GPDB中,数据恢复的过程包含了数据重放。数据库启动时,会有startup进程打开checkpoint redo文件,开始按顺序读取xlog,进行恢复操作。
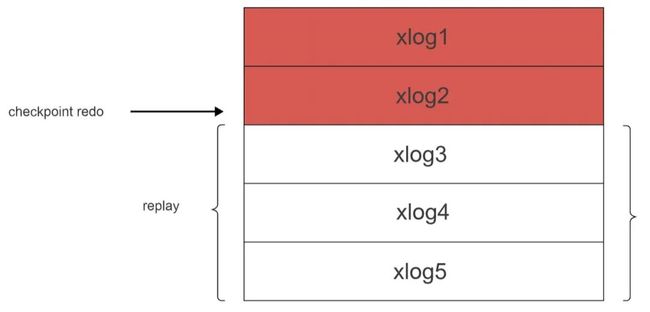
图4:recovery流程示意图
在联机场景下,primary/master集群完成数据恢复后,会退出recovery,这时WAL sender进程仍会不断会向从节点发送xlog信息。 此时,在mirror/standby集群中 startup进程则不会退出,而是会通过WAL receiver不断地接收xlog信息,并在startup进程中进行replay操作。
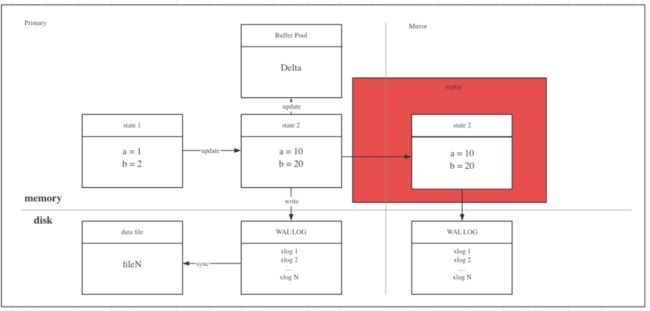
图5:replay操作流程示意图
如图5所示,备库不断地从主库同步相应的日志数据,并在备库应用每个WAL record,流复制每次传输WAL日志的record;主库启动WAL sender进程,主要负责将主服务器产生的WAL日志记录发送给从库。
相应地,从库启动WAL receiver进程,与对应的WAL sender进程通讯,负责接收主库发送的WAL日志记录;同时,从库启动startup进程,负责将WAL receiver进程接收到WAL日志记录在从库上replay,从而达成主从的数据同步。在GPDB中,默认支持同步复制,同时也支持异步复制。
示例:insert场景下WAL log的变化
图6为在insert(单条数据)场景下,WAL log的变化,感兴趣的读者可以对应着图中标注的函数名来调试代码。
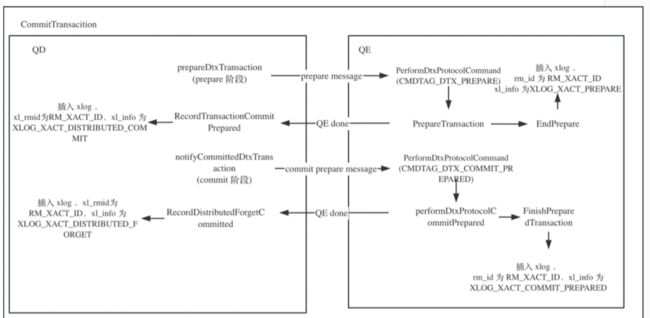
图6:insert场景下WAL log的变化
Custom WAL Resource Managers特性
在此前的PostgreSQL版本中,rmgr是一个静态的enum。如果要增加新的Resource Managers,需要在内核里去定义。
在PostgreSQL 15中,xlog模块支持了Custom WAL Resource Managers 的新改动,支持动态注册的结构,且新加了一些回调函数。
Custom WAL Resource Managers支持外部extension动态添加自定义的资源类型,比如在extension中实现的 table access method 或index access method。
目前,HashData的企业级产品系列已经全面支持PostgreSQL 15的新特性,后续HashData会不断完善相关功能,进一步提升产品可用性。
总结
PostgreSQL中的WAL机制的核心思想是:先日志落盘,后数据落盘。在写数据到磁盘里成为固定数据之前,先写入到日志里。