初识C++之模拟实现stack、queue和反向迭代器
一、stack模拟实现
有了vector和list的基础,stack这里我们就不过多的讲解了。stack其本质上就是一个“栈”。数据遵循先进先出的原则。在学习数据结构的时候,想必大家都应该对stack的特点和实现方式有了一定的了解。

在stl的stack的模拟实现之前,我们要先了解“设计模式”。
设计模式并不是我们此次学习的重点,但我们还是要有一定的了解。简单来讲,设计模式就是我们在写代码时所遵循的一些固定的方法。就好比在古代的战争中,许多能人志士根据过去的战役中使用的战术,将其总结起来,写成了“兵法”。后面的人在遇到类似的情况时就可以参考兵法进行排兵布阵。而“设计模式”,就是编程里面的“兵法”。以前的那些计算机大佬对过去的程序员所写出的优秀代码进行总结,研究出了一些在特定情况下比较好用的代码编写方法,就是设计模式。
设计模式现在大概有23种左右,我们现在不必全部了解。在过去,我们其实就已经接触过一种设计模式了,那就是“迭代器”。而现在,我们还要学习一种设计模式,即“适配器模式”。
“适配器模式”大家可能不太理解。举个例子,在我们的日常生活中,存在着大量电源接口。在国内,我们的电压一般都是220V。但是,在国外,他们的电压可能就和我们不同,如英国的电压就是230V。这就会导致我们国内的一些电子产品因为电压不适配无法使用。因此,国内出国时,一般都需要带一个变压器或转换插头,通过变压器或转换插头以适配当地的电压。编程中的“适配器”就和变压器的作用类似,用于将“已有的东西封装转换成你想要的东西”
在学习数据结构时,我们说过,因为stack“先进后出”只需要尾插尾删的特性,选用数组作为其底层结构比较好。因此,我们以前写stack,就会需要去写一个结构体加上几个成员变量,然后用数组去存储。
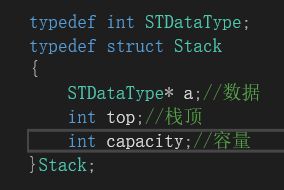
但是现在我们了解了“适配器模式”后,就可以不再这样写。而是将“vector”作为适配器:

我们查阅库中的stack实现,可以看到,它的构造中有两个参数,第一个传的是类型。而第二个传的就是一个“适配器”,其缺省值为deque。deque是一个“双端队列”,也是一个数据结构,这里先不过多讲解。有了适配器,我们要实现一个栈就很简单了。
#pragma once
#include
#include
#include
using namespace std;
namespace MyStack
{
template >
class stack
{
public:
void push(const T& x)//数据插入
{
_con.push_back(x);
}
void pop()//数据删除
{
_con.pop_back();
}
const T& top()//获取栈顶元素
{
return _con.back();
}
size_t size()//获取元素个数
{
return _con.size();
}
bool empty()//判断是否为空
{
return _con.empty();
}
private:
Container _con;
};
}
在上面的代码中,就模拟实现好了一个stack。在这里面,我们在类模板中新加入了一个参数“class Container”。该参数用于标志我们所用的适配器。在适配器中,我们默认传入vector。在以前,我们要写一个stack需要多个成员变量,如size、capacity、data等。但是用了适配器后,我们只需要一个Container _con即可。这是一个自定义类型的成员,因此我们甚至不需要写它的构造函数,因为对于自定义类型,编译器会自动调用它的构造函数,这里我们默认传入vector后,创建对象时_con成员变量就会去调用库中的默认构造函数进行构造。
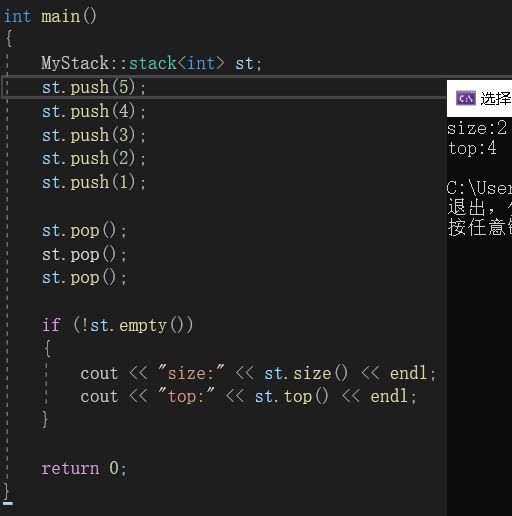
我们再写点代码进行测试:
虽然我们默认传的适配器是vector,但我们也可以手动传入list来实现stack:
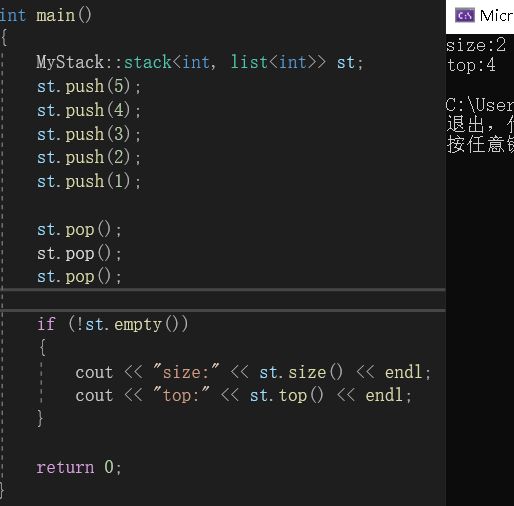
同样可以正常运行。
二、queue的模拟实现
queue,简单来讲,其实就是一个“先进先出”的队列。它的概念学过数据结构的应该都很清楚。

从上图中我们可以知道,queue和stack一样,都是使用了适配器的。我们再来看库中queue的接口:

queue的接口与list、vector和string相比,就少了很多了。而上面的几个接口,经过对其他几个stl组件的学习,已经非常熟悉了,这里就不再过多讲解。
要模拟实现一个queue,也只需要在stack的基础上稍加改造即可:
#pragma once
#include
#include
#include
using namespace std;
namespace MyQueue
{
template >
class queue
{
public:
void push(const T& x)//数据插入
{
_con.push_back(x);
}
void pop()//数据删除
{
_con.pop_front();
}
const T& front()//获取队首元素
{
return _con.front();
}
const T& back()//获取队尾元素
{
return _con.back();
}
size_t size()//获取元素个数
{
return _con.size();
}
bool empty()//判断是否为空
{
return _con.empty();
}
private:
Container _con;
};
}
同样的,我们再写一个测试用例:
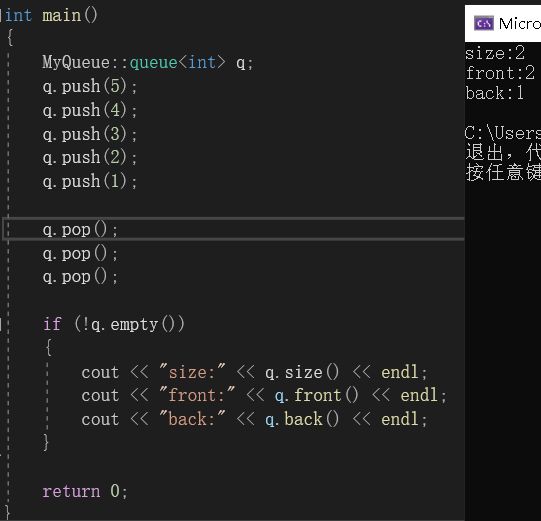
也是可以正常运行的
三、双端队列
现在我们已经模拟实现了stack和queue,但是,我们再来看这两个组件在库中的使用:


可以看到,虽然我们在数据结构中说过,stack因为先进后出,适合用顺序表实现;queue因为先进先出,适合用链表实现。但是在库中,它们传入的适配器既不是list,也不是vector,而是deque。
deque也是一个数据结构,叫做“双端队列”。虽然deque的名字叫做双端队列,但它实际上并不是队列,不遵守先进先出的原则。
deque的出现,源于list和vector的缺点。vector的底层可以看做一个数组,因此它有在头部中部插入效率低和需要扩容的缺点。而list的底层可以看作链表,因此它的每个节点都是分开存储的,不支持随机访问,且CPU高速缓存命中率低。
既然list和vector有这些缺点,那我们能不能想出一个兼具list和vector的优点,又能够解决它们的缺点的数据结构呢?答案就是deque。
deque不仅在随机插入上有着较高的效率,还能够支持随机访问,需要扩容的次数也比较少,有着较高的CPU告诉缓存命中率。我们来看一下它的部分接口:
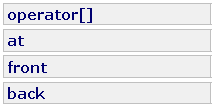

通过上面的这些接口,也就证实了deque确实继承了list和vector的缺点。但是,如果deque真的完美继承了list和vector的优点且摈弃了它们的缺点,那list和vector早就应该被淘汰掉了。但是它们却还依然活跃在stl中。因此我们可以知道,deque其实并没有它说的那么完美。
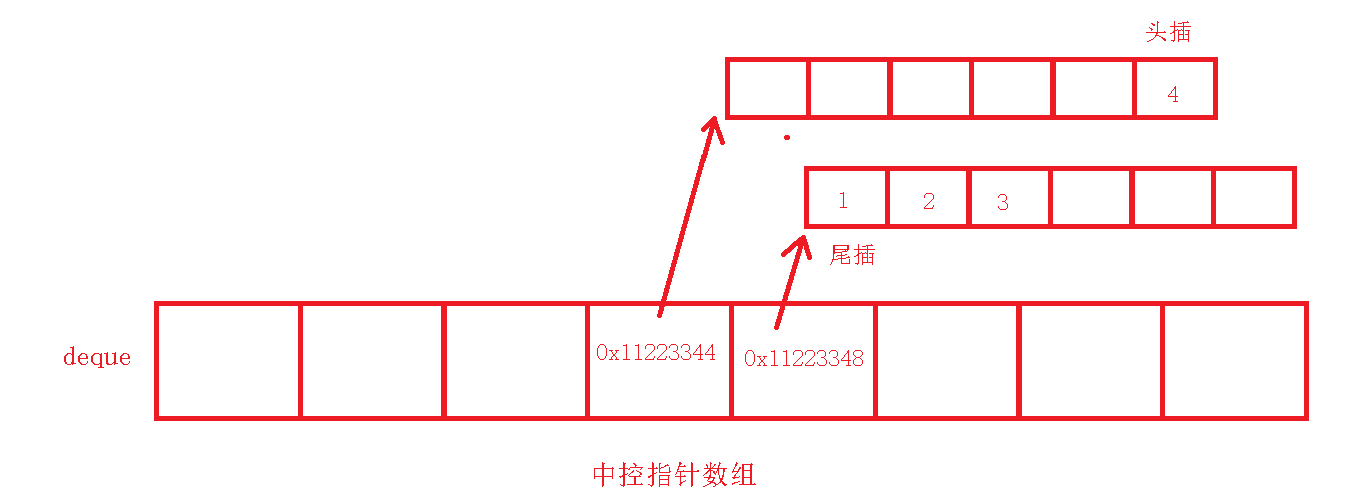
deque这个数据结构,简单来讲就是一个“指针数组”。要更具体点,我们可以将其看做一个“中控指针数组”。这里的“中控”是指,用deque存储数据时,deque会先从数组的中间位置开始使用。而该数组元素存储的是一个buffer[]空间,这个buffer[]的大小是固定的,在不同的编译器下buffer的大小可能有所不同。
当我们要插入数据时,deque会先根据存储的指针找到buffer[]的位置,然后再将数据插入到buffer中。假设我们现在要存储int类型的数据,当我们要尾插时,就会根据数组中的指针找到buffer[],然后将数据按顺序插入到buffer[]里面;当我们要头插时,就是找到第一个使用的指针,然后使用这个指针的前一个指针所指向的buffer[],再将数据插入到buffer[]的最后面。
通过这种方式,虽然解决了list和vector的缺点,但却没有完全继承它们的优点。比如vector要用“[]”随机访问时,只需要解引用即可。但是deque还需要通过计算得到对应数据的位置,然后再获取。这中间就hi有一定的消耗。举个例子,list和stack就像是三国时期的吕布和诸葛亮,一个武力出众,一个智慧超群。而deque就像是魏延,既有武力也有智慧,但都不如吕布和诸葛亮。deque也是如此。因此,在实际中,deque用的并不多,应用场景比较少。但是其实现方式却很复杂,其迭代器就存在四个参数。
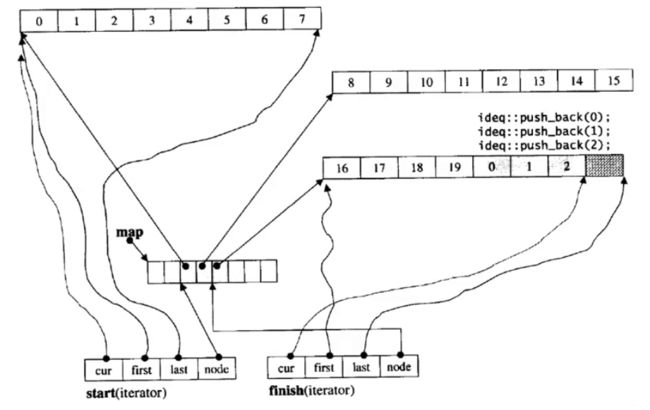
这里就不再进行模拟实现了。如果有兴趣,大家可以自己尝试着模拟实现。
四、仿函数
仿函数,它的对象可以叫做函数对象。也是用类来写的。但是,仿函数和普通的类有一个区别,就是仿函数中要对“()”进行重载,“()”其实就是函数调用时所用的运算符。仿函数有很多种,你可以随意指定。在这里,我们实现一个比较仿函数来示范:
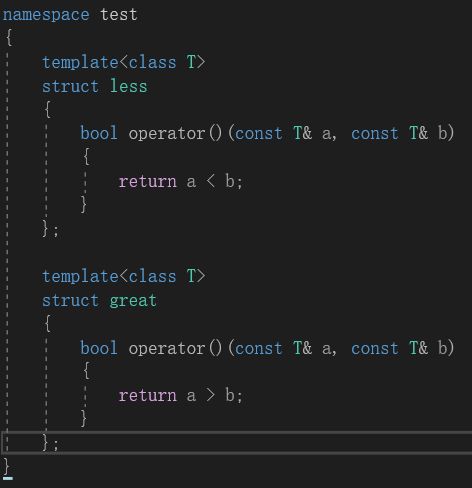
上图中,就实现了一个less和great仿函数。使用起来也和普通的类一样:
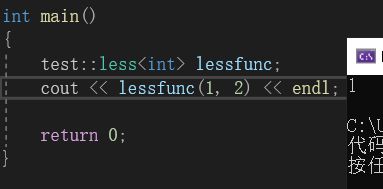
可以看到,仿函数使用起来和普通函数的使用时一样的。在这里,lessfunc()看起来是一个函数调用,但实际上却是调用一个运算符重载。叫做仿函数就是因为它可以像函数那样使用。
看到这里,有些人可能就觉得这个仿函数没有什么用。因为这里虽然封装了两个比较函数,但是我们自己写一个比较函数还比这里的要简单,而且封装的函数中也没有做什么。但是,既然仿函数存在,就一定有它存在的意义。
我们以我们写的堆举例。现在我们写的堆默认是大堆。但是,如果我们有一天想将这个堆改成小堆呢?我们就只能修改源代码中的比较方法。我们可以将比较中的大于小于修改,也可以传一个函数指针去修改。
修改源代码中的比较方法很麻烦不考虑。而传函数指针的方法虽然可以用,但是使用起来却非常的难受。那如果我们不想用函数指针,又不愿意去修改源代码,此时我们就可以用仿函数。在类模板中我们新加入一个参数:
该参数传入缺省值less
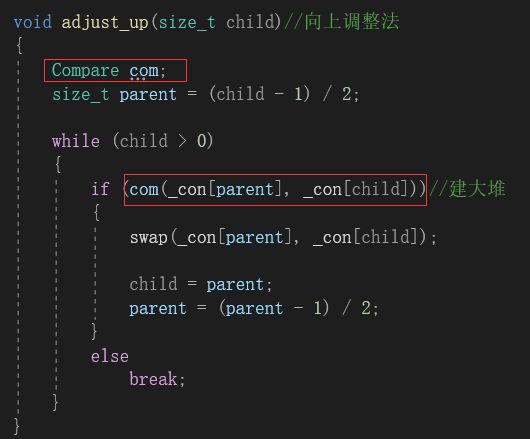
我们运行程序:
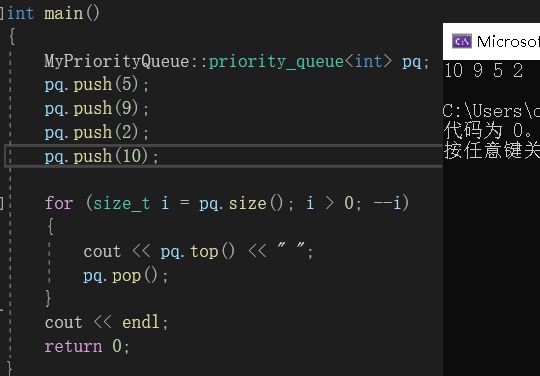
可以看到,pq的参数是使用的缺省值,因此排的的大堆。如果我们想改成小堆,只需要向里面手动传入对应比较大于的仿函数即可:
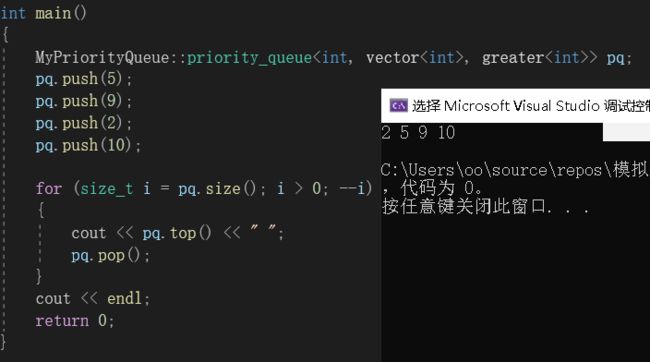
通过传仿函数的方式,我们就可以在不修改底层代码的情况,根据传入参数的不同构建不同的堆。
在这里,使用less建小堆,greater建大堆也是为了和库中的逻辑相同。因为库中的优先级队列就是默认用less构建大堆,传入greater构建小堆。

当然,仿函数的不仅仅可以在类中用于指定不同的方法。我们也可以在用其他类时使用仿函数。
假如我们现在有一个日期类,我们要比较它的日期大小。一般来讲,它的类里面都会自己封装比较。但如果类中没有封装,我们就可以自己写。但是就算类中自己写了,它的比较方式也可能不是我们所想要的:
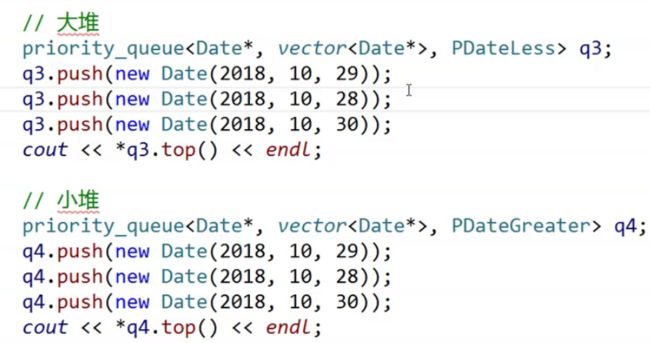
在上图中,我们比较日期类时,传入的是指针。如果用类中封装的直接比较数据的函数,那么它比较的值就是地址的大小,不符合我们的需求。所以我们可以自己写一个PDateLess和PDateGreater仿函数,再将其传入构建的优先级队列中,就可以控制它进行正确的比较了。
五、优先级队列

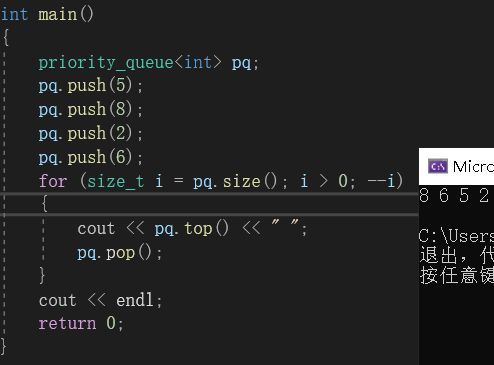
优先级队列,虽然名字中也有队列,但是我们可以将其看成一个“堆”。当然,说是一个堆,它的结构在物理上还是一个数组。只是它的数据会根据优先级出队列。在优先级队列中,它有三个模板参数,分别是传入的数据类型、适配器和仿函数。
在优先级队列中,我们传入的数据它会默认按照大堆的方式为我们排列。这里的参数传入有点特殊。我们从上图中可以看到,它默认传入的是less仿函数,但是构建的却是大堆:
而当我们传入greater仿函数时,构建的却是小堆:
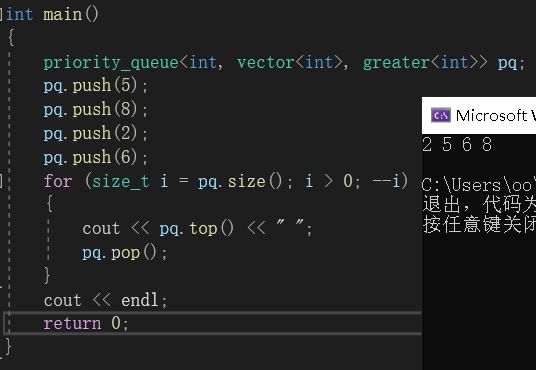
在使用时,我们就需要注意点仿函数的传入。
我们再来看看它的接口:

可以看到,它的接口也是比较少的,而且与stack和queue一样,都不支持迭代器。
#pragma once
#include
#include
#include
#include
using namespace std;
namespace MyPriorityQueue
{
template
struct less//大于比较仿函数
{
bool operator()(const T& a, const T& b)
{
return a < b;
}
};
template
struct greater//小于比较仿函数
{
bool operator()(const T& a, const T& b)
{
return a > b;
}
};
template, class Compare = less>
class priority_queue
{
public:
priority_queue()//一个什么都没有的构造函数,自定义成员变量进来后会走初始化列表调用自己的构造函数
{}
template
priority_queue(InputIterator first, InputIterator last)//支持迭代器构造优先级队列
:_con(first, last)
{}
void adjust_up(size_t child)//向上调整法
{
Compare com;
size_t parent = (child - 1) / 2;
while (child > 0)
{
if (com(_con[parent], _con[child]))//建大堆
{
swap(_con[parent], _con[child]);
child = parent;
parent = (parent - 1) / 2;
}
else
break;
}
}
void push(const T& x)//插入数据
{
_con.push_back(x);
adjust_up(_con.size() - 1);
}
void adjust_down(size_t parent)//向下调整建堆
{
Compare com;
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if (child + 1 < _con.size() && com(_con[child], _con[child + 1]))
{
++child;
}
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
void pop()//删除堆顶数据
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
size_t size()//获取数据个数
{
return _con.size();
}
const T& top() const//获取堆顶数据
{
return _con.front();
}
bool empty()//判断是否为空
{
return _con.empty();
}
private:
Container _con;
};
}
六、反向迭代器
反向迭代器,其实也是使用了适配器的。反向得迭代器会将传入的迭代器的begin()和end()视为反向,写起来也比较简单。
#pragma once
#include
using namespace std;
namespace MyReverseIterator
{
template
class ReverseIterator
{
typedef ReverseIterator Self;
public:
ReverseIterator(iterator it)//构造函数
: _it(it)
{}
Ref operator*()//运算符*重载
{
iterator tmp = _it;
return *(--tmp);
}
Rtr operator->()//运算符->重载
{
return *(operator*());
}
Self& operator++()//前置++重载
{
--_it;
return *this;
}
Self& operator--()//前置--重载
{
++_it;
return *this;
}
bool operator!=(const iterator& it) const//运算符!=重载
{
return _it != it._it;
}
private:
iterator _it;
};
} 在反向迭代器里面,为了支持“*”和“->”的重载,加入了三个模板参数。其他都没有什么好讲的,但是大家可以注意到运算符“*”的重载,这里返回的是“*(--tmp)”,而不是当前位置。原因是,我们的反向迭代器是和正向迭代器对应的:
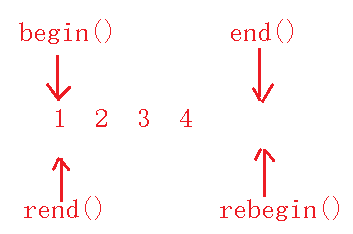
反向迭代器中的rbegin()和rend()与我们所想的rend()指向1前,rbegin()指向4不同,是与正向迭代器相对照的。
我们将反向迭代器添加到我们自己写的list中测试:


添加到list的头文件后,我们再写出如下测试程序:
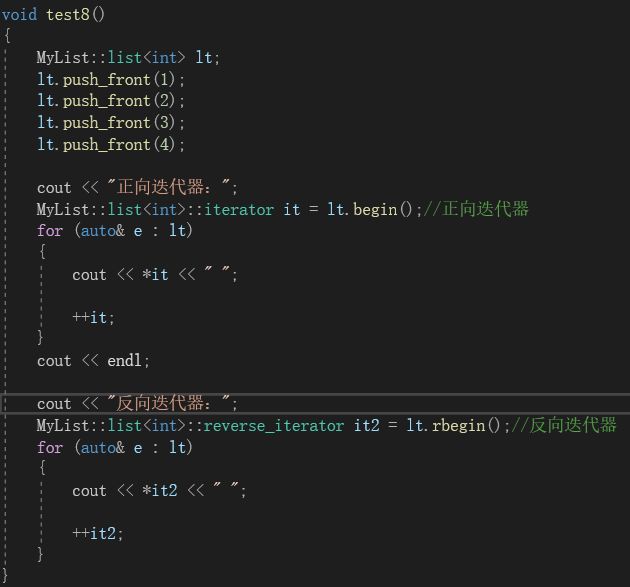
运行该程序:
可以看到,反向迭代器可以正常运行。