大数据之Flume(二)
大数据之Flume(二)
- 3. Flume进阶
-
- 3.1 Flume 事务
- 3.2 Flume Agent 内部原理
- 3.3 Flume 拓扑结构
-
- 3.3.1 简单串联
- 3.3.2 复制和多路复用
- 3.3.3 负载均衡和故障转移
- 3.3.4 聚合
- 3.4 Flume企业开发案例
-
- 3.4.1 复制和多路复用
- 3.4.2 负载均衡和故障转移
- 3.3.4 聚合
- 3.5 自定义Interceptor
- 3.6 Flume 数据流监控
-
- 3.6.1 Ganglia的安装与部署
- 3.6.2 操作Flume测试监控
之前一节分享是基础的内容,今天来讲解一下进阶的哈!!
3. Flume进阶
3.1 Flume 事务
关于Flume事务我总结了一下,不过我们先看图来了解一下:
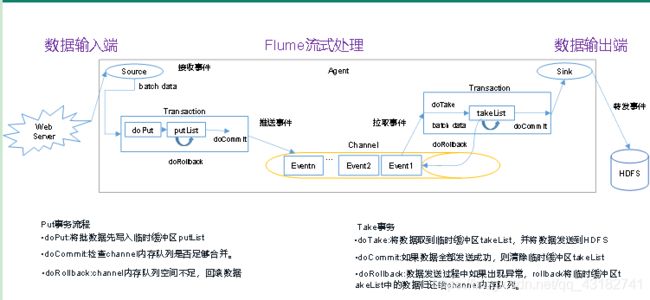
看完图后,我们来看一下总结:
Flume是由两个事务组成的,一个是数据传输到Source组件后到Channel的过程中,这个事务我们一般称为put事务,另外一个是Sink组件从Channel组件中提取数据的过程中,这个事务我们一般称为take事务。
PUT事务:source组件接收数据后,会将数据封装成一个一个的event,source组件中的一个个event会像经过put事务,写到transaction的临时缓冲区中,一般情况下设置临时缓冲区的大小为100个event,当临时缓冲区存够100个event后,会把自己的数据传输到Channel组件中,若此时发现Channel内存队列中存不下100个event(上传失败),put事务会清除掉上传的部分数据以及put事务中的数据,然后回重新读取Source组件中的数据再进行上传,此操作为回滚,上传成功后,put事务结束。
TAKE事务:take事务会从Channel提取数据到临时缓冲区,并将数据发送到HDFS上。假设在传输过程中,数据传输失败了,take事务此次也就失败了,存储在事务中的临时缓冲区中的数据也会清除,但是传输到HDFS上的数据不能清除(这也是生产过程中产生数据重复的原因之一),当数据成功写到HDFS上后,take事务成功,成功后,其也会清除掉临时缓冲区的数据,此时,take事务结束。
Flume中的事务主要是为了保证数据传输的完整性,所以一般情况下数据都是完整的,但是也不避免,Channel组件使用memory类型时,Flume宕机造成数据丢失的情况,但是发生这种情况的时候,数据丢失往往不那么重要了。。。
3.2 Flume Agent 内部原理
老套路,我们先来看下图,然后我在给大家阐述一下:
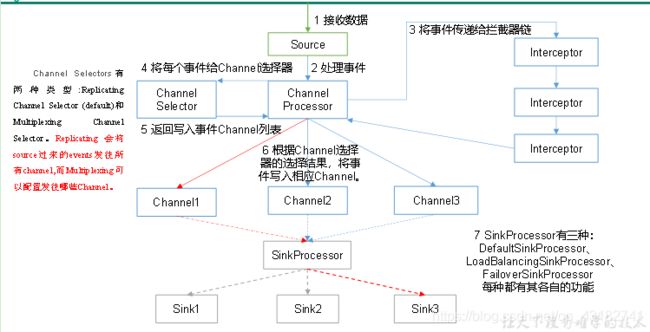
我们先来看一下各个组件:
1)ChannelSelector
ChannelSelector的作用就是选出Event将要被发往哪个Channel。其共有两种类型,分别是Replicating(复制)和Multiplexing(多路复用)。
ReplicatingSelector会将同一个Event发往所有的Channel,Multiplexing会根据相应的原则(event的header),将不同的Event发往不同的Channel。
2)SinkProcessor
SinkProcessor共有三种类型,分别是DefaultSinkProcessor、LoadBalancingSinkProcessor和FailoverSinkProcessor
DefaultSinkProcessor对应的是单个的Sink,LoadBalancingSinkProcessor和FailoverSinkProcessor对应的是Sink Group(sink组),LoadBalancingSinkProcessor可以实现负载均衡的功能,FailoverSinkProcessor可以**错误恢复(故障转移)**的功能。
ok,我们来走一下event的一生,Source组件接收数据封装为event(诞生),其后到达Channel Processor(处理event),因在实际的生产过程中,我们收集到数据多少会存在脏数据,所以哦一般会将event传递给interceptor(拦截器),若是多个拦截器,我们称之为拦截器链,经过拦截器链处理后的数据会传递给Channel Selector,Selector的类型上面我有写到,但是Multiplexing的处理原则是会根据event的header发送至不同的Channel组件,之后event会在通过sinkprocessor,这里我再讲一下loadbalancingsinkprocessor,它的原则是随机和轮循原则,随机原则是不同的sink随机出来一个提取数据,而轮循原则是一个一个sink来提取数据(可能会出现提取不到数据的情况)。当event经过processor后,被sink提取后,event的一生结束。
3.3 Flume 拓扑结构
3.3.1 简单串联

这种模式的优点就是Channel多,缓存多一些,但是它的缺点太明显了,只要一台flume出现宕机,整个系统就废了,所以不建议用这个。
3.3.2 复制和多路复用

flume支持将数据传输到一个或多个目的地,这种模式可以将相同数据复制到多个channel中,或者将不同数据分发到不同的channel中,sink选择传送到不同的目的地。
3.3.3 负载均衡和故障转移
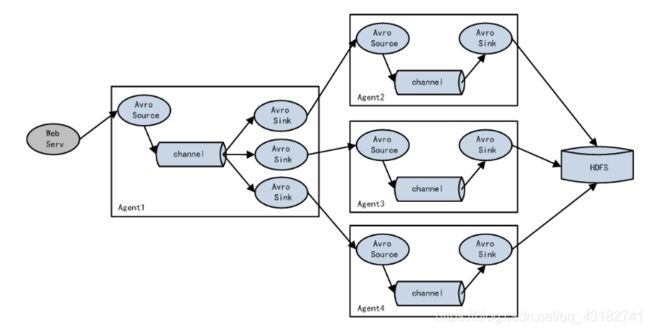
Flume支持使用将多个sink逻辑上分到一个sink组,sink组配合不同的SinkProcessor可以实现负载均衡和错误恢复的功能。
3.3.4 聚合
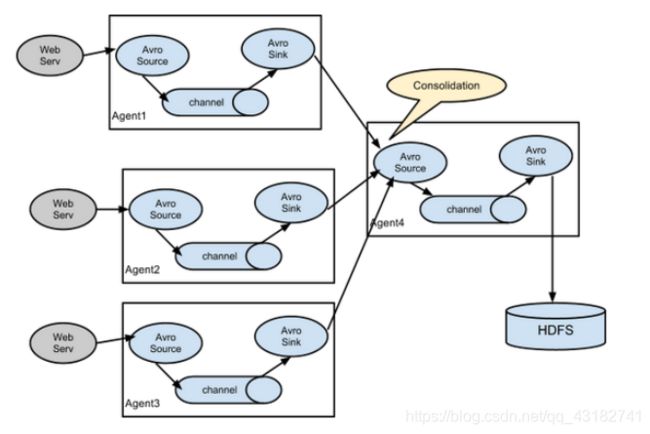
这种模式是我们经常使用的,日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用flume的这种组合方式能很好的解决这一问题,每台服务器部署一个flume采集日志,传送到一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase等,进行日志分析。
3.4 Flume企业开发案例
3.4.1 复制和多路复用
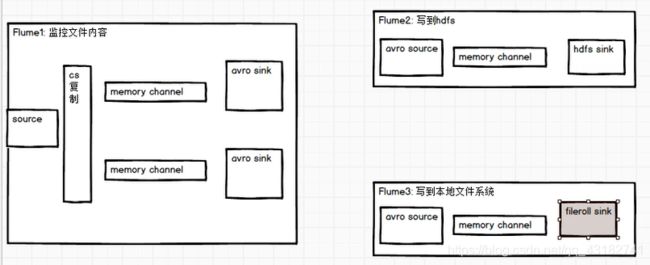
1)案例需求
使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3负责输出到Local FileSystem。
2)需求分析:
3)实现步骤:
(1)准备工作
在/opt/module/flume/job目录下创建group1文件夹[atguigu@hadoop102 job]$ cd group1/在/opt/module/datas/目录下创建flume3文件夹
[atguigu@hadoop102 datas]$ mkdir flume3(2)创建flume-file-flume.conf
配置1个接收日志文件的source和两个channel、两个sink,分别输送给flume-flume-hdfs和flume-flume-dir。
编辑配置文件[atguigu@hadoop102 group1]$ vim flume-file-flume.conf添加如下内容
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # 将数据流复制给所有channel a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink # sink端的avro是一个数据发送者 a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2(3)创建flume-flume-hdfs.conf
配置上级Flume输出的Source,输出是到HDFS的Sink。
编辑配置文件[atguigu@hadoop102 group1]$ vim flume-flume-hdfs.conf添加如下内容
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source # source端的avro是一个数据接收服务 a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop102:8020/flume2/%Y%m%d/%H #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- #是否按照时间滚动文件夹 a2.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a2.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是128M a2.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a2.sinks.k1.hdfs.rollCount = 0 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1(4)创建flume-flume-dir.conf
配置上级Flume输出的Source,输出是到本地目录的Sink。
编辑配置文件[atguigu@hadoop102 group1]$ vim flume-flume-dir.conf添加如下内容
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/module/data/flume3 # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。
(5)执行配置文件
分别启动对应的flume进程:flume-flume-dir,flume-flume-hdfs,flume-file-flume。[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf(6)启动Hadoop和Hive
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh [atguigu@hadoop102 hive]$ bin/hive hive (default)>(7)检查HDFS上数据
(8)检查/opt/module/datas/flume3目录中数据[atguigu@hadoop102 flume3]$ ll 总用量 8 -rw-rw-r--. 1 atguigu atguigu 5942 5月 22 00:09 1526918887550-3
3.4.2 负载均衡和故障转移
1)案例需求
使用Flume1监控一个端口,其sink组中的sink分别对接Flume2和Flume3,采用FailoverSinkProcessor,实现故障转移的功能。
2)需求分析

3)实现步骤
(1)准备工作
在/opt/module/flume/job目录下创建group2文件夹[atguigu@hadoop102 job]$ cd group2/(2)创建flume-netcat-flume.conf
配置1个netcat source和1个channel、1个sink group(2个sink),分别输送给flume-flume-console1和flume-flume-console2。
编辑配置文件[atguigu@hadoop102 group2]$ vim flume-netcat-flume.conf添加如下内容
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinkgroups = g1 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 a1.sinkgroups.g1.processor.maxpenalty = 10000 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1(3)创建flume-flume-console1.conf
配置上级Flume输出的Source,输出是到本地控制台。
编辑配置文件[atguigu@hadoop102 group2]$ vim flume-flume-console1.conf添加如下内容
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = logger # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1(4)创建flume-flume-console2.conf
配置上级Flume输出的Source,输出是到本地控制台。
编辑配置文件[atguigu@hadoop102 group2]$ vim flume-flume-console2.conf添加如下内容
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2(5)执行配置文件
分别开启对应配置文件:flume-flume-console2,flume-flume-console1,flume-netcat-flume。[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf(6)使用netcat工具向本机的44444端口发送内容
[atguigu@hadoop102 ~]$ nc localhost 44444(7)查看Flume2及Flume3的控制台打印日志
(8)将Flume2 kill,观察Flume3的控制台打印情况。
注:使用jps -ml查看Flume进程。
3.3.4 聚合
1)案例需求:
hadoop102上的Flume-1监控文件/opt/module/group.log,
hadoop103上的Flume-2监控某一个端口的数据流,
Flume-1与Flume-2将数据发送给hadoop104上的Flume-3,Flume-3将最终数据打印到控制台。
2)需求分析
3)实现步骤:
(1)准备工作
分发Flume
[atguigu@hadoop102 module]$ xsync flume
在hadoop102、hadoop103以及hadoop104的/opt/module/flume/job目录下创建一个group3文件夹。[atguigu@hadoop102 job]$ mkdir group3 [atguigu@hadoop103 job]$ mkdir group3 [atguigu@hadoop104 job]$ mkdir group3(2)创建flume1-logger-flume.conf
配置Source用于监控hive.log文件,配置Sink输出数据到下一级Flume。
在hadoop102上编辑配置文件[atguigu@hadoop102 group3]$ vim flume1-logger-flume.conf添加如下内容
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/group.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop104 a1.sinks.k1.port = 4141 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1(3)创建flume2-netcat-flume.conf
配置Source监控端口44444数据流,配置Sink数据到下一级Flume:
在hadoop103上编辑配置文件[atguigu@hadoop102 group3]$ vim flume2-netcat-flume.conf添加如下内容
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = netcat a2.sources.r1.bind = hadoop103 a2.sources.r1.port = 44444 # Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = hadoop104 a2.sinks.k1.port = 4141 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1(4)创建flume3-flume-logger.conf
配置source用于接收flume1与flume2发送过来的数据流,最终合并后sink到控制台。
在hadoop104上编辑配置文件[atguigu@hadoop104 group3]$ touch flume3-flume-logger.conf [atguigu@hadoop104 group3]$ vim flume3-flume-logger.conf添加如下内容
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop104 a3.sources.r1.port = 4141 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1(5)执行配置文件
分别开启对应配置文件:flume3-flume-logger.conf,flume2-netcat-flume.conf,flume1-logger-flume.conf。[atguigu@hadoop104 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group3/flume3-flume-logger.conf -Dflume.root.logger=INFO,console [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group3/flume1-logger-flume.conf [atguigu@hadoop103 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group3/flume2-netcat-flume.conf(6)在hadoop103上向/opt/module目录下的group.log追加内容
[atguigu@hadoop103 module]$ echo 'hello' > group.log(7)在hadoop102上向44444端口发送数据
[atguigu@hadoop102 flume]$ telnet hadoop102 44444(8)检查hadoop104上数据

3.5 自定义Interceptor
1)案例需求
使用Flume采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统。
2)需求分析
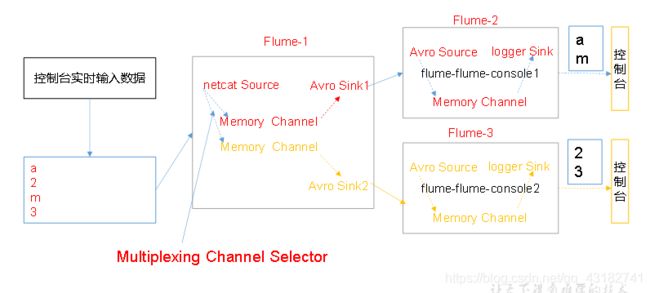
在实际的开发中,一台服务器产生的日志类型可能有很多种,不同类型的日志可能需要发送到不同的分析系统。此时会用到Flume拓扑结构中的Multiplexing结构,Multiplexing的原理是,根据event中Header的某个key的值,将不同的event发送到不同的Channel中,所以我们需要自定义一个Interceptor,为不同类型的event的Header中的key赋予不同的值。
在该案例中,我们以端口数据模拟日志,以数字(单个)和字母(单个)模拟不同类型的日志,我们需要自定义interceptor区分数字和字母,将其分别发往不同的分析系统(Channel)。
3)实现步骤
(1)创建一个maven项目,并引入以下依赖。<dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.9.0</version> </dependency>(2)定义CustomInterceptor类并实现Interceptor接口
public class CustomInterceptor implements Interceptor { @Override public void initialize() { } @Override public Event intercept(Event event) { byte[] body = event.getBody(); if (body[0] < 'z' && body[0] > 'a') { event.getHeaders().put("type", "letter"); } else if (body[0] > '0' && body[0] < '9') { event.getHeaders().put("type", "number"); } return event; } @Override public List<Event> intercept(List<Event> events) { for (Event event : events) { intercept(event); } return events; } @Override public void close() { } public static class Builder implements Interceptor.Builder { @Override public Interceptor build() { return new CustomInterceptor(); } @Override public void configure(Context context) { } } }(3)编辑flume配置文件
为hadoop102上的Flume1配置1个netcat source,1个sink group(2个avro sink),并配置相应的ChannelSelector和interceptor。# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.CustomInterceptor$Builder a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = type a1.sources.r1.selector.mapping.letter = c1 a1.sources.r1.selector.mapping.number = c2 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop103 a1.sinks.k1.port = 4141 a1.sinks.k2.type=avro a1.sinks.k2.hostname = hadoop104 a1.sinks.k2.port = 4242 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Use a channel which buffers events in memory a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2为hadoop103上的Flume4配置一个avro source和一个logger sink。
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = hadoop103 a1.sources.r1.port = 4141 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.channel = c1 a1.sources.r1.channels = c1为hadoop104上的Flume3配置一个avro source和一个logger sink。
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = hadoop104 a1.sources.r1.port = 4242 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.channel = c1 a1.sources.r1.channels = c1(4)分别在hadoop102,hadoop103,hadoop104上启动flume进程,注意先后顺序。
(5)在hadoop102使用netcat向localhost:44444发送字母和数字。
(6)观察hadoop103和hadoop104打印的日志。
3.6 Flume 数据流监控
3.6.1 Ganglia的安装与部署
Ganglia由gmond、gmetad和gweb三部分组成。
gmond(Ganglia Monitoring Daemon)是一种轻量级服务,安装在每台需要收集指标数据的节点主机上。使用gmond,你可以很容易收集很多系统指标数据,如CPU、内存、磁盘、网络和活跃进程的数据等。
gmetad(Ganglia Meta Daemon)整合所有信息,并将其以RRD格式存储至磁盘的服务。
gweb(Ganglia Web)Ganglia可视化工具,gweb是一种利用浏览器显示gmetad所存储数据的PHP前端。在Web界面中以图表方式展现集群的运行状态下收集的多种不同指标数据。
1)安装ganglia
(1)规划
| 主机名 | gweb | gmetad | gmond |
|---|---|---|---|
| hadoop102 | gweb | gmetad | gmond |
| hadoop103 | gmond | ||
| hadoop104 | gmond |
(2)在102 103 104分别安装epel-release
[atguigu@hadoop102 flume]$ sudo yum -y install epel-release
(3)在102 安装[atguigu@hadoop102 flume]$ sudo yum -y install ganglia-gmetad [atguigu@hadoop102 flume]$ sudo yum -y install ganglia-web [atguigu@hadoop102 flume]$ sudo yum -y install ganglia-gmond(4)在103 和 104 安装
[atguigu@hadoop102 flume]$ sudo yum -y install ganglia-gmond2)在102修改配置文件/etc/httpd/conf.d/ganglia.conf
[atguigu@hadoop102 flume]$ sudo vim /etc/httpd/conf.d/ganglia.conf修改为红颜色的配置:
# Ganglia monitoring system php web frontend Alias /ganglia /usr/share/ganglia <Location /ganglia> # Require local # 通过windows访问ganglia,需要配置Linux对应的主机(windows)ip地址 Require ip 192.168.202.1 # Require ip 10.1.2.3 # Require host example.org </Location>5)在102修改配置文件/etc/ganglia/gmetad.conf
[atguigu@hadoop102 flume]$ sudo vim /etc/ganglia/gmetad.conf修改为:
data_source "my cluster" hadoop1026)在102 103 104修改配置文件/etc/ganglia/gmond.conf
[atguigu@hadoop102 flume]$ sudo vim /etc/ganglia/gmond.conf修改为:
cluster { name = "my cluster" owner = "unspecified" latlong = "unspecified" url = "unspecified" } udp_send_channel { #bind_hostname = yes # Highly recommended, soon to be default. # This option tells gmond to use a source address # that resolves to the machine's hostname. Without # this, the metrics may appear to come from any # interface and the DNS names associated with # those IPs will be used to create the RRDs. # mcast_join = 239.2.11.71 # 数据发送给hadoop102 host = hadoop102 port = 8649 ttl = 1 } udp_recv_channel { # mcast_join = 239.2.11.71 port = 8649 # 接收来自任意连接的数据 bind = 0.0.0.0 retry_bind = true # Size of the UDP buffer. If you are handling lots of metrics you really # should bump it up to e.g. 10MB or even higher. # buffer = 10485760 }7)在102修改配置文件/etc/selinux/config
[atguigu@hadoop102 flume]$ sudo vim /etc/selinux/config修改为:
# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted尖叫提示:selinux本次生效关闭必须重启,如果此时不想重启,可以临时生效之:
8)启动ganglia
(1)在102 103 104 启动[atguigu@hadoop102 flume]$ sudo systemctl start gmond(2)在102 启动
[atguigu@hadoop102 flume]$ sudo systemctl start httpd [atguigu@hadoop102 flume]$ sudo systemctl start gmetad9)打开网页浏览ganglia页面
http://hadoop102/ganglia
尖叫提示:如果完成以上操作依然出现权限不足错误,请修改/var/lib/ganglia目录的权限:[atguigu@hadoop102 flume]$ sudo chmod -R 777 /var/lib/ganglia
3.6.2 操作Flume测试监控
1)启动Flume任务
[atguigu@hadoop102 flume]$ bin/flume-ng agent \ -c conf/ \ -n a1 \ -f datas/netcat-flume-logger.conf \ -Dflume.root.logger=INFO,console \ -Dflume.monitoring.type=ganglia \ -Dflume.monitoring.hosts=hadoop102:86492)发送数据观察ganglia监测图
[atguigu@hadoop102 flume]$ nc localhost 44444

图例说明:

Flume到此结束,需要源码和资料私聊哦!