白话解读 WebRTC 音频 NetEQ 及优化实践
NetEQ 是 WebRTC 音视频核心技术之一,对于提高 VoIP 质量有明显的效果,本文将从更为宏观的视角,用通俗白话介绍 WebRTC 中音频 NetEQ 的相关概念背景和框架原理,以及相关的优化实践。
作者| 良逸
审校| 泰一
为什么要 “白话” NetEQ?
随便搜索一下,我们就能在网上找到很多关于 WebRTC 中音频 NetEQ 的文章,比如下面的几篇文章都是非常不错的学习资料和参考。特别是西安电子科技大学 2013 年吴江锐的硕士论文《WebRTC 语音引擎中 NetEQ 技术的研究》,非常详尽地介绍了 NetEQ 实现细节,也被引用到了很多很多的文章中。
- 《WebRTC 语音引擎中 NetEQ 技术的研究》
- NetEQ 算法
- WebRTC 中音频相关的 NetEQ
这些文章大部分从比较 “学术” 的或 “算法” 的角度,对 NetEQ 的细节做了非常透彻的分析,所以这里我想从更宏观一些的角度,说一下我个人的理解。白话更容易被大家接受,争取一个数学公式都不用,一行代码都不上就把思路说清楚,有理解不对的地方,还请大家不吝赐教。
丢包、抖动和优化的理解
在音视频实时通信领域,特别是移动办公(4G),疫情下的居家办公和在线课堂 (WIFI),网络环境成了影响音视频质量最关键的因素,在差的网络质量面前,再好的音视频算法都显得有些杯水车薪。网络质量差的表现主要有延时、乱序、丢包、抖动,谁能处理和平衡好这几类问题,谁就能获得更好的音视频体验。由于网络的基础延时是链路的选择决定的,需优化链路调度层来解决;而乱序在大部分网络条件下并不是很多,而且乱序的程度也不是很严重,所以接下来我们主要会讨论丢包和抖动。
抖动是数据在网络上的传输忽快忽慢,丢包是数据包经过网络传输,因为各种原因被丢掉了,经过几次重传后被成功收到是恢复包,重传也失败的或者恢复包过时的,都会形成真正的丢包,需要丢包恢复 PLC 算法来无中生有的产生一些假数据来补偿。丢包和抖动从时间维度上又是统一的,等一会来了的是抖动,迟到很久才来的是重传包,等一辈子也不来的就是 “真丢包”,我们的目标就是要尽量降低数据包变成 “真丢包” 的概率。
优化,直观来讲就是某个数据指标,经过一顿猛如虎的操作之后,从 xxx 提升到了 xxx。但我觉得,评判优化好坏不能仅仅停留在这个维度,优化是要 “知己知彼”,己是自己的产品需求,彼是现有算法的能力,己彼合一才是最好的优化,不管算法是简单还是复杂,只要能完美的匹配自己的产品需求,就是最好的算法,“能捉到老鼠的就是好猫”。
NetEQ 及相关模块
NetEQ 的出处
《GIPS NetEQ 原始文档》,这是由 GIPS 公司提供的最原始的 NetEQ 的说明文档(中文翻译),里面介绍了什么是 NetEQ 以及对其性能的简单说明。NetEQ 本质上就是一个音频的 JitterBuffer(抖动缓冲器),名字起的非常贴切,Network Equalizer(网络均衡器)。大家都知道 Audio Equalizer 是用来均衡声音的效果器,而这里的 NetEQ 是用来均衡网络抖动的效果器。而且 GIPS 还给这个名字注册了商标,所以很多地方看到的是 NetEQ ™ 。
上面的官方文档中,有一条很重要信息,“最小化抖动缓冲带来的延时影响”,这说明 NetEQ 的设计目标之一就是:“追求极低延时”。这个信息很关键,为我们后续的优化提供了重要线索。



NetEQ 在音视频通讯 QoS 流程中的位置
音视频通讯对于普通用户来说,只要网络是通的,WIFI 和 4G 都可以,一个呼叫过去,看到人且听到声音,就 OK 了,很简单的事情,但对于底层的实现却没有看起来那么简单。单 WebRTC 开源引擎的相关代码文件数量就有 20 万个左右,代码行数不知道有没有人具体算过,应该也是千万数量级的了。不知道多少码农为此掉光了头发 。
下面这张图,是对实际上更复杂的音视频通讯流程的抽象和简化。左边是发送 (推流) 侧:经过采集、编码、封装、发送;中间经过网络传输;右边是接收 (拉流) 侧:接收、解包、解码、播放;这里重点体现了 QoS(Quality of Service,服务质量)的几个大的功能,以及跟推拉流数据主要流程的关系。可以看到 QoS 功能分散在音视频通讯流程中的各个位置,导致要了解整个流程之后才能对 QoS 有比较全面的理解。图上看起来左边发送侧的 QoS 功能要多一些,这是因为 QoS 的目的就是要解决通讯过程中的用户体验问题,要解决问题,最好就是找到问题的源头,能从源头解决的,都是比较好的解决方式。但总有一部分问题是不能从源头来解决的,比如在多人会议的场景,一个人的收流侧网络坏了,不能影响其它人的开会体验,不能出现 “一颗老鼠屎坏掉一锅粥” 的情况,不能污染源头。所以收流也要做 QoS 的功能,目前收流侧的必备功能就是 JitterBuffer,包括视频的和音频的,本文重点分析音频的 JitterBuffer – NetEQ。

NetEQ 原理及相关模块的关系

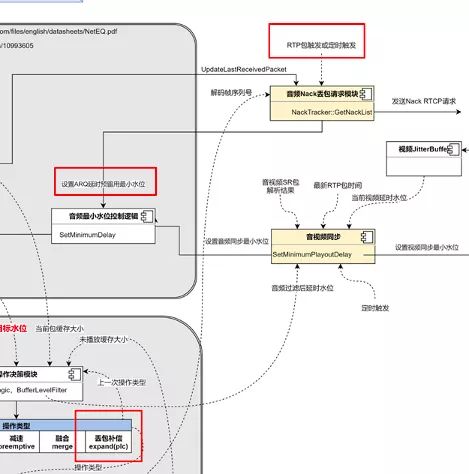
上面这张图是对 NetEQ 及其相关模块工作流程的抽象,主要包含 4 个部分,NetEQ 的输入、NetEQ 的输出、音频重传 Nack 请求模块、音视频同步模块。为什么要把 Nack 请求模块和音视频同步模块也放进 NetEQ 的分析中?因为这两个模块都直接跟 NetEQ 有依赖,相互影响。图里面的虚线,标识每个模块依赖的其它模块的信息,以及这些信息的来源。接下来介绍一下整个流程。
1. 首先是 NetEQ 的输入部分:
底层 Socket 收到一个 UDP 包后,触发从 UDP 包到 RTP 包的解析,经过对 SSRC 和 PayloadType 的匹配,找到对应的音频流接收的 Channel,然后从 InsertPacketInternal 输入到 NetEQ 的接收模块中。
收到的音频 RTP 包很可能会带有 RED 冗余包(redundance),按照 RFC2198 的标准或者一些私有的封装格式,对其进行解包,还原出原始包,重复的原始包将会被忽略掉。解出来的原始 RTP 数据包会被按一定的算法插入到 packet buffer 缓存里面去。之后会将收到的每一个原始包的序列号,通过 UpdateLastReceivedPacket 函数更新到 Nack 重传请求模块,Nack 模块会通过 RTP 收包或定时器触发两种模式,调用 GetNackList 函数来生成重传请求,以 NACK RTCP 包的格式发送给推流侧。
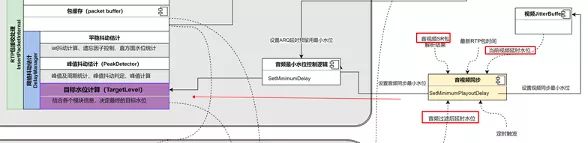
同时,解完的每一个原始包,得到了时间轴上唯一的一个接收时刻,包和包之间的接收时间差也能算出来了,这个接收时间差除以每个包的打包时长就是 NetEQ 内部用来做抖动估计的 IAT(interarrival time),比如,两个包时间差是 120ms,而打包时长是 20ms,则当前包的 IAT 值就是 120/20=6。之后每个包的 IAT 值经过核心的网络抖动估计模块(DelayManager)处理之后,得到最终的目标水位(TargetLevel),到此 NetEQ 的输入处理部分就结束了。
2. 其次是 NetEQ 的输出部分:
输出是由音频硬件播放设备的播放线程定时触发的,播放设备会每 10ms 通过 GetAudioInternal 接口从 NetEQ 里面取 10ms 长度的数据来播放。
进入 GetAudioInternal 的函数之后,第一步要决策如何应对当前数据请求,这个任务交给操作决策模块来完成,决策模块根据之前的和当前的数据和操作的状态,给出最终的操作类型判断。NetEQ 里面定义了几种操作类型:正常、加速、减速、融合、拉伸(丢包补偿)、静音,这几种操作的意义,后面再详细的说。有了决策的操作类型,再从输入部分的包缓存(packet buffer)里面取出一个 RTP 包,送给抽象的解码器,抽象的解码器通过 DecodeLoop 函数层层调用到真正的解码器进行解码,并把解码后的 PCM 音频数据放到 DecodedBuffer 里面去。然后就是开始执行不同的操作了,NetEQ 里面为每一种操作都实现了不同的音频数字信号处理算法(DSP),除了 “正常” 操作会直接使用 DecodedBuffer 里的解码数据,其它操作都会结合解码的数据进行二次 DSP 处理,处理结果会先被放到算法缓存(Algorithm Buffer)里面去,然后再插入到 Sync Buffer 里面。Sync Buffer 是一个循环 buffer,设计的比较巧妙,存放了已经播放过的数据、解码后未播放的数据,刚刚从算法缓存里插入的数据放在 Sync Buffer 的末尾,如上图所示。最后就是从 Sync Buffer 取出最早解码后的数据,送出去给外部的混音模块,混音之后再送到音频硬件来播放。
另外,从图上可以看出决策模块(BufferLevelFilter)会结合当前包缓存 packet buffer 里缓存的时长,和 Sync Buffer 里缓存的数据时长,经过算法过滤后得到音频当前的缓存水位。音视频同步模块会使用当前音频缓存水位,和视频当前缓存水位,结合最新 RTP 包的时间戳和音视频的 SR 包获得的时间戳,计算出音视频的不同步程度,再通过 SetMinimumPlayoutDelay 最终设置到 NetEQ 里面的最小目标水位,来控制 TargetLevel,实现音视频同步。
NetEQ 内部模块
NetEQ 抖动估计模块(DelayManager)
1. 平稳抖动估计部分:
将每个包的 IAT 值,按照一定的比例(取多少比例是由下面的遗忘因子部分的计算决定的),累加到下面的 IAT 统计的直方图里面,最后计算从左往右累加值的 0.95 位置,此位置的 IAT 值作为最后的抖动 IAT 估计值。例如下图,假定目标水位 TargetLevel 是 9,意味着目标缓存数据时长将会是 180ms(假定打包时长 20ms)。

2. 平稳抖动遗忘因子计算:
遗忘因子是用来控制当前包的 IAT 值取多少比例累加到上面的直方图里面去的系数,计算过程用了一个看起来比较复杂的公式,经过分析,其本质就是下面的黄色曲线,意思是开始的时候遗忘因子小,会取更多的当前包的 IAT 值来累加,随着时间推移,遗忘因子逐渐变大,会取更少的当前包 IAT 值来累加。这个过程搞的有点复杂,从工程角度看完全可以简化成直线之类的,因为测试下来 5s 左右的时间,基本就收敛到目标值 0.9993 了,其实这个 0.9993 才是影响抖动估计的最主要的因素,很多优化也是直接修改这个系数来调节估计的灵敏度。

3. 峰值抖动估计:
DelayManager 中有一个峰值检测器 PeakDetector 用来识别峰值,如果频繁检测到峰值,会进入峰值抖动的估计状态,取最大的峰值作为最终估计结果,而且一旦进入这个状态会一直维持 20s 时间,不管当前抖动是否已经恢复正常了。下面是一个示意图。

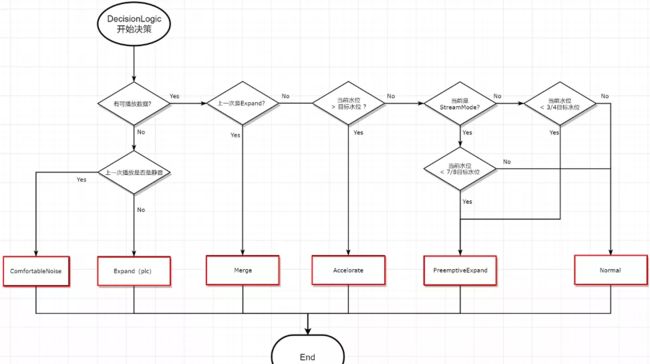
NetEQ 操作决策模块(DecisionLogic)
决策模块的简化后的基本判定逻辑,如下图所示,比较简洁不用解释。这里解释一下下面这几个操作类型的意义:
- ComfortNoise:是用来产生舒适噪声的,比单纯的静音包听起来会更舒服的静音状态;
- Expand(PLC):丢包补偿,最重要的无中生有算法模块,解决 “真丢包” 时没数据的问题,造假专业户 ;
- Merge:如果上一次是 Expand 造假出来的数据,那为了听起来更舒服一些,会跟正常数据包做一次融合算法;
- Accelerate:变声不变调的加速播放算法;
- PreemptiveExpand:变声不变调的减速播放算法;
- Normal:正常的解码播放,不额外引入假数据;
NetEQ 相关模块优化点
NetEQ 抗抖动优化
- 由于 NetEQ 的设计目标是 “极低延时”,不能很好的匹配,视频会议,在线课堂,直播连麦等非极低延时场景,需要对其敏感度进行调整,主要调整抖动估计模块相关的灵敏度;
- 直播场景,由于对于延时敏感度可以到秒级以上,所以需要启用 StreamMode 的功能(新版本中好像去掉了),而且也需要对其中参数进行适配;
- 服务于极低延时目标,原始的包缓存 packetbuffer 太小,容易造成 flush,需要按业务需要调大一些;
- 还有一些业务会根据自己的业务场景主动识别网络状况,然后直接设置最小 TargetLevel,简单粗暴的控制 NetEQ 的水位。

NetEQ 抗丢包优化:
- 原始的 WebRTC 的 Nack 丢包请求的触发机制是用包触发的,在弱网下会恶化重传效果,可以改为定时触发来解决;
- 丢包场景会有重传,但如果 buffer 太小,重传也会被丢弃,所以为了提高重传效率,增加 ARQ 延时预留功能,可明显降低拉伸率;
- 比较算法级的优化是对丢包补偿 PLC 算法的优化,调整现有 NetEQ 的拉伸机制,优化听感效果;
- 开启 Opus 的 Dtx 功能之后,在丢包场景会导致音频 Buffer 变大,需要单独优化 Dtx 相关处理逻辑。
下面是 ARQ 延时预留功能开启后的效果对比,平均拉伸率降低 50%,延时也会相应增加:

音视频同步优化:
- 原始的 WebRTC 的 P2P 音视频同步算法是没有问题的,但是目前架构上面一般都有媒体转发服务器(SFU),而服务器的 SR 包生成算法可能会由于某些限制或者错误会不完全正确,导致无法正常同步,为规避 SR 包生成错误,需要优化音视频同步模块的计算方式,使用水位为主要参考来同步,即在接收端保证音视频的缓存时间是差不多大小的。下面是优化效果的对比:
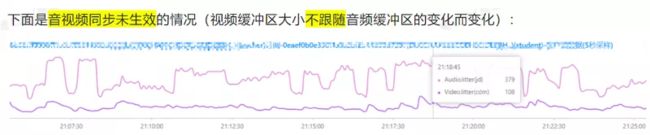
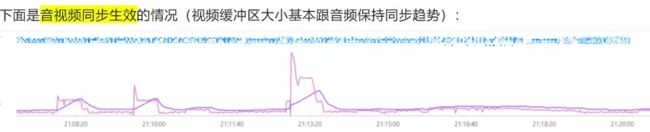
- 还有一种音视频同步的问题,其实不是音视频同步机制导致的,而是设备性能有问题,不能及时处理视频的解码和渲染,导致视频数据累积,从而形成的音视频不同步。这种问题可以通过对比不同步时长的趋势,跟视频解码和渲染时长的趋势,两者匹配度会很高,如下图所示:

总结
NetEQ 作为音频接收侧的核心功能,基本上包含了各个方面,所以很多很多音视频通讯的技术实现里都会有它的踪迹,乘着 WebRTC 开源快 10 年的东风,NetEQ 也变的非常普及,希望这篇白话文章能帮大家更好的理解 NetEQ。
作者最后的话:需求不停歇,优化无止境!
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。