操作系统学习笔记——用户级线程和核心级线程
绪论
为什么要说线程的切换
操作系统是多进程的,我们关注的应该是进程之间的切换,那为什么关注线程的切换呢?因为理解了线程的切换之后可以更好的理解进程的切换,换句话说线程的切换是进程切换的基础。
进程的切换其实是包含两个部分的,第一个指令的切换,第二个内存映射表的切换。指令的切换就是从这段程序跳到另外一段程序执行,内存映射表切换涉及到内存管理这部分的内容,相对来说比较复杂。线程的切换只有指令的切换,同处于一个进程里面,不存在内存映射表的切换。因此理解了线程的切换之后可以更好的理解进程的切换。
一、用户级线程
1.1 用户级线程实例
以前网速比较慢的时候,打开浏览器访问一个网页,首先弹出来的是网页的文字部分,然后是一些图片,最后才是一些小视频之类的。为什么呢?浏览器向服务器发起访问的程序是一个进程,它包含若干线程,比如:一个线程用来从服务器接收数据,一个线程用来显示文本,一个线程用来显示文本,一个线程用来显示图片等等。在网速比较慢的时候用来从服务器接收数据的线程要执行的时间比较长,因为一些图片和视频都比较大。如果要等这个线程运行完了之后再显示,那么电脑屏幕就会有一段时间什么东西都没有,这样用户体验就会比较差;一个比较合理的办法是:接受数据的线程接受完文本东西之后,就调用显示文本的线程将数据显示出来,然后再接受图片再显示,再接受视频再显示;这样至少可以保证电脑屏幕上始终有东西;相比前面的方法好很多,当然最根本的办法还是提高网速。
还有一个问题,为什么浏览器向服务器请求数据的程序是一个进程,而不是多个?浏览器接受服务器的数据肯定都是存储在一个缓冲区里面的,并且这个缓冲区是共享的,如果是多个进程,那么肯定有多个映射表,也就是说如果程序里面存储数据的地址是连续的,经过不同的映射表之后,就会分布在内存的不同区域,这样肯定没有在一块地方好处理呀。
上面这个例子就牵涉到线程(用户级线程)的切换,也可以看出线程并不是一个无意义的概念,而是有实际作用的。
下面说一下线程之间到底是如何切换的,其实主要是切过去之后还要能够切回来。
1.2 两个线程共用一个栈
线程一:
100:A()
{
B();
104:
}
200: B()
{
Yield1(); // 切换线程
204:
}
线程二:
300:C()
{
D();
304:
}
400: D()
{
Yield2();
404:
}
按照这个执行一下:首先从线程一的A函数开始,调用B函数,将B函数的返回地址:104压栈;然后进入B函数;在B函数内部使用Yield1切换到线程二的C()函数里面去,同时将Yield1的返回地址压栈,此时栈中的数据如下:
104 204
Yield1的伪代码应该是:
void Yield1()
{
find 300;
jmp 300;
}
现在执行到了线程二,计划是在D函数里面通过Yield2跳到线程一的204这个地址,完成线程的切换。调用c函数,同时将304这个地址压栈,跳到D函数里面执行,在D函数里面调用Yield2,同时将404压栈。Yield2的伪代码应该是:
void Yield2()
{
find 204;
jmp 204;
}
目前栈里面的数据应该是:
104 204 304 404
跳到204之后,接着执行B函数剩下的内容,执行完内容之后,执行函数B的"}"相当于ret,弹栈,此时栈顶的地址是404,B函数应该是返回到104处,而不是404处;这里就出现了问题。怎么处理?
1.3 一个线程配一个栈
处理方法是在不同的线程里面使用不同的栈。在线程一中使用栈一,线程二中使用栈二。这是一个伟大的发明。
重新执行一下上面那个程序,从A函数开始执行,在B函数里面调用Yield1进入线程二的C函数之后,线程一对应的栈一中的内容应该是:
104 204
执行到D函数的Yield2之后,线程二对应的栈二的内容应该是:
304 404
在Yield2里面做的第一件事就应该是切换栈,如何切换?肯定需要一个数据结构将原来栈一的地址保存起来,这个数据结构就是TCB(Thread control block) ;当前栈的栈顶地址是存放在CPU里面的esp寄存器里面的, 因此只需要改变esp的值就可以切换栈了。
void Yield2()
{
TCB2.esp = esp; // 保存当前栈顶地址
esp = TCB1.esp; // 切换栈
jmp 204;
}
jmp到204之后,执行完B函数剩下的代码之后执行B函数的"}",即弹栈,这时栈顶是204,也就是又跳到204去了,显然有问题,但是比前面已经好很多了,因为不会跳到另外一个线程里去。那现在为什么会这样呢?原因是Yield2()直接跳到204之后,而没有将栈中的204弹出去,如果Yield2跳到204这个位置,同时将栈中的204弹出去就好了。其实这个可以实现,修改Yield2如下:
void Yield2()
{
TCB2.esp = esp; // 保存当前栈顶地址
esp = TCB1.esp; // 切换栈
}
没错,就是将jmp 204去掉就可以了,利用Yield2的"}“弹栈同时跳到204地址处, 执行完B函数之后, 通过B函数的”}"再次弹栈到104处,完美。
二、核心级线程
2.1 由多处理器和多核的区别引出内核级线程的必要性
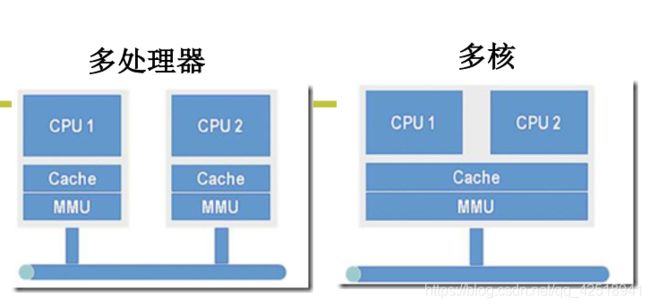
多处理器每一个CPU都有一套自己的MMU(Memory Management Unit)。多核是所有的CPU共用一套MMU,也就是多个CPU的内存映射关系是一致的。
对于多核处理器来说,系统将任务分配到每一个处理器上,用的是同一套MMU,这就是典型的多线程模式。而今天我们的电脑,基本上都是多核模式。多核模式的电脑正因为有了内核级线程技术,才能更好的发挥电脑的硬件优势。
2.2 核心级线程与用户级线程有什么区别呢?
首先要明确的一点是,核心级线程是需要进入到系统内核中执行的程序。核心级线程需要在用户态和核心态里面跑,在用户态里跑需要一个用户栈,在核心态里面跑需要一个核心栈。用户栈和核心栈合起来称为一套栈,这就是核心级线程与用户级线程一个很重要的区别。
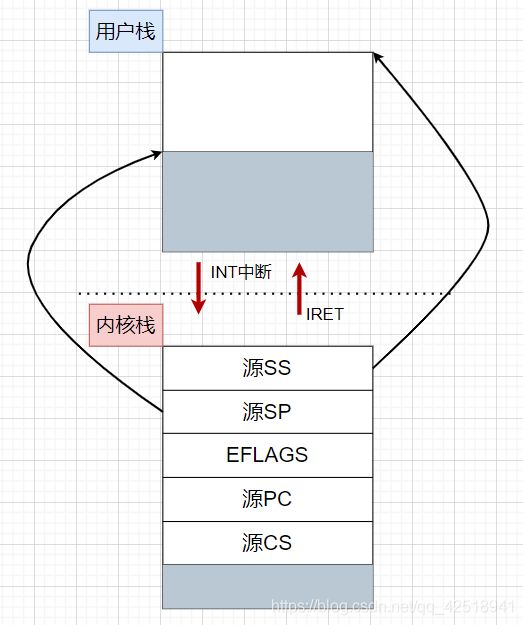
2.3 用户栈与内核栈之间的关联:
内核栈什么时候出现?当线程进入内核的时候就应该建立一个属于这个线程的内核栈。
通过INT中断,线程进入内核,操作系统可以根据一些硬件寄存器来知道这个哪个线程,它对应的内核栈在哪里。同时会将用户态的栈的位置:SS(Stack Segment)、SP(Stack Pointer)和程序执行到哪个地方了:CS(Code Segment)、IP(Instruction Pointer)都压入内核栈中保存下来。
等线程在内核里面执行完,退出内核态返回用户态时(也就是IRET指令),就根据之前内核栈中存入的SS、SP的值找到用户态中对应栈的位置,根据存入的CS、IP的值找到程序执行到哪个地方。
用户栈和内核栈,通过SS和SP两个指针联系在了一起,组成了一套栈。
2.4 内核级线程的切换概述
我们来看一个例子:
- 假设有两个内核级线程S和T。线程S的任务是启动磁盘读取数据,线程T随便。他俩的代码如下图所示。


- 通过中断进入内核。首先执行线程S,通过
int 0x80中断进入内核,内核栈的SS,SP指针建立起了内核栈和用户栈之间的联系;同时可以看到,PC指针指向的是中断int 0x80的下一个语句,CS代码段寄存器指向线程S代码的起始位置。
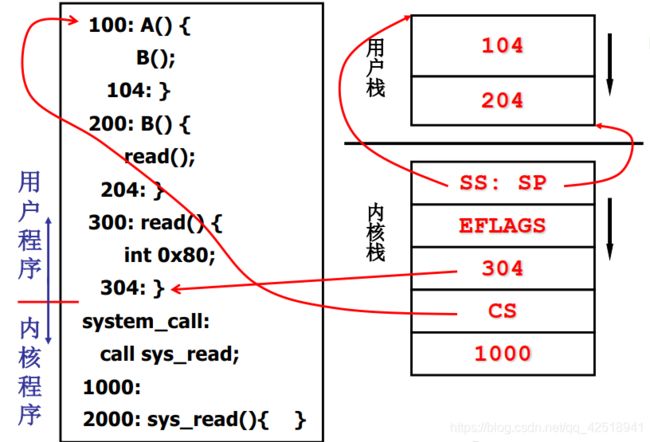
通过int0x80这个中断号进入内核态后,执行系统调用sys_read。由于读取数据需要等待,不能一直占用着CPU,这时候系统会将线程S设置为阻塞态,切换到下一个线程T去继续执行。
sys_read()
{
启动磁盘读;
将自己变成阻塞状态,让出CPU,让CPU执行其他线程;
找到next(寻找到下一个可执行的线程);
调用switch_to(cur,next);
}
switch_to()函数负责切换线程,形参cur表示当前线程S的TCB(Thread Control Block),next表示下一个执行线程T的TCB。
- 内核栈切换
switch_to()这个函数首先将目前esp(Extended Stack Pointer)寄存器的值存入cur.TCB.esp,将next.TCB.esp放入esp寄存器里面。其实就是从当前线程的内核栈切换到next线程的内核栈。
cur.TCB.esp = esp;
esp = next.TCB.esp;
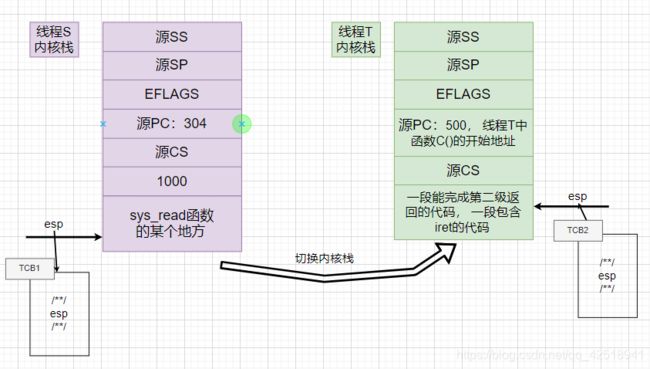
这里要明白一件事,内核级线程的代码还是在用户态的,只是进入内核态完成系统调用,也就是逛一圈之后还是要回去执行的。因此从线程S切换到线程T就是要根据线程T的内核栈找到这个线程阻塞前执行到的位置,执行线程T的函数。所以切换到线程T的内核栈之后,应该通过一条包含IRET指令的语句从内核栈返回到用户态执行线程T的代码。这样就完成了线程S到线程T的切换。
总结一下,内核级线程的切换可以分成五个步骤:
- 中断进入内核;
- 在内核态中,由于启动磁盘或者时钟中断,引发线程切换;
- 通过
TCB对内核栈进行切换; - 使用
IRET退出中断,对用户栈进行切换。至此,内核栈+用户栈都完成了切换; - 如果两个相互切换的线程不是同一个进程,还需要对内存映射表进行切换
三、核心级线程的具体实现
以fork()函数为例,剖析源码,了解一个核心级线程创建需要做哪些事情、同时观察核心级线程切换的具体过程。
main()
{
A();
B();
}
A()
{
fork(); // 系统调用
}
3.1 中断进入内核
执行到A()调用的时候会将A函数的返回地址也就是B()函数的起始地址压入当前线程的用户栈中,然后转入fork()这个系统调用,在fork()中肯定会通过int 0x80这个中断号进入操作系统内核;进入内核的时候会将用户栈的位置以及当前程序的执行地址都压入到内核栈中,然后开始执行fork()。
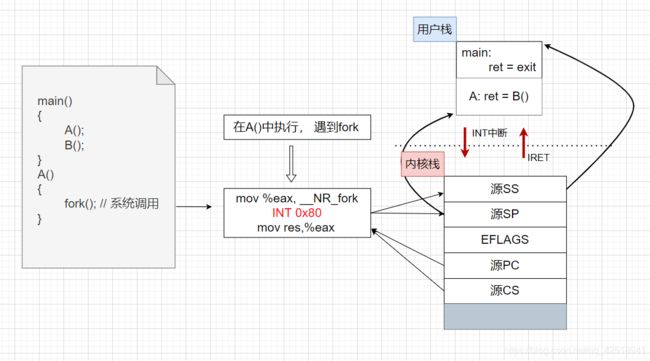
根据前面讲的系统调用知识可以知道,int 0x80的中断处理程序是_system_call,linux0.11的_system_call程序代码如下:
//文件位置: ~/oslab/linux-0.11/kernel/system_call.s
system_call:
cmpl $nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs points to local data space
mov %dx,%fs
call sys_call_table(,%eax,4) # call sys_fork
pushl %eax
//还有部分代码未展示
上面_system_call这段代码主要作用是将用户态的寄存器压栈到内核栈中进行保存。
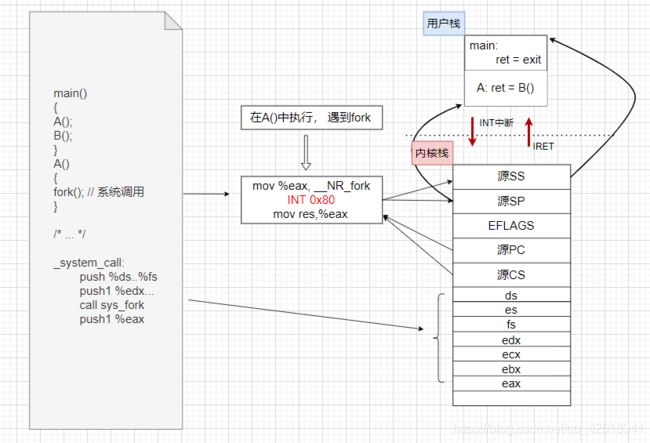
在sys_fork执行过程中可能需要切换到另外一个线程,它是如何切换的?其实也就是通过判断:
//文件位置: ~/oslab/linux-0.11/kernel/system_call.s
movl current,%eax
cmpl $0,state(%eax) # state
jne reschedule
cmpl $0,counter(%eax) # counter
je reschedule
movl _current;%eax中的_current 指的是当前线程的TCB。
cmpl $0,state(%eax)的含义就是判断当前线程的状态是不是0(0是运行态,TASK_RUNNING)。如果不是就调度,即执行jne reschedule。
cmpl $0,state(%eax)
jne reschedule
判断当前线程的时间片是不是用完了,如果用完了也需要调度。
reschedule:
pushl $ret_from_sys_call
jmp schedule
跳到reschedule位置后,程序首先将返回地址ret_from_sys_call压栈,接着执行调度函数 schedule。此处的schedule是一个C语言函数。该函数的伪代码如下,首先找到需要执行的下一个线程,然后转到该线程执行。
void schedule(void)
{
next=i; // 找到需要执行的下一个线程
switch_ to(next); // 转到该线程执行
}
schedule函数执行完成后,内核栈弹栈,将之前压入的ret_from_sys_call弹出来,程序接着跳转到ret_from_sys_call处继续执行。
ret_from_sys_call:
popl %eax...
pop %fs
iret
在ret_frome_sys_call程序段中做的事情主要是弹栈。不过值得注意的是,之前的switch_to()对内核栈进行了切换,所以这里的弹栈应该是对另一个线程的内核栈进行弹栈。内核栈中的SS, SP指向用户栈,CS, PC指向下一句程序执行的位置,切换后的内核栈和用户栈联系在一起,接着利用iret退出中断转到用户态,在用户态继续执行另一个线程的程序。
到目前为止,线程的切换已经说完了,但是从线程一切换到线程二这部分没讲,也就是switch_to这个宏定义
#define switch_to(n)
{struct{long a,b;}
__asm__(
movw %%dx,%1\n\t”
ljmp %0\n\t"
::"m"(*&_tmp.a),
"m(*&_tmp.b),
"d"(_TSS(n))}
这是段C内嵌汇编,是利用TSS进行切换的。TSS全称是Task State Segment,是TCB的一个子段。Linux0.11这种方式的代码简单但是效率不高,因此window和稍高版本的linux都不是用的这种方法。
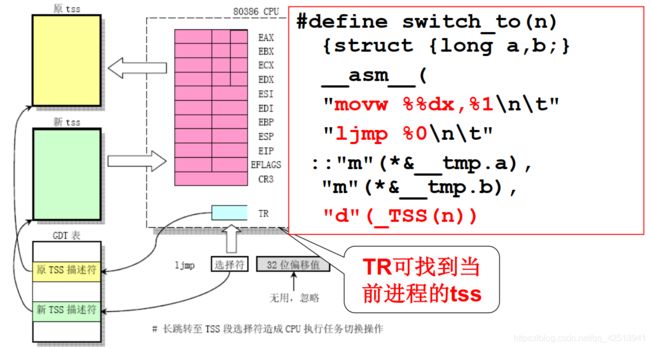
这种方法主要就是通过ljmp %o\n\t这条语句就是将线程二的TSS段中的值赋给CPU的寄存器。其实就和看电视一样,如果从节目一切换到节目二,就要先将节目一切换前的一幕存在脑海里面,以便于下次再看这个节目的时候能“不间断”的看。
参考文献:
1.操作系统(哈工大李治军老师)
2.操作系统(四) – 用户级线程与核心级线程(线程的切换)